目的
ゲームのスクリーンショットから切り出したキャラクターの顔を分類できるようにする.この際,新キャラクターが追加された場合に行う学習コストを下げられるような手法を選択する.
環境
機械学習の実行
- Python 3.8.2
- Pytorch 1.9.0+cu111
- torchvision 0.10.0+cu111
- GPy 1.9.9
- plotly 4.14.3
- windows 10 home, Intel i9-9900KF, RTX 2070super
画像の準備
- Mac Mini(M1, macOS Monterey)
- 写真.app
- プレビュー.app
導入
待ちに待ったアイマスの家庭用機向け新作(通称スタマス.以下,本作)が2021年10月に発売されました.今作はシナリオ量が過去最大とも言われており,スキップせずにプレイすると約70時間はかかるほどです.真エンディングまでですと100時間弱とたっぷりプレイできます.
本作に限らずゲームをプレイしているとスクリーンショットを撮る機会は少なからずあると思います.本作ではお気に入りのアイドル,衣装,楽曲,ステージを組み合わせてMVを鑑賞することが可能なため,必然的にベストショットがフォルダに数千枚と蓄積されていきます・・・
せっかくのベストショットも未整理で数千枚とあれば見返す機会が限られてしまいます.そこで積み上がったベストショットを整理すべく,画像分類タスクに取り組むことにしました.
ところでただ画像を分類したいだけなら,深い畳み込み層の後に全結合層を接続したニューラルネットを作成するだけで十分ですね?ですがこの手法には欠点があります.分類したいクラスが増えて再学習を行おうとすると,深い畳み込み層の再学習コストが大き過ぎるのです1.本作のようにDLCでアイドル=新クラスが追加されるような場合には由々しき事態です.この問題に対処するため,本記事ではDeep Metric Learning(以下,DML)という手法で顔空間を別の低次元空間に埋め込みました.同じ顔は近くに,異なる顔は遠くに埋め込まれるような変換を最初に学習することで,再学習の際には埋め込み空間を分割する全結合層だけを学習すれば十分になることを期待します2.
全体の流れ
- 本作の真エンディングまでクリアする
- MV鑑賞でベストショットを撮りまくる(本記事では3千枚以上)
- ベストショットから顔部分を切り抜く
- アイドルごとのフォルダに仕分け(同5千枚以上)
- DML実行,埋め込み空間の確認
- DLCを購入,追加アイドルのベストショットを撮りまくる(30枚程度)
- DML実行時に存在しなかった追加アイドルが埋め込み空間でどう分布するかを確認する
顔の切り抜きは偉大な先人の力を借りることで簡単に実行できます.フォルダへの仕分けは気合いで手作業です.~~これを自動化したかったのに本末転倒.~~DMLもほぼコピペです.パラメータの調整とか手付けずです.埋め込み空間の確認に先人達との差別化がありますが,これもパーツを組み合わせただけです.
分類対象の確認
画像の仕分けという泥臭い作業が完了したところから始めます。
画像例
今回の学習対象となるアイドル32人の画像と,未知データへの適用可能性を評価する用の追加アイドル2人の例です.例示画像は32*32に縮小しています.
