自分が初めて本格参戦したKaggleのコンペである、MoAコンペが先日終了したので
振り返りのために書きます。Qiita記事を書くのは今回が初めてなので、見た目があまり
美しくない点は大目に見ていただければと思います。
追記:いろいろな方々からフィードバックをいただき、アンサンブルについて考え直しました。
そこで、反省点2の後に"アンサンブルをするのが遅すぎた"を加え、その後に続く反省点のインデックスを一つずつずらしました。
最終結果
とりあえず最終結果を。
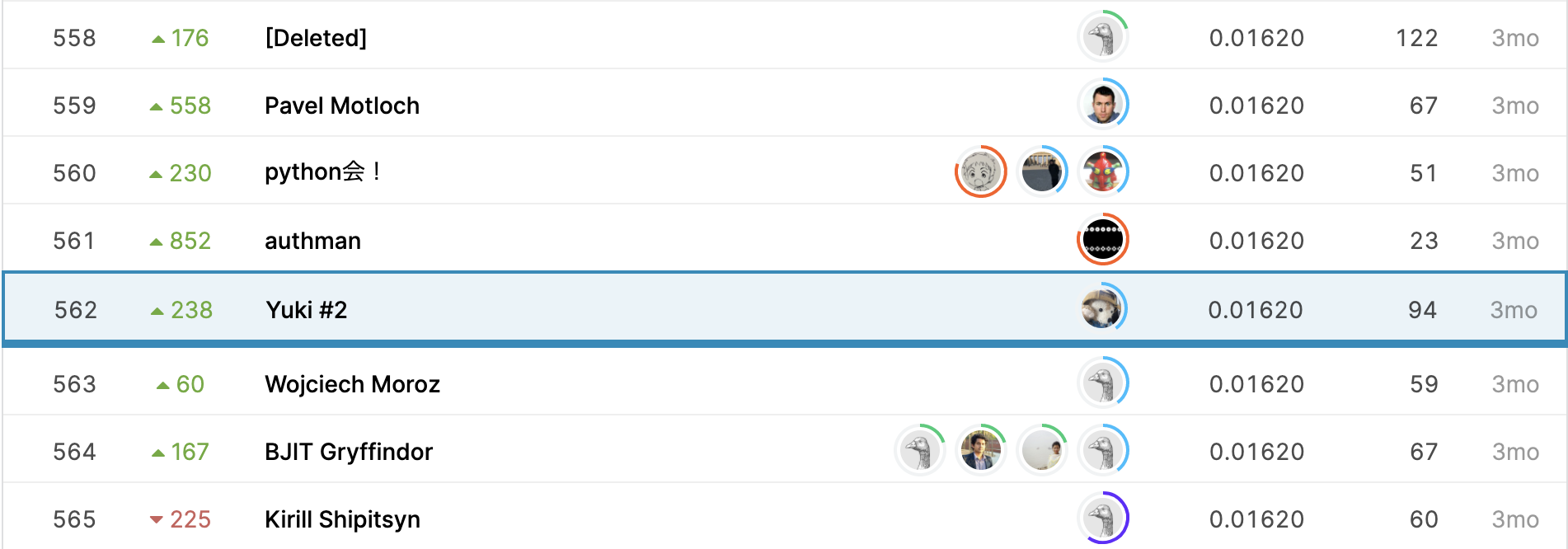
562/4373 上位13% でした。
少しだけshake upした感じですね。
軽く自己紹介
東京大学理科一類の1年生です。
専攻はまだ決めかねていますが、量子論あたりを深く学ぶことになりそうです。
まだよくはわかっていませんが量子機械学習とかいいなあと思ってます。
4月からプログラミングを初め、機械学習に持ち、現在は深層学習をメインに勉強しています。
7月あたりからKaggleでちゃんと活動し始めたContributorです。ここからProfileに飛べます。
そもそもKaggleとは?
