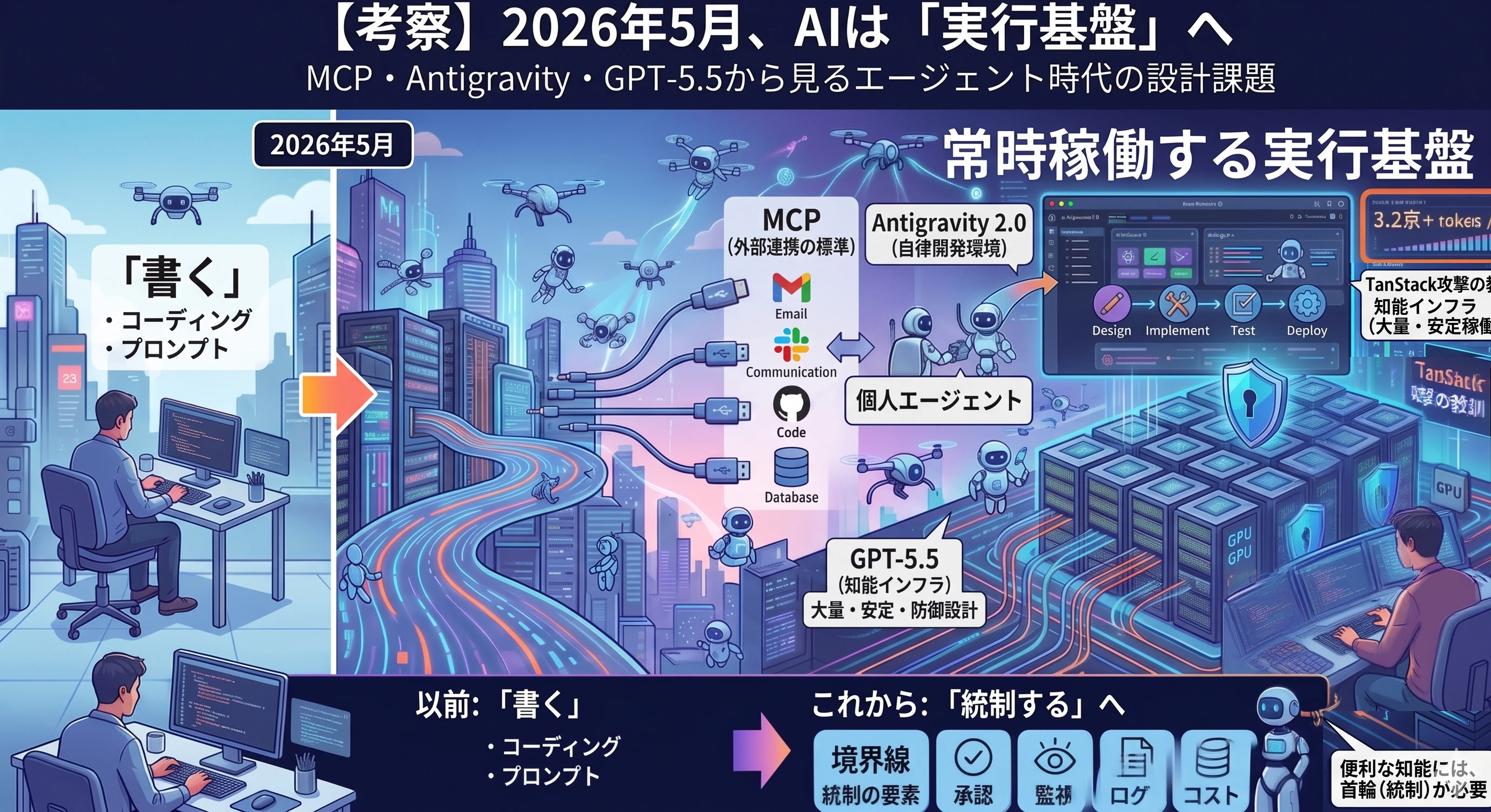
MCP・Antigravity・GPT-5.5から見るエージェント時代の設計課題
はじめに:AI活用が「便利なチャット欄」で終わる前に
2026年5月のAI業界を追っていて、かなりはっきり感じたことがあります。
もうAIは「チャット欄で返事をしてくれる便利ツール」ではなくなりました。
これまでの生成AIは、基本的にはユーザーが入力したプロンプトに対して、文章、コード、画像、要約を返すものでした。
つまり、AIはまだ 人間が呼び出したときだけ動く道具 だったわけです。
しかし2026年5月の発表群を見ると、流れが完全に変わっています。
- AIがバックグラウンドで動く
- 外部サービスに接続する
- メールを読む
- 予定を調整する
- コードを書く
- PRを作る
- セキュリティリスクを検知する
- 購買や支払いの前段まで入り込む
これは、単に「モデルの性能が上がった」という話ではありません。
AIが、アプリの中の機能から、常時稼働する実行基盤へ変わり始めた という話です。
GoogleはI/O 2026で、Googleの各サービス上で処理される月間トークン量が、2024年5月の9.7兆、2025年の約480兆から、2026年5月には 3.2Q+ tokens / 月、約3,200兆トークン に達したと説明しています。
ここで注意したいのは、これは「3.2京」ではなく、英語のquadrillionなので日本語では約3,200兆、つまり0.32京です。
英語の大きい数字は、普通に人類を殴ってきます。
この数字が示しているのは、AIが「試してみるもの」から「毎月消費される知能インフラ」になったということです。
電気、通信、クラウド、そして推論。
いよいよ知能にも使用量メーターが付く時代になりました。
便利ですが、だいぶ物騒です。
結論:AIエージェント時代の本質は「生成」ではなく「統制」
2026年5月の変化を一言でまとめるなら、こうです。
AIは「答える存在」から「動く存在」になった。
そして、AIが動く存在になった瞬間、エンジニアが考えるべきことは変わります。
これまでは、
どうプロンプトを書くか
どうコードを書かせるか
どう速く実装するか
が中心でした。
しかし、これからは違います。
AIに何を任せるか
どのデータに触らせるか
どこで人間の承認を挟むか
失敗したときにどう止めるか
操作ログをどう残すか
コストをどう制御するか
セキュリティをどう担保するか
が主戦場になります。
プロンプトは入口です。
本番運用では、入口よりも 境界線 の方が重要になります。
AIがチャット欄の中にいる間は、多少間違えても「変な回答」で済みました。
しかしAIエージェントが外部サービスに接続し、ファイルを編集し、CIを動かし、チケットを更新し、PRを作り、場合によっては決済や送信に近い操作まで担うようになると、話は変わります。
「ちょっと間違えました」では済みません。
AIエージェントは、便利な補助輪ではありません。
