はじめに
皆さん、今日は何の日かご存知でしょうか。
そうです、NiziUの日です!
今月12/2でデビュー1周年を迎え、2年連続紅白出場決定とその活躍ぶりは飛ぶ鳥を落とす勢いですね。
そんなNiziUのメンバー9人の中で、自分は誰と似ているのかAIが教えてくれWebアプリを作ってみました。
完成品
NiziUの公式ホームページも参考にしつつ、NiziUらしい雰囲気を意識してデザインしてみました。

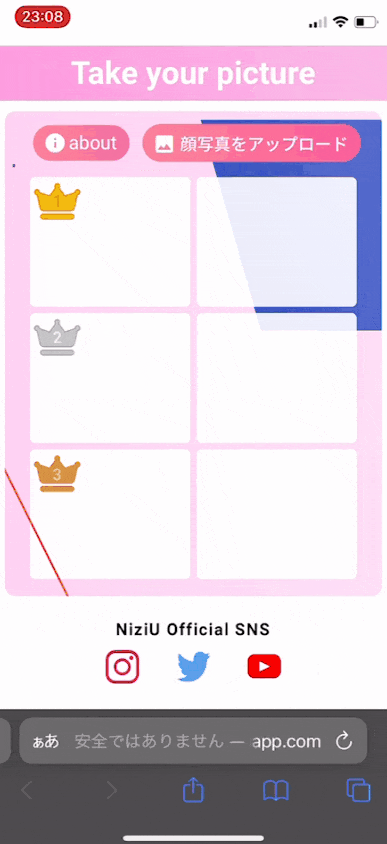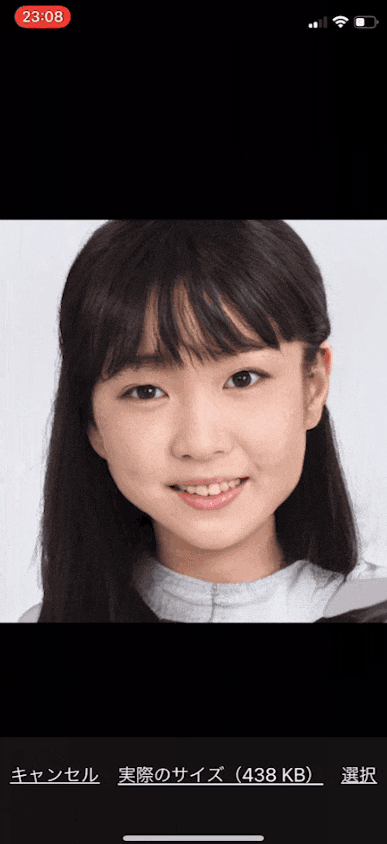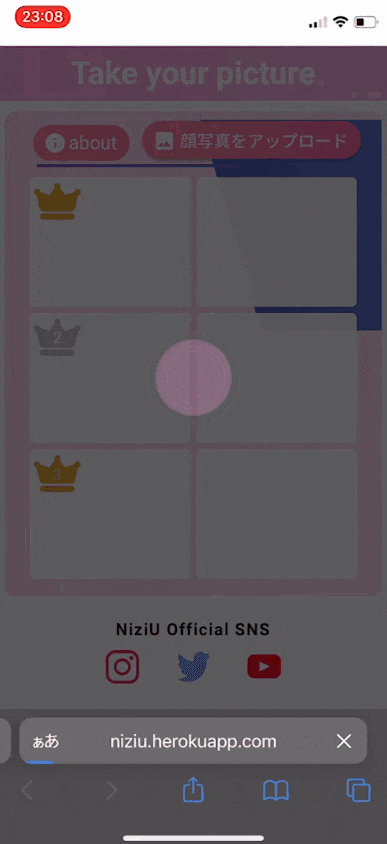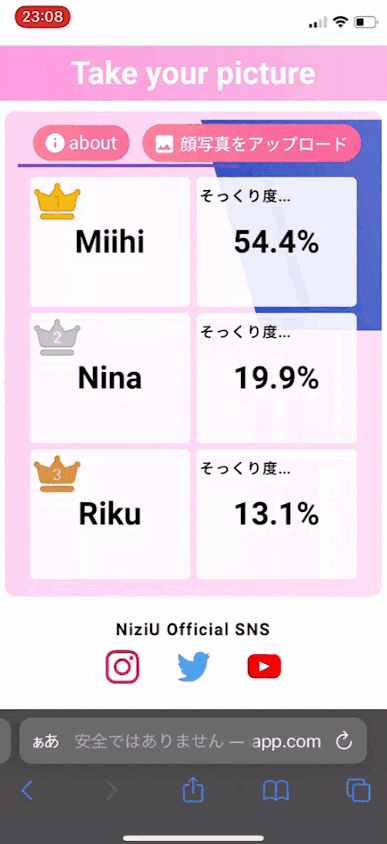
実際に写真をアップロードしたときの動きはこのような感じです。
※フリー素材の顔写真を利用しています。
AIによる顔分類の実装
今回はkerasのCNN(Convolutional Neural Network:畳み込みニューラルネットワーク)を利用しています。
実装方法については、こちらの記事をかなり参考にさせていただきました。
乃木坂メンバーの顔をCNNで分類
ソースの全容は以下のリンクから確認できます。
画像収集
はじめは「Google Custom Search API」を利用して画像収集をしようとしていました。しかし、無料枠として利用できるのは1日上限1000枚までかつ、まったく同じ画像を複数ダウンロードしてきていることに気づいて途中で使用するのを諦めました。
そこで次に見つけた「icrawler」を利用することにしました。こちらを利用すればたった数行で各メンバー100枚以上簡単に集めることができました。
members = ['Mako', 'Rio', 'Maya', 'Riku', 'Ayaka', 'Mayuka', 'Rima', 'Miihi', 'Nina']
for member in members:
crawler = BingImageCrawler(storage={'root_dir': os.path.join(IMAGE_FOLDER_PATH, member)})
crawler.crawl(keyword = f'NiziU {member}', max_num = 200)
顔認識
集めた画像から学習のため顔の部分だけ切り取っていきます。
こちらは参考記事のソースをほぼそのまま利用しています。
members = ['Mako', 'Rio', 'Maya', 'Riku', 'Ayaka', 'Mayuka', 'Rima', 'Miihi', 'Nina']
for member in members:
print(member)
#元画像を取り出して顔部分を正方形で囲み、64×64pにリサイズ、別のファイルにどんどん入れてく
images = os.listdir(os.path.join(IMAGE_FOLDER_PATH, member))