Kaggleは企業や研究者がデータを投稿し、世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム及びその運営会社である。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
Wikipediaからの引用です。
簡単にいうと、企業がKaggleという団体に「この問題を使ってコンペを開いて欲しい!」と依頼し、Kaggleがコンペを開催して
世界中の人たちが自由に参加して精度を競い合うところです。(あんまり簡単になってないですね。)
各コンペの終了直前までディスカッションが行われているため、僕のようなアマチュアでも勉強することができます。
全て英語なので最初は少し辛いですが、すぐ慣れます。なんならDeeplで押し切れます。
MoAコンペとは?
めちゃくちゃ大雑把に言うと薬の性能を予測するコンペです。(色んなところから突っ込まれそう...)
MoAとは mechanism of action(作用機序) のことで、Wikipediaによると
薬理学における作用機序(さようきじょ、英: mechanism of action, MOA)とは、薬剤がその薬理学的効果を発揮するための特異的な生化学的相互作用を意味する[2]。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
もう少し詳しく書くと、
それぞれの薬が従来のどの薬の性能をカバーしているのか、それぞれの薬を使った実験データから予測して確率を出して、その精度を競うと言うものです。
参戦当初の目標
とりあえず完走する
もうこれに尽きます。と言うのは、実は僕はOSICコンペ(肺コンペ)に参戦していたんですね。
ところが開始一週間ぐらいで、セグメンテーションが必須みたいな空気に気付き、
「え...? じゃあ俺セグメンテーションからやらないとだめじゃん!」とセグメンテーションを勉強し始め、
その勢いでコンペそっちのけで統計や機械学習の理論の勉強に走り、そのままコンペが終了してしまいました。
今回はそのことを踏まえ、自分の至らぬところには目を瞑ってコンペ終了まで走り切ることを目標に設定しました。
その上でメダル獲得を目指しました。
反省点
まずは列挙してその後にそれぞれを詳しく見ていきます。
1.コード管理が杜撰だった
2.途中で無駄なアベレージングをしていた
3.アンサンブルをするのが遅すぎた
4.学習と推論でNoteBookを分けていなかった
5.終盤でやる気が失せた
6.データの内容をあまり把握できていなかった
7.Trust CV できなかった
8.単純にコーディング不足だった
1.コード管理が杜撰だった
もうこれがぶっちぎりの反省点です。とりあえず完走することを重視した弊害と言えます。
これはコンペ途中の僕のNoteBook名による管理の写真です。
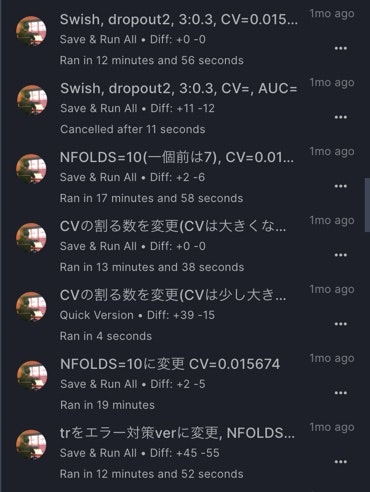
なんだこれ。マジで意味不明。
もう目もあてられない状況です。一応管理方法としては、"加えた代表的な変更とCVを書く"だったのですが、
名前の文字数制限が50字だったので、当然変更を全て書くことができません。後述しますが、度々モデルの細かい変更やパラメータチューニングを行っていたために、
「あれ?このモデルのハイパーパラメータって何がいいんだっけ...」
「え?いつここいじったの?いじらない方がよくね?」
みたいなことが頻発してどんどん時間が削られていきました。
1ヶ月半も参戦してた割に進捗が少ないのはここに原因があります。
これは完全にNoteBook名管理が崩壊してしまったときの僕です。
notebook名による管理がもうほぼ崩壊してる。
— ユウキ | Kaggler (@No1Yuki33937424) November 14, 2020
一番いい時のLBに戻れない。
厳しすぎてコンペ撤退が頭にちらつくレベル。
誰か助けてくれ本当に。
まさかここで足元をすくわれるとは思ってなかった。
辛かった...