認証情報を持った自律プロセス です。
この認識を持たずに導入すると、便利な秘書を雇ったつもりが、社内システムを徘徊するランダムウォーカーを解き放つことになります。
監査部門が泣きます。
1. Google I/O 2026で見えた「Agentic Web」
Google I/O 2026で重要だったのは、単にGeminiの新モデルが出たことではありません。
本質は、Googleが検索、Gemini、Workspace、YouTube、Shopping、開発環境をまとめて、AIエージェントが動く前提のプラットフォーム に作り替えようとしている点です。
私はこの流れを、かなり実務寄りに捉えています。
これは「便利なAI検索」の話ではありません。
Webそのものが、人間がクリックする場所から、AIエージェントが行動する場所へ変わる という話です。
Gemini Spark:24時間稼働する個人AIエージェント
Googleが発表したGemini Sparkは、24時間稼働するパーソナルAIエージェントです。
ポイントは、ただ賢く返事をすることではありません。
Googleの説明では、SparkはGemini 3.5とGoogle Antigravity platformを基盤にし、ユーザーの指示のもとで自律的に動作し、重要な操作の前には確認する設計になっています。
つまり、AIが次のようなことを始めるわけです。
受信メールを整理する
予定を確認する
タスクを進める
ドキュメントを横断して情報を整理する
必要に応じて外部サービスへ接続する
重要操作の前に人間へ確認する
これは、従来のAIアシスタントとは別物です。
従来のAIは「質問に答える人」でした。
Gemini Sparkは「裏で仕事を進める人」に近づいています。
ここで実務的に重要になるのは、AIの賢さではありません。
AIがどの状態を保持し、どの権限を持ち、どこまで自律してよいか です。
たとえば、メールを読むだけならまだよいです。
しかし、返信文を作る、予定を変更する、外部ツールへ入力する、支払いに関わる、となると話が変わります。
便利さと事故リスクはセットです。
AIエージェントを導入するなら、最初に考えるべきは「何ができるか」ではなく、何をさせないか です。
2. Universal CartとAsk YouTube:検索も購買も「AIが代行する」方向へ
Google I/O 2026では、Universal Cartも発表されました。
これは、Search、Gemini、YouTube、Gmailなどを横断し、商品の価格、在庫、互換性、支払い方法の特典などをAIが見ながら、購買行動を支援する仕組みです。
従来のEC体験は、かなり人間に負担を押し付けていました。
検索する
比較する
レビューを見る
在庫を見る
価格を見る
カートに入れる
クーポンを探す
決済する
届くまで不安になる
冷静に考えると、これは買い物ではありません。
小さな業務システムを、毎回人間が手作業で運用しているだけです。
Universal Cartは、この手作業をAIが横断的に支援する方向へ進めるものです。
