はじめに
今回私は最近はやりのchatGPTに興味を持ち、深層学習について学んでみたいと思い立ちました!
深層学習といえばPythonということなので、最終的にはPythonを使って深層学習ができるとこまでコツコツと学習していくことにしました。
ただ、勉強するだけではなく少しでもアウトプットをしようということで、備忘録として学習した内容をまとめていこうと思います。
この記事が少しでも誰かの糧になることを願っております!
※投稿主の環境はWindowsなのでMacの方は多少違う部分が出てくると思いますが、ご了承ください。
最初の記事:Python初心者の備忘録 #01
前の記事:Python初心者の備忘録 #26 ~深層学習超入門編02~
次の記事:Python初心者の備忘録 #28 ~深層学習超入門編04~
今回はGPU、nnモジュール、Optimizer、Dataset・DataLoader、学習率設定についてまとめております。
■学習に使用している資料
Udemy:①米国AI開発者がやさしく教える深層学習超入門第一弾【Pythonで実践】
■GPU
- 深層学習では膨大な計算量になるときがあり、その際は並列慶安が得意なGPUを活用することで計算時間を大幅に短縮することができる。
- 自身で高性能なGPUを用意するのは困難なので、クラウドサービスを使用するのがBetter
- AWS
- Google Colab
- Kagglu
...etc
▶GPUを使った計算
- tensorでは明示的に指定しない限りCPUで計算するので、どの計算をGPUで計算するのかをその都度指定する必要がある
-
.to()メソッドでtensorを特定のデバイスに移動させる(新しいtensorを作成)-
.to('cuda'):GPUに移動 -
.to('cpu'):CPUに移動(デフォルトではCPU上に作られる)
※.to()で移動させたtensorは別の新たなtensorになり、異なるデバイスにあるtensor同士の演算はできないことに注意
-
-
torch.cuda.is_available()でGPUの有無を確認できる
→ GPUが使える状態であればTrueを返す
device = "cuda" if turch.cuda.is_available() else "cpu"
sample_tensor = torch.randn(10).to()device
GPUでの学習
import torch
import time
# CPU上でTensorを作成
tensor_cpu = torch.randn(10000, 10000)
# GPU上でTensorを作成 (もしGPUが利用可能なら)
device = "cuda" if torch.cuda.is_available() else "cpu" # device -> GPUが使用可能であれば'cuda',使えなければ'cpu'が入る
tensor_gpu = tensor_cpu.to(device)
# CPU上での計算の時間を測定
start_time = time.time()
result_cpu = torch.mm(tensor_cpu, tensor_cpu)
end_time = time.time()
print(f"Time taken on CPU: {end_time - start_time:.5f} seconds")
# GPU上での計算の時間を測定 (もしGPUが利用可能なら)
if device == "cuda":
start_time = time.time()
result_gpu = torch.mm(tensor_gpu, tensor_gpu)
end_time = time.time()
print(f"Time taken on GPU: {end_time - start_time:.5f} seconds")
MLP学習ループをGPU上での計算をするように修正
※モデルとデータ準備の部分でそれぞれのtensorをGPUに移すように修正を入れています。
import torch
from sklearn import datasets
import matplotlib.pyplot as plt
from torch.nn import functional as F
from sklearn.model_selection import train_test_split
import numpy as np
device = 'cuda'
# ======モデル======
class Linear():
def __init__(self, in_features, out_features, n):
self.W = (torch.randn((out_features, in_features)) * torch.sqrt(torch.tensor(2.0 / n))).to(device) # 修正
self.W.requires_grad = True
self.b = torch.zeros((1, out_features)).to(device) # 修正
self.b.requires_grad = True # 修正
def forward(self, X):
self.X = X
self.Z = X @ self.W.T + self.b
return self.Z
def backward(self, Z):
self.W.grad_ = Z.grad_.T @ self.X
self.b.grad_ = torch.sum(Z.grad_, dim=0)
self.X.grad_ = Z.grad_ @ self.W
return self.X.grad_
class ReLU():
def forward(self, X):
self.X = X
return X.clamp_min(0.)
def backward(self, A):
return A.grad_ * (self.X > 0).float()
class SoftmaxCrossEntropy:
def forward(self, X, y):
e_x = torch.exp(X - torch.max(X, dim=-1, keepdim=True)[0])
self.softmax_out = e_x / (torch.sum(e_x, dim=-1, keepdim=True) + 1e-10)
log_probs = torch.log(self.softmax_out + 1e-10)
target_log_probs = log_probs * y
self.loss = -target_log_probs.sum(dim=-1).mean()
return self.loss
def backward(self, y):
return (self.softmax_out - y) / y.shape[0]
class Model:
def __init__(self, input_features, hidden_units, output_units, data_num):
self.linear1 = Linear(input_features, hidden_units, data_num)
self.relu = ReLU()
self.linear2 = Linear(hidden_units, output_units, data_num)
self.loss_fn = SoftmaxCrossEntropy()
def forward(self, X, y):
self.X = X
self.Z1 = self.linear1.forward(X)
self.A1 = self.relu.forward(self.Z1)
self.Z2 = self.linear2.forward(self.A1)
self.loss = self.loss_fn.forward(self.Z2, y)
return self.loss, self.Z2
def backward(self, y):
self.Z2.grad_ = self.loss_fn.backward(y)
self.A1.grad_ = self.linear2.backward(self.Z2)
self.Z1.grad_ = self.relu.backward(self.A1)
self.X.grad_ = self.linear1.backward(self.Z1)
def zero_grad(self):
# 勾配の初期化
self.linear1.W.grad_ = None
self.linear1.b.grad_ = None
self.linear2.W.grad_ = None
self.linear2.b.grad_ = None
def step(self, learning_rate):
# パラメータの更新
self.linear1.W -= learning_rate * self.linear1.W.grad_
self.linear1.b -= learning_rate * self.linear1.b.grad_
self.linear2.W -= learning_rate * self.linear2.W.grad_
self.linear2.b -= learning_rate * self.linear2.b.grad_
## Refactoring後の学習ループ(OptimizerやDataset, Dataloaderは後ほどRefactoring)
# ===データの準備====
dataset = datasets.load_digits()
data = dataset['data']
target = dataset['target']
images = dataset['images']
X_train, X_val, y_train, y_val = train_test_split(images, target, test_size=0.2, random_state=42)
X_train_mean = X_train.mean()
X_train_std = X_train.std()
X_train = (X_train - X_train_mean) / X_train_std
X_val = (X_val - X_train_mean) / X_train_std
X_train = torch.tensor(X_train.reshape(-1, 64), dtype=torch.float32).to(device) # 修正
X_val = torch.tensor(X_val.reshape(-1, 64), dtype=torch.float32).to(device) # 修正
y_train = F.one_hot(torch.tensor(y_train), num_classes=10).to(device) # 修正 #1437 x 10
y_val = F.one_hot(torch.tensor(y_val), num_classes=10).to(device) # 修正 # 360 x 10
batch_size = 30
# モデルの初期化
model = Model(input_features=64, hidden_units=1000, output_units=10, data_num=batch_size)
learning_rate = 0.01
# ログ
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(100):
# エポック毎にデータをシャッフル
shuffled_indices = np.random.permutation(len(y_train))
num_batches = np.ceil(len(y_train)/batch_size).astype(int)
running_loss = 0.0
start_time = time.time()
for i in range(num_batches):
# mini batch作成
start = i * batch_size
end = start + batch_size
batch_indices = shuffled_indices[start:end]
y_true_ = y_train[batch_indices, :] # batch_size x 10
X = X_train[batch_indices] # batch_size x 64
# 順伝播と逆伝播の計算
loss, _ = model.forward(X, y_true_)
model.backward(y_true_)
running_loss += loss.item()
# パラメータ更新
with torch.no_grad():
model.step(learning_rate)
model.zero_grad()
# validation
with torch.no_grad():
val_loss, Z2_val = model.forward(X_val, y_val)
val_accuracy = torch.sum(torch.argmax(Z2_val, dim=-1) == torch.argmax(y_val, dim=-1)) / y_val.shape[0]
train_losses.append(running_loss/num_batches)
val_losses.append(val_loss.item())
val_accuracies.append(val_accuracy)
end_time = time.time()
epoch_duration = end_time - start_time
# print(f'epoch: {epoch}: train error: {running_loss/num_batches}, validation error: {val_loss.item()}, validation accuracy: {val_accuracy}, epoch duration {epoch_duration:.2f} sec')
■NN(ニューラルネットワーク)モジュール
今まではNNをスクラッチで作成してきたが、Pytorchではすでに用意されているものもあるので、そのようなモジュールについて紹介していく。
▶torch.nnについて
-
torch.nnには深層学習のアーキテクチャこ構築するためんおクラスと関数が入っている-
層:NNの基本的な層のblock
-
nn.Linear:全結合層 -
nn.ReLU:ReLU層
-
-
損失関数:ネットワークのパフォーマンスを評価する
-
nn.MSELoss:平均二乗誤差 -
nn.CrossEntropy:交差エントロピー
-
-
モジュール:全てのNNモジュールの基本クラスで、カスタムする際は
nn.Moduleを継承する -
関数:単一の関数として層や損失関数、活性化関数を提供する。
torch.nn.functionalに入っており、通常はFとしてimportする
※例えばnn.ReLUとF.relu()のようにどちらにもReLUはある。それぞれクラスと関数なので、その時の用途で使い分ける
-
層:NNの基本的な層のblock
▶全結合層(FC層:Fully Connected)(nn.Linear)
- 全結合$XW^T+b$を実装したモジュール
import torch
from torch import nn
linear = nn.Linear(input_dim, output_dim)
import torch
class MyLinear:
def __init__(self, input_dim, output_dim):
self.weight = torch.randn(output_dim, input_dim)
self.bias = torch.zeros(output_dim)
def __call__(self, x):
return x @ self.weight.t() + self.bias
.
