はじめに
この記事では、ViViTの論文について要約してみました。
原論文は以下のリンクから読めます。
1. ViViTとは
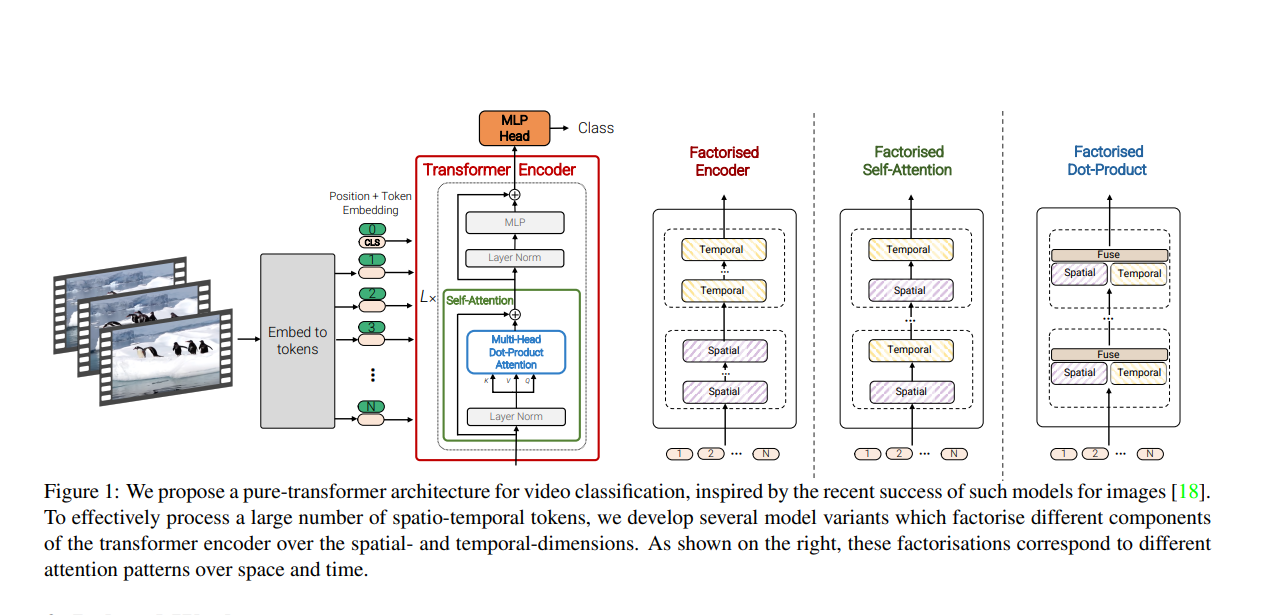
ViViT とは 畳み込み処理を一切使用せず、trasformerのエンコーダ部分のみ を使用し、動画を連続した画像のトークンに変換することで、時空間の両方の情報を捉えた 動画分類モデル です。
論文中では、複数のアーキテクチャを作成、入念なアブレーションスタディを実施し調整することで、複数の動画分類のベンチマークにおいて SoTA を達成し、これまでに提案されてきた3D畳み込みモデルの性能を圧倒しました。
2. Embedding video clips
原論文では、ViT(Vision Transformer)に基づいたトークン化を行っています。
ここでは動画 $V∊ℝ^{T×H×W×C}$ を連続したトークン$V∊ℝ^{nt×nth×nw×d}$にマッピングする手法を考案します。そして、位置埋め込みを実施し、$V∊ℝ^{N×d}$にリシェイプします。
ここでは、クリップされた動画の長さを$T$、画像の長さをそれぞれ$H$、$W$と置きます。そして、時間方向へのフレーム数を$t$、パッチの長さをそれぞれ$h$、$w$と置き、$n_{t} = [\frac{T}{t}]$、$n_{h} = [\frac{H}{h}]$、$n_{w} = [\frac{W}{w}]$としています。
ViTについて知りたい方は、以下の作者の記事を参考にしてください。
2.1. Uniform frame sampling

このトークン化方法は、時間方向と空間方向の情報の相互関係を考慮せず、独立してトークン化を行います。具体的には、フレーム単位でViTと同様にパッチ化を行い、最終的に$z∊R^{nt×nh×nw}$になります。
2.2. Tubelet embedding
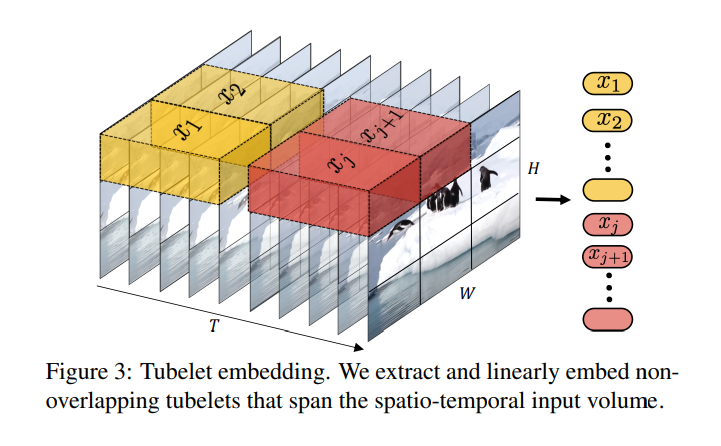
もう一方の手法として、こちらは時間方向と空間方向の情報の相互関係を考慮したトークン化です。直感的には3D畳み込みが分かりやすいと思います。空間方向のパッチと時間方向のストライドごとにトークン化を行い、最終的に$z∊R^{nt×nh×nw}$になります。ただし、抽出する次元を小さくすると計算量が多くなります。
3. Transformer Models for Video
Table 1に示されているように、複数のTransformerベースのアーキテクチャを提案しています。ViTの直感的な拡張から始め、すべての時空間トークン間のペアワイズな相互作用をモデル化し、次にTransformerアーキテクチャのさまざまなレベルで入力ビデオの空間および時間の次元を分解するより効率的な様々のモデルを開発しています。
3.1. Model 1: Spatio-temporal attention
このモデルは、単純に動画から抽出されたすべての時空間トークン$z_{0}$をtransformerエンコーダを介して進めます。CNNアーキテクチャでは、受容野が層の数と線形に成長するのに対し、各Transformerレイヤーはすべての時空間トークン間のペアワイズな相互作用をモデル化し、したがって最初のレイヤーからビデオ全体にわたる長距離の相互作用をモデル化します。