それによる弊害をいくつか列挙しておきます。
・ハイパーパラメータの調整をしすぎた
前述の通りです。正直最後に集中してやれば良かったと反省してます
・戻したいバージョンに戻ってくれない
ここでもかなり時間を無駄にしました。
・これ以上崩壊するのが怖くて前に進めなくなる
これがかなり敗因として大きいです。後の話にもつながります。
2.途中で無駄なアベレージングをしていた
特徴量をふやすなり、label smoothingを入れるなりしてCVが改善するたびに、
seedを10個とかにしてアベレージングをしていました。
それだと学習だけでも2時間かかり、加えて推論のNoteBookを分けていなかったこともあり、
GPU quotaをかなり消費していました。コンペ後半に反省してやめましたが、損失は大きいです。
アンサンブルをすればスコアは伸びますが、それでLBを上がっても、結局終盤にはみんなやるのであまり意味はありません。
モデルを変えるたびにアンサンブルをすることはやめます。
(もちろん過度にやらなければ、モデルのポテンシャルを図ると言う意味ではいいことだと思います。)
3.アンサンブルをするのが遅すぎた
一見2と矛盾してるように思えますがそうではありません。
ここで一応(ここで用いている)言葉の定義をしておきます。
・アベレージング : シングルモデルでseedを増やして単純に平均をとる
・アンサンブル : 複数のモデルの出力を混ぜる
厳密にはアンサンブルはアベレージングを含む包括的な概念なので、この分け方は適切ではありませんが、
便宜上ここでのみ分けます。
僕がアンサンブルをしたのはコンペ終了一週間前あたりです。単純に4つのモデルの平均をとっただけです。
銀圏に入る予定がまさかのメダル圏内。スコアの伸びが想像以上に渋かったです。
このことから言えるのはアンサンブルはスコアの急上昇を保証するものではないと言うことです。
上位者のsolutionを見ると、自分との決定的な違いの1つはアンサンブルのパイプラインにあります。
アンサンブルをどう組むかを考える時間が取れなかったことは、今となっては大きな敗因です。
ではどうすべきだったか。
アンサンブルに関しては、ギリギリまでシングルモデルで粘る派と、最初からアンサンブルする派に分かれているように見えます。
僕個人の見解としては、2つのどちらかが絶対に正しいと言うことはないと感じています。
ただ、そこにはトレードオフがあり、何を優先するかで立場がどちら寄りになるかが変わると思います。
議論の前提として、モデルの改善をするためにシングルモデルでのSubmitはしっかりとるものとします。
(そうでないと、実験結果の解釈が困難になりかねないからです。)
すると、前者 <-> 後者 で
要するSubmit数・時間 : 減る <-> 増える
アンサンブルによるスコア上昇の情報利得 : 減る <-> 増える
のようになると考えています。(他にも色々あるかもしれません)
自分はアンサンブル後のスコアの情報を全く得ないまま終盤に突入したため、明らかに間違えています。
恐らく、本当に強い方々が用意が出来次第アンサンブルをしながら戦うのは、そういったアンサンブルによる負の側面を(LBを上がったことで慢心するみたいなメンタル面も含みます)、呼吸をするようにコントロールしているからだと思います。
自分は恐らくそれは無理なので、アンサンブルに関してはあと何回かコンペに参加して、適切なペースを掴まなければいけません。次回のコンペは動きを変えて、(あくまでやりすぎない程度で)初めからアンサンブルもしていきたいと思います。
4.学習と推論でNoteBookを分けていなかった
2.とも絡みますが、コンペの途中まで、モデルごとに学習と推論を同じNoteBookでしていたために
学習のみと比べ2倍のGPU quotaを消費してしまっていました。
週末にGPU quataが切れて動けなくなることが頻発したので、次回からは最初から分けてSubmitします。
5.終盤でやる気が失せた
コード管理が破綻して戻すのに大苦戦した後、「これ以上いじったら本当に戻せないかもしれない」と怖くなって放置気味になってしまいました。
また、コンペ終盤でDiscussionでshakeについての議論が活発になり、全てがOverfitに見えてしまっていたのも大きいです。
privateのスコアを見る限り、終盤でメダル目前まで迫っていたようなので惜しいことをしたと思っています...
