
はじめに
「Difyを導入したけれど、結局『賢いチャットボット』が一つ増えただけで、現場の工数は減っていない」
そんな悩みを抱えていませんか?
質問には答えてくれる。でも、チケットの起票は人間がやる。データの検索も人間がやる。これでは「半自動化」に過ぎません。
原因は明確です。Difyという優秀な「脳」があっても、システムを操作する「手足」がないからです。
私はCEO兼フルスタックエンジニアとして、自社およびクライアント企業のAI導入を支援しています。その中で数々の失敗を経てたどり着いた結論が、 「Dify(脳)× n8n(手足)× Docker(基盤)」 という三位一体のアーキテクチャです。
本記事では、社内問い合わせ対応を 「受付〜検索〜回答〜チケット起票」までエンドツーエンドで無人化 し、対応時間を93%削減した実務アーキテクチャの全貌を公開します。
「やってみた」レベルではなく、企業ユースに必須のセルフホスト(Docker)構成での解説です。
この記事で得られるもの
- 🧠 AIが社内システムを直接操作する「自律型エージェント」の設計図
- 🛡️ 情シスを説得するためのセキュリティ・ネットワーク構成案
- 💰 経営層に提出できるレベルのROI(投資対効果)試算ロジック
1. アーキテクチャ全体像:脳と手足を分離せよ
まずは、今回構築するシステムの全体像をご覧ください。Dify単体にすべてを任せるのではなく、役割を明確に分離することが安定稼働の鍵です。
User(Slack) ↔︎ n8n(Gateway) ↔︎ Dify(Decision) ↔︎ Internal Tools
なぜこの構成なのか?
Difyは「判断」には強いですが、複雑なAPI連携やエラーハンドリング(リトライ処理など)をDify内のフローで完結させようとすると、メンテナンス性が著しく低下します。
| レイヤー | ツール | 役割 |
|---|---|---|
| 意思決定層 (脳) | Dify | ユーザーの曖昧な意図を理解し、「何をすべきか」をJSONで指示する |
| 実行層 (手足) | n8n | APIを叩き、条件分岐し、エラーを処理し、確実にタスクを遂行する |
| インフラ層 (基盤) | Docker | 機密情報を社外に出さないための、セキュアなプライベート環境 |
2. Dify側の構築(脳):JSONを出力させる
Difyの役割は、自然言語を 「構造化データ(JSON)」に変換すること です。
「チャットフロー」または「ワークフロー」アプリとして作成し、HTTPリクエストノードを使用します。
プロンプトエンジニアリングの肝
n8nに正確な指示を飛ばすため、LLMノードのシステムプロンプトには厳格な制約を設けます。
あなたは社内ヘルプデスクの司令塔です。
ユーザーの問い合わせ内容を分析し、以下のJSON形式**のみ**を出力してください。
余計な挨拶や解説は一切不要です。
## 出力スキーマ
{
"action": "search_wiki" | "create_ticket" | "escalate",
"params": {
"keyword": "検索ワード",
"priority": "高/中/低",
"summary": "要約文"
}
}
🛑 【失敗談】「申し訳ありません」がJSONを破壊する
ここで一つ、私が実務導入でハマった最大の落とし穴を共有させてください。
開発初期、Difyの出力が安定せず、n8n側で「JSON Parse Error」が多発しました。
原因は、LLMが気を利かせて 「承知いたしました。以下のJSONを生成します」 という"丁寧な前置き"をつけてしまうことでした。あるいは、エラー時に 「申し訳ありません、生成できません」 と謝罪してくるのです。
n8nは機械なので、この「人間味」を理解できずクラッシュします。