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
 Amana Amana |
 Ami Ami |
 Anzu Anzu |
 Aya Aya |
 Azusa Azusa |
 Chihaya Chihaya |
 Haruka Haruka |
 Hibiki Hibiki |
 Iori Iori |
 Kaho Kaho |
 Kaori Kaori |
 Kirari Kirari |
 Kohaku Kohaku |
 Leon Leon |
 Makoto Makoto |
 Mami Mami |
 Mika Mika |
 Miki Miki |
 Mirai Mirai |
 Nana Nana |
 Ranko Ranko |
 Rinze Rinze |
 Ritsuko Ritsuko |
 Sakuya Sakuya |
 Shiika Shiika |
 Shizuka Shizuka |
 Takane Takane |
 Tenka Tenka |
 Tsubasa Tsubasa |
 Tsumugi Tsumugi |
 Yayoi Yayoi |
 Yukiho Yukiho |
DLC |
 Kaede Kaede |
 Kotoha Kotoha |
| 本記事の投稿前日にDLCアイドルが追加されているのですが,画像の準備ができていないため省略します. |
クラス分布
クラス間のデータの偏りです.トップだけで全体の20%,5人/32人で40%というのは教師データとしては不適切でしょうが仕方ありません.最上位陣は感覚通りですが,上位陣くらいからもう「そうなの?」という感じです.割とストーリークリアの都合で決まってる気がします.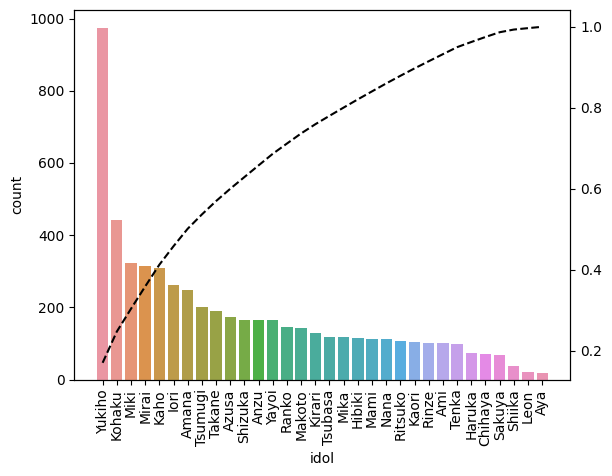
画像の大きさ
ベストショットの構図によって顔画像の大きさは全て異なるのですが,基本4K画質で保存してあるため大きめの画像が多いです.正方形で切り抜いたところ一辺の長さの中央値は522ピクセルでした.学習の際には中央値で大きさを統一しておきました.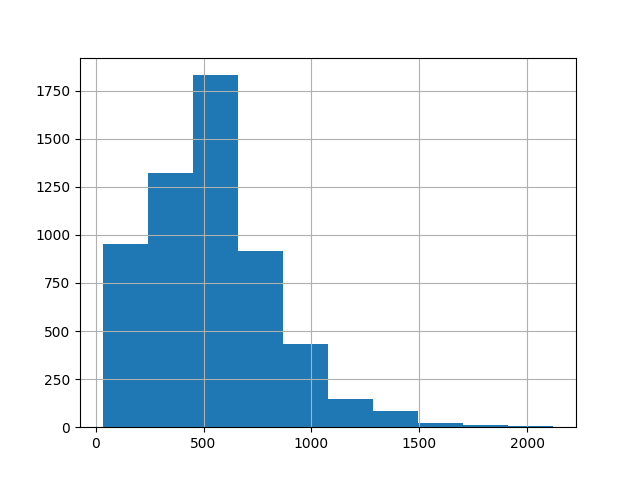
学習
本質的にはこちらの記事と同じです.モデルをResNetに置き換え,こちらの記事に従って高速化を施し,学習全体をクラスにまとめて,パラメータをコマンドライン引数として受け付けられるように書き換えてます.
モデル
Pytorchで既に構築されているResNet18を使います.本来は調整すべきパラメータなのですが,最後の全結合層の出力は仮で128個としておきます.すなわち顔空間を128次元で再現することをDMLで学習します.
import torch
from torchvision.models.resnet import resnet18
model = resnet18(pretrained=True)
model.fc = torch.nn.Linear(model.fc.in_features, 128)
Data augmentation
DataLoaderに渡すtransformで実行します.
import os
from pathlib import Path
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision import transforms
class MyTransformer(object):
def __init__(
self, resize=None, horizontal_flip=True,
vertical_flip=True, rotation=45,
normalize=None,
resize_kws={}, horizontal_kws={},
vertical_kws={}, rotation_kws={},
normalize_kws={},
):
transform = []
if resize is not None:
transform.append(
transforms.Resize(resize, **resize_kws)
)
if horizontal_flip:
transform.append(
transforms.RandomHorizontalFlip()
)
if vertical_flip:
transform.append(
transforms.RandomVerticalFlip()
)
if rotation:
transform.append(
transforms.RandomRotation(
degrees=rotation, **rotation_kws
))
if normalize is not None:
transform.append(normalize)
transform.append(transforms.ToTensor())
self.transform = transforms.Compose(transform)
#transform = torch.nn.Sequential(*transform)
#self.transform = torch.jit.script(transform)
def __call__(self, img):
return self.transform(img)
学習データと評価データの分離
ここで言う評価データとはDLCアイドルのことではありません.最初にDMLで学習するアイドル32人の画像を,学習用と評価用に分離するということです.前述の通りデータ分布が著しく偏っているため,ランダムサンプリングで分離すると評価が安定しなくなります.これを回避するためにscikit-learnで層化抽出を行います3.学習データと評価データにそれぞれどの画像が選ばれたかを追跡するためにcsvでの保存も行っています.
