前回Octoparseというツールを紹介し、そのツールの登録、ダウンロード、インストール、データ抽出などの利用方法を紹介しました。(前回の内容の詳細については、こちらをご覧下さい。)今回は、Octoparseをもっと理解して頂くために、主な特長、具体例による使用方法および幾つかの拡張機能を紹介します。
1.概要
Octoparseは、簡単かつ非常に視覚的に理解しやすいWebスクレイパーであり、あまりプログラミングの知識が無い人でも、Webからデータを収集して抽出することができます。
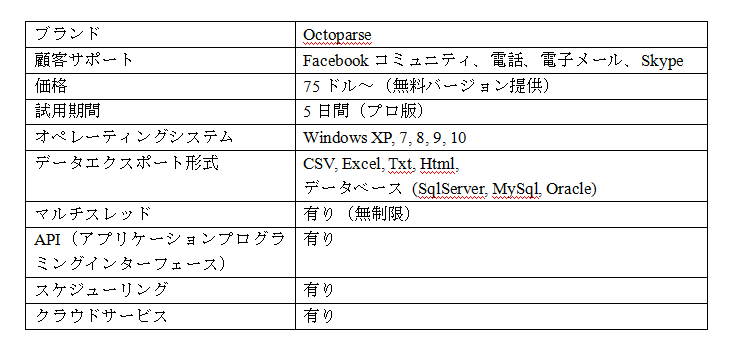
2.Octoparseの主な特長の紹介
(1)クリックとドラッグによる簡単なWebスクレイピング
Octoparseは、全てのユーザーがWebスクレイピングを利用できるようなツールです。そのインターフェースは、ユーザーが非常に視覚的に理解しやすい操作画面のペイン(領域)となっています。基本的には、「クリック」、「ポイント」及び「ドラッグ」で、既存のWebサイトの98%をスクレイピングするのに非常に機能的なワークフローを作成できます。
(2)動的なWebサイトへの対応
より複雑なスクレイピングについて、例えば、データが相互交流型のWebサイト上でJavaScriptを使用して読み込まれるとき、Octoparseは下記の全ての場合において解決案を提供することができます。
ログイン後のスクレイピング
検索ベースの抽出
Ajaxで読み込まれたスクレイピングデータ
無限スクロール
「Next」ボタンが無いページネーション