またAsk YouTubeも同じ流れです。
従来のYouTube検索は、タイトル、概要欄、タグ、再生数などを頼りに動画を探す体験でした。
しかしAsk YouTubeでは、自然言語で質問すると、YouTube上の関連動画を集め、該当箇所へ直接誘導する体験が提示されています。
つまり検索は、
リンク一覧を返す
から、
目的に対して必要な情報と行動経路を組み立てる
へ変わりつつあります。
これはWebサービス側から見るとかなり重要です。
これからのサービスは、人間に見せるUIだけでなく、AIエージェントに操作される前提の構造 を持つ必要があります。
検索順位を気にしていた時代から、エージェントに正しく読まれ、正しく操作される時代へ移ります。
SEOの次に来るのは、たぶん AEO(Agent Experience Optimization) です。
また人類は新しい略語を作ります。
もう十分あるのに。
3. MCPは、AIが現実世界に触るための標準口になる
Agentic AIの時代に、かなり重要になるのがMCPです。
MCPはModel Context Protocolの略で、AIアプリケーションが外部システムに接続するためのオープン標準です。
公式ドキュメントでは、MCPはAIアプリケーションにとってのUSB-Cのようなものだと説明されています。
この比喩はかなり分かりやすいです。
従来、AIと外部サービスをつなぐには、サービスごとに個別のAPI連携が必要でした。
AI × Gmail
AI × Slack
AI × GitHub
AI × Jira
AI × Notion
AI × Salesforce
AI × 社内DB
AI × 独自業務システム
接続先が増えるたびに、認証、権限、入力形式、返却形式、エラー処理が増えます。
これは地獄です。
人類はAPIを増やすたびに、自分の足元にレゴブロックを撒いています。
MCPが目指しているのは、この接続方式の標準化です。
ざっくり構成すると、こうなります。
ユーザー
↓
AIアプリケーション / MCP Host
↓
MCP Client
↓
MCP Server
↓
外部サービス・DB・API・社内システム
MCPの標準トランスポートは、ローカル接続向けのstdioと、リモート接続向けのStreamable HTTPです。
古い資料ではSSE前提の説明も残っていますが、今の記事としてはstdio / Streamable HTTPと書く方が安全です。
MCPの本質は「接続」ではなく「権限設計」
MCPの話になると、どうしても「AIがいろいろなツールを使えるようになる」という便利側の話に寄りがちです。
しかし実務で重要なのはそこではありません。
MCPの本質は、AIに外部システムへ触らせるための境界設計 です。
AIがGitHub Issueを作れる。
AIがSlackに投稿できる。
AIが社内DBを読める。
AIがカレンダーを見られる。
ここまでは便利です。
しかし次の瞬間、こうなります。
そのAIは、どのリポジトリを読めるのか?