.
.
Pythonでnn.Linear
-
nn.Linear()のインスタンスを生成 -
.parameters()でその層の全てのパラメータを確認 -
.weightおよび.bias属性にアクセスし,パラメータの重みとバイアスの値を
確認 - tensorを作って順伝播させる
import torch
from torch import nn
# インスタンス生成
linear = nn.Linear(64, 30)
# weightとbiasの二つのtensorがparameter
list(linear.parameters())
""" 出力結果
[Parameter containing:
tensor([[-0.0445, 0.0273, 0.0644, ..., -0.0004, 0.0982, -0.0988],
[-0.0505, -0.0322, -0.0073, ..., -0.0187, 0.0680, -0.0556],
[-0.0376, -0.0396, -0.0291, ..., 0.0521, -0.1179, 0.0771],
..,
[ 0.0637, 0.0988, 0.1097, ..., -0.0255, -0.0306, -0.0304],
[ 0.0380, 0.0816, -0.0582, ..., -0.0325, -0.0317, -0.0513],
[ 0.0148, -0.0768, 0.0188, ..., -0.1154, -0.0139, 0.1208]],
requires_grad=True),
Parameter containing:
tensor([-0.0092, 0.0294, 0.0859, -0.0046, -0.0866, -0.0182, -0.0050, 0.0097,
0.0126, -0.0632, 0.0738, 0.0108, 0.1179, -0.0548, 0.1244, -0.1035,
-0.0980, 0.0472, -0.0942, -0.0102, -0.0765, -0.1038, -0.0761, -0.1179,
0.0798, 0.0589, -0.0605, -0.0856, -0.0483, 0.0448],
requires_grad=True)]
"""
# weightは出力x入力であることに注意.Z = X@W.T + bになっている
print(linear.weight.shape) # -> torch.Size([30, 64])
print(linear.bias.shape) # -> torch.Size([30])
# 順伝搬
X = torch.randn((5, 64))
Z = linear(X)
Z.shape # -> torch.Size([5, 30])
▶ReLU層(F.relu)
import torch
import torch.nn.functional as F
# 入力tensorの定義(ランダムな値を持つ5次元のベクトル)
x = torch.randn(5, requires_grad=True)
# ReLU関数の適用
out = F.relu(x)
import torch
class MyReLU:
def __call__(self, x):
# ⼊⼒xが0より⼤きい位置のインデックスを保持
self.mask = x > 0
return x * self.mask.float()
.
.
.
▶nnモジュールでMLPモデルを作成
- 作成の仕方は大きく3つ
-
nn.<class>とF.<function>を組み合わせる-
nn.Moduleクラスを継承するクラスを作成 - パラメータを持つ層は
nn.<class>で定義する - パラメータを持たない操作(活性化関数など)は
F.<funcbon>で定義する
- パラメータを持つ層の管理が容易になる
-
-
nn.<class>のみで構成する- パラメータを持たない操作も
nn.<class>を使用する - モデル全体の構造に一貫性が生まれ,パラメータの有無を意識する必要がなくなる
- 操作によっては,
nn.<class>の方がF.<funcbon>よりも処理が重い場合もある
- パラメータを持たない操作も
-
nn.Sequenbalを使う-
nn.Sequenbal()にnn.<class>のインスタンスを直列に引数に渡す -
nn.Sequenbal()は,NNのアーキテクチャを直列に定義するための簡単な方法 - 非常にシンプルなアーキテクチャを作成する際に便利だが、複雑なモデルには使えない
-
-
1. nn.<class>とF.<function>を組み合わせる
# 1. nn.クラスとF.関数を組み合わせたケース
class MLP(nn.Module):
def __init__(self, num_in, num_hidden, num_out):
super().__init__()
self.l1 = nn.Linear(num_in, num_hidden)
self.l2 = nn.Linear(num_hidden, num_out)
def forward(self, x):
# z1 = self.l1(x)
# a1 = F.relu(z1)
# z2 = self.l2(a1)
x = self.l2(F.relu(self.l1(x))) # 上記3つを合わせて
return x
# 順伝搬テスト
model = MLP(64, 30, 10)
X = torch.randn(5, 64)
Z = model(X) # 親クラスのnn.Moduleの設定によって、これで.forward()が呼び出される
Z.shape # -> torch.Size([5, 10])
2. nn.<class>のみで構成する
# 2. nn.クラスのみで構成するケース
class MLP(nn.Module):
def __init__(self, num_in, num_hidden, num_out):
super().__init__()
self.l1 = nn.Linear(num_in, num_hidden)
self.l2 = nn.Linear(num_hidden, num_out)
self.relu = nn.ReLU()
def forward(self, x):
x = self.l2(self.relu(self.l1(x)))
return x
# 順伝搬テスト
model = MLP(64, 30, 10)
X = torch.randn(5, 64)
Z = model(X)
Z.shape # -> torch.Size([5, 10])
3. nn.Sequenbalを使う
# 3. nn.Sequentialを使ったケース
num_in = 64
num_hidden = 30
num_out = 10
model = nn.Sequential(
nn.Linear(num_in, num_hidden),
nn.ReLU(),
nn.Linear(num_hidden, num_out)
)
# 順伝搬テスト
Z = model(X)
Z.shape # -> torch.Size([5, 10])
nnモジュールを使って今までの学習コードを修正した例
# nn.Moduleを使ったMLPモデル
class MLP(nn.Module):
def __init__(self, num_in, num_hidden, num_out):
super().__init__()
self.l1 = nn.Linear(num_in, num_hidden)
self.l2 = nn.Linear(num_hidden, num_out)
def forward(self, x):
x = self.l2(F.relu(self.l1(x)))
return x
## Refactoring後の学習ループ(OptimizerやDataset, Dataloaderは後ほどRefactoring)
# ===データの準備====
dataset = datasets.load_digits()
data = dataset['data']
target = dataset['target']
images = dataset['images']
X_train, X_val, y_train, y_val = train_test_split(images, target, test_size=0.2, random_state=42)
X_train_mean = X_train.mean()
X_train_std = X_train.std()
X_train = (X_train - X_train_mean) / X_train_std
X_val = (X_val - X_train_mean) / X_train_std
X_train = torch.tensor(X_train.reshape(-1, 64), dtype=torch.float32)
X_val = torch.tensor(X_val.reshape(-1, 64), dtype=torch.float32)
y_train = torch.tensor(y_train)
y_val = torch.tensor(y_val)
batch_size = 30
num_batches = np.ceil(len(y_train)/batch_size).astype(int)
learning_rate = 0.03
# モデルの初期化
model = MLP(64, 30, 10)
# ログ
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(100):
# エポック毎にデータをシャッフル
shuffled_indices = np.random.permutation(len(y_train))
running_loss = 0.0
for i in range(num_batches):
# mini batch作成
start = i * batch_size
end = start + batch_size
batch_indices = shuffled_indices[start:end]