ネスト(入れ子)構造のドロップダウンメニュー
フォームへの記入
HTML内で非表示にされたキャプチャデータ
などなど。
Octoparseは全てのユーザーがデータをクローリングできるように設計されています。Octoparseに内蔵されているXPath及びRegExツールを利用することにより、開発者はもちろん、開発者以外の人でも、Webページ上の一つ一つの要素を簡単に完全照合できます。(直接拡張機能のページをご覧下さい。)
(3)サポート
無料版を使用しているユーザーの場合、FacebookのOctoparseグループのヘルプを参照して下さい。そのコミュニティのグループメンバーたちは熱心に協力して説明してくれると思います。また、Octoparseサポートに連絡する方法もありますが、対応に時間が掛かるかもしれません。
有料版を使用しているユーザーの場合、Octoparseチームが優先的に対応し、電話、電子メール及びSkypeを通じてサポートします。
3.具体例による使用方法の説明
上記では、Octoparseの主な特長について簡単に紹介しました。ここでは、さらに知りたい場合に備えて、シナリオを作成し、具体例を挙げて説明します。
あなたは、自分が東京に引っ越してきたばかりの若い従業員だと想像してみて下さい。最初に解決すべきことは、賃貸アパートを探すことですよね?賃貸アパートに関する情報はネット上にたくさんあるので、どの賃貸アパートに決めれば良いかわからないと思います。ここで、もし整理された賃貸アパートのリストがあれば、より簡単に比較することができますよね?Octoparseはそのような場合に役に立つ最良のツールになると思います。