そのAIは、どのSlackチャンネルに投稿できるのか?
そのAIは、顧客情報を見てよいのか?
そのAIは、本番データを変更してよいのか?
そのAIの操作ログは残るのか?
そのAIが間違えたら誰が止めるのか?
AIに外部システムを触らせるということは、AIに権限を渡すということです。
便利なものは危険でもあります。
包丁と同じです。
ただしAIエージェントの場合、包丁が自分で歩きます。
4. Antigravity 2.0:開発環境はIDEから「エージェント統制盤」へ変わる
この流れは、開発環境にも来ています。
Google Antigravity 2.0は、その象徴です。
GoogleはI/O 2026で、Antigravityをagent-first development platformとして説明し、Antigravity 2.0を複数の自律AIエージェントを扱うためのスタンドアロンデスクトップアプリとして発表しました。
ここで起きているのは、単なるコード補完の進化ではありません。
IDEの役割そのものが変わっています。
これまでのIDEは、人間がコードを書く場所でした。
人間が設計する
人間が実装する
人間がテストを書く
人間がレビューする
AIが補完する
しかし、エージェント型開発環境では構図が変わります。
人間が目的を決める
AIエージェントが分担して実装する
AIエージェントがテストを書く
AIエージェントが調査する
AIエージェントがPRを作る
人間が統制・レビュー・承認する
人間の役割は、「全部を書く人」から「分散した作業を設計し、評価する人」へ移ります。
これは、エンジニアが不要になるという話ではありません。
むしろ逆です。
AIに任せる領域が広がるほど、人間側の設計責任が重くなる という話です。
マルチエージェント開発で必要な3層構造
私はマルチエージェント開発を、少なくとも次の3層で考えるべきだと思っています。
| 層 | 役割 |
|---|---|
| オーケストレーター | タスク分解、依存関係管理、進捗監視、マージ方針の決定 |
| 専門エージェント | 実装、テスト、デバッグ、ドキュメント作成などの個別作業 |
| 共有メモリ | 仕様、状態、決定事項、制約、ログを保存する共通コンテキスト |
この構造がないまま複数エージェントを走らせると、普通に壊れます。
同じファイルを別々に編集する
仕様が分裂する
テスト方針がバラバラになる
片方の修正が片方を壊す
最後に人間が全部読む
最後の行が地獄です。
AIで楽をするはずが、人間がAIたちの保育士になります。
マルチエージェント開発で重要なのは、「AIを何体走らせるか」ではありません。
AIたちをどう統制するか です。
これは開発速度の問題ではなく、組織設計の問題に近いです。
5. OpenAIとAnthropicの競争は、モデル競争ではなくインフラ競争になっている
AI業界を見ると、どうしてもモデル名に目が行きます。
GPT、Claude、Gemini。
数字が増えたり、Proが付いたり、Ultraが付いたりします。
命名だけで人類が迷子になります。
しかし2026年5月時点で本当に重要なのは、モデル名そのものではありません。
モデルを24時間動かし続けるための資本、GPU、データセンター、企業導入経路 です。
OpenAIは2026年3月、1,220億ドルの資金調達を発表しました。
事後評価額は8,520億ドルです。
この規模になると、もはやスタートアップというより、知能インフラ企業です。
OpenAIは同時に、Computeを戦略的優位として位置づけています。
ここが重要です。
AIエージェント時代には、モデルが賢いだけでは足りません。
安定して動くか
安く動くか
長時間動くか
大量のタスクを並列に処理できるか
企業の権限・監査・セキュリティ要件に耐えられるか
が重要になります。
チャットなら、多少遅くても待てました。
しかしエージェントは裏で動き続けます。
メールを読む。
検索する。
コードを書く。
テストする。
失敗したら再試行する。
ログを読む。
また考える。
ほぼ人間の会議です。
違いは従量課金なことです。
GPT-5.5 InstantとTAC / GPT-5.5-Cyber
OpenAIはGPT-5.5 Instantについて、高リスク領域のプロンプトでGPT-5.3 Instantよりハルシネーションが52.5%少なかったと説明しています。
ただし、ここで重要なのは「賢くなった」だけではありません。
同時にOpenAIは、サイバー防御向けにDaybreak、Trusted Access for Cyber(TAC)、GPT-5.5-Cyber、Codex Securityという階層を出しています。
整理すると、こうです。
Daybreak
└─ OpenAIのサイバー防御構想・プログラム全体