import pandas as pd
from torchvision import transforms, datasets
from sklearn.model_selection import train_test_split
from mydataset import MyTransformer
# import dataset
root = #your image folder
dataset = datasets.ImageFolder(
root, transform=MyTransformer()
)
train_idx, test_idx = train_test_split(
list(range(len(dataset.targets))),
test_size=0.2, shuffle=True,
stratify=dataset.targets
)
img_table = pd.DataFrame(
dataset.imgs,
columns=['path', 'label'],
)
img_table.loc[train_idx].to_csv('train_images.csv')
img_table.loc[test_idx].to_csv('test_images.csv')
train_dataset = Subset(dataset, train_idx)
test_dataset = Subset(dataset, test_idx)
# make DataLoader
train_loader = DataLoader(
train_dataset, batch_size=64,
shuffle=True, num_workers=4,
pin_memory=True,
)
test_loader = DataLoader(
test_dataset, batch_size=64,
shuffle=False, num_workers=4,
pin_memory=True,
)
自作DMLクラス
前述の通り先人の業績を整理しました.保存機能や保存済みモデルの読み込み機能も追加し,精神的安全のためにプログレスバーを実装するなど欲張りクラスに仕上がってます.
import os
from pathlib import Path
from datetime import datetime
import numpy as np
import pandas as pd
from tqdm import tqdm
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
import torch
from torch import optim
from torch.utils.data import Dataset, DataLoader, Subset
import torchvision
from torchvision import transforms, datasets
from torchvision.models.resnet import resnet18, resnet34, resnet50, resnet101, resnet152
from pytorch_metric_learning.miners import TripletMarginMiner
from pytorch_metric_learning.distances import CosineSimilarity
from pytorch_metric_learning.losses import TripletMarginLoss
from pytorch_metric_learning.reducers import ThresholdReducer
from mydataset import MyTransformer
class DML(object):
def __init__(self, root, nn, loss_func, mining_func,
device='cpu', num_workers=2,
pin_memory=True, non_blocking=True,
transform=MyTransformer(),
output_dim=128,
batch_size=128,
):
self.root = root
self.device = device
self.num_workers = num_workers
self.pin_memory = pin_memory
self.non_blocking = non_blocking
self.output_dim = output_dim
self.batch_size = batch_size
self.loss_func = loss_func
self.mining_func = mining_func
self.log = {'train': [], 'test': []}
#self.optimizer = optimizer
# import dataset
dataset = datasets.ImageFolder(
self.root, transform=transform
)
train_idx, test_idx = train_test_split(
list(range(len(dataset.targets))),
test_size=0.2, shuffle=True,
stratify=dataset.targets
)
img_table = pd.DataFrame(
dataset.imgs,
columns=['path', 'label'],
)
img_table.loc[train_idx].to_csv('train_images.csv')
img_table.loc[test_idx].to_csv('test_images.csv')
self.train_dataset = Subset(dataset, train_idx)
self.test_dataset = Subset(dataset, test_idx)
# make DataLoader
self.train_loader = DataLoader(
self.train_dataset,
batch_size=self.batch_size,
shuffle=True,
num_workers=self.num_workers,
pin_memory=self.pin_memory,
)
self.test_loader = DataLoader(
self.test_dataset,
batch_size=self.batch_size,
shuffle=False,
num_workers=self.num_workers,
pin_memory=self.pin_memory,
)
# import model
model = nn
model.fc = torch.nn.Linear(
model.fc.in_features, self.output_dim
)
self.model = model.to(
self.device,
non_blocking=self.non_blocking
)
def set_optimizer(self, optimizer):
self.optimizer = optimizer
def amp_train(self, epoch=0, epochs=0):
self.model.train()
scaler = torch.cuda.amp.GradScaler()
dataloader = self.train_loader
loss = torch.tensor([0])
triplets = 0
with tqdm(dataloader) as pbar:
for i, (inputs, labels) in enumerate(pbar):
pbar.set_description(
f'[Epoch {epoch}/{epochs}'
)
pbar.set_postfix({
'loss': loss.detach().to('cpu').numpy(),
'triplets': triplets
})
inputs = inputs.to(
self.device,
non_blocking=self.non_blocking
)
labels = labels.to(
self.device,
non_blocking=self.non_blocking
)
self.optimizer.zero_grad()
with torch.cuda.amp.autocast():
embeddings = self.model(inputs)
indices_tuple = self.mining_func(