suumo.jpは不動産・賃貸住宅に関する最大の総合情報サイトで、投資家、新入社員および住宅需要のある人向けに多くの情報を提供しています。自分が、渋谷駅、新宿駅、原宿駅から15分以内で、家賃が15万円以下のアパートを探していると仮定して、今からOctoparseでスクレイピングしてみましょう。
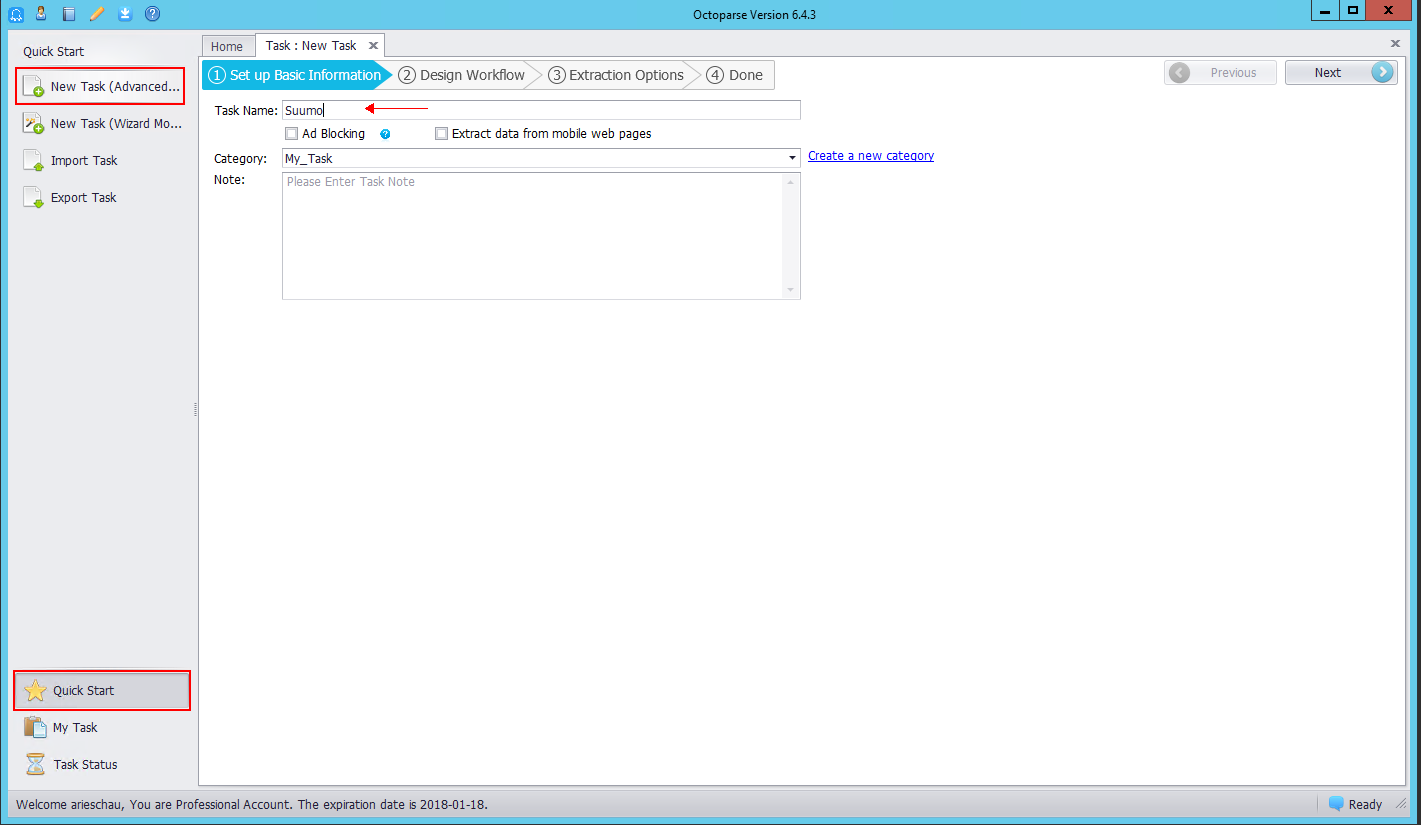
ステップ1.Basic Informationを設定します。
「Quick Start」をクリックします。➜ New Task (Advanced Mode)をクリックします。➜Basic Informationを完成させます。
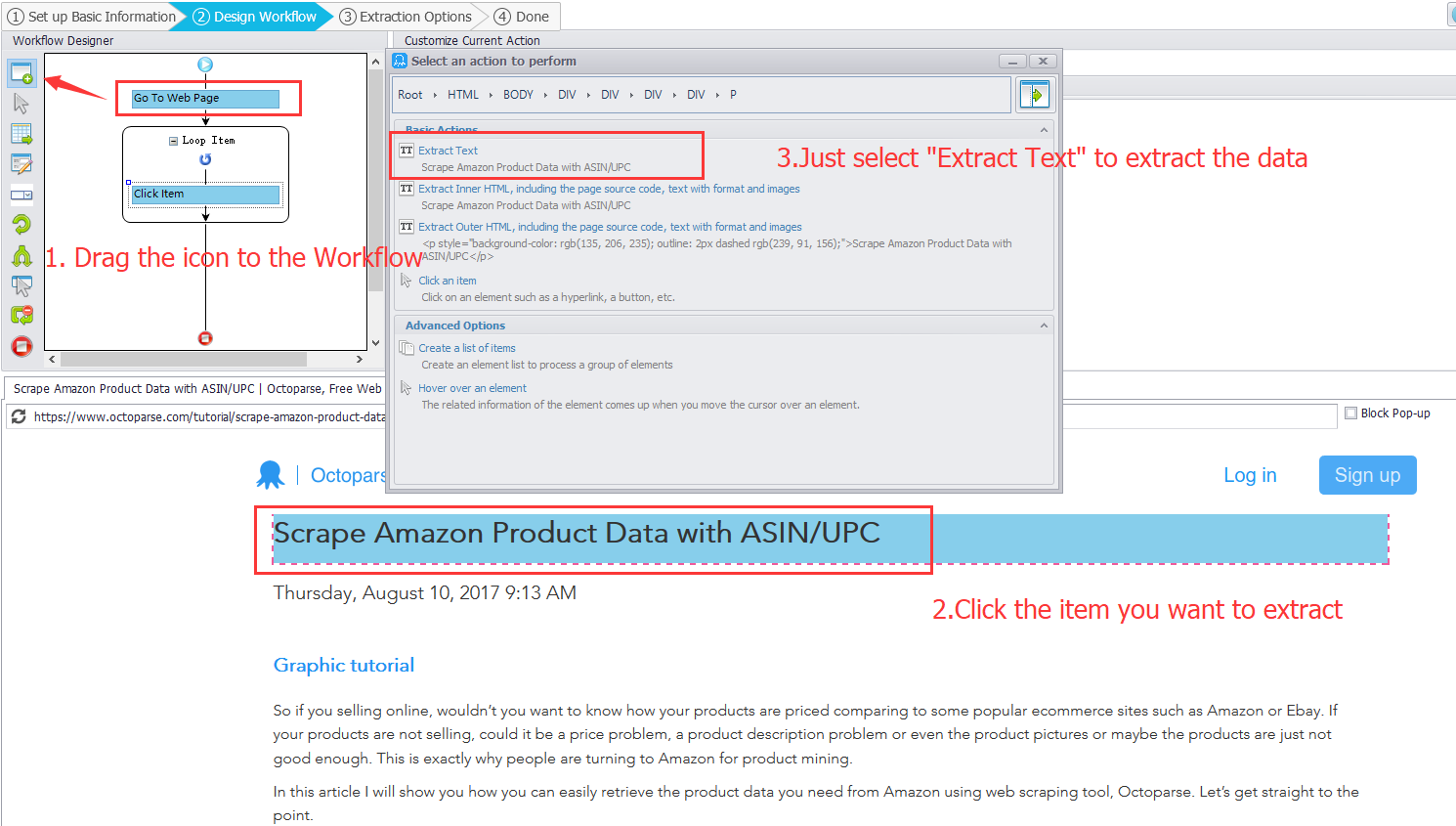
ステップ2.内蔵されているブラウザで検索したいWebサイトに移動します。
内蔵されているWeb ブラウザに検索したいURLを入力します。➜ 「Go」をクリックしてサイトを開きます。
URLの例:
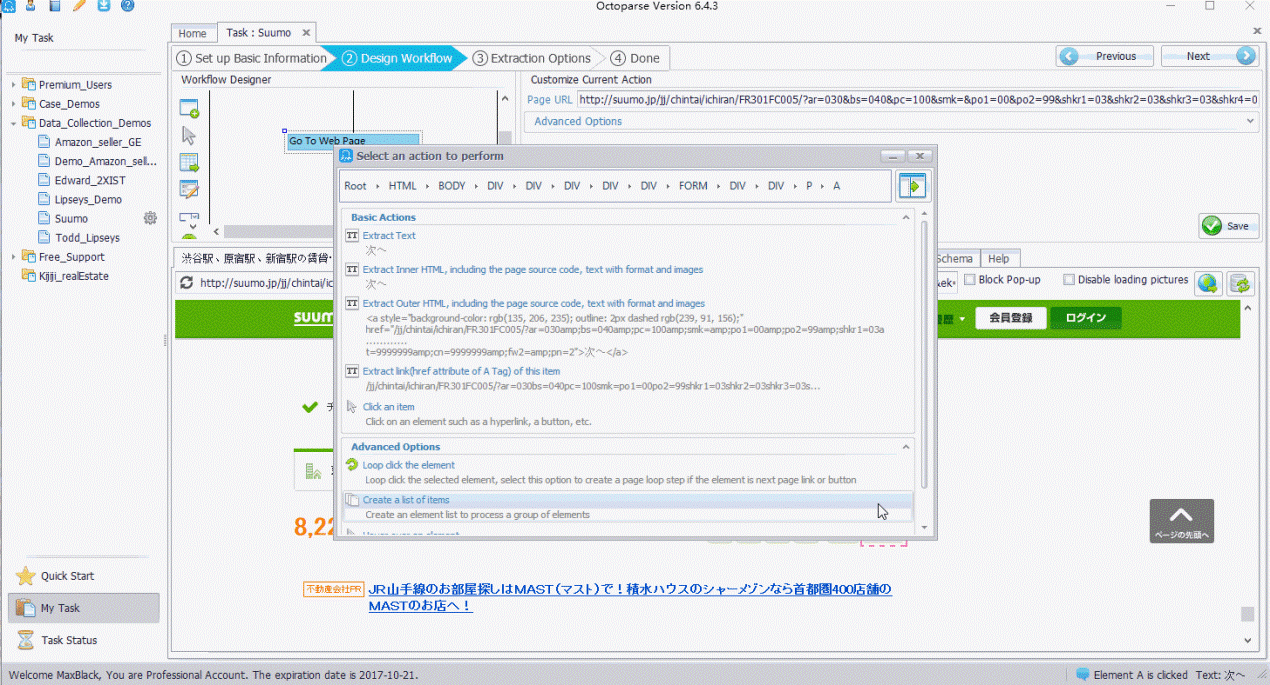
ステップ3.ページネーションを設定します。
「次へ」(ページネーションリンク)をクリックします。➜「Loop click the element」を選びます。
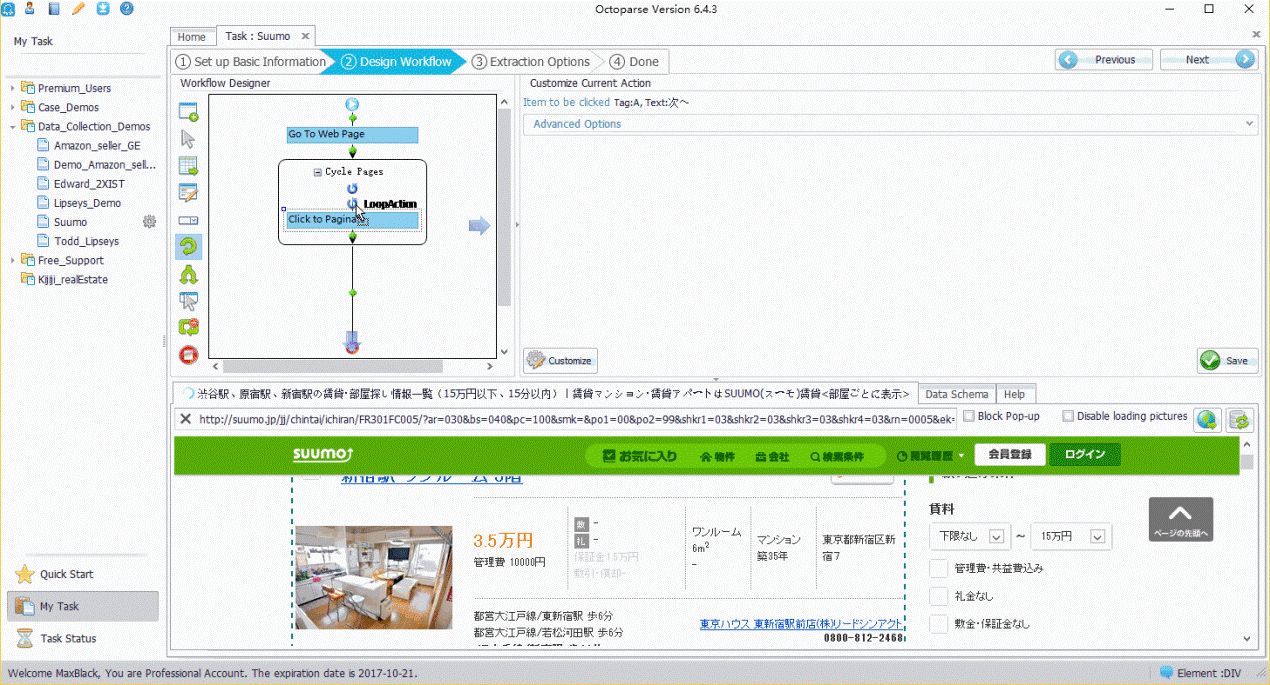
ステップ4.項目のリストを作成します。
「Loop item」をWorkflowにドラッグします。➜「Variable list」を選びます。➜その下の「Variable list」の横にある空欄に、下記のXPathを貼り付けます。➜「Save」をクリックします。