y = y_train[batch_indices] # batch_size x 10
X = X_train[batch_indices] # batch_size x 64
# 順伝播と逆伝播の計算
preds = model(X)
loss = F.cross_entropy(preds, y)
loss.backward()
running_loss += loss.item()
# パラメータ更新
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
model.zero_grad()
# validation
with torch.no_grad():
preds_val = model(X_val)
val_loss = F.cross_entropy(preds_val, y_val)
val_accuracy = torch.sum(torch.argmax(preds_val, dim=-1) == y_val) / y_val.shape[0]
train_losses.append(running_loss/num_batches)
val_losses.append(val_loss.item())
val_accuracies.append(val_accuracy)
# print(f'epoch: {epoch}: train error: {running_loss/num_batches}, validation error: {val_loss.item()}, validation accuracy: {val_accuracy}')
# 描画
plt.plot(train_losses)
plt.plot(val_losses)
▶モジュールやパラメータのイテレーション
-
nn.Moduleを継承したモデルのクラスには、各コンポーネントやパラメータをイテレーションする機能が実装されている-
.parameters()/.named_parameters(): パラメータのイテレーション -
.children()/.named_children(): 直接の子のモジュールのイテレーション -
.modules()/.named_modules(): 自分自身を含む全てのモジュールのイテレーション
※.named_のほうはそのモジュールやパラメータの名前も返してくれる
-
■Optimizer
▶Optimizerクラス
- パラメータの更新部分をOptimizerクラスにまとめることが一般的
- 学習の対象となるparamertersおよびlr(学習率)をインスタンスの引数に渡す
- step()メソッドにて各パラメータを更新する処理を記述する
- zero_grad()メソッドにて各パラメータの勾配をゼロにする処理を記述する
※コードで言うと下記部分
# パラメータ更新
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
model.zero_grad()
Optimizerクラスの実装
# Optimazerクラス
class Optimizer():
# prametersはジェネレータを受け取る -> 初期化例:x = Optimazer(model.paramaters(), lr)
def __init__(self, parameters, lr=0.03):
self.parameters = list(parameters)
self.lr = lr
def step(self):
with torch.no_grad():
for param in self.parameters:
param -= self.lr * param.grad
def zero_grad(self):
for param in self.parameters:
if param.grad is not None:
param.grad.zero_()
MLPコードに組み込み
import torch
from torch import nn
from torch.nn import functional as F
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import numpy as np
class MLP(nn.Module):
def __init__(self, num_in, num_hidden, num_out):
super().__init__()
self.l1 = nn.Linear(num_in, num_hidden)
self.l2 = nn.Linear(num_hidden, num_out)
def forward(self, x):
x = self.l2(F.relu(self.l1(x)))
return x
class Optimizer():
def __init__(self, parameters, lr=0.03):
self.parameters = list(parameters)
self.lr = lr
def step(self):
with torch.no_grad():
for param in self.parameters:
param -= self.lr * param.grad
def zero_grad(self):
for param in self.parameters:
if param.grad is not None:
param.grad.zero_()
# クラスの初期化
model = MLP(64, 30, 10)
learning_rate = 0.01
opt = Optimizer(parameters=model.parameters(), lr=learning_rate)
## Refactoring後の学習ループ(Dataset, Dataloaderは後ほどRefactoring)
# ===データの準備====
dataset = datasets.load_digits()
data = dataset['data']
target = dataset['target']
images = dataset['images']
X_train, X_val, y_train, y_val = train_test_split(images, target, test_size=0.2, random_state=42)
X_train_mean = X_train.mean()
X_train_std = X_train.std()
X_train = (X_train - X_train_mean) / X_train_std
X_val = (X_val - X_train_mean) / X_train_std
X_train = torch.tensor(X_train.reshape(-1, 64), dtype=torch.float32)
X_val = torch.tensor(X_val.reshape(-1, 64), dtype=torch.float32)
y_train = torch.tensor(y_train)
y_val = torch.tensor(y_val)
batch_size = 30
num_batches = np.ceil(len(y_train)/batch_size).astype(int)
# ログ
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(100):
# エポック毎にデータをシャッフル
shuffled_indices = np.random.permutation(len(y_train))
running_loss = 0.0
for i in range(num_batches):
# mini batch作成
start = i * batch_size
end = start + batch_size
batch_indices = shuffled_indices[start:end]
y = y_train[batch_indices] # batch_size x 10
X = X_train[batch_indices] # batch_size x 64
# 順伝播と逆伝播の計算
preds = model(X)
loss = F.cross_entropy(preds, y)
loss.backward()
running_loss += loss.item()
# パラメータ更新:Optimazerクラスに移動
# with torch.no_grad():
# for param in model.parameters():
# param -= learning_rate * param.grad
# model.zero_grad()
# パラメータ更新
opt.step()
opt.zero_grad()
# validation
with torch.no_grad():
preds_val = model(X_val)
val_loss = F.cross_entropy(preds_val, y_val)
val_accuracy = torch.sum(torch.argmax(preds_val, dim=-1) == y_val) / y_val.shape[0]
train_losses.append(running_loss/num_batches)
val_losses.append(val_loss.item())
val_accuracies.append(val_accuracy)
# print(f'epoch: {epoch}: train error: {running_loss/num_batches}, validation error: {val_loss.item()}, validation accuracy: {val_accuracy}')
▶PytorchのOptimazer(torch.optim)
- NNモデルのパラメータ更新の際の様々な最適化アルゴリズムを提供
- 勾配降下法を使用してモデルのパラメータを更新し,損失を最小化してくれる
- 以下のようなOpbmizerが実装されている
-
