前回 画像オートエンコーダの学習におけるロスの選び方の違い(CelebAの場合) の続きです。
課題のおさらい
ディープラーニングの画像オートエンコーダにおいて出力のロスを計算する方法がいろいろな実装によって異なるので実際どれくらい違うのかを試そうというお話。以下のそれぞれのロスの取り方でどれくらい学習の傾向が異なるのかを試します。
- 画素毎に二乗誤差をとる
- 画素毎にバイナリクロスエントロピーをとる
- 画素毎の二乗誤差をサンプルごとに平均する
- 画素毎のバイナリクロスエントロピーをサンプルごとに平均する
- 画素毎の二乗誤差をミニバッチ全体で平均する
- 画素毎のバイナリクロスエントロピーをミニバッチ全体で平均する
実験条件
前回はデータセットとして CelebA を使用しました。今回はCelebAよりも個々の画像の違いが大きい Places2 を使用します。
Places2の256x256のTrainイメージを128x128にリサイズしたものを学習データとしています。
使用するデータセット以外は前回 画像オートエンコーダの学習におけるロスの選び方の違い(CelebAの場合) と同一です。
ロスの推移
学習中のロスの推移です。全体で見るとあまり変わらない印象。
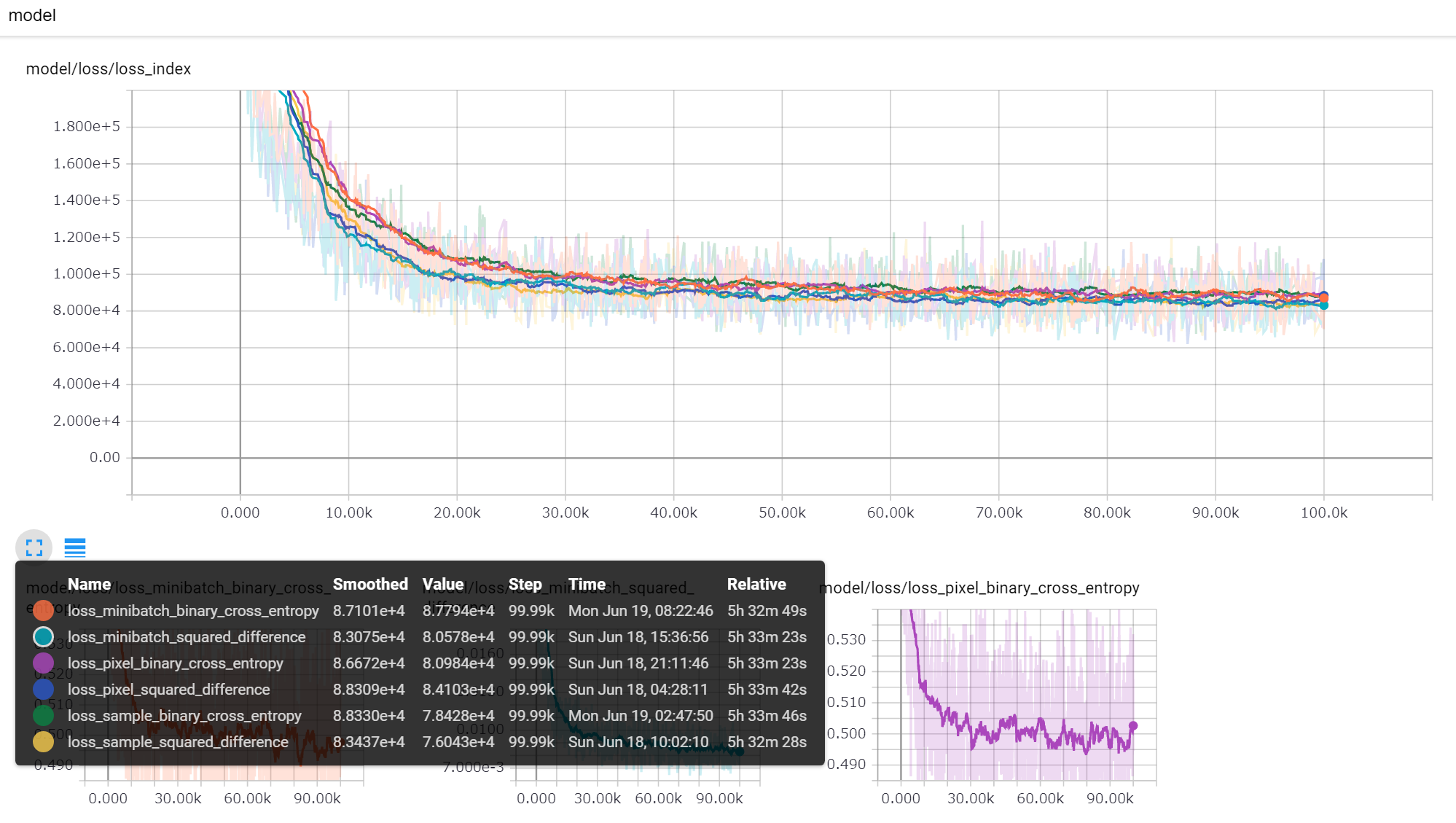
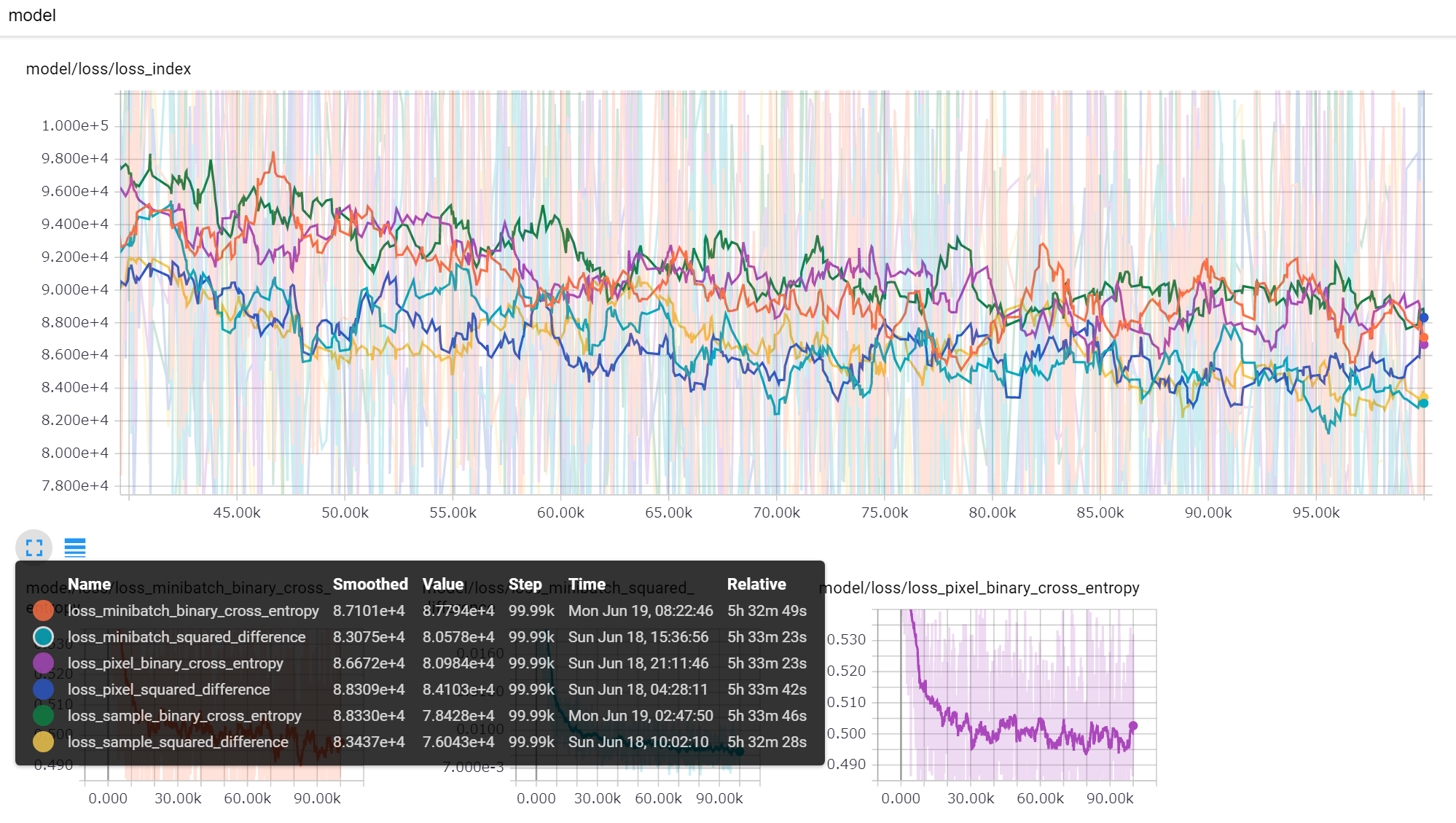
中盤から後半にかけての部分の拡大表示。傾向としてバイナリクロスエントロピーよりも二乗誤差の方が常に下で推移している。画素で取るか、サンプルで取るか、ミニバッチで取るかはあまり影響しない。