embeddings, labels
)
loss = self.loss_func(
embeddings, labels,
indices_tuple
)
triplets = self.mining_func.num_triplets
scaler.scale(loss).backward()
scaler.step(self.optimizer)
scaler.update()
self.log['train'].append([loss, triplets])
def test(self):
_predicted_metrics = []
_true_labels = []
dataloader = self.test_loader
self.model.eval()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloader):
inputs = inputs.to(
self.device,
non_blocking=self.non_blocking
)
labels = labels.to(
self.device,
non_blocking=self.non_blocking
)
metric = self.model(
inputs).detach().cpu().numpy()
metric = metric.reshape(
metric.shape[0],
metric.shape[1]
)
_predicted_metrics.append(metric)
_true_labels.append(
labels.detach().cpu().numpy()
)
return np.concatenate(_predicted_metrics), np.concatenate(_true_labels)
def save(self, path):
torch.save(self.model.state_dict(), str(path))
def load(self, path):
self.model.load_state_dict(torch.load(str(path)))
学習
実行するだけ.パラメータチューニングしたいならスクリプトを書き換えずにコマンドライン引数から対応可能です4.
import argparse
if __name__=='__main__':
# inputs from command line
parser = argparse.ArgumentParser()
parser.add_argument('--title')
parser.add_argument('--root', default='DataSet')
## training options
parser.add_argument('--epochs', default=50, type=int)
parser.add_argument('--learning_rate', default=1e-4, type=float)
parser.add_argument('--batch_size', default=64, type=int)
## model options
parser.add_argument('--output_dim', default=128, type=int)
parser.add_argument(
'--resnet', default=18, type=int,
choices=[18, 34, 50, 101, 152]
)
## options of metrics learning
parser.add_argument('--reducer_low', default=0, type=int)
parser.add_argument('--losser_margin', default=0.2, type=float)
parser.add_argument('--miner_margin', default=0.2, type=float)
# parameters
args = parser.parse_args
epochs = args.epochs
learning_rate = args.learning_rate
batch_size = args.batch_size
root = args.root
num_workers = 4 if os.cpu_count()>=4 else 2
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if args.title is None:
store = Path(f'{datetime.now(): %Y%m%d%H%M}')
else:
store = Path(args.title)
store.mkdir(parent=True)
with open(store/'parameters.txt', 'w') as f:
f.write(vars(args))
resnet = args.resnet
if resnet==18:
nn = resnet18
elif resnet==34:
nn = resnet34
elif resnet==50:
nn = resnet50
elif resnet==101:
nn = resnet101
elif resnet==152:
nn = resnet152
nn = nn(pretrained=True)
output_dim = args.output_dim
distance = CosineSimilarity()
reducer = ThresholdReducer(low=args.reducer_low)
losser = TripletMarginLoss(
margin=args.losser_margin, distance=distance,
reducer=reducer
)
miner = TripletMarginMiner(
margin=args.miner_margin, distance=distance
)
dml = DML(
root, nn, losser, miner, device=device,
num_workers=num_workers,
output_dim=output_dim, batch_size=batch_size,
)
optimizer = optim.Adam(dml.model.parameters(), lr=learning_rate)
dml.set_optimizer(optimizer)
test_predicted_metrics = []
test_true_labels = []
# Performance Tuning
torch.backends.cudnn.benchmark = True
# training
for epoch in range(epochs+1):
dml.amp_train(epoch, epochs)
_tmp_metrics, _tmp_labels = dml.test()
test_predicted_metrics.append(_tmp_metrics)
test_true_labels.append(_tmp_labels)
dml.log['test'] = [test_true_labels, test_predicted_metrics]
if (epoch*10)%epochs == 0:
dml.save(store/f'epoch_{epoch}.pt')
np.save(store/f'epoch_{epoch}_test_labels.npy', test_true_labels)
np.save(store/f'epoch_{epoch}_test_predicted.npy', test_predicted_metrics)
np.save(store/f'epoch_{epoch}_train.npy',
dml.log['train'])
print(f'result of epoch{epoch} is saved.')
dml.save(store/'model.pt')
#np.save('test_log.npy', dml.log['test'])
#np.save(f'train_log.npy', dml.log['train'])
私の環境でコマンドライン引数を与えずに実行すると,72batch/epochの学習が約40秒で計算できます.その後の評価やら保存まで込みだと60秒ほどになりました.画像が522*522と大きいためバッチサイズ64でも8GBのVRAMがギリギリです.AMPを使わない場合はバッチサイズを32にしないとメモリに乗りませんでした.