os.makedirs(os.path.join(OUTPUT_FOLDER, member), exist_ok=True)
for img in images:
image=cv2.imread(os.path.join(IMAGE_FOLDER_PATH, member, img))
if image is None:
print("Not open:", img)
continue
image_gs = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier("C:\\ProgramData\\Anaconda3\\Lib\site-packages\\cv2\data\\haarcascade_frontalface_alt.xml")
# 顔認識の実行
face_list=cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
#顔が1つ以上検出された時
if len(face_list) > 0:
for rect in face_list:
x,y,width,height=rect
image = image[rect[1]:rect[1]+rect[3],rect[0]:rect[0]+rect[2]]
if image.shape[0]<64:
continue
image = cv2.resize(image,(64,64))
#保存
fileName=os.path.join(OUTPUT_FOLDER, member, img)
cv2.imwrite(str(fileName),image)
#顔が検出されなかった時
else:
print(img + ":顔が検出できませんでした")
continue
print()
ただ、集めた画像にそのままこれを実行しただけだと、顔が斜めになっている画像で顔認識されないことが多々ありました。
そういった場合は人力で画像の向きを補正してから顔認識させていました。
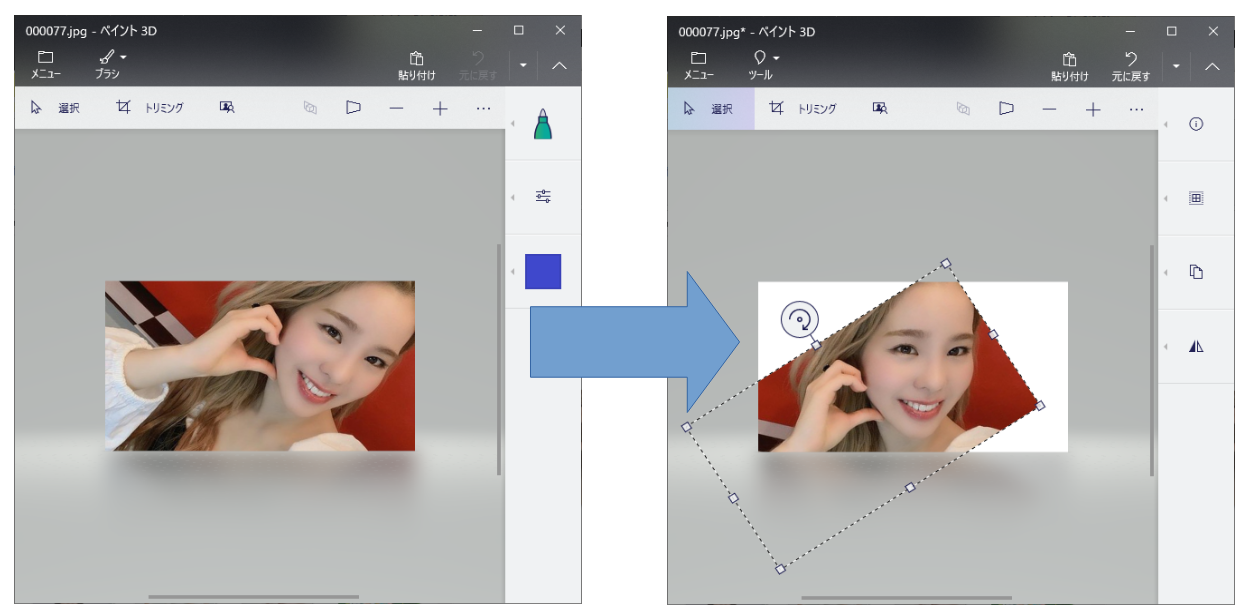
特に、RimaとNinaの自撮りは斜めを向きがちで補正作業が大変でした...。
今思えば水増し処理で利用してる画像の回転を利用して、顔が見つからなければ左右何度か回転して顔認識を試すというような処理を入れてもよかったかもしれません。
また、クローラーでの画像収集ではまだ数が足りなさそうだったので、この顔認識を利用して人力で画像を集めるのを効率化するツールも作成しました。
while True:
if keyboard.read_key() == 'f10':
im = ImageGrab.grabclipboard()
if isinstance(im, Image.Image):
print('has image')
else:
print('no image')
continue
# クリップボードの画像から顔部分を正方形で囲み、64×64にリサイズ、別のファイルにどんどん入れてく
image = np.asarray(im)