XPath://div[@class='property_group']/div(XPathの詳細については、こちらをご覧下さい。)
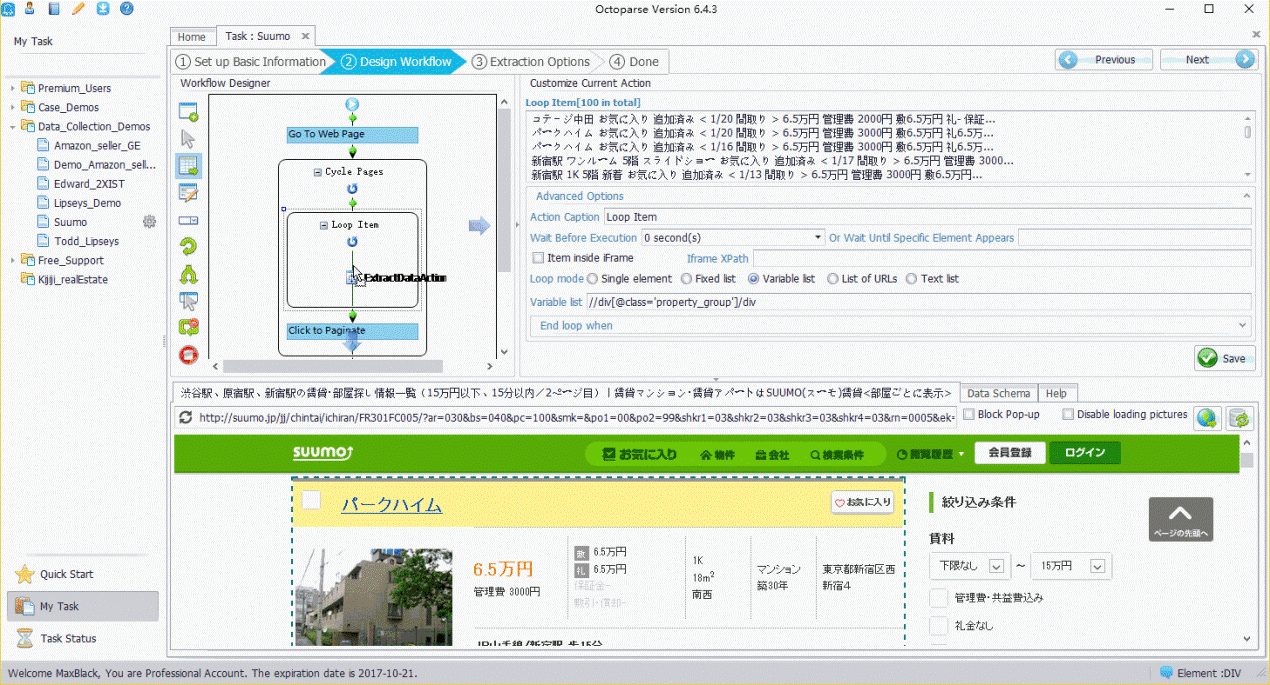
ステップ5.検索結果を抽出します。
タイトル部分を抽出します。➜タイトルをクリックします。➜「Extract text」を選びます。他のコンテンツも同じ方法で抽出することができます。
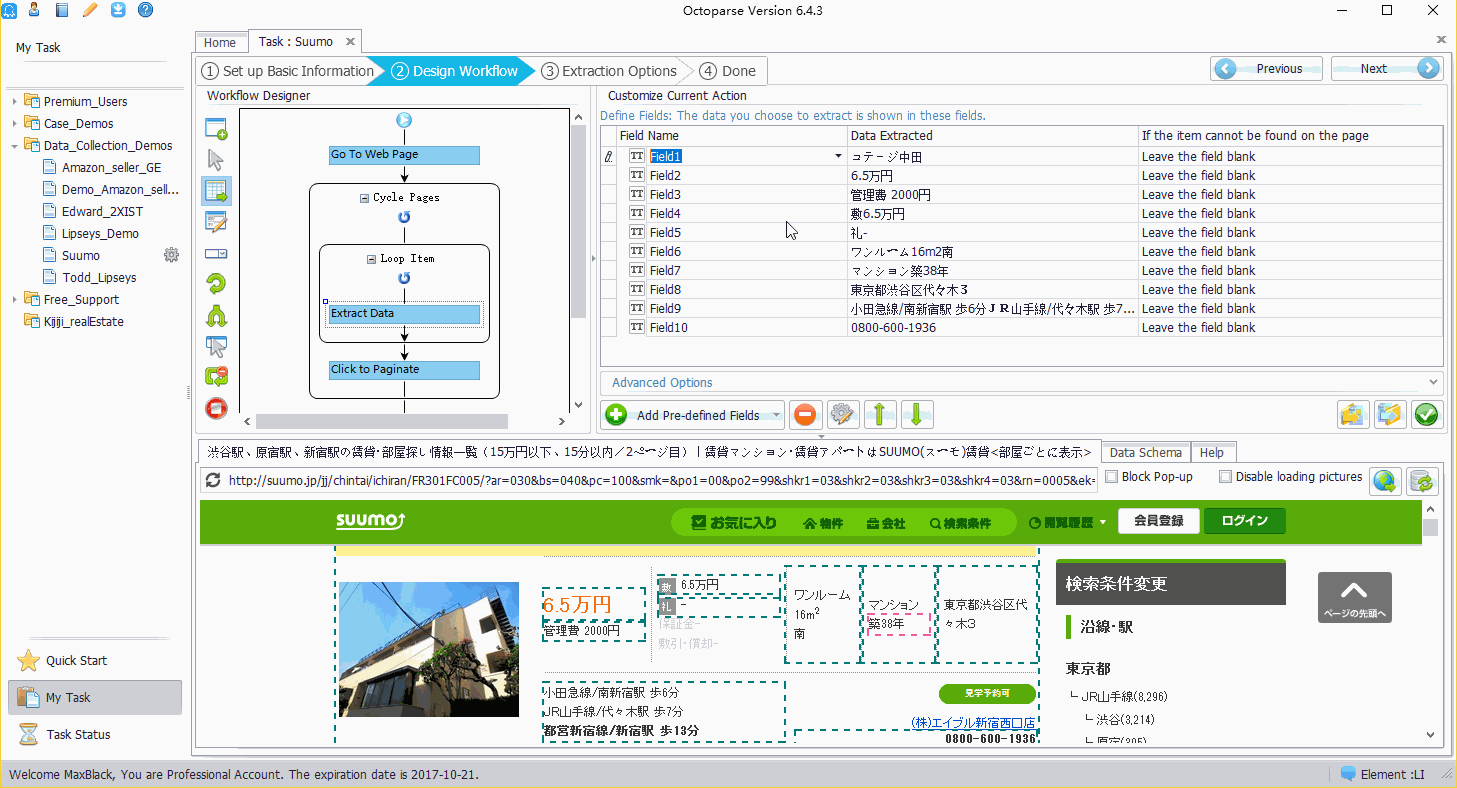
ステップ6. 抽出されたData Fieldの名前を修正します。
全てのData Fieldは抽出されると、自動的に名前が付けられます。➜名前を修正したい場合は、「Field Name」をクリックして修正します。
ステップ7.ページネーションのXPathを修正します。
Octoparseで設定されたデフォルトのXPathでは、「次へ」という項目を正しく配置できないので、XPathを修正する必要があります。修正されたXPathは次の通りです。
//P[@class='pagination-parts']/A[contains(text(),'次へ')] (XPathの詳細については、こちらをご覧下さい。)
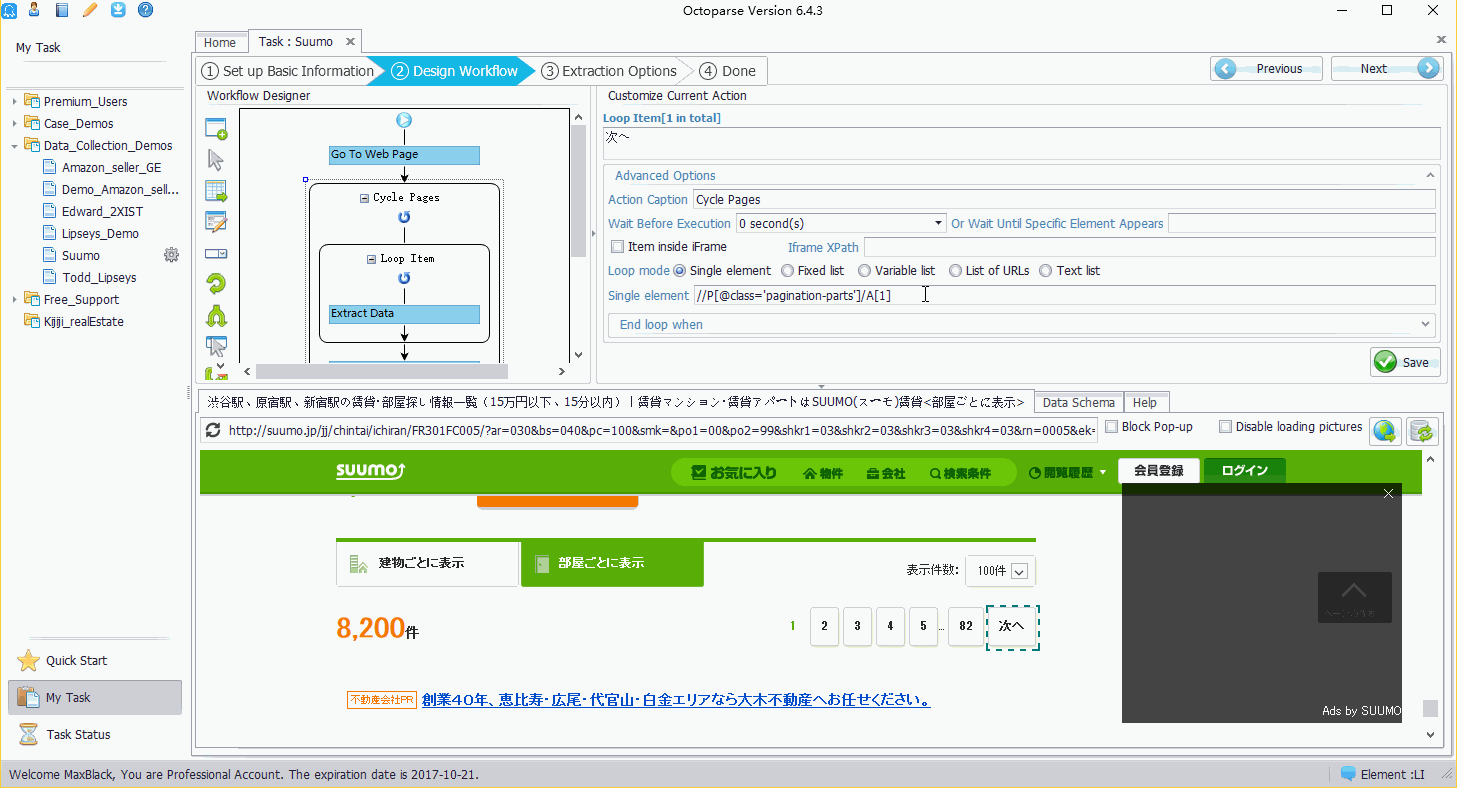
ステップ8.エクストラクタを実行します。