ただし、すべてのペアワイズな相互作用をモデル化するため、Multi-Headed Self Attention(MSA)はトークンの数に対して2次の計算量を持ちます。この計算量は動画に対して関連しており、トークンの数が入力フレームの数と線形に増加するため、効率的なアーキテクチャの開発を促しています。
3.2. Model 2: Embedding video clips
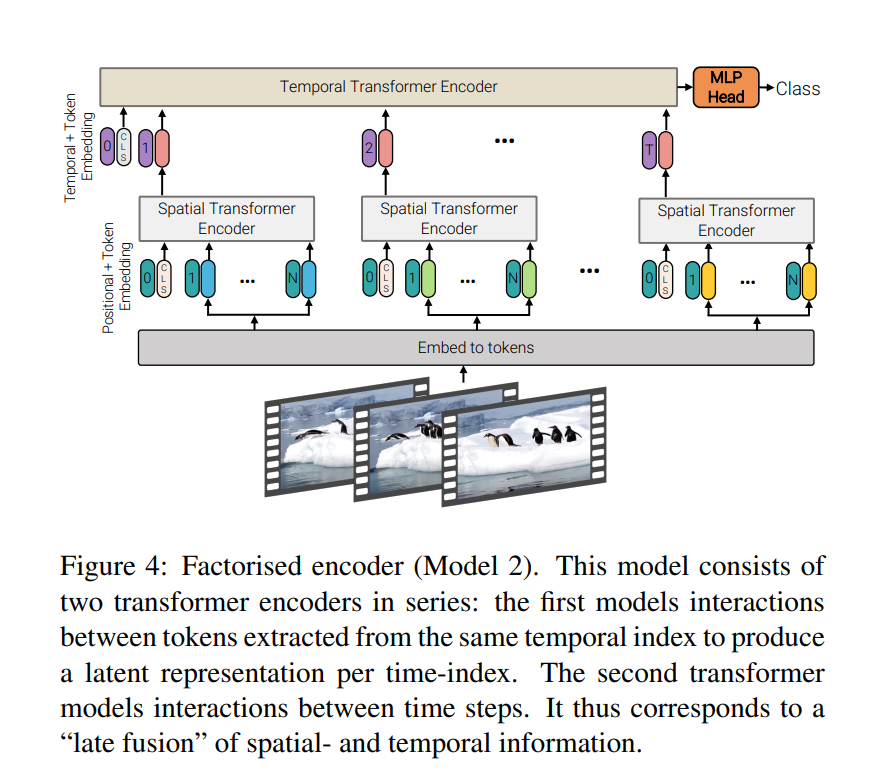
Table 4に示されているように、このモデルは2つの別々のtransformerエンコーダで構成されています。最初の空間エンコーダは、同じ時間インデックスから抽出されたトークン間の相互作用のみをモデル化します。
各時間インデックスの表現$h_{i} ∈ R^{d}$は$L_{s}$レイヤー後に得られます。これはエンコードされた分類トークン$z^{Ls}_{cls}$です。
それ以外の場合は空間エンコーダによって出力されたトークンからのグローバル平均プーリングz^{Ls}です。フレームレベルの表現$h_{i}$は、$H ∈ R^{nt×d}$に連結され、次に異なる時間インデックスからのトークン間の相互作用をモデル化するために構成された$L_{t}$transformerレイヤで進められます。このエンコーダの出力トークンは最終的に分類されます。
このアーキテクチャの初期の空間エンコーダは画像分類に使用されるものと同一です。これらのアーキテクチャはまず各フレームの特徴を抽出し、それを最終的な表現に集約してから分類します。
このモデルはモデル1よりもtransformerレイヤーが多く(したがってパラメータが多いですが)、浮動小数点演算(FLOP)が少なくて済みます。これは、2つの異なるトランスフォーマーブロックは$O((n_{h} · n_{w})^{2} + n^{2}_{t})$の計算量を持ち、
モデル1の$O(n_{t} · n_{h} · n_{w})^{2}$と比較して少ないためです。
3.3. Model 3: Embedding video clips

このモデルは、モデル1と同じ数のtransformerレイヤで構成されています。だたし、レイヤ1で全トークンに対してMulti-HeadAttentionを計算するのではなく、最初に空間的(同じ時間インデックス上から抽出されたトークンが対象)に計算し、次に時間的(同じ空間インデックス上から抽出されたトークンが対象)に計算するよう操作を分割します。これにより、モデル1よりも効率的に処理を分割し、より細かい要素に注目することでモデル2と同じ計算複雑性を実現します。
この操作は、トークン$z$を$R^{1×nt·nh·nw·d}$から$R^{nt×nh·nw·d}$に変形して空間自己注意機構を計算するために効率的に行うことができます。同様に、時間注意機構の入力$z_{t}$は$R^{nh·nw×nt·d}$に変形されます。ここで、先頭の次元は「バッチ次元」です。分解された自己注意機構は次のように定義されます。
\begin{align}
y^{l}_{s} = MSA(LN(z^{l}_{s})) + z^{l}_{s}\\
y^{l}_{s} = MSA(LN(z^{l}_{s})) + z^{l}_{s}\\