結果の可視化
評価データでtSNE
522pixel * 522pixel * RGB = 817,452次元の画像がDMLによって128次元空間に埋め込まれています.おおよそ7pixel * 6 pixel * RGB相当の情報量ですが,そう画像にしたところで顔とは分からないでしょう.埋め込みがうまくいっているかを評価データで確認します.128次元そのままでは確認できないためtSNEで次元圧縮します.
import seaborn as sns
if __name__=='__main__':
epochs = 50
learning_rate = 1e-4
batch_size = 64
root = 'DataSet'
num_workers = 4 if os.cpu_count()>=4 else 2
output_dim = 128
device = 'cuda' if torch.cuda.is_available() else 'cpu'
nn = resnet18()
distance = CosineSimilarity()
reducer = ThresholdReducer(low=0)
losser = TripletMarginLoss(
margin=0.2, distance=distance,
reducer=reducer
)
miner = TripletMarginMiner(
margin=0.2, distance=distance
)
dml = DML(
root, nn, losser, miner, device=device,
num_workers=num_workers,
output_dim=output_dim, batch_size=batch_size,
)
res = []
datafolder = datasets.DatasetFolder(
root, lambda x: x, ('jpg', 'jpeg', 'png')
)
labels = datafolder.find_classes(root)[0]
#from IPython.core.debugger import Pdb; Pdb().set_trace()
for epoch in range(0, 50, 10):
dml.load(f'epoch_{epoch}.pt')
metrics, label = dml.test()
tSNE_metrics = TSNE(
n_components=2, random_state=38038
).fit_transform(