torch.opbm.SGD:最もオーソドックス、上でスクラッチ実装したものと似たイメージ torch.opbm.Momentumtorch.opbm.RMSProptorch.opbm.Adam
-
- モデルのパラメータ(
model.parameters())と,学習率(lr)を渡してインスタンスを生成 -
.step()でパラメータを更新 -
.zero_grad()でパラメータの勾配をNoneにリセット
■DatasetとDataLoader
- Pytorchにおいて、データを読み込んだり前処理を効率的に行うための仕組み
(※MPLコードで長々と書いている「==データ準備==」の部分)
▶Dataset
torch.utils.data.Dataset- pytorchには既にいくつものDatasetが用意されている
- カスタムで作ることも可能
-
torch.utils.data.Datasetを継承する -
__len__と__geDtem__をオーバーライドする
-
torchvision.datasets(例:MNIST)
-
torchvision.datasetsにさまざまなDatasetがあり,全てtorch.ubls.data.Datasetを継承している -
torchvision.datasets.MNISTクラスでインスタンスを生成-
root:データを保存するディレクトリを指定 -
train:Trueなら学習データを,Falseならテストデータをロード -
download:Trueなら,rootに指定したディレクトリにダウンロードし,既にデータがある場合はそのデータを使用する
-
- []でindexingによりデータとラベルをtuple形式で取得する
- データはPIL(Pillow)で返ってくるので,tensorにtransformが必要
import sys
import torchvision
import torch
from torchvision import transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from torch import optim, nn
from torch.nn import functional as F
from torch.utils.data import Dataset
from sklearn import datasets
from sklearn.model_selection import train_test_split
# datasetsモジュールに様々なデータセットがある:https://pytorch.org/vision/stable/datasets.html
train_dataset = torchvision.datasets.MNIST('./mnist_data', train=True, download=True)
# 変数にデータが格納されているわけではない、呼び出し毎にデータはロードする
sys.getsizeof(train_dataset) # -> 48 48byteしかデータを持っていない
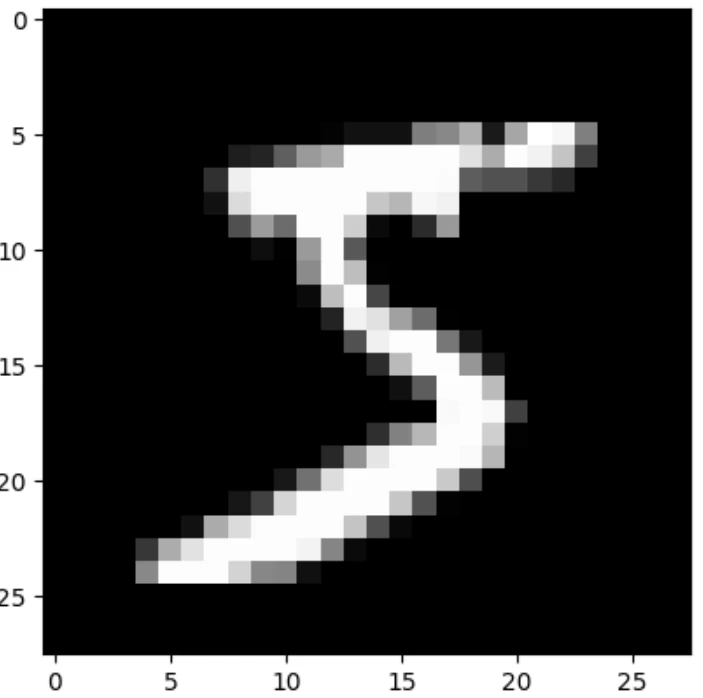
image, label = train_dataset[0]
print(label) # -> 5
len(train_dataset) # -> 60000
image # そのままだとPIL、JupyterNoteBookなので描画される

# 描画
plt.imshow(image, cmap='gray')
▶Transform(前処理:PIL→tensor、標準化)
-
torchvision.transforms:画像関連で使用する便利な変換機能を提供-
.ToTensor():[0, 255]の(H, W, C)のPILやNumpyArrayをtensorに変換するクラス- インスタンスを生成しPIL形式のデータを渡して呼び出す
- 変換後は[0., 1.]の(C, H, W)のtensorとなる
-
.Normalize():平均と標準偏差を使って画像データを標準化する-
mean:それぞれのchannelのmeanをtupleで渡す -
std:それぞれのchannelのstdをtupleで渡す - 正規化として使われることが多い (0~1 -> -1~1)
-
-
.Compose():複数のtransformをまとめる- 複数のtransformsのインスタンスをリストにして渡す
-
datasets.<クラス名>のtransform引数に渡すことで、データをロードする際に変換処理を行ってくれる
-
from torchvision import transforms
# .ToTensor()
# PIL (もしくはNumpy Array)をTensorに変換する(スケールも0~1になる)
# tramsform_tensor = transforms.ToTensor()
# image_tensor = tramsform_tensor(image)
image_tensor = transforms.ToTensor()(image) # 上2行をまとめて書いてもいい
# .Normalize()
# 0.5を引いて0.5で割ることで、0~1を-1~1にする
# -1 ~ 1にする。平均を0にすることで、学習の効率を上げる
# transform_normalize = transforms.Normalize((0.5,), (0.5,))
# normalized_image_tensor = transform_normalize(image_tensor)
normalized_image_tensor = transforms.Normalize((0.5,), (0.5,))(image_tensor) # 上2行をまとめて書いてもいい
# Composeを使うことで、複数のTransformを直列にしまとめてくれる。これをDatasetのインスタンス生成時に指定する
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
transformed_image = transform(image)
# datasetのtransform引数に入れて使用する
train_dataset = torchvision.datasets.MNIST('./mnist_data', train=True, download=True, transform=transform)
val_dataset = torchvision.datasets.MNIST('./mnist_data', train=False, download=True, transform=transform)
▶Dataloader
torch.utils.data.DataLoader- Datasetからバッチ単位でデータを効率的に読み込むためのイテレータを提供
- 複数のCPUスレッドによる並列処理に対応
複数のCPUスレッドによる並列処理とは
深層学習において、学習部分についてはGPUでの高速処理が可能だが、データのロードはCPUが行う。
そのため、「学習は完了しているがデータロードが完了していないので学習が進まない」ということが起こりえる。
そのような事態は避けたいので、データロードも並列処理で高速化することが必要となってくる。
DatasetからDataLoaderを作成
-
torch.ubls.data.DataLoaderクラスでインスタンスを生成-
dataset:ロード対象となるDatasetオブジェクトを指定 -
batch_size:ミニバッチ学習におけるバッチサイズ -
shuffle:Trueの場合,各epochでシャッフルする
※検証データの場合,shuffleは不要(False) -
num_workers:データロードに使用するスレッドの数
-
# DatasetからDataLoaderを作る
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, num_workers=2) # validationにはshuffleは不要だが、可読性やメモリを考えてbatch_sizeは指定する
# DataLoaderからデータ取得&描画
images, labels = next(iter(train_loader))
# [batch, ch, h, w]になっている
print(images.shape) # -> torch.Size([32, 1, 28, 28])
# 描画
# gridで描画しやすい形に変換できる
grid_images = torchvision.utils.make_grid(images)
# unnormalize
grid_images = grid_images / 2 + 0.5
plt.imshow(torch.permute(grid_images, (1, 2, 0)))

MLPコードに組み込み
# 入力が[batch, ch, h, w]なので,[batch, chzhxw]にするためにnn.Flatten()を追加
class MLP(nn.Module):
def __init__(self, num_in, num_hidden, num_out):
super().__init__()
self.flatten = nn.Flatten() # [b, c, h, w] -> [b, c x h x w]
self.l1 = nn.Linear(num_in, num_hidden)
self.l2 = nn.Linear(num_hidden, num_out)
def forward(self, x):
x = self.l2(F.relu(self.l1(self.flatten(x))))
return x
# transforms作成
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# クラスの初期化
learning_rate = 0.01
model = MLP(28*28, 30, 10)
opt = optim.SGD(model.parameters(), lr=learning_rate)