「Next」をクリックします。➜「Next」クリックします。➜「Local Extraction」をクリックします。➜「OK」をクリックしてコンピューター上でタスクを実行します。Octoparseは、指定した全てのデータを自動的に抽出します。
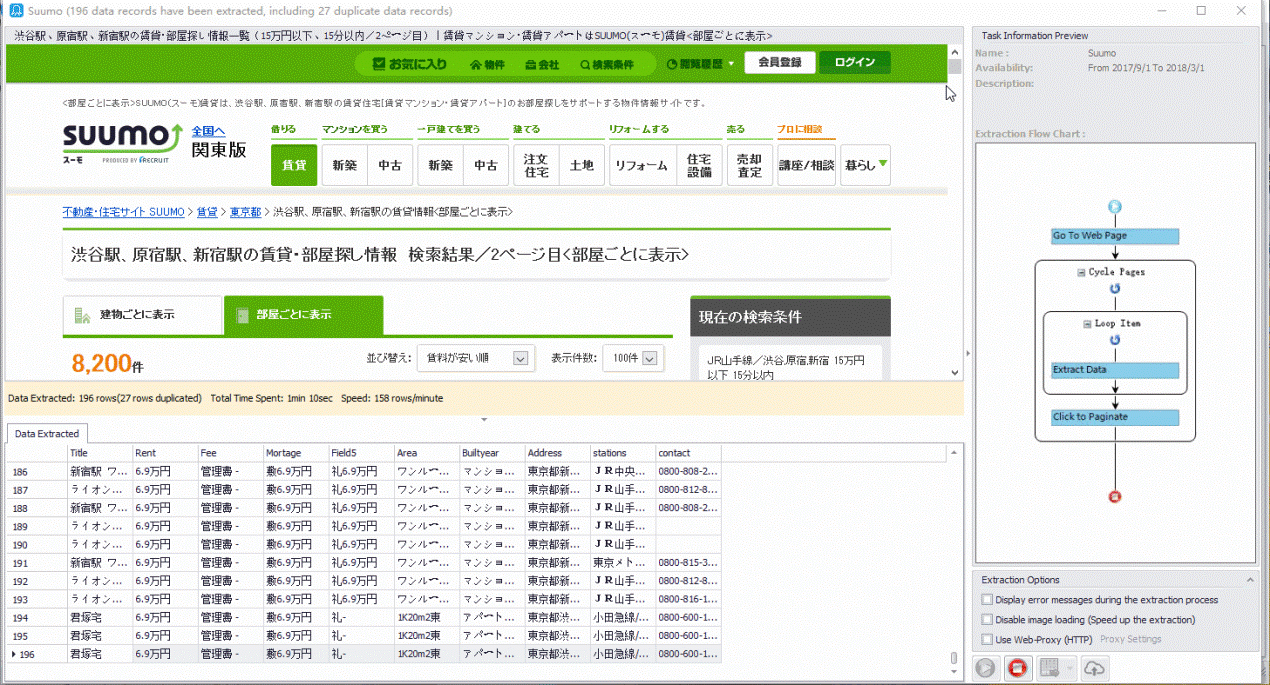
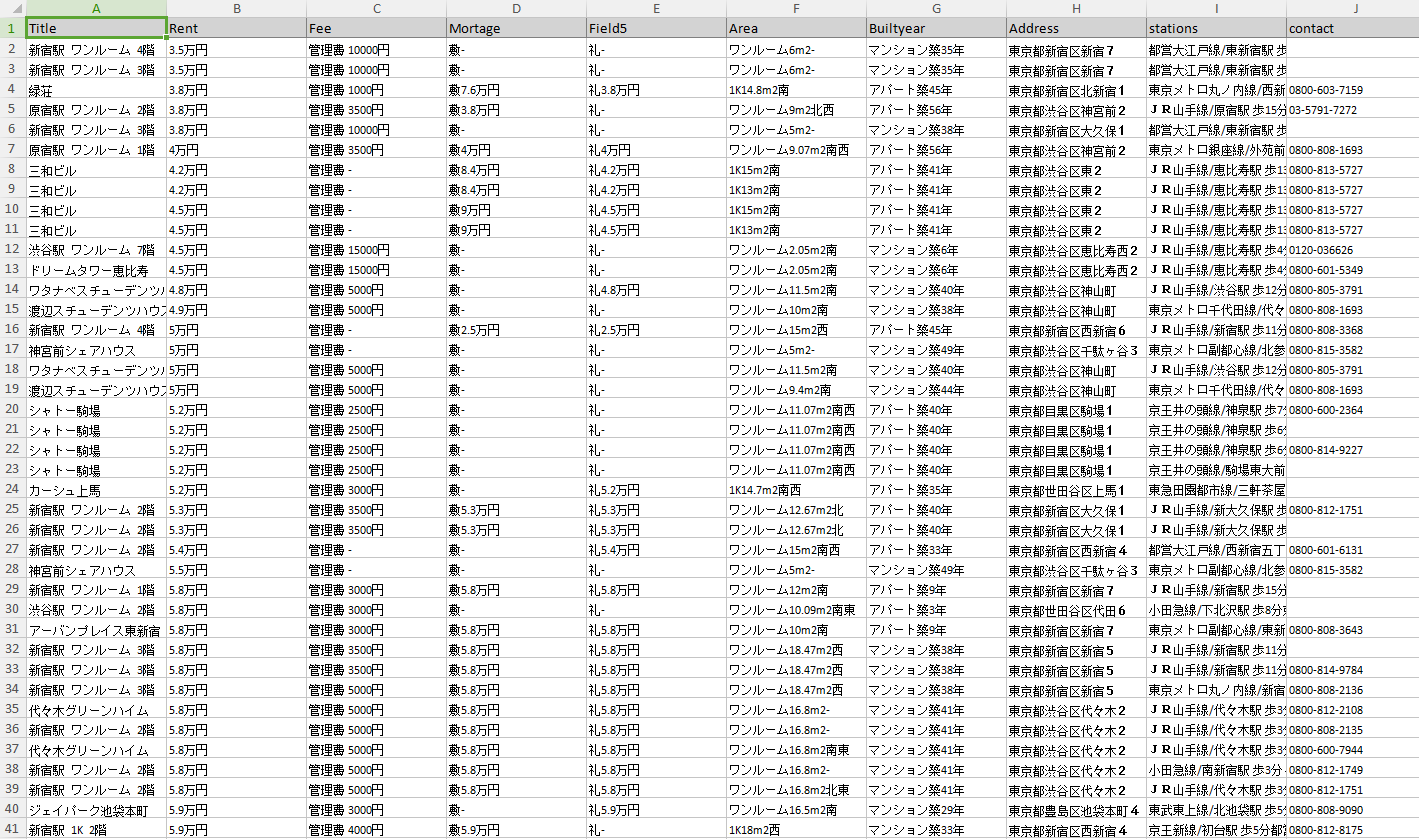
以上のステップが全部完了したら、下記のようなきちんと分類されたデータが得られます。
4.Octoparseの拡張機能の紹介
(1)Xpath及びRegEx(正規表現というツール) - ネクストレベルのWebスクレイピング
XPathと正規表現は、複雑なWebスクレイピングをするために必須の技術ですが、初心者が利用するのはそう簡単なことではありません。そこで、Octoparseチームは、正確なWebスクレイピングをするのに必要なXPathとRegExについて、誰でも簡単に作れるように十分配慮されたツールを提供しています。
a.XPathツール
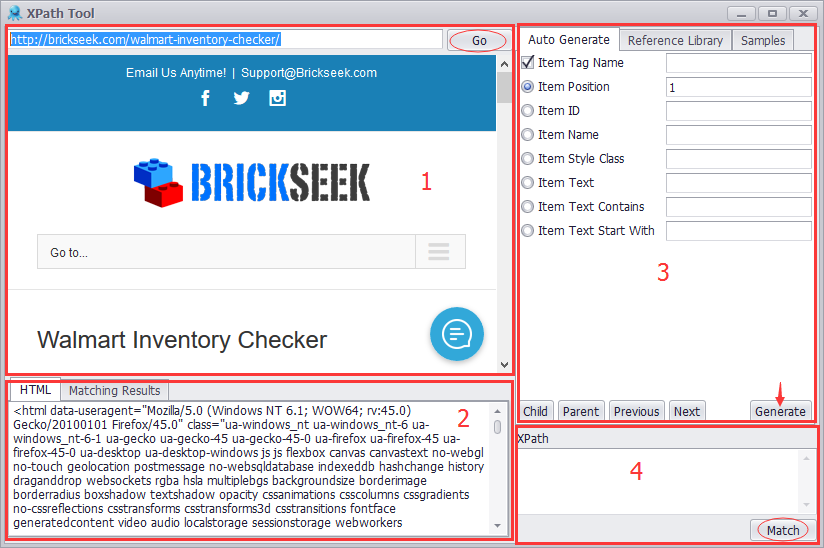
OctoparseのXPathツールの画面は、4つのペイン(領域)で構成されています。
ペイン1:ブラウザのペイン。内蔵されているブラウザで検索したいURLを入力し、「Go」をクリックすると、Webページのコンテンツが表示されます。
ペイン2:ソースコードのペイン。Webページのソースコードが表示されます。
ペイン3:XPathの設定のペイン。選択肢をチェックし、幾つかのパラメーターを入力して、「Generate」をクリックすると、XPath式が作成されます。