6.データの内容をあまり把握できていなかった
何を予測していたのか本当に理解できたのは、コンペの終了後に上位者のチーム内の議論を見た後です。
正直これではメダルを取れなくて当然だと反省しています。
「自分は物理と化学で入試を受けたから理解できなくても仕方ないや」と諦めていた部分がありました。
コンペを終えて、本当に銀圏や金圏に入れるのはコンペ主催者が提示している課題を真に理解してそれに適切にアプローチしている人であると理解しました。
それこそが(恐らく)Kaggleの本質であり、自分のように終始モデルをガチャガチャやっているようではいつまで経っても勝てないと感じています。
7.Trust CV ができなかった
これは実際にコンペ終盤になって真に難しさを理解しました。
正直、コンペに参加する前は舐めていた部分がありましたが、いざ最終サブを選ぶとなると想像以上に怖かったです。
数週間にわたる取り組みがここで全て決まる、と思ったらデータの一部であっても見える形で順位が出ているLBにすがりたくなるのが
人間の性であり、だからこそ「Trust CV」がここまで有名な言葉になっていることがそこでようやくわかりました。
メンタル面もそうですが、ちゃんと信頼に値するCVを自分で組めるかという技術面が最も大事です。
そう言う意味では今回のコンペは使っているCVがほとんどみんな同じだったため、Trust CVすることはそこまで難しくなかったと思います。
大反省です。
8.単純にコーディング不足
これは言わずもがなです。最後にEfficient Netを使用したNoteBookを自分のパイプラインに組み込もうとしましたが、コードが理解できず
諦めてしまいました。1th solutionを読む限りではアンサンブルに効いていたようなのでもったいなかったと思います。
(ただ、他のsolutionにはそれほど多くは出てきていないので一概には言えませんが)
良かった点
甘めな自己評価ではありますが、一応列挙します。
・完走できた
当初の最大の目的です。しかしメダルは取れなかったので、正直微妙です。
・色々試せた
終盤では減速しましたが、一応アイデアは40個程度試せました。もうやることないよ...と言う状況にはならなかったことは救いとも言えます。
・論文も読んでみた
途中で伸びてきたTabNetに関しては論文もしっかり読み、GitHubに貼られていたリンクからYoutubeでのTabNetのプレゼン動画も見たりしました。
結局モデルの細部を把握するにはいたりませんでしたが、論文までしっかり読む取り組み方は今後も継続します。
今後の予定
上述の反省点も踏まえていくつか列挙します。
・Git, GitHubを勉強する
実はコンペ参加前にも一度勉強していたのですが、実際に使うレベルにはいたりませんでした。ぶっちゃけドラクエの教会でのお祈りと何も変わらんと思ってた。
最低限は使えるようにしました。ここからリポジトリに飛べるようになっているので、もしご覧になりたければ是非。
・E資格に向けた勉強をする
コンペ参加前に勢いで申し込み、講座を全て受けたっきりになってしまっているので...
G検定ほどは甘くないような感じがしますが、まあこれまでの復習もかねて勉強します。
・キャッサバコンペに出る
Riiid!コンペは忙しい期間と丸かぶりしているので残念ですが見送ります。
あとは、自分はE資格の最終プロダクト課題にキャッサバコンペのデータを使ってもいいようなので、
それも兼ねて、かつコード管理ツールのアウトプットも兼ねて参戦します。
まだ方向性は模索中ですが、最終的には画像コンペを中心にメダルを取りたいと考えています。
終わりに
いかがでしたでしょうか。恥を恐れず、等身大の文章を書いたつもりです。
周りの方々が化物すぎて、全力で取り組んでメダルを取れなかった自分はもうだめだと一時期は自暴自棄になりかけましたが、そんなことはないと信じています。公開NoteBookに頼りすぎない、肩書きに見合う実力を持つKagglerになれるように頑張ります!