metrics
)
r = pd.DataFrame(
{'dim0': tSNE_metrics[:, 0],
'dim1': tSNE_metrics[:, 1],
'label': label,},
).assign(epoch=epoch)
res.append(r)
dml.load('model.pt')
metrics, label = dml.test()
tSNE_metrics = TSNE(
n_components=2, random_state=0
).fit_transform(
metrics
)
r = pd.DataFrame(
{'dim0': tSNE_metrics[:, 0],
'dim1': tSNE_metrics[:, 1],
'label': label,},
).assign(epoch=50)
res.append(r)
res = pd.concat(res).assign(
idol=lambda d: d['label'].apply(
lambda x: labels[x]
)).sort_values('idol')
g = sns.relplot(
data=res,
x='dim0', y='dim1',
hue='idol', style='idol',
col='epoch', col_wrap=3,
)
g.savefig("tSNE.png", bbox_inches='tight')
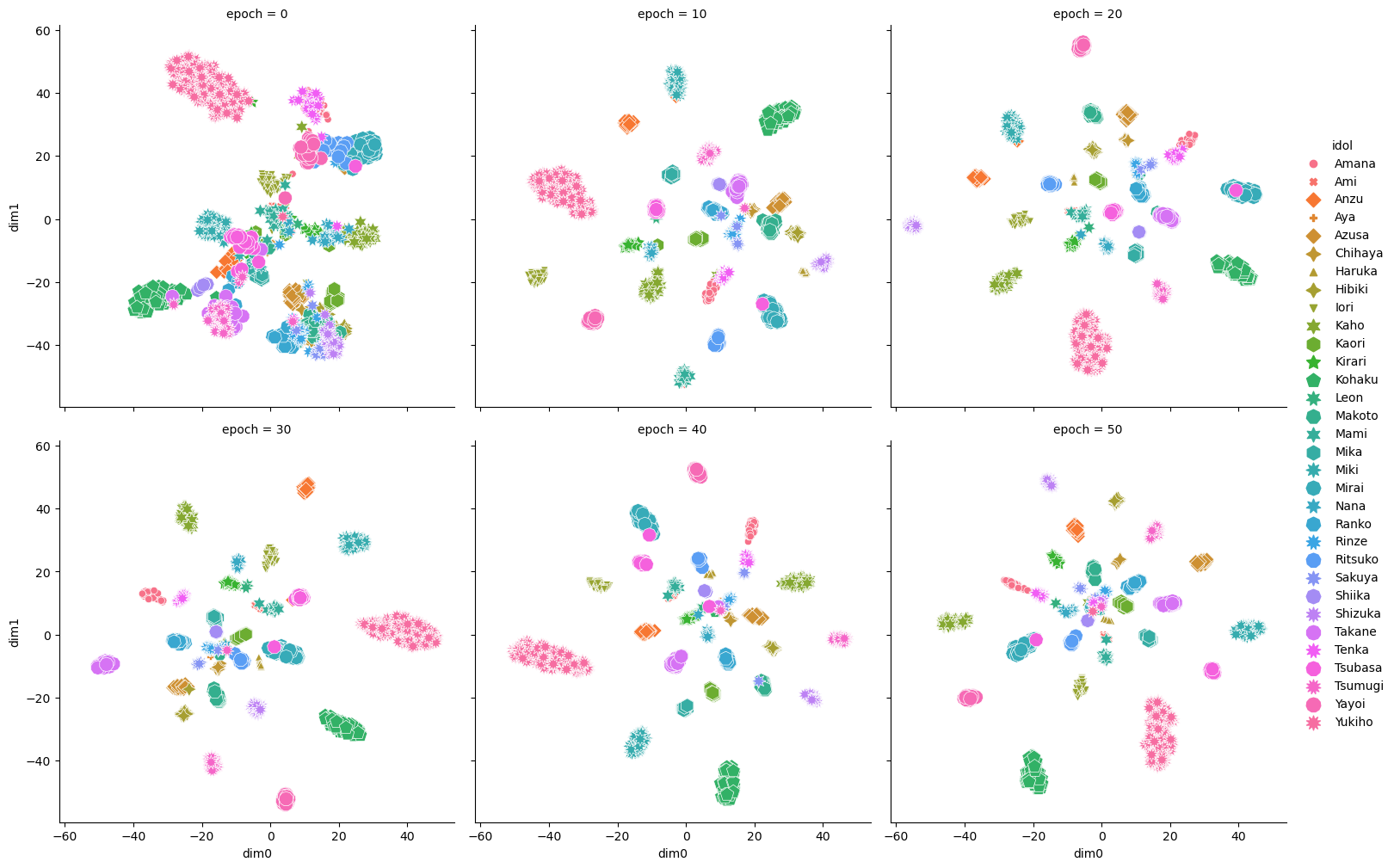
2次元に圧縮してる割には綺麗にクラスター=アイドルが分離されてる気がします.また10エポック以上は学習が進展していないようにも見えますね.実際,学習中に選択されるtripletがどんどん減少して途中から0個のケースも散見されました.このまま分類用の層を接続すれば分類タスクもきっとうまくいくでしょう.たった4千の教師データでもDNNは有用なんですね.準備の手間は全く無視できませんでしたが.
3次元に圧縮するGPLVM
次元圧縮がtSNEばかりでも芸がないため,ガウス過程回帰を用いたGPLVMを試してみます.また2次元の例もつまらないので3次元にします.
面倒なことにGPyの想定しているplolyはかなり古いようで公式サンプルをコピペしてもうまく描画できません.さらに面倒なことに,APIリファレンスを読んでも埋め込み後の点を取得する方法が明記されていません.ひとまずそれっぽいところを辿ってget_x_y_var()なる関数を発見しましたが,明記されていない以上いつまで使えるか怪しいです.