ペイン4:XPathの結果のペイン。XPathが作成された後、「Match」をクリックすると、現在のXPathがWebページの要素を見つけているかどうかを確認できます。
OctoparseのXPathツールの詳細については、こちらをご覧下さい。
b.RegEx(正規表現)ツール
正規表現とは、文字列内での文字の組み合わせを照合させるために用いられるパターンです。どんなスクレイピングシナリオでも、例えば、CSSセレクタやXPathがうまく動作しない場合でも、正規表現構文を使用して必要な情報をすぐに検索することができます。XPathツールと同様に、Octoparseには内蔵されているRegExツールがあります。このRegExツールがあれば、ユーザーは文字や文字列の一致に苦労する必要は無く、シンプルに幾つかの条件を入力するだけで、RegExは自動的に作成されます。
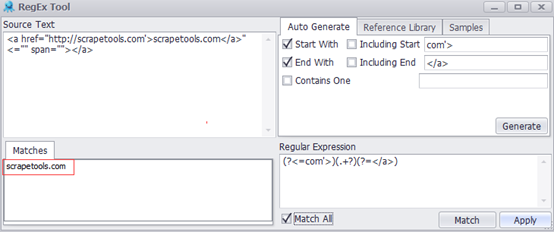
OctoparseのRegExツールの詳細については、こちらをご覧下さい。
c.データの再配置(再フォーマット)ツール
さて、欲しいデータをうまく抽出しましたが、そのデータは利用しやすい形式ではありません。例えば、日付の書式が間違っていたり、単語間に不要な空白があったり、不要な接頭辞や接尾辞が付いていたりする点です。そこで、Octoparseは内蔵されたデータの再配置ツールを使用して、簡単に必要なデータ変換をできるようにしました。サポートされている変換機能は次の8個になります。
①Replace:抽出したデータの文字列やキーワードを置換します。