Trusted Access for Cyber, TAC
└─ 検証済み防衛者向けに高度なサイバー能力へのアクセスを調整する枠組み
GPT-5.5 with TAC
└─ 多くの防御ワークフロー向けの推奨 starting point
GPT-5.5-Cyber
└─ より専門的な認可済みワークフロー向けの限定プレビューモデル
Codex Security
└─ コードベースの脅威モデル化、脆弱性検証、パッチ検証などを担う製品面
これはかなり重要な整理です。
AIがコードを書く量が増えるなら、AIが作る脆弱性も増えます。
コード生成の速度だけ上げても、レビューと検証が追いつかなければ意味がありません。
むしろ、速く壊れるだけです。
爆速で穴を掘る機械を作って「生産性が上がりました」と言うのは、なかなか人類らしいです。
AnthropicとSpaceX:Claudeもコンピュートの取り合いへ
Anthropicも、Claude CodeやClaude APIの利用上限を引き上げるため、SpaceXのColossus 1データセンターの計算容量を使う契約を発表しています。
OpenAIもAnthropicも、結局やっていることは同じです。
モデルを賢くするだけでなく、モデルを大量に、長時間、安定して動かすためのインフラを押さえている。
AIエージェント時代の競争は、知能そのものよりも、知能を動かし続ける基盤の競争になります。
つまり、AIはSaaSというより、電力・通信・物流に近づいています。
知能のクラウドインフラ化です。
6. セキュリティは後付けではなく、エージェント時代の中心要件になる
AIエージェントが外部システムに接続し、実際に操作を始めると、セキュリティの重要性は一気に上がります。
「ちょっと文章を生成しました」と「本番環境にPRを出しました」は、意味がまったく違います。
前者は誤字で済むかもしれません。
後者は会社が燃えます。
選挙と情報起源の証明
OpenAIは2026年5月、選挙に関する安全対策を発表しました。
そこでは、信頼できる投票情報、サイバー防御、AI生成コンテンツの透明性、不正利用対策、政治的中立性が重点として挙げられています。
特に重要なのが、情報の出所を証明する仕組みです。
OpenAIは、SynthIDウォーターマークやC2PA標準を組み合わせた来歴証明に触れています。
GoogleもI/O 2026で、SynthIDとContent Credentialsの対応拡大を発表しています。
AIが大量のコンテンツを生成できるようになると、「何が本物か」だけでは足りません。
「誰が、いつ、どう作ったか」を追跡できることが重要になります。
つまり、これからの情報空間では、文章力よりも 来歴情報 が価値を持ちます。
悲しいですが、文章は誰でもそれっぽく作れます。
それっぽい文章が量産された結果、最終的に大事になるのは「それ、どこから来たの?」という地味な問いです。
7. TanStack npmサプライチェーン攻撃、Mini Shai-Huludが示した現実
2026年5月、AIが開発環境へ溶け込む過渡期に起きたTanStack関連のnpmサプライチェーン攻撃、通称Mini Shai-Huludは、かなり重い事件でした。
TanStackのポストモーテムによれば、2026年5月11日19:20から19:26 UTCの間に、42個の@tanstack/* npmパッケージに対して84個の悪性バージョンが公開されました。
攻撃は、以下を組み合わせたものです。
pull_request_target の Pwn Request パターン
GitHub Actions cache poisoning
GitHub Actions runner process のメモリからの OIDC token extraction
ここで嫌なのは、攻撃者がnpmトークンを盗んだわけではない点です。
正規のリリースパイプラインを悪用し、trusted OIDC identityを使って公開されています。
つまり、こういうことです。
署名されているから安全
正規パイプラインから出ているから安全
という前提が崩れました。
正規パイプラインそのものが乗っ取られた場合、署名は「安全の証明」ではなく、攻撃が正規ルートを通った証明 にもなり得ます。
嫌すぎる教訓です。
しかも実務に効きます。
OpenAIもこの攻撃に関連して、社内の2台の従業員デバイスが影響を受けたと発表しています。
OpenAIは、ユーザーデータ、本番システム、知的財産、ソフトウェア改変への影響は確認されていないと説明しつつ、限定的な認証情報素材の流出に対して、セッション無効化、認証情報ローテーション、デプロイワークフロー制限、コード署名証明書のローテーションなどを実施しています。
この事件の教訓は重いです。