# ===データの準備====
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, num_workers=2)
# ログ
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(5):
running_loss = 0.0
running_val_loss = 0.0
running_val_acc = 0.0
for train_batch, data in enumerate(train_loader):
X, y = data
opt.zero_grad()
# forward
preds = model(X)
loss = F.cross_entropy(preds, y)
running_loss += loss.item()
# backward
loss.backward()
opt.step()
# validation
with torch.no_grad():
for val_batch, data in enumerate(val_loader):
X_val, y_val = data
preds_val = model(X_val)
val_loss = F.cross_entropy(preds_val, y_val)
running_val_loss += val_loss.item()
val_accuracy = torch.sum(torch.argmax(preds_val, dim=-1) == y_val) / y_val.shape[0]
running_val_acc += val_accuracy.item()
train_losses.append(running_loss/(train_batch + 1))
val_losses.append(running_val_loss/(val_batch + 1))
val_accuracies.append(running_val_acc/(val_batch + 1))
# print(f'epoch: {epoch}: train error: {train_losses[-1]}, validation error: {val_losses[-1]}, validation accuracy: {val_accuracies[-1]}')
# 描画
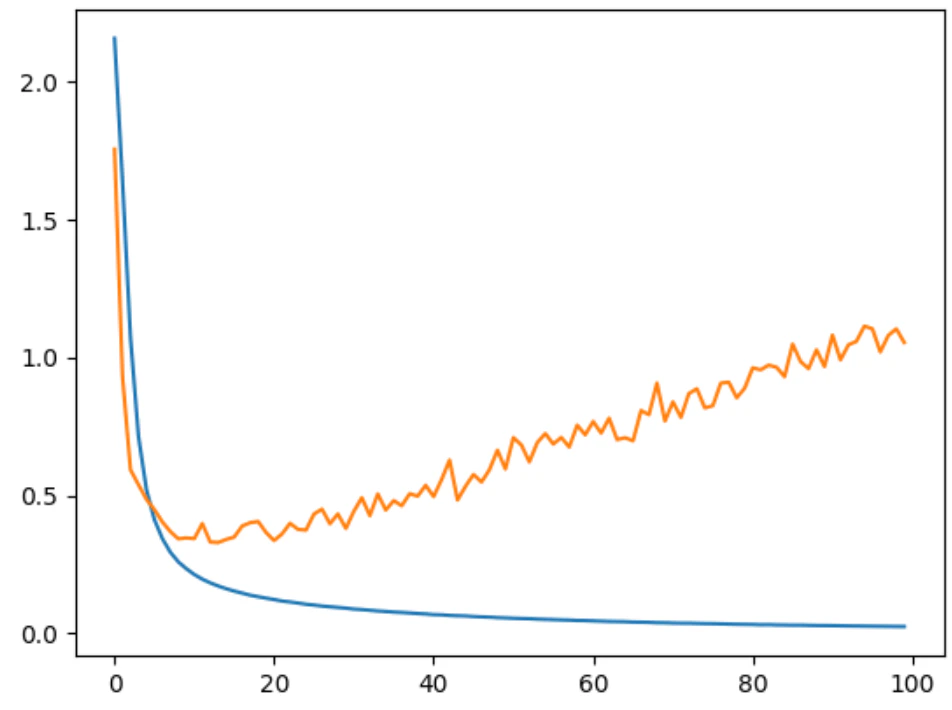
plt.plot(train_losses)
plt.plot(val_losses)
※5epochしか回していないので、まだ学習途中のようなグラフになっている
▶カスタムDataset作成
-
torch.ubls.data.Datasetクラスを継承する -
__len__メソッドおよび__getitem__をオーバーライドする -
transformを引数で受け取り,データに対して変換できるようにする
"""
本来は下記のような実装だとすべてのデータがメモリに載ってしまうので、重いデータだと使用できないことが多い
なので、「self.X = X」でデータを受け取るのではなく、pathを受け取り__getitem__()でデータを取得するような実装にするのがベター
"""
class MyDataset(Dataset): # Datasetクラスを継承する
def __init__(self, X, y, transform=None):
self.X = X
self.y = y
self.transform = transform
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
X = self.X[idx]
y = self.y[idx]
if self.transform:
X = self.transform(X)
return X, y
# データ準備
dataset = datasets.load_digits()
target = dataset['target']
images = dataset['images']
# ToTensorを使うため,0~255にする
images = images * (255. / 16.) # 0~16 -> 0~255
images = images.astype(np.uint8)
X_train, X_val, y_train, y_val = train_test_split(images, target, test_size=0.2, random_state=42)
# クラスの初期化
train_mydataset = MyDataset(X_train, y_train)
# __len__
len(train_mydataset) # -> 1437
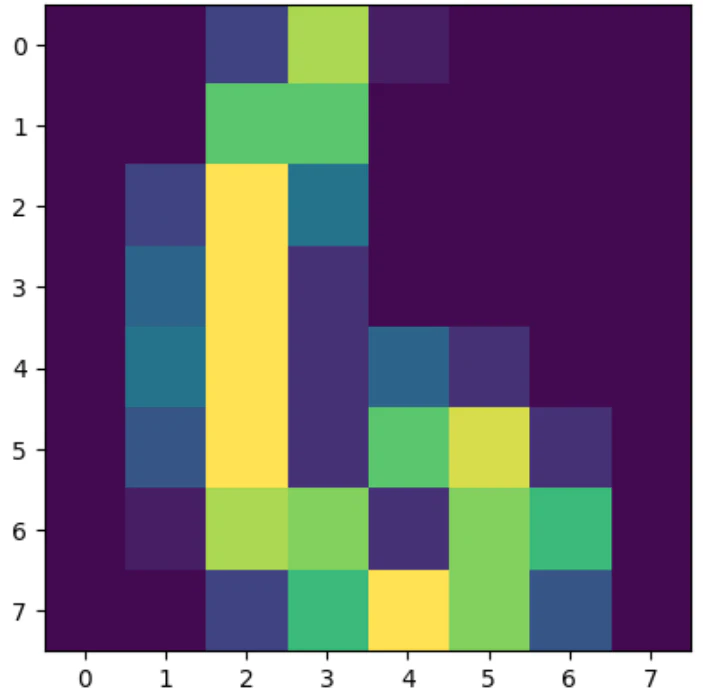
# __getitem__
image, label = train_mydataset[0]
# データ可視化
plt.imshow(image)
# transform
transform = transforms.Compose([
transforms.ToTensor(), # 0~255 -> 0~1
transforms.Normalize((.5, ), (.5, )) # 0~1 -> -1~1
])
train_mydataset = MyDataset(X_train, y_train, transform=transform)
val_mydataset = MyDataset(X_val, y_val, transform=transform)
# DataLoader
train_myloader = DataLoader(train_mydataset, batch_size=10, shuffle=True, num_workers=2)
val_myloader = DataLoader(val_mydataset, batch_size=10, num_workers=2)
images, labels = next(iter(train_myloader))
# 描画
grid_images = torchvision.utils.make_grid(images)
grid_images = grid_images / 2 + 0.5
plt.imshow(torch.permute(grid_images, (1, 2, 0)))
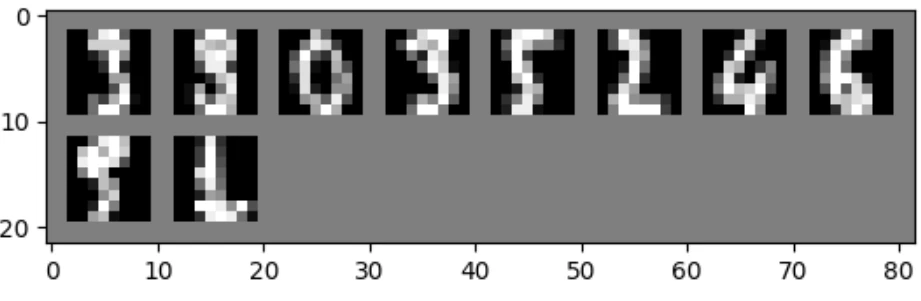
※カスタムDatasetでも同様の動きを再現できるということがわかる
■モデルの保存とロード
- 学習が完了したモデルを保存することで、他の環境で使用したり、実用化、他人への共有などが可能になる
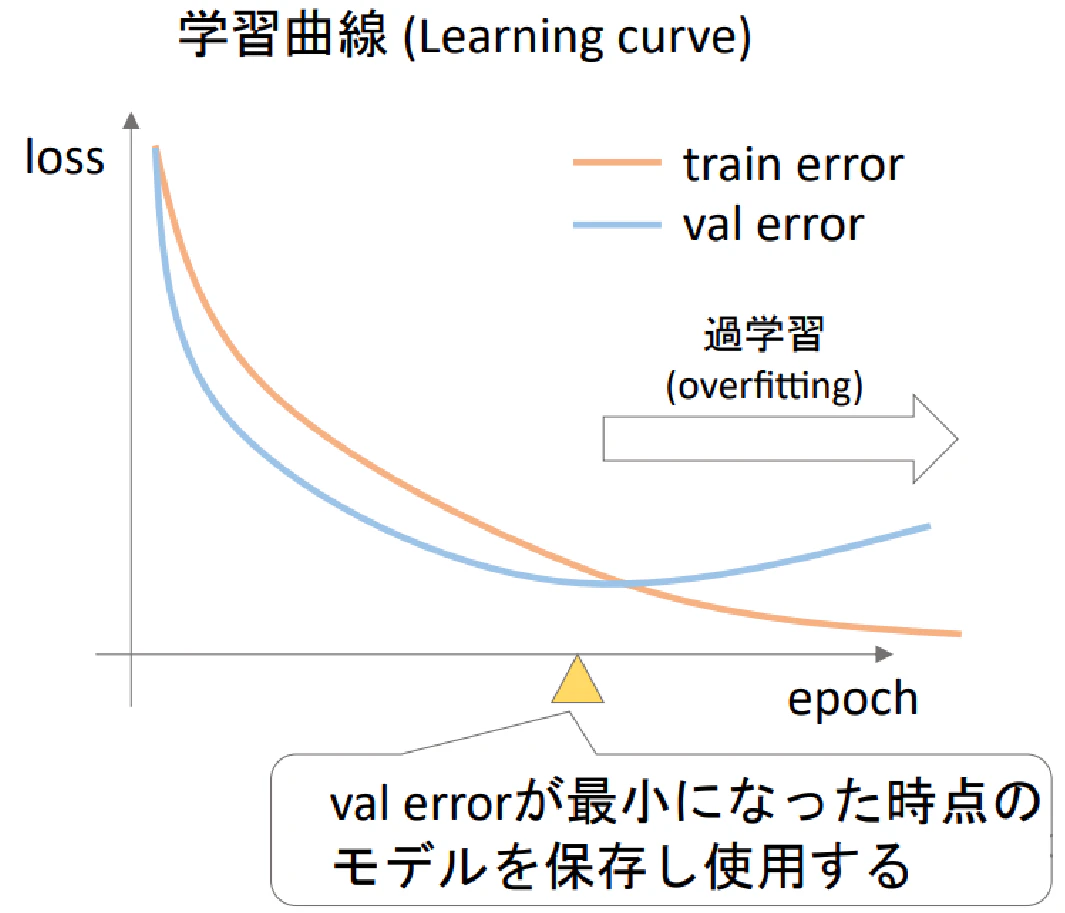
- 学習曲線において最も損失が小さいモデルを保存する
- early stopping:一定epoch損失がさがらなければ学習を終える
▶Early Stopping
- 学習を途中で止め,過学習を防ぐ正則化手法の一つ
- 各epochの終了時に学習データと検証データの両方で評価し,検証データにおける損失が一定epoch減少しなかったら学習ループをストップする
- 今までのMLPコードにEarly Stoppingを実装すると下記のような例となる
import torchvision
import torch
from torchvision import transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from torch import optim, nn
from torch.nn import functional as F
from torch.utils.data import Dataset
from sklearn import datasets
from sklearn.model_selection import train_test_split
class MyDataset(Dataset):
def __init__(self, X, y, transform=None):
self.X = X
self.y = y
self.transform = transform
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
X = self.X[idx]
y = self.y[idx]
if self.transform:
X = self.transform(X)
return X, y
class MLP(nn.Module):
def __init__(self, num_in, num_hidden, num_out):
super().__init__()
self.flatten = nn.Flatten() # [b, c, h, w] -> [b, cxhxw]
self.l1 = nn.Linear(num_in, num_hidden)
self.l2 = nn.Linear(num_hidden, num_out)
def forward(self, x):
x = self.l2(F.relu(self.l1(self.flatten(x))))
return x
# 学習ループを関数化、early_stopping=NoneならEarly Stoppingは実施しない
def learn(model, train_loader, val_loader, optimizer, loss_func, num_epoch, early_stopping=None):
# ログ
train_losses = []
val_losses = []
val_accuracies = []
# 最初の損失に無限を指定することで、どのような値でも1回目の学習の損失は初期値より低くなり、更新される
best_val_loss = float('inf')
no_improve = 0 # カウント用変数
for epoch in range(num_epoch):
running_loss = 0.0
running_val_loss = 0.0