z^{l+1} = MLP(LN(y^{l}_{t})) + y^{l}_{t}
\end{align}
また、この自己注意機構の順番における性能の差は生じません。ただし、パラメータの数はモデル1と比べて増加しています。
3.4. Model 4: Factorised dot-product attention

このモデルは、モデル2とモデル3と同じ計算複雑性を内包しながら、空間的、時間的に分解されていないモデル1と同じパラメータ数を保持しています。分解の処理はモデル3と似ていますが、代わりにMulti-Head-dot-product-attentionを分解しています。具体的には、異なるヘッドを使用して各トークンに対し空間、並びに時間の次元ごとに個別に注視した重みを計算します。各ヘッドの操作は次のように定義されています。
\begin{align}
Attention(Q,K,V) &= Softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V \\
Q &= XW_{q}\\
K &= XW_{k}\\
V &= XW_{v}\\
\end{align}
ここでは、$X, Q, K, V∊ℝ^{N×d}$となります。分解されていない場合(モデル1)は$N=n_{t}×n_{h}×n_{w}$として結合されます。
アイデアとしては、各queryに対してkeyとvalueを変更し、空間と時間の同じ次元のトークンにの注視するようにします。$K_{s}, V_{s}∊ℝ^{nh⋅nw×d}$並びに$K_{t}, V_{t}∊ℝ^{nt×d}$を構成し、その後、半分のヘッドについては空間次元のトークンに注視するため以下を計算します。
\begin{align}
Y_{s} &= Attention(Q,K_{s},V_{s})\\
Y_{t} &= Attention(Q,K_{t},V_{t})\\
\end{align}
その後、複数のヘッドの出力を連結し、線形射影を使用して結果を得ます。
\begin{align}
Y = Concat(Y_{s}, Y_{t})W_{o}
\end{align}
3.5. Initialisation by leveraging pretrained models
ViTは、畳み込みネットワークの帰納的なバイアスがいくつか欠けているため、大規模なデータセットでトレーニングされた場合にのみ効果があることが示されています。しかし最大の動画データセットでも、対応する画像データセットと比較して数桁少ないラベル付きの例があります。その結果、大規模なモデルをゼロから高い精度でトレーニングすることは非常に困難となります。この問題を回避し、より効率的なトレーニングを可能にするために、動画モデルを事前に学習された画像モデルから初期化します。ただし、これには画像モデルに存在しないか、互換性がないパラメータをどのように初期化するかという課題がいくつかあります。これらの大規模な動画分類モデルのパラメータを効果的に初期化するためのいくつかの戦略について説明します。
3.5.1. Positional embeddings