import plotly.express as px
import GPy
from GPy.plotting.gpy_plot.plot_util import get_x_y_var
class ImageTransform():
def __init__(self):
self.transform = transforms.Compose(
[transforms.ToTensor()]
)
def __call__(self, img):
return self.transform(img)
if __name__=='__main__':
# load DML result
metrics_luminous = np.load('epoch_45_test_predicted.npy')
labels_luminous = np.load('epoch_45_test_labels.npy')
idols = ['Amana', 'Ami', 'Anzu', 'Aya', 'Azusa',
'Chihaya',
'Haruka', 'Hibiki', 'Iori', 'Kaho',
'Kaori', 'Kirari', 'Kohaku', 'Leon',
'Makoto',
'Mami', 'Mika', 'Miki', 'Mirai', 'Nana',
'Ranko',
'Rinze', 'Ritsuko', 'Sakuya', 'Shiika',
'Shizuka', 'Takane', 'Tenka', 'Tsubasa',
'Tsumugi', 'Yayoi', 'Yukiho']
idol = [idols[i] for i in labels_luminous[-1]]
# GPLVM
input_dim = 3
m = (GPy.models.bayesian_gplvm_minibatch
.BayesianGPLVMMiniBatch(
metrics_luminous[-1], input_dim,
num_inducing=30, missing_data=True
))
m.optimize(messages=1, max_iters=5e3)
x, x_var, y = get_x_y_var(m)# No sample in GPy's API reference
df = pd.DataFrame(
x, columns=list('xyz')
).assign(
Idol=idol
).sort_values('Idol')
fig = px.scatter_3d(
df, x='x', y='y', z='z', color='Idol',
symbol='Idol'
)
fig.write_html('gplvm_test.html')
残念ながらCodePenの上限(1MB)に引っかかってしまってグリグリ動かせて,ポインタを当てるとラベルが表示できるplotlyのグラフを掲載できません.このため静止画のみ掲載します.

なんか3層になってました.しかし共通点も見出せなかったので偶然でしょう.
未知アイドルの埋め込み
本命.学習時に全く情報を与えていないアイドルが他のアイドルから離れた点になるかを確認します.これがうまく成功すると***DLCでどれだけアイドルが追加されようが,***CNNを固定して低コストで分類機を学習できます.なんなら転移学習して他のゲームのキャラクター識別にも使えるはずです.先ほどの続きです.
# DLC idols
# prepare dataset and dataloader
dataset = datasets.ImageFolder(
'Supporter', transform=ImageTransform()
)
dataloader = DataLoader(
dataset, batch_size=64, num_workers=4,
pin_memory=True,
)
# load model
model = resnet18()
model.fc = torch.nn.Linear(
model.fc.in_features, 128
)
model.load_state_dict(torch.load('epoch_45.pt'))
model.to('cuda', non_blocking=True)
# embedding
metrics = []
labels = []
model.eval()
with torch.no_grad():
for i, (inputs, label) in enumerate(dataloader):
inputs = inputs.to('cuda', non_blocking=True)
label = label.to('cuda', non_blocking=True)
metric = model(inputs).detach().cpu().numpy()
metric = metric.reshape(
metric.shape[0],
metric.shape[1]
)
metrics.append(metric)
labels.append(label.detach().cpu().numpy())
metrics = np.concatenate(metrics)
labels = np.concatenate(labels)
label = [['Kaede', 'Kotoha'][i] for i in labels]
# concatenate embedding results
luminous = pd.DataFrame(
metrics_luminous[-1]
).assign(
Idol=idol, DLC='X'
).sort_values(
'Idol'
)
supporter = pd.DataFrame(
metrics
).assign(
Idol=label, DLC='O'
)
y = luminous.append(supporter).reset_index(drop=True)
# GPLVM
m_ = (GPy.models.bayesian_gplvm_minibatch
.BayesianGPLVMMiniBatch(
y.iloc[:, :-2].to_numpy(), input_dim,
num_inducing=30, missing_data=True
))
m_.optimize(messages=1, max_iters=5e3)
x, x_var, _ = get_x_y_var(m_)
df_ = pd.DataFrame(
x, columns=list('xyz')
).join(
y.iloc[:, -2:]
)
fig_ = px.scatter_3d(
df_, x='x', y='y', z='z', color='Idol',
symbol='DLC'
)
fig_.write_html('gplvm_DLC.html')
さて静止画で確認です.