if image is None:
print("Not open:", img)
continue
#BGRからRGBへ変換
image = image[:, :, ::-1].copy()
cascade = cv2.CascadeClassifier("C:\\ProgramData\\Anaconda3\\Lib\site-packages\\cv2\data\\haarcascade_frontalface_alt.xml")
# 顔認識の実行
face_list = cascade.detectMultiScale(image, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
# 顔が1つ以上検出された時
if len(face_list) > 0:
for rect in face_list:
x,y,width,height = rect
faceimage = image[rect[1]:rect[1] + rect[3],rect[0]:rect[0] + rect[2]]
if faceimage.shape[0] < 64:
continue
faceimage = cv2.resize(faceimage,(64,64))
#保存
fileName = os.path.join(OUTPUT_FOLDER, str(cnt) + '.jpg')
cv2.imwrite(str(fileName),faceimage)
cnt+=1
# 顔が検出されなかった時
else:
print("顔が検出できませんでした")
time.sleep(0.5)
裏で常駐させて特定のキー入力があるとクリップボードの画像から顔を認識して、顔の部分だけ切り取って保存してくれます。
下のgifのように、ChromeをアクティブにしてAlt+PrintScreen → F10キーでどんどん画像を保存してくれます。
これを利用すれば、YouTubeの動画などでも使えそうなところで一時停止してどんどん画像化することができました。

水増し処理
画像の枚数が明らかに足りなさそうなので、水増し処理をしていきます。
閾値処理、ぼかし処理、回転処理を加えて9倍まで数を増やすことができます。
こちらも参考記事のソースをそのまま利用させていただきました。
def inflation():
members = ['Mako', 'Rio', 'Maya', 'Riku', 'Ayaka', 'Mayuka', 'Rima', 'Miihi', 'Nina']
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
for member in members:
images = os.listdir(os.path.join(IMAGE_FOLDER_PATH, member))
os.makedirs(os.path.join(OUTPUT_FOLDER, member), exist_