②Replace with regular expression:特定の正規表現に一致するコンテンツを置換します。
③Match with regular expression:乱雑な単語の中から目的のキーワードを選び出します。
④Trim spaces:抽出したデータの前後の空白を削除します。
⑤Add prefix:抽出したデータの先頭に必要なもの(番号、文字、信号など)を追加します。
⑥Add suffix:データの最後に何かを追加します。これは「Add prefix」とちょうど逆になります。
⑦Re-format extracted date/time:希望の日付や時刻の書式を設定し直します。
⑧Html transcoding:HTMLソースを抽出するときに、HTMLエンコードされた文字をエンコードされていないテキストにデコードします。
Octoparseにキャプチャされたデータの再配置の詳細については、こちらをご覧下さい。
(2)クラウドサービス
Octoparseは、ユーザーのスクレイピング技能をさらに強化するために(有料版を使用しているユーザー向けに)クラウドサービスを提供しています。このクラウドサービスでは、次の4つのオプションが使用できます。
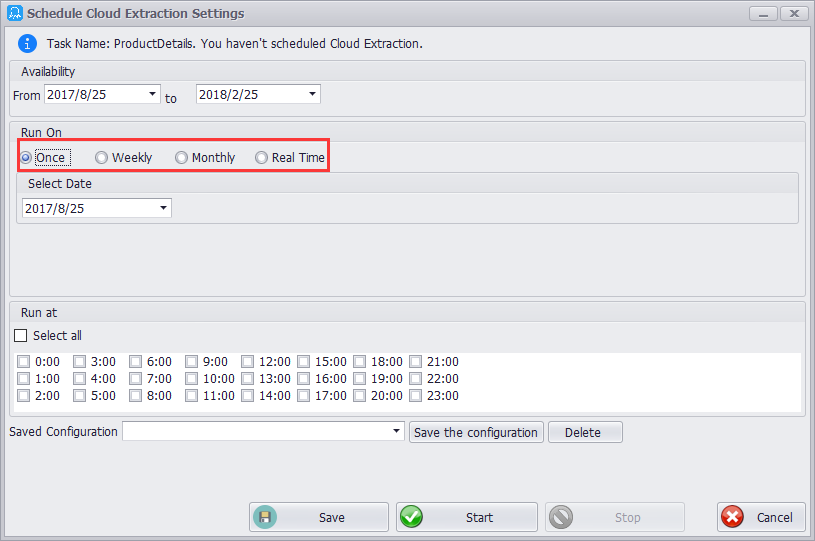
①スケジュール通りの自動データスクレイピング
ユーザーは、いつでも、たとえリアルタイムでも、スクレイピングを実行できるようにクローラーの予定を決めることができます。
②リアルタイム抽出のためのAPI経由での接続