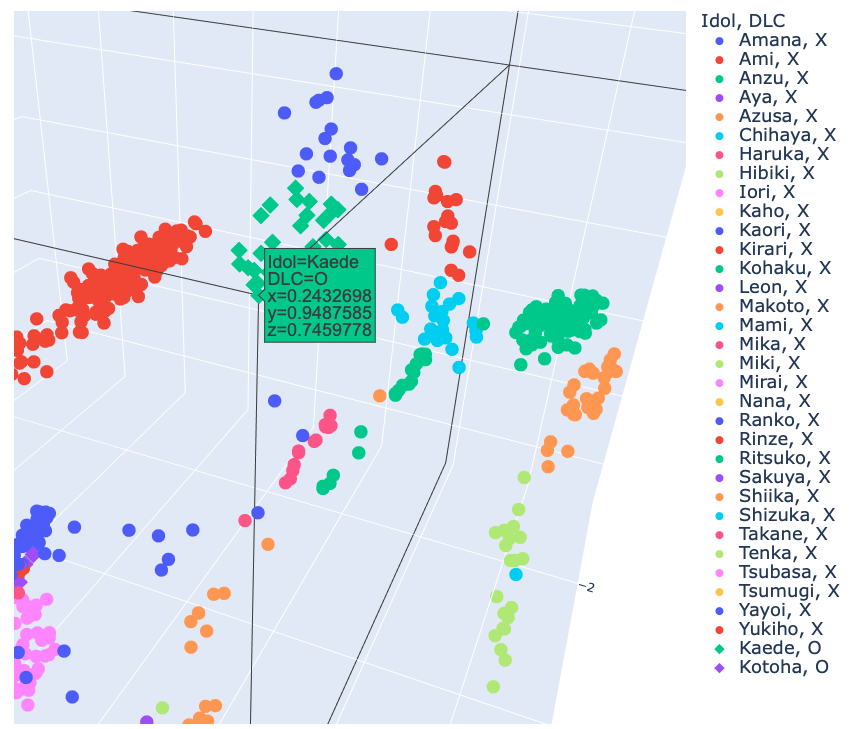
いい感じ.
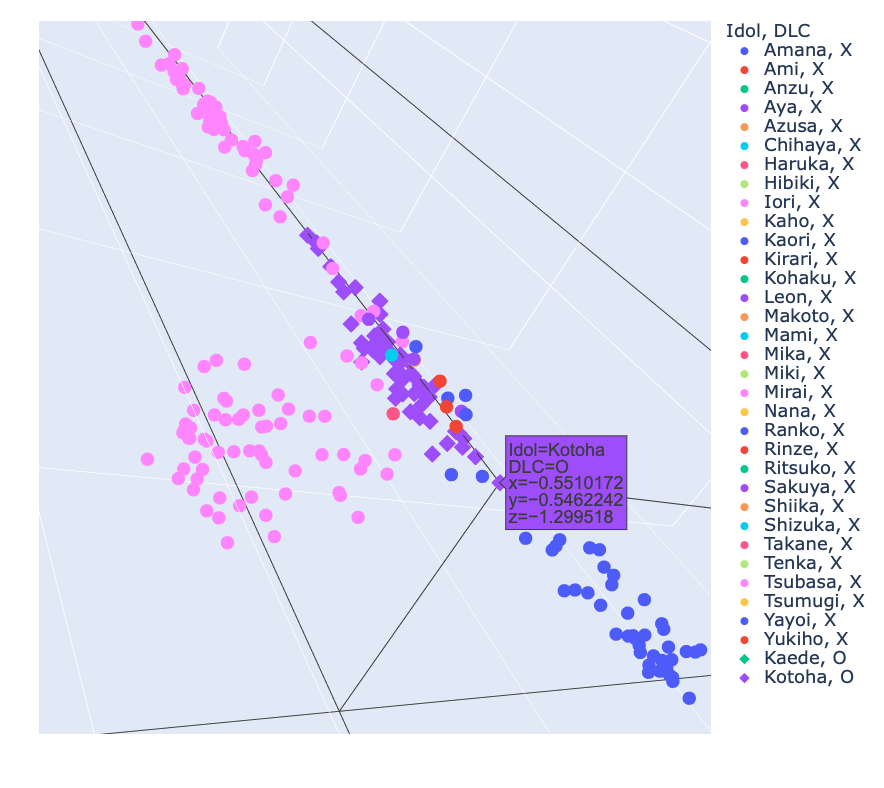
3アイドル(Amana, Iori, Mirai)の交点みたいなところに埋め込まれてしまいました.確かに髪の長さとか色とか似てます.その他,別のアイドルの外れ値も紛れています.ですが4千程度の学習データから未知データをこれだけ分離できているのは十分有効な手法だと思います.
Plotly Chart Studioで描画
グリグリ動かせるグラフを外部で保存しました.グラフ用のGPLVMの計算を保存しておらず再計算したため上記の結果と全く同じではありませんが,DLCアイドルのうちKaedeは分離できたのに対してKotohaはやはり他のアイドルに近い位置になりました.
結論
DMLで埋め込んだ空間は未知データもうまく分離できる.
データの公開
google driveで画像とpythonファイルと学習済みモデルを公開予定です.
公開しました.