running_val_acc = 0.0
for train_batch, data in enumerate(train_loader):
X, y = data
optimizer.zero_grad()
# forward
preds = model(X)
loss = loss_func(preds, y)
running_loss += loss.item()
# backward
loss.backward()
optimizer.step()
# validation
with torch.no_grad():
for val_batch, data in enumerate(val_loader):
X_val, y_val = data
preds_val = model(X_val)
val_loss = loss_func(preds_val, y_val)
running_val_loss += val_loss.item()
val_accuracy = torch.sum(torch.argmax(preds_val, dim=-1) == y_val) / y_val.shape[0]
running_val_acc += val_accuracy.item()
train_losses.append(running_loss/(train_batch + 1))
val_losses.append(running_val_loss/(val_batch + 1))
val_accuracies.append(running_val_acc/(val_batch + 1))
# print(f'epoch: {epoch}: train error: {train_losses[-1]}, validation error: {val_losses[-1]}, validation accuracy: {val_accuracies[-1]}')
# 損失が下がっているかの確認
if val_losses[-1] < best_val_loss:
best_val_loss = val_losses[-1]
no_improve = 0
else:
no_improve += 1
# Early Stopping
if early_stopping and no_improve >= early_stopping:
print('Stopping early')
break
return train_losses, val_losses, val_accuracies
# ===コード実行===
# データロード
dataset = datasets.load_digits()
target = dataset['target']
images = dataset['images']
images = images * (255. / 16.) # 0~16 -> 0~255
images = images.astype(np.uint8)
# 学習データと検証データ作成
X_train, X_val, y_train, y_val = train_test_split(images, target, test_size=0.2, random_state=42)
# DatasetとDataLoader作成
transform = transforms.Compose([
transforms.ToTensor(),# 0~255 -> 0~1
transforms.Normalize((.5, ), (.5, )) # 0~1 -> -1~1
])
batch_size = 32
train_dataset = MyDataset(X_train, y_train, transform=transform)
val_dataset = MyDataset(X_val, y_val, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, num_workers=2)
early_stopping = 5 # ここで指定した回数損失が下がらなければStoppingする
## Refactoring後の学習ループ
learning_rate = 0.1
model = MLP(64, 30, 10)
opt = optim.SGD(model.parameters(), lr=learning_rate)
num_epoch = 100
train_losses, val_losses, val_accuracies = learn(model, train_loader, val_loader, opt, F.cross_entropy, num_epoch, early_stopping=5)
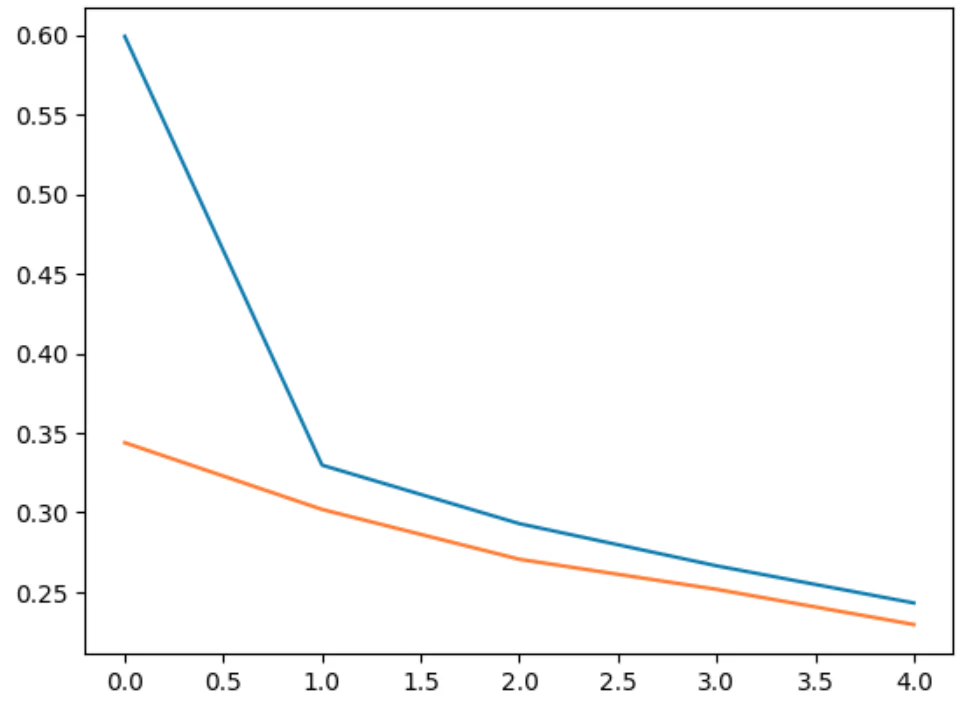
# 描画
plt.plot(train_losses)
plt.plot(val_losses)
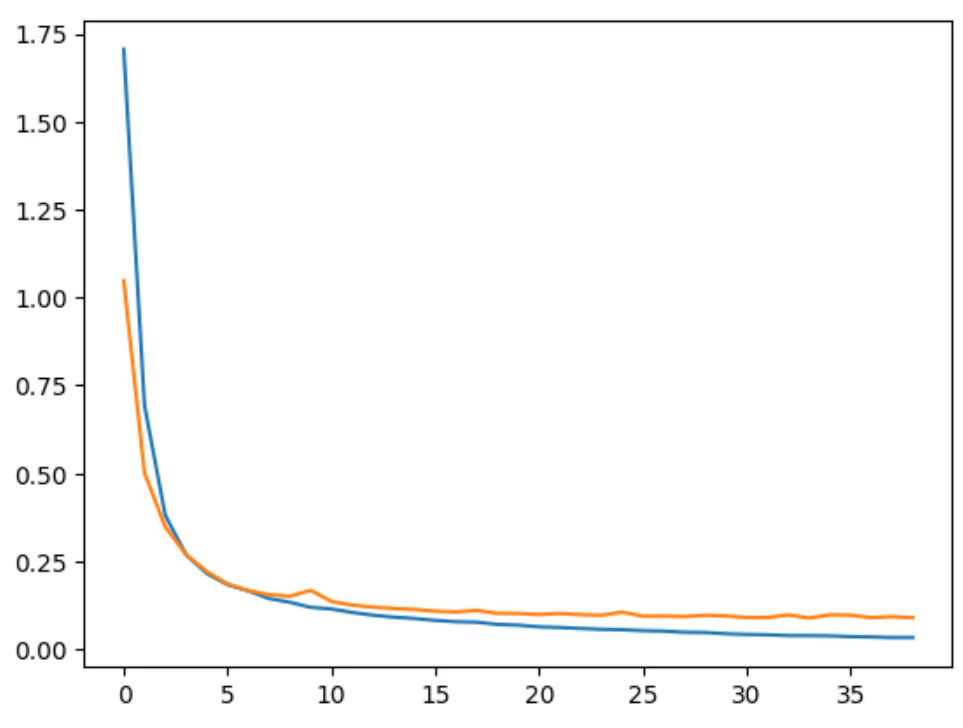
※40epochあたりでStoppingしているのがわかる
▶モデルオブジェクトの保存/ロード
-
torch.save():モデルを指定したパスに保存する-
obj:保存するモデルオブジェクト -
f:保存するモデルのファイル名やパス
-
-
torch.load():指定したパスからモデルをロードする-
f:ロードするモデルのファイル名やパス
-
- 拡張子に
.pthを使う慣習がある - 保存後にコードを変更した場合や、異なる環境でロードした際に予期しない問題が起こる可能性があることに注意
# 上で学習したモデルを保存/ロードしてみる
torch.save(model, 'sample_model.pth')
loaded_model = torch.load('sample_model.pth')
loaded_model
""" 出力 ->
MLP(
(flatten): Flatten(start_dim=1, end_dim=-1)
(l1): Linear(in_features=64, out_features=30, bias=True)
(l2): Linear(in_features=30, out_features=10, bias=True)
)
"""
▶モデルパラメータの保存/ロード
- 一般的に、オブジェクトごとの保存/ロードするより推奨される
-
.state_dict()でモデルのパラメータの情報のみを取り出す - パラメータのみを切り出して保存することで、パラメータに関連するコード以外が変更されてもロードし使用することができる
- Opbmizerについて同様にパラメータを保存することができる
# パラメータの保存例
torch.save(model.state_dict(), 'model_state_dict.pth')
# パラメータのロード例
model = TheModelClass(*args, **kwargs) # まずモデルのインスタンスを作成
model.load_state_dict(torch.load('model_state_dict.pth'))
MLPコードへの組み込み
- 以下条件で最もvalidabon lossが低いモデルを保存する
- モデルのパラメータ, Opbmizerのパラメータ, 当該epochにおけるvalidabonlossをdicbonary形式で保存する
- save_path引数で保存先のパスを受け取る(Noneであれば保存しない)
# モデル保存付き
def learn(model, train_loader, val_loader, optimizer, loss_func, num_epoch, early_stopping=None, save_path=None):
# ログ
train_losses = []
val_losses = []
val_accuracies = []
best_val_loss = float('inf')
no_improve = 0 # カウント用変数
for epoch in range(num_epoch):
running_loss = 0.0
running_val_loss = 0.0
running_val_acc = 0.0
for train_batch, data in enumerate(train_loader):
X, y = data
optimizer.zero_grad()
# forward
preds = model(X)
loss = loss_func(preds, y)
running_loss += loss.item()
# backward
loss.backward()
optimizer.step()
# validation
with torch.no_grad():
for val_batch, data in enumerate(val_loader):
X_val, y_val = data
preds_val = model(X_val)
val_loss = loss_func(preds_val, y_val)
running_val_loss += val_loss.item()
val_accuracy = torch.sum(torch.argmax(preds_val, dim=-1) == y_val) / y_val.shape[0]
running_val_acc += val_accuracy.item()
train_losses.append(running_loss/(train_batch + 1))
val_losses.append(running_val_loss/(val_batch + 1))
val_accuracies.append(running_val_acc/(val_batch + 1))
# print(f'epoch: {epoch}: train error: {train_losses[-1]}, validation error: {val_losses[-1]}, validation accuracy: {val_accuracies[-1]}')
# 損失が減少しているか確認
if val_losses[-1] < best_val_loss:
best_val_loss = val_losses[-1]
no_improve = 0
# パラメータの保存
if save_path is not None:
state = {
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'val_loss': val_losses[-1]
}
torch.save(state, save_path)
else:
no_improve += 1
# Early Stopping
if early_stopping and no_improve >= early_stopping:
print('Stopping early')
break
return train_losses, val_losses, val_accuracies
# コード実行(データ準備の一部省略)
model = MLP(64, 30, 10)
opt = optim.SGD(model.parameters(), lr=learning_rate)
train_losses, val_losses, val_accuracies = learn(model, train_loader, val_loader, opt, F.cross_entropy, num_epoch, early_stopping=5, save_path='checkpoint')
# ロード
# state = torch.load('checkpoint')
# model.load_state_dict(state['model_state_dict'])
# opt.load_state_dict(state['optimizer_state_dict'])
■Learing rate finderとLearnig rate scheduler
▶Learnig rate finder
- 学習率は深層学習において最も重要なハイパーパラメータの一つで、モデル学習の速度や過学習にかかわってくる
- 適当な値では効率が悪いので、Learning Rate Finderを使って学習率の初期値の目安を探す必要がある
- 非常に小さい値(例:1e-8)を学習率に設定する
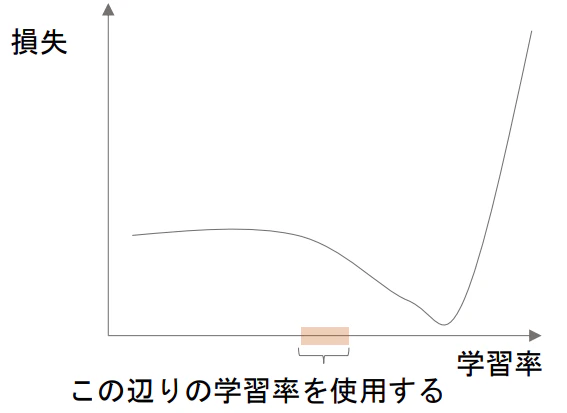
- 各ミニバッチの学習毎に徐々に(log scaleで)学習率を大きくする
- ある程度大きくなると、損失が急激に上昇し始める(適切な学習率の上限)
- 損失が最も早く改善されている範囲を見つける(ここが良い学習率の範囲とされる)
スクラッチでLearing rate finderを実装
- PytorchにはLearning rate finderは実装されていないので自分で用意する必要がある
- 学習率=1e-8からはじめ、log scaleでミニバッチ毎に学習率を増加する
- 横軸:学習率(log scale)、縦軸:損失のグラフを描画する
- 学習データ、モデル等は問わない
- モデル、train data loader、損失関数、学習率の増加係数を引数にする
事前準備
import torchvision
import torch
from torchvision import transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from torch import optim, nn
from torch.nn import functional as F
from torch.utils.data import Dataset
from sklearn import datasets
from sklearn.model_selection import train_test_split
from torch.optim.lr_scheduler import StepLR, CosineAnnealingLR
class MyDataset(Dataset):
def __init__(self, X, y, transform=None):
self.X = X
self.y = y
self.transform = transform
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
X = self.X[idx]
y = self.y[idx]
if self.transform:
X = self.transform(X)
return X, y
class MLP(nn.Module):
def __init__(self, num_in, num_hidden, num_out):
super().__init__()
self.flatten = nn.Flatten() # [b, c, h, w] -> [b, cxhxw]
self.l1 = nn.Linear(num_in, num_hidden)
self.l2 = nn.Linear(num_hidden, num_out)
def forward(self, x):
x = self.l2(F.relu(self.l1(self.flatten(x))))
return x
def learn(model, train_loader, val_loader, optimizer, loss_func, num_epoch, early_stopping=None, save_path=None):
# ログ
train_losses = []
val_losses = []
val_accuracies = []
best_val_loss = float('inf')
no_improve = 0 # カウント用変数
for epoch in range(num_epoch):
running_loss = 0.0
running_val_loss = 0.0
running_val_acc = 0.0
for train_batch, data in enumerate(train_loader):
X, y = data
optimizer.zero_grad()
# forward
preds = model(X)
loss = loss_func(preds, y)
running_loss += loss.item()
# backward
loss.backward()
optimizer.step()
# validation
with torch.no_grad():
for val_batch, data in enumerate(val_loader):
X_val, y_val = data
preds_val = model(X_val)
val_loss = loss_func(preds_val, y_val)
running_val_loss += val_loss.item()
val_accuracy = torch.sum(torch.argmax(preds_val, dim=-1) == y_val) / y_val.shape[0]
running_val_acc += val_accuracy.item()
train_losses.append(running_loss/(train_batch + 1))
val_losses.append(running_val_loss/(val_batch + 1))
val_accuracies.append(running_val_acc/(val_batch + 1))
# print(f'epoch: {epoch}: train error: {train_losses[-1]}, validation error: {val_losses[-1]}, validation accuracy: {val_accuracies[-1]}')
if val_losses[-1] < best_val_loss:
best_val_loss = val_losses[-1]
no_improve = 0
if save_path is not None:
state = {
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'val_loss': val_losses[-1]
}
torch.save(state, save_path)
else:
no_improve += 1
if early_stopping and no_improve >= early_stopping:
print('Stopping early')
break
return train_losses, val_losses, val_accuracies
# データロード
dataset = datasets.load_digits()
target = dataset['target']
images = dataset['images']
images = images * (255. / 16.) # 0~16 -> 0~255
images = images.astype(np.uint8)
# 学習データと検証データ作成
X_train, X_val, y_train, y_val = train_test_split(images, target, test_size=0.2, random_state=42)
# DatasetとDataLoader作成
transform = transforms.Compose([
transforms.ToTensor(),# 0~255 -> 0~1
transforms.Normalize((.5, ), (.5, )) # 0~1 -> -1~1
])
batch_size = 10
train_dataset = MyDataset(X_train, y_train, transform=transform)
val_dataset = MyDataset(X_val, y_val, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, num_workers=2)
early_stopping = 5
## Refactoring後の学習ループ
learning_rate = 0.1