RESTful APIに接続すると、抽出されたデータをリアルタイムなど任意の希望する頻度で取得できます。
③IPブロッキングを防ぐIPローテーション
これまでに、Webサイトをよくスクレイピングする場面で、IPアドレスが使えなくなってWebサイトにアクセスできなくなって、ものすごくイライラしたことがありますか?ありますよね。例えば、ソーシャルプラットフォームや企業電話帳などの注目を集めるWebサイトからデータを抽出している場合は、特によく起こります。しかし、Octoparseを使用すると、匿名のHTTPプロキシ・サーバーを何台も使い回して、ブロックされる可能性を最小限に抑えることにより、これらのWebサイトをスクレイピングすることができます。
④データのデータベースへの自動エクスポート
Octoparseのクラウドサービスは、SQLサーバー、MySQL及びOracleのデータベースへの自動エクスポートもサポートしています。ここの説明を読み、データベースをOctoparseに接続する手順に従って下さい。
5.まとめ
Octoparseは、機能豊富な視覚的に理解しやすいWebスクレイピングツールです。特に、ノンテクニカルユーザーが簡単にWebスクレイピングできるという点では、間違いなく支持できます。Octoparseのソフトウェアは、優秀かつ汎用性が高いので、ほとんどの動的なサイトをかなり簡単にスクレイピングできます。また、無制限のWebページのスクレイピングをサポートしている無料のプランが付いてこの価格なのも、明らかに「財布に優しい」です。以上のことから、Octoparseは、絶対に試す価値があります。