チャートは二乗誤差の平均値でプロットしているため二乗誤差のロスが有利になっていて、バイナリクロスエントロピーで比較すると逆転するのかもしれない。
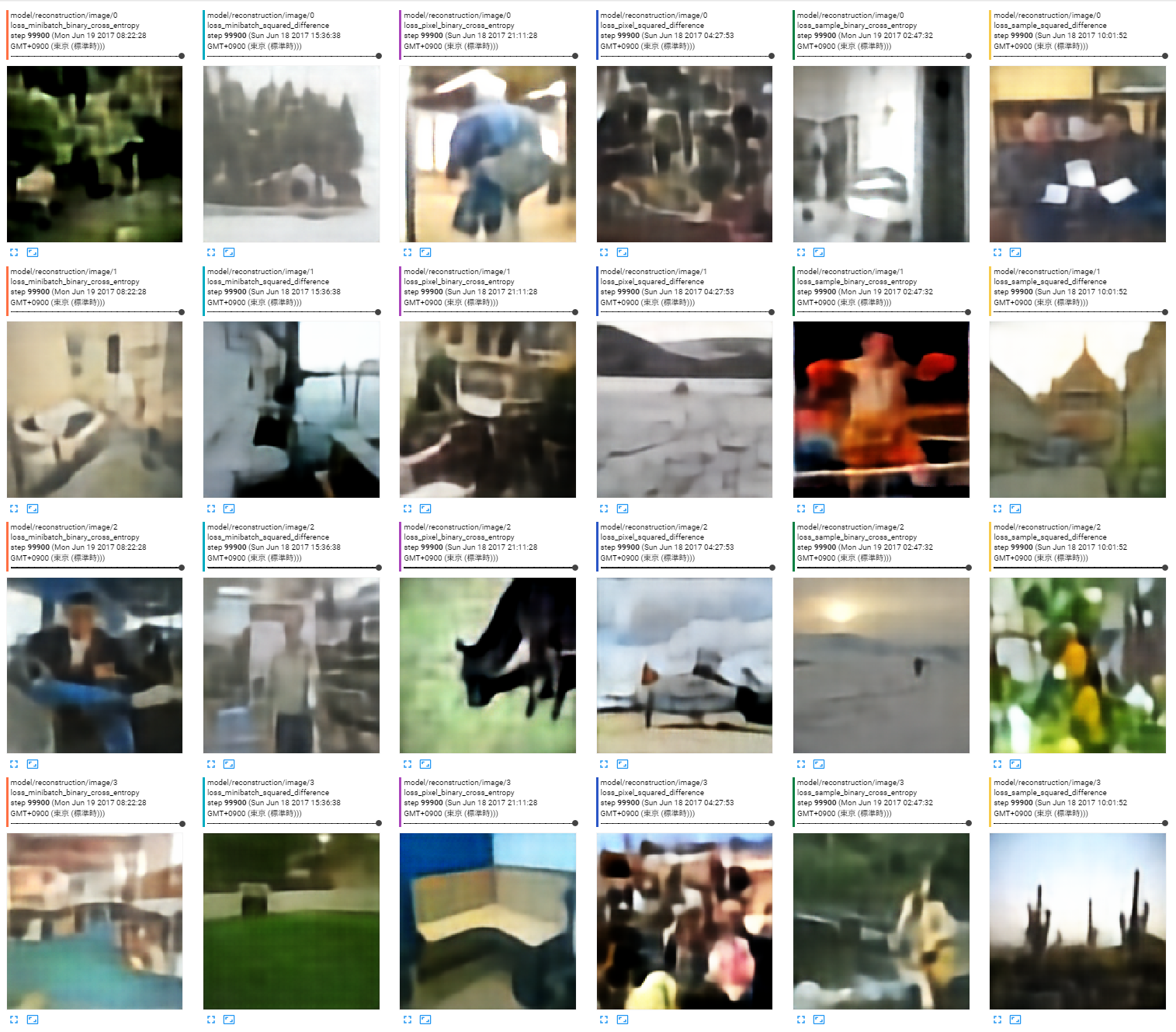
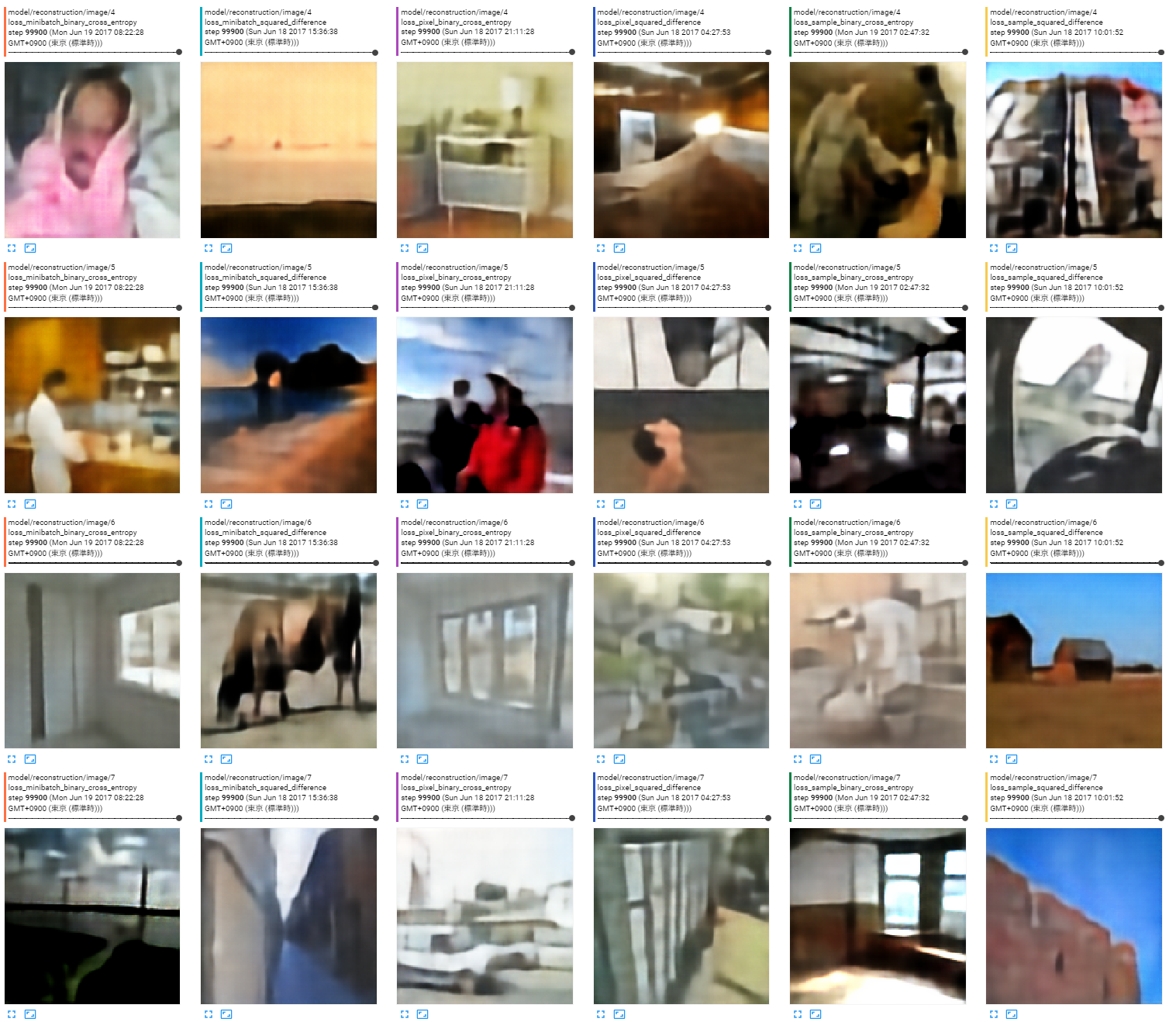
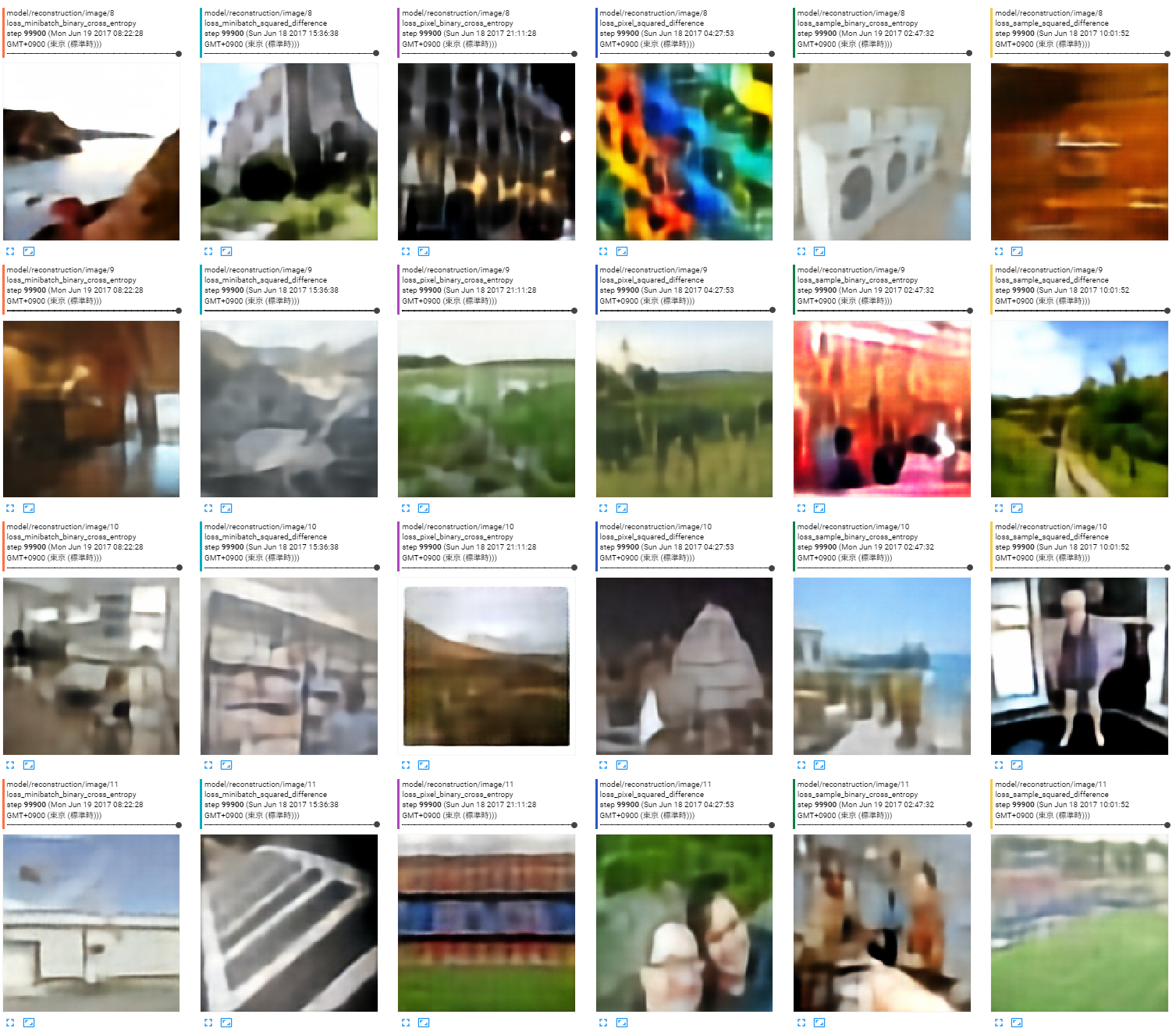
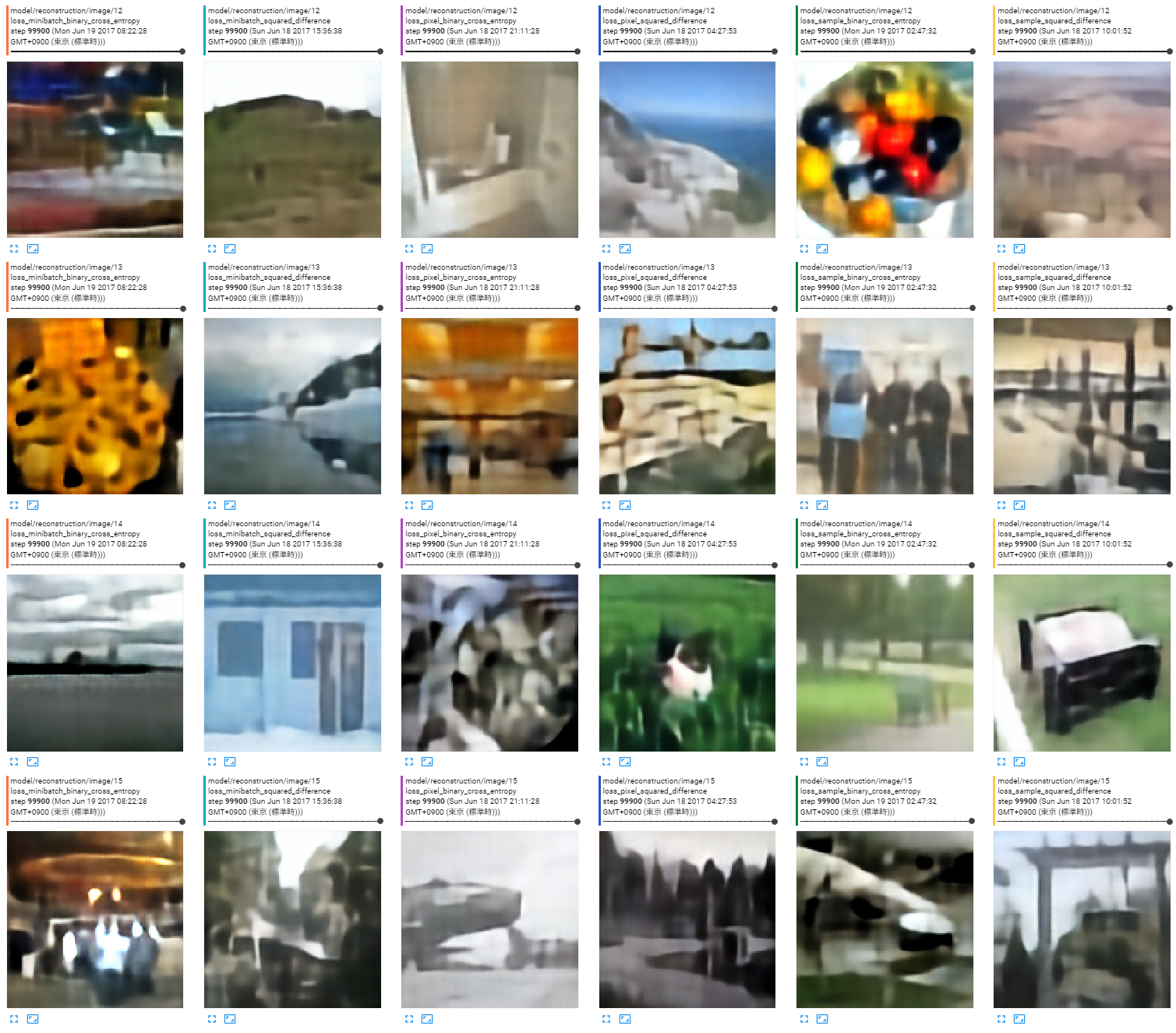
出力画像
ロスの種類は左から以下の順。
- ミニバッチ全体の平均、バイナリクロスエントロピー
- ミニバッチ全体の平均、二乗誤差
- 画素単位、バイナリクロスエントロピー
- 画素単位、二乗誤差
- サンプルごとに平均、バイナリクロスエントロピー
- サンプルごとに平均、二乗誤差
今回の調査には関係ないがCelebAよりも分散が大きいので見た目の再構成がうまくいっていない。こういう時にエンコーダ、中間特徴、デコーダのどこをどうすれば十分になるのかの勘どころもよく分かっていない。
まとめ
前回に引き続いて実験して、前回同様に「あまり気にしなくていいんじゃないか」という感想になった。
モデルが表現可能な分散を増やして(ネットワークのチャネル数や次元数を大きくして)ピクセル単位でほぼ一致するところまで学習を進めようとしたときにどれだけ影響が出るのかわからないしGAN系列やVAE系列でどうなるかもよくわからない。
結論「あんま変わらないけど最終的には違いが出るかも知れないけどよくわからない!」