今の開発環境では、攻撃対象はアプリ本体だけではありません。
npmパッケージ
GitHub Actions
CI/CD
OIDCトークン
開発者端末
署名証明書
パッケージ公開権限
キャッシュ
依存関係
全部が攻撃面になります。
AIエージェントが開発フローに入ると、この攻撃面はさらに広がります。
エージェントがPRを作る
エージェントが依存関係を追加する
エージェントがCIを修正する
エージェントがデプロイ設定を書く
便利ですが、かなり怖いです。
エージェント時代の最低限の防衛策
AIエージェントを開発フローに入れるなら、最低でも以下はパイプライン側で防衛すべきです。
pnpm-lock.yaml / package-lock.json / yarn.lock を必ずレビューする
GitHub ActionsのサードパーティActionはタグではなくSHA固定にする
pull_request_target を使うworkflowは、fork由来コードを実行しない
Actions cacheを信頼境界として扱い、fork↔base間のキャッシュ共有を疑う
OIDCトークンの発行範囲と寿命を最小化する
パッケージ公開や本番デプロイなどの特権操作にはHuman-in-the-loopを挟む
エージェントの作業領域に秘密情報を雑に配置しない
エージェントが変更した .github/workflows はCODEOWNERSで人間レビュー必須にする
AIがコードを書く時代には、セキュリティレビューもAI前提で再設計する必要があります。
「AIが便利に直してくれる」だけで終わるなら楽でした。
実際には、「AIが便利に壊す可能性」も同じくらい設計対象になります。
8. Microsoft FoundryとBuild 2026で見える「プロダクション化」の現実
Microsoft Build 2026は、2026年6月2日から3日にかけて開催予定です。
記事執筆時点ではまだ開催前なので、ここでは発表内容ではなく、公開済みのMicrosoft Foundry更新とBuild関連セッションから見える方向性として扱います。
ここで重要なのは、Windows 12のような未確定情報ではありません。
実務上見るべきは、次の問いです。
AIエージェントを、どう本番環境で安全に動かすか?
Microsoft Foundryの2026年4月アップデートでは、以下のような要素が紹介されています。
Foundry Local GA
GPT-5.5のFoundryモデルラインアップ入り
Microsoft Agent Framework tracing
Hosted-agent tracing
Continuous evaluation
Agent Monitoring Dashboard
Microsoft Agent Framework 1.0
VS Code Toolkit
これは、かなり現実的な話です。
PoCなら簡単です。
チャットで動いた
デモで動いた
動画で映えた
社内発表で拍手された
ここまではいけます。
問題はその先です。
本番データに触れる
顧客データを扱う
失敗時に復旧する
コストを監視する
ログを残す
評価を継続する
権限を制御する
法務と監査に説明する
ここまで来ると、AI導入は「モデル選定」ではありません。
普通にシステム設計です。
むしろ、従来のシステムより面倒かもしれません。
なぜなら、AIエージェントは出力が確率的で、外部システムに触り、時には人間っぽい顔で間違えるからです。
自信満々な新人に本番権限を渡すようなものです。
9. 実務でAIエージェントを入れるなら、この順番で考える
ここからは、かなり実務寄りに整理します。
AIエージェント導入で最初にやるべきことは、モデル選びではありません。
権限と境界の棚卸し です。
1. AIに触らせるシステムを棚卸しする
まず、AIエージェントがアクセスする可能性のあるシステムを洗い出します。
メール
カレンダー
社内ドキュメント
顧客管理
チケット管理
GitHub
CI/CD
本番環境
決済
経理
人事情報
ここで分類します。
Readだけ許可するもの
Writeも許可するもの
人間承認が必要なもの
絶対に触らせないもの
AI導入の最初の設計は、モデル選びではありません。
どの情報に触らせるかです。
2. 読み取り専用から始める
最初から書き込み権限を渡すのは危険です。
まずはRead-onlyで十分です。
Issueを読む
PR差分を読む
ログを読む
Sentryを読む
ドキュメントを読む
Slackの特定チャンネルだけ読む
これだけでも、AIはかなり役に立ちます。
最初から投稿、更新、削除、デプロイまで渡す必要はありません。
AIエージェント導入で重要なのは、いきなり自動化し切ることではなく、事故らない範囲を見極めること です。
3. Write権限は限定する
書き込み権限を渡す場合は、必ずスコープを絞ります。
GitHub Issueのコメントだけ許可
PR作成だけ許可
mainブランチへのpushは禁止
Slack投稿は特定チャンネルだけ
本番デプロイは禁止
削除操作は禁止
AIに任せるときほど、権限は狭くします。
AIは賢いから広い権限を渡してよい、ではありません。
賢いからこそ、狭い権限で十分に働けるよう設計するべきです。
4. Human-in-the-loopを設計する
次の操作は、人間承認を挟むべきです。
外部へのメール送信
契約・決済
本番デプロイ
データ削除
顧客への通知
権限変更
セキュリティ設定変更
.github/workflows の変更
パッケージ公開
AIエージェント時代の設計で重要なのは、AIに全部やらせることではありません。
どこまでは自動化し、どこからは人間が責任を持つか を決めることです。
5. ログと評価を最初から入れる
AIエージェントは、成功したときだけ見ていても意味がありません。
失敗したときに、次を追える必要があります。
何を読んだのか
何を判断したのか
どのツールを呼んだのか
どの結果を受け取ったのか
なぜその操作をしたのか
誰が承認したのか
どのコストが発生したのか
これは開発ログであり、監査ログであり、改善データです。
ログがないAIエージェントは、実務ではかなり怖いです。
人間でもログを残さない作業者は怖いのに、確率的に動くAIがログを残さないのは普通に無理です。
10. やってはいけないAIエージェント導入
実務でやると危ない導入パターンも整理しておきます。
1. いきなり本番権限を渡す
一番やってはいけません。
AIが動くことを確認する前に、本番データ、本番デプロイ、顧客通知へ接続するのは危険です。
まずはSandboxです。
次にStagingです。
最後にProductionです。
これはAIでも同じです。
AIだからといって、いきなり本番へ行ってよい理由にはなりません。
2. MCP Serverを雑に公開する
MCP Serverは便利ですが、外部システムへの入口です。
雑に公開すると、ただの便利な攻撃面になります。
最低でも次を考える必要があります。
認証
認可
Origin検証
監査ログ
レート制限
ローカルバインド
Secret管理
Toolごとの権限分離
MCP Serverは「AI用API」ではありません。
AIが使う 権限付き操作口 です。
3. AIが作ったCI/CD変更をノーレビューで通す
TanStackの件を見れば分かりますが、CI/CDは攻撃面です。
.github/workflows の変更をAIが出してきた場合、通常のコードより厳しく見るべきです。
pull_request_target を使っていないか
fork由来コードを実行していないか
cacheのtrust boundaryを壊していないか
OIDCのid-token: writeが広すぎないか
サードパーティActionがSHA固定されているか
CI/CDの変更は、便利改善ではなく、セキュリティ変更です。
AIが作ったからといって雑に通すと、あとで自分の環境が教材になります。
4. 「AIがやったから」で責任を曖昧にする
これは組織として一番危険です。
AIエージェントが失敗したときに、
AIが勝手にやりました
は通りません。
誰が権限を渡したのか。
誰が承認したのか。
どのログが残っているのか。
どの範囲で動くよう設計したのか。
結局、責任は人間側に戻ってきます。
AIエージェント導入は、責任の外注ではありません。
責任範囲の再設計です。
まとめ:エンジニアは「書く」から「統制する」へ
2026年5月のAI業界で起きている変化は、単なるモデル性能競争ではありません。
AIは、チャット欄の中から外へ出ました。
Gemini Sparkは、24時間稼働する個人エージェントの方向性を示しました。
MCPは、AIが外部システムへ触るための標準口になりつつあります。
Universal CartやAsk YouTubeは、検索、購買、メディア体験をエージェント前提に変え始めました。
Antigravity 2.0は、開発環境をコードエディタからエージェント統制盤へ変えようとしています。
OpenAIとAnthropicの競争は、モデルだけでなく、コンピュートとインフラの競争になっています。
Daybreak、TAC、GPT-5.5-Cyber、Codex Securityは、防御側AIの制度設計を示しています。
TanStack / Mini Shai-Hulud攻撃は、AI時代のサプライチェーン防衛が後付けでは済まないことを示しました。
Microsoft Foundryの流れは、AIエージェントを本番運用するには、観測、評価、ログ、コスト管理が必要だと示しています。
これから問われるのは、「AIに何を答えさせるか」ではありません。
AIにどこまで任せ、どこで止め、どう検証し、誰が責任を持つか です。
プロンプトはお願いです。
MCPは接続口です。
HooksやCI/CDガードはゲートです。
ログと評価は監査装置です。
Human-in-the-loopは責任境界です。
AIがチャット欄の外に出た瞬間、設計対象は文章ではなくなります。
設計対象は、業務そのものになります。
エンジニアの仕事は、コードを1行ずつ書くことから、AIが安全に速く動けるレールを敷くことへ変わりつつあります。
AIに全部任せる時代ではありません。
AIを疑いながら、使える形に閉じ込める時代です。
便利な知能には、ちゃんと首輪が必要です。
それを作るのが、これからのエンジニアの仕事になるはずです。
参考
-
Google I/O 2026: Welcome to the agentic Gemini era
https://blog.google/innovation-and-ai/sundar-pichai-io-2026/ -
100 things we announced at I/O 2026
https://blog.google/innovation-and-ai/technology/ai/google-io-2026-all-our-announcements/ -
Model Context Protocol: What is MCP?
https://modelcontextprotocol.io/docs/getting-started/intro -
Model Context Protocol: Transports
https://modelcontextprotocol.io/specification/2025-11-25/basic/transports -
OpenAI raises $122 billion to accelerate the next phase of AI
https://openai.com/index/accelerating-the-next-phase-ai/ -
GPT-5.5 Instant: smarter, clearer, and more personalized
https://openai.com/index/gpt-5-5-instant/ -
Scaling Trusted Access for Cyber with GPT-5.5 and GPT-5.5-Cyber
https://openai.com/index/gpt-5-5-with-trusted-access-for-cyber/ -
Daybreak | OpenAI for cybersecurity
https://openai.com/daybreak/ -
Election information and safeguards in 2026
https://openai.com/index/election-safeguards-2026/ -
Our response to the TanStack npm supply chain attack
https://openai.com/index/our-response-to-the-tanstack-npm-supply-chain-attack/ -
Postmortem: TanStack npm supply-chain compromise
https://tanstack.com/blog/npm-supply-chain-compromise-postmortem -
TanStack npm Packages Hit by Mini Shai-Hulud
https://snyk.io/blog/tanstack-npm-packages-compromised/ -
Higher usage limits for Claude and a compute deal with SpaceX
https://www.anthropic.com/news/higher-limits-spacex -
What’s new in Microsoft Foundry | April 2026
https://devblogs.microsoft.com/foundry/whats-new-in-microsoft-foundry-apr-2026/
この記事を書いた人✏️@YushiYamamoto
ITPRODX.com代表 / AIアーキテクト
Next.js / TypeScript / n8nを活用した自律型アーキテクチャ設計を専門としています。
日々の自動化の検証結果や、ビジネス側の視点(ROI等)に関するより深い考察は、以下の公式サイトおよびnoteで発信しています。