model = MLP(64, 30, 10)
opt = optim.SGD(model.parameters(), lr=learning_rate)
num_epoch = 100
# train_losses, val_losses, val_accuracies = learn(model, train_loader, val_loader, opt, F.cross_entropy, num_epoch, early_stopping=5)
# optimizerの.param_groupsの中に様々なパラメータが保持されていて,learning rateもここに格納されている
for param_group in opt.param_groups:
param_group['lr'] *= 1.1
# opt.param_groups
def lr_finder(model, train_loader, loss_func, lr_multiplier=1.2):
lr = 1e-8
max_lr = 10
opt = torch.optim.SGD(model.parameters(), lr=lr)
losses = []
lrs = []
for train_batch, data in enumerate(train_loader):
X, y = data
opt.zero_grad()
# forward
preds = model(X)
loss = loss_func(preds, y)
losses.append(loss.item())
lrs.append(lr)
# backward
loss.backward()
opt.step()
# 学習率の更新
lr *= lr_multiplier
# optimizer内のlearning rateを更新する
for param_group in opt.param_groups:
param_group['lr'] = lr
# 大きくなりすぎないように上限を設置
if lr > max_lr:
break
return lrs, losses
lrs, losses = lr_finder(model, train_loader, F.cross_entropy, lr_multiplier=1.2)
# 描画
plt.plot(lrs, losses)
plt.xscale('log')
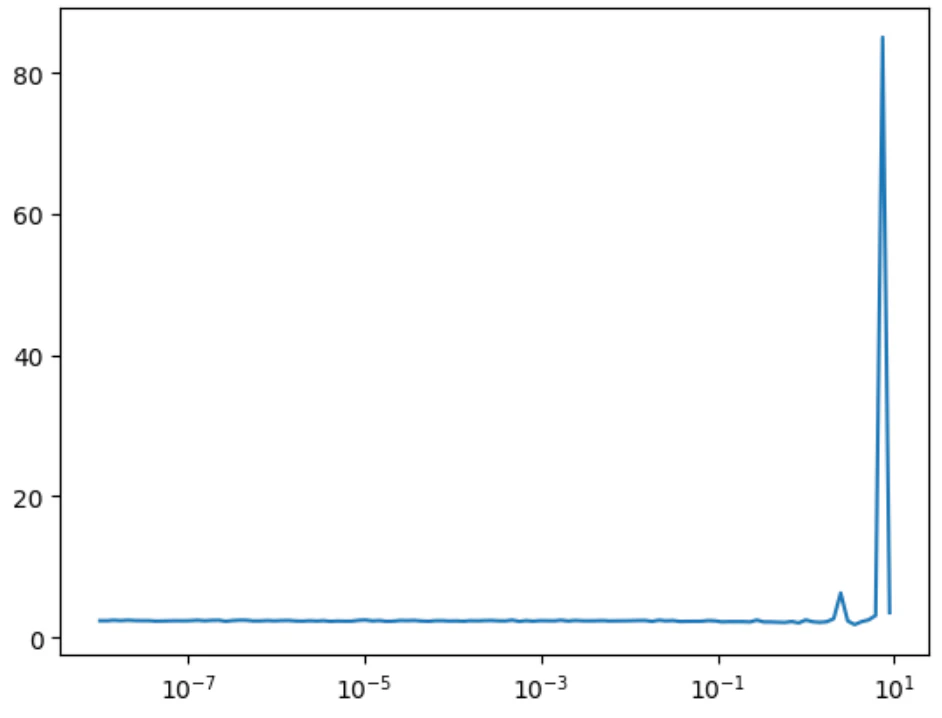
※少しわかりにくいがおそらく0.1~1.0の間で設定すれば良さそうなのがわかる
▶Learnig rate scheduler
- 深層学習のモデル学習中に学習率を動的に調整する手法で、局所解に陥る問題を緩和する
- 学習初期には学習率を高めにして広範囲に探索し、最適解の近くにきたら徐々に学習率を小さくして精度を高くする等
Learnig rate schedulerの種類の一部
- StepLR:指定したepoch数毎に学習率を減少
- MulbStepLR:指定した複数のepochで学習率を減少
- ExponenbalLR:epoch毎に指数関数的に減少
- CosineAnnealingLR:コサイン曲線に従って徐々に減少
-
CyclicLR:周期的に学習率を変動
- 局所解にトラップされることを防ぐ
- CosineAnnealingWarmRestarts:学習中に学習率を初期化するwarm restartsを伴いながらCosine Annealingで学習率を変動
PythonでLearnig rate scheduler
-
torch.optim.lr_schedulerにて様々なschedulerを提供- インスタンスを生成
- 第一引数にopbmizerオブジェクトを渡す
- その他のパラメータを引数に渡す
-
.step()メソッドで,optimizerのlearning rateを更新する
- インスタンスを生成
- StepLR
-
opbmizer:optimizerオブジェクト -
step_size:学習率を減少させるstep数 -
gamma:学習率の減衰率. step_sizeのepoch毎に学習率にgammaを乗ずる
-
# StepLR
model = MLP(64, 30, 10)
opt = optim.SGD(model.parameters(), lr=learning_rate)
scheduler = StepLR(opt, step_size=30, gamma=0.1)
for param_group in opt.param_groups:
print(param_group['lr']) # -> 0.1
for epoch in range(60):
scheduler.step()
for param_group in opt.param_groups:
print(param_group['lr']) # -> 0.0010000000000000002
- CosineAnnealingLR
-
opbmizer:optimizerオブジェクト -
T_max:最大値から最小値になるまでのイテレーション数
-
# CosineAnnealing
model = MLP(64, 30, 10)
opt = optim.SGD(model.parameters(), lr=learning_rate)
scheduler = CosineAnnealingLR(opt, T_max=50)
lrs = []
for epoch in range(150):
lrs.append(opt.param_groups[0]['lr'])
scheduler.step()
# lrの描画
plt.plot(lrs)
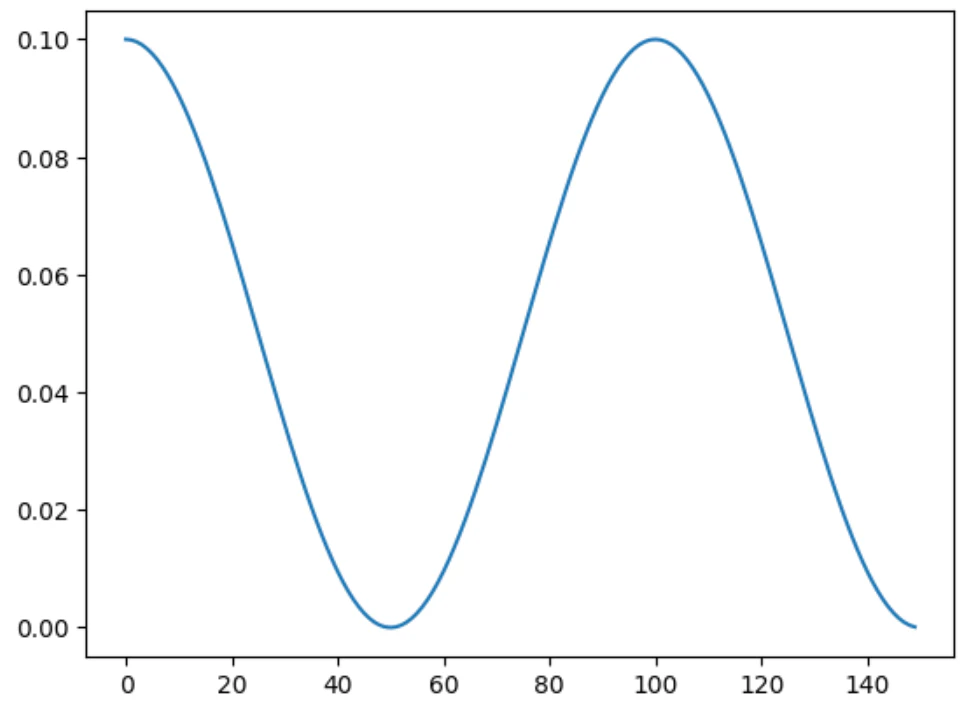
MLPコードに組み込み
# learning rate schedulerを学習ループに組み込む
def learn(model, train_loader, val_loader, optimizer, loss_func, num_epoch, early_stopping=None, save_path=None, scheduler=None):
# ログ
train_losses = []
val_losses = []
val_accuracies = []
best_val_loss = float('inf')
no_improve = 0 # カウント用変数
for epoch in range(num_epoch):
running_loss = 0.0
running_val_loss = 0.0
running_val_acc = 0.0
for train_batch, data in enumerate(train_loader):
X, y = data
optimizer.zero_grad()
# forward
preds = model(X)
loss = loss_func(preds, y)
running_loss += loss.item()
# backward
loss.backward()
optimizer.step()
# validation
with torch.no_grad():
for val_batch, data in enumerate(val_loader):
X_val, y_val = data
preds_val = model(X_val)
val_loss = loss_func(preds_val, y_val)
running_val_loss += val_loss.item()
val_accuracy = torch.sum(torch.argmax(preds_val, dim=-1) == y_val) / y_val.shape[0]
running_val_acc += val_accuracy.item()
train_losses.append(running_loss/(train_batch + 1))
val_losses.append(running_val_loss/(val_batch + 1))
val_accuracies.append(running_val_acc/(val_batch + 1))
# print(f'epoch: {epoch}: train error: {train_losses[-1]}, validation error: {val_losses[-1]}, validation accuracy: {val_accuracies[-1]}')
if val_losses[-1] < best_val_loss:
best_val_loss = val_losses[-1]
no_improve = 0
if save_path is not None:
state = {
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'val_loss': val_losses[-1]
}
torch.save(state, save_path)
else:
no_improve += 1
if early_stopping and no_improve >= early_stopping:
print('Stopping early')
break
if scheduler:
scheduler.step()
return train_losses, val_losses, val_accuracies
# 学習
model = MLP(64, 30, 10)
opt = optim.SGD(model.parameters(), lr=learning_rate)
scheduler = StepLR(opt, step_size=30, gamma=0.1)
train_losses, val_losses, val_accuracies = learn(model, train_loader, val_loader, opt, F.cross_entropy, 100, scheduler=scheduler)
# 元の学習率との変化を確認
# opt.param_groups
# learning_rate