各入力トークンには、位置埋め込みが追加されます。ただし動画モデルは、事前学習された画像モデルよりも$n_{t}$倍多くのトークンを持っています。そのため、位置埋め込みは時空間的に$R∊^{nw·nh×d}$から$ℝ∊^{nt·nh·nw×d}$に「繰り返し」されるように初期化されます。したがって、初期化時には、同じ空間インデックスを持つすべてのトークンが同じ埋め込みを持ち、その後微調整されます。
3.5.2. Embedding weights, E
「tubelet embedding」トークン化(2.2)を使用する場合、埋め込みフィルタ$E$は3Dテンソルであり、事前学習モデルの2Dテンソル$E_{image}$と比較しています。動画分類のために3D畳み込みフィルタを2Dフィルタから初期化する一般的なアプローチは、フィルタを時間の次元に沿って複製し、平均化することです。これは以下のように表されます。
\begin{align}
E = \frac{1}{t}[E_{image}, E_{image}, ......, E_{image}]
\end{align}
さらに、「central frame initialisation」と呼ぶ別のアプローチあります。ここでは、$E$はすべての時間位置でゼロで初期化され、中央の位置だけが$E_{image}$であるとします。
\begin{align}
E = [0,0, ..., E_{image}, ..., 0, 0]
\end{align}
これにより、3D畳み込みフィルタは初期化時にUniform frame samplingのように振る舞い、学習が進むにつれてモデルが複数のフレームからの時間情報を集約することを学習できるようにもなります。
3.5.3. Transformer weights for Model 3
Model 3のTransformerブロック(Fig. 5)は、事前学習されたViTモデルとは異なり、2つのMulti-Headed Self Attention(MSA)モジュールを含んでいます。この場合、空間MSAモジュールは事前学習済みのモジュールから初期化し、全ての時間MSAの重みをゼロで初期化します。これにより、初期化時に残差接続として振る舞います。
4. Empirical evaluation
4.1. Experimental Setup
4.1.1 Network architecture and training
作成したバックボーンのアーキテクチャはViTおよびBertに従います。ViT-Base(ViT-B、L=12、NH=12、d=768)、ViT-Large(ViT-L、L=24、NH=16、d=1024)、およびViT-Huge(ViT-H、L=32、NH=16、d=1280)を想定しています。ここで、Lはtransformerレイヤーの数であり、各レイヤーにはNHヘッドの自己注意機構ブロックと隠れた次元dがあります。モデルにも同じ命名スキームを適用します(例:ViViT-B/16x2は、16×16×2のチューブレットサイズを持つViT-Baseバックボーンを示します)。
すべての実験では、Tubuletの高さと幅が等しくなります。小さなTubuletサイズは、入力のトークンが増加し、計算量が増えることを意味します。
私たちはsynchronous SGDとmomentum、 cosine learning rate schedule 、TPU-v3アクセラレータを使用してモデルをトレーニングします。モデルは通常、ImageNet-21K(それ以外が指定されていない限り)またはより大きなJFTデータセットでトレーニングされたViTイメージモデルから初期化されます。
4.1.2. Datasets
提案されたモデルの性能を検証するために、複数の動画分類データセットで評価します。
Kinetics
YouTubeから25fpsでサンプリングされた10秒の動画で構成されています。Kinetics 400および600の両方で評価し、それぞれ400および600のクラスが含まれています。これらは動的なデータセットであり(YouTubeから動画が削除される可能性があるため)、データセットのサイズはそれぞれ約267,000および446,000です。
Epic Kitchens-100
日常のキッチン活動を捉えた動画で構成され、100時間と90,000のクリップが含まれています。。ここでは、各ビデオには「動詞」と「名詞」がラベル付けされており、したがって2つのヘッドを持つ単一のネットワークを使用して両方のカテゴリを予測します。ネットワークが予測したトップスコアの動詞とアクションのペアが「アクション」を形成し、アクションの精度が主要なメトリクスです。
Moments in Time
動物、物体、人物、または自然現象を含む動的なシーンの要点を捉えた800,000の3秒のYouTubeクリップから構成されています。
Something-Something v2(SSv2)
2〜6秒の動画が220,000本含まれています。他のデータセットとは異なり、動画内のオブジェクトと背景は異なるアクションクラスでも一貫しており、モデルが微細なモーションキューを認識する能力に重点を置いています。
4.1.3. Inference
基本的な入力は、ストライド2を使用して32フレームのビデオクリップです。一般的な慣習に従い、推論時にはより長いビデオの複数のビューを処理し、ビューごとのロジットを平均して最終結果を得ます。それ以外が指定されていない限り、各動画につき合計4つのビューを使用します(これはさまざまなデータセット全体のビデオクリップを「見る」のに十分であるため)、そして次にこれらおよびその他の設計における選択肢を削除します。
4.2. Ablation study
4.2.1. Input encoding

最初に、異なる入力エンコーディング方法の効果を検討します。これは、私たちの非因子化モデル(Model 1)およびViViT-Bを使用してKinetics 400で行います。ネットワークには32フレームの入力が渡されるため、8フレームをサンプリングし、長さ $t = 4$のチューブレットを抽出することは、両方のケースで同じ数のトークンに対応します。表1によれば、"central frame" メソッドで初期化されたTublet embeddingは、一般的に使用される "filter inflation" 初期化方法よりも1.6%、"uniform frame sampling" よりも0.7% 優れています。そのため、これ以降のすべての実験でこのエンコーディング方法を使用します。
4.2.2. Model variants
全ての実験でLt = 4を設定し、表3でこの選択に対してモデルが敏感でないことを示しています。

提案した複数のモデルについて Kinetics 400 および Epic Kitchens データセットで、精度と効率の両方の観点から比較します(Table 2)。

Model 1は Kinetics 400 で最も優れた性能を発揮しますが、Epic Kitchensなどの小さなデータセットでは過学習する可能性があり、ここではModel 2が最も優れています。
4.2.3. Model regularisation

純粋なトランスフォーマーアーキテクチャ、例えばViTは大規模なトレーニングデータセットを必要とし、ImageNetで事前にトレーニングされたモデルを使用しても、Epic KitchensやSSv2などの小規模なデータセットで過学習が観察されることが知られています。そこで、これらのデータセットでモデルを効果的にトレーニングするために、Table 4で「Factorised encoder」モデルを使用していくつかの正則化戦略を採用しました。
Table 4の各行にはそれよりも前の行で使用されたすべての手法が含まれ、各正則化を追加することで段階的な改善が見られます。全体として、Epic Kitchensでは5.3%の大幅な総合改善が得られました。また、Table 4の全ての正則化を使用してSSv2で5%の類似の改善を達成しました。初期化に使用されるKineticsの事前トレーニングモデルはTab. 2から取得し、Tab. 2のEpic KitchensモデルはTable 4のすべての正則化を使用してトレーニングされました。KineticsやMoments in Timeなどの大規模なデータセットでは、最先端の結果が得られるため、これらの追加の正則化を使用しません(Table 4の最初の行のみ使用)。
4.2.4. Varying the backbone

Fig 7は、分解されていない時空間モデルのViViT-BとViViT-Lのバックボーンを比較しています。容量が増加するにつれて、一貫した精度向上が観察されます。予想通り、計算量もバックボーンのサイズの関数として増加しています。
4.2.5. Varying the number of tokens
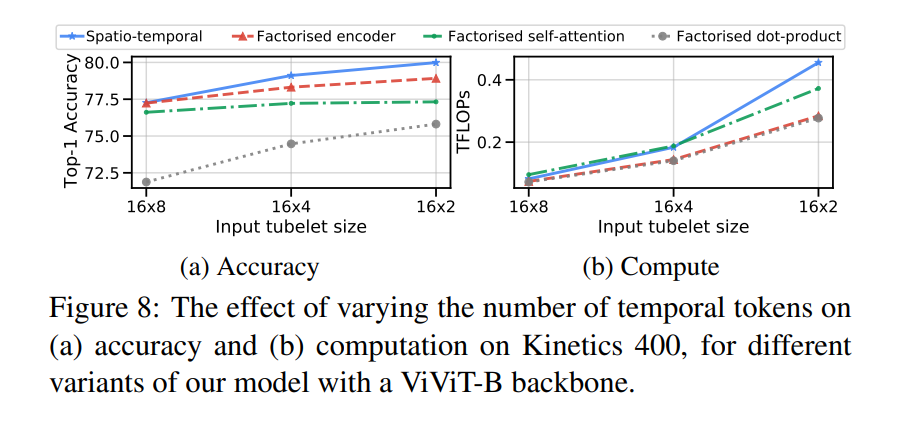
最初に、時間的次元に沿ったトークンの数の関数として性能を分析します(Fig 8)。小さい入力Tubletサイズを使用すると、すべてのモデルアーキテクチャで一貫した精度向上が見られます。同時に、FLOPの観点から計算が増加し、分解されていないモデル(Model 1)が最も影響を受けています。
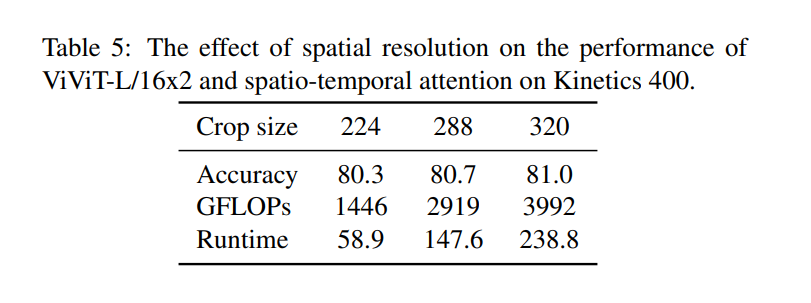
次に、モデルに供給されるトークンの数を変更するために、デフォルトの224から320に空間のクロップサイズを増加させた場合を見てみます(Tab. 5)。予想通り、精度と計算の両方が一貫して増加しています。空間分解能が224である場合に比較して、これまでの研究と比較しても最先端の結果が得られることに留意しますが、さらなる改善が高い空間分解能で可能であることも強調しています。
4.2.6. Varying the number of input frames

これまでの実験では、入力フレーム数を32に固定していました。これからは、モデルに供給されるフレーム数を増やし、それに比例してトークンの数を増やしてみます。Fig 9は、ViViT-L/16x2 Factorised Encoderを使用してKinetics 400で行ったもので、Kineticsのビデオは250フレーム(25 fpsでサンプリングされた10秒間)で、各モデルの精度は等間隔の時間的ビューがビデオクリップ全体を「見る」のに十分な場合に飽和します。
4.3. Comparison to state-of-the-art

前節の検証研究に基づき、2つのモデルを使用して、現行の最先端と比較します。主にFactorised Encoderモデル(Model 2)を使用し、これはModel 1よりも多くのトークンを処理して高い精度を達成できます。
Kinetics
Table 6aおよび6bでは、空間的なAttentionモデルがKinetics 400および600で最先端を上回っていることがわかります。標準的な手法に従い、各時間ビューに3つの空間クロップ(左、中央、右)を取り、以前のCNNベースの手法よりも明らかに少ないビューで済むことに注意が必要です。ViViT-L/16x2 Factorised Encoder(FE)でImageNetで事前学習したものを使用して、以前のCNNベースの最先端を上回り、純粋なトランスフォーマーアーキテクチャも凌駕しています。さらに、JFTデータセットで事前学習したモデルからバックボーンを初期化することで、さらなる改善が得られます。
Moments in Time
Table 6cに示されているように、提案されたモデルはこれまでの性能を大幅に上回っています。このデータセットの動画は多様で、重要なラベルノイズが含まれており、このタスクは困難であり、他のデータセットよりも低い精度につながっていることに注意が必要です。
Epic Kitchens 100
Tble 6dによれば、Factorised Encoderモデルは、先行手法を大幅に上回っています。さらに、我々のモデルは「名詞」クラスのTop-1精度を大幅に向上させ、唯一「動詞」の精度が高い手法は光学的な流動を追加の入力モダリティとして使用しています。さらに、Table 2で示されている当社のモデルの各手法は、アクションの精度で既存の最先端を上回りました。
まとめ
今回は動画分類モデルのViViTの論文についてまとめてみました。ViViTはVision Transformerが基本となっているため比較的読みやすかった印象でした。transformerモデルである以上パラメータや計算速度の効率について、ハード面に依存していることは確かです。しかし、画像認識をさらに拡張した動画分類タスクという観点はとても興味深く、さらにRNNやLSTMといった時系列モデルを使用することなく、SoTAを達成したことはある種の革命であると言えるでしょう。これから先、transformerを使用した別種のタスクを解くモデルが開発されるのでしょうが、どんなものが世に出てくるのか楽しみで仕方ありませんね。余談ですがtransoformerはテキスト、画像、動画の他にも音声分類タスクにも対応している論文が発表されていました。次はその論文についてまとめて、実際に使ってみたいと思います。