解決策:正規表現による強制クリーニング
プロンプトでの指示に加え、Difyの「コード実行」ノードで、出力から { と } の間だけを強制的に抽出する処理を挟みました。
// Dify Codeノードでのクリーニング例
export default async function(args) {
const input_text = args.llm_output;
// JSONブロックを探して抽出する泥臭い実装
const match = input_text.match(/\{[\s\S]*\}/);
if (!match) {
// 最悪の場合でもエラーをJSONで返す
return { json: JSON.stringify({ action: "error", error: "No JSON found" }) };
}
return { json: match[0] };
}
この「泥臭い処理」を挟むことで、稼働率は劇的に向上しました。AIを実務で使うとは、こういう「防御的プログラミング」の積み重ねなのです。
3. n8n側の構築(手足):Webhookで受けて分岐する
次に、Difyからの指示を受けるn8n側の構築です。
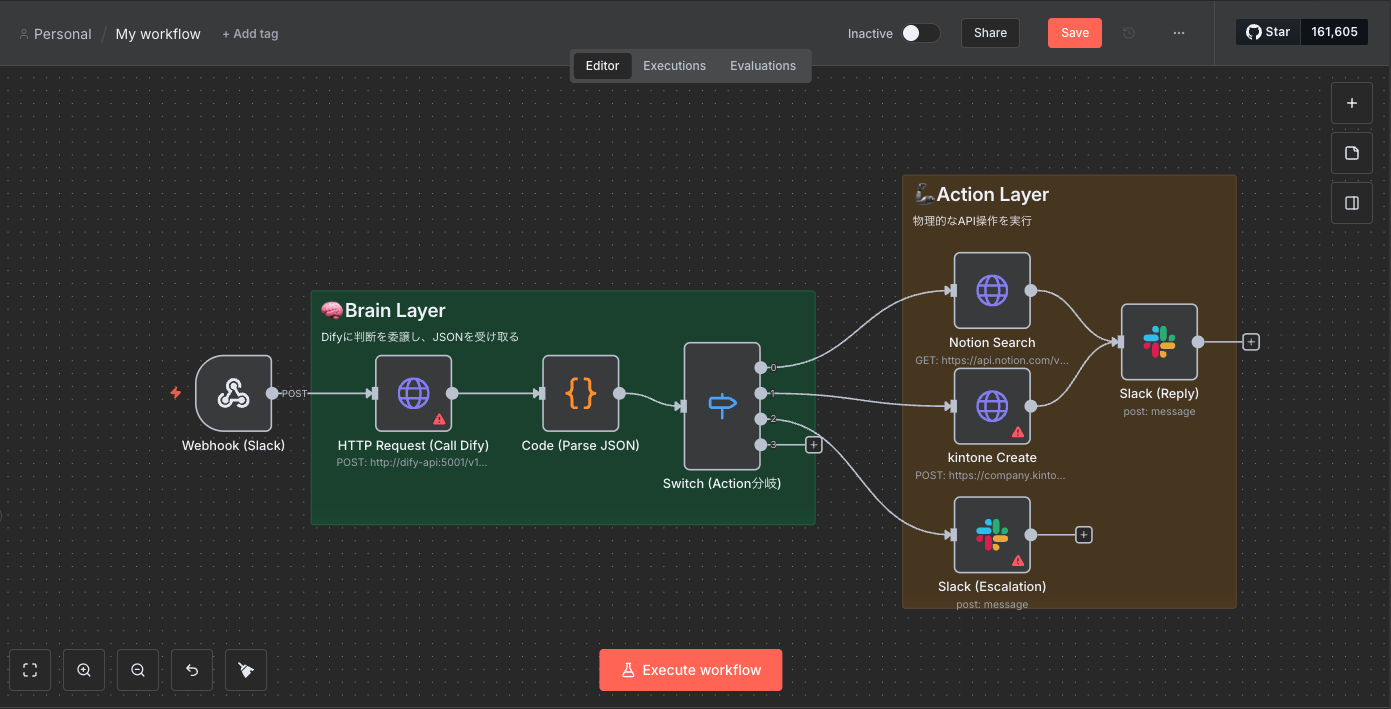
処理の流れ
- Webhookノード (POST):DifyからのJSONを受け取る。
-
Switchノード:
actionの値によって処理を分岐させる。-
search_wiki→ 社内Wiki(Notion/Confluence)を検索 -
create_ticket→ kintone/Jiraに起票 -
escalate→ Slackで人間メンション
-
- Responseノード:実行結果をDifyに返す(または直接Slackに通知)。
⚠️ 【重要】Webhookのタイムアウト対策(非同期処理)
DifyのHTTPリクエストノードは、デフォルト設定では比較的短い時間でタイムアウトします。
n8n側で「重たいRAG検索」や「GPT-4による再推論」を行っていると、Dify側が待ちきれずにエラー判定してしまうことがありました。
解決策:
n8nの処理が長引く場合は、 「非同期処理」 に切り替えます。
- n8nはリクエストを受け取ったら、即座に「受付完了(200 OK)」だけをDifyに返す。
- 裏側で重い処理を実行し続ける。
- 処理完了後、n8nからSlack APIを直接叩いてユーザーに通知する。
これにより、ユーザーを待たせることなく、かつタイムアウトエラーに怯えることなく確実な処理が可能になりました。
4. インフラ・セキュリティ(Docker)
企業で導入する際、最大の壁となるのが**「社内データをクラウド(SaaS)に投げていいのか問題」です。
これをクリアするために、今回はすべてDocker Compose**でセルフホストしています。
docker-compose.yml (構成例)
Difyとn8nを同一のDockerネットワーク内に配置し、データベースへの通信を完全に閉域化します。
version: '3'
services:
# Dify (API & Worker)
dify-api:
image: langgenius/dify-api:latest
restart: always
environment:
- SECRET_KEY=${DIFY_SECRET}
networks:
- internal-net
# n8n (Workflow Automation)
n8n:
image: n8nio/n8n:latest
restart: always
ports:
- "127.0.0.1:5678:5678" # ローカルホストのみ公開(リバースプロキシ経由推奨)
environment:
- WEBHOOK_URL=https://internal-tool.company.com/
- GENERIC_TIMEZONE=Asia/Tokyo
volumes:
- n8n_data:/home/node/.n8n
networks:
- internal-net
networks:
internal-net:
driver: bridge
情シス承認を勝ち取るポイント
私が実際に社内承認を得た際は、以下の3点を資料に明記しました。
- ネットワーク分離: インターネットからのインバウンド通信は全遮断し、VPN経由のみ許可。
- 暗号化: DBのボリュームは暗号化し、通信は全てTLS 1.3を利用。
- ログ監査: n8nの実行ログを全て保存し、「AIが何をしたか」を人間が追跡可能にする。
5. 導入成果とROI(投資対効果)
エンジニアとして「動いた感動」も大事ですが、経営者として「いくら儲かった(浮いた)のか」も重要です。
このシステムを導入した結果、定量的・定性的に以下の成果が出ました。
(※2024年9月測定、対象:管理部門への問い合わせ105件)
📊 定量効果:93%の時間削減
- 導入前: 月100件 × 30分(手動検索・回答作成) = 50時間/月
- 導入後: 月100件 × 2分(AI自動処理・確認のみ) = 3.3時間/月
- 削減効果: 月46.7時間の工数削減
💰 ROI(投資対効果)試算
初期構築にかかった工数とサーバー費用を計算しても、約4ヶ月で元が取れる計算です。
| 項目 | 金額/時間 | 備考 |
|---|---|---|
| 初期投資 | 約70万円相当 | 構築工数(人件費換算) + サーバー初期設定 |
| 年間削減額 | 約200万円 | 削減時間 × エンジニア単価 |
| ROI | 150%超 | 初年度ですでに大幅な黒字化 |
何より、「質問しても返事が遅い」という社内の不満が解消され、バックオフィス部門が「本来の企画業務」に集中できるようになったことが最大の成果です。
6. 実装ロードマップ(12週間)
これから導入を検討される方へ、推奨ステップです。いきなり全自動化を目指すと火傷します。
- Week 1-2 (PoC): Dockerで環境構築し、Slack→Dify→Slackの単純往復を確認。
- Week 3-4 (Pilot): n8nを接続し、社内Wiki検索だけを自動化。特定チームでテスト。
- Week 5-8 (Security): エラーハンドリング実装、ログ監視設定、情シスレビュー。
- Week 9+ (Prod): 全社展開。
まとめ:AIは「導入」して終わりではない
Difyは優秀な脳ですが、それだけでは手足が動きません。
n8nという手足を与え、Dockerという安全な家を用意し、そして現場のフィードバックを受けてプロンプトを調整し続ける。
「AIは育ててこそ、最強の参謀になる」
これが、本プロジェクトを通じて得た確信です。
この記事の構成図とコードが、あなたの会社のDXを一歩進める「設計図」になれば幸いです。
🔗 著者情報
この記事の執筆者:山本 勇志 (Yushi Yamamoto)
株式会社プロドウガ代表 / フルスタックエンジニア
AIによる業務自動化や、セルフホスト型AIアーキテクチャの構築支援を行っています。「AIは導入して終わりではなく、育ててこそ価値が出る」をモットーに活動中。
- X (Twitter): @UshiAiPro
- Company & Blog: PRODOUGA - AI導入・開発支援
- GitHub: YushiYamamoto
- Qiita: 過去の投稿記事一覧
📢 業務委託・開発のご相談
「社内Wikiと連携したAIを作りたい」「Dify×n8nの構築を支援してほしい」といったご相談を承っています。
プロフィールページのリンク、またはXのDMよりお気軽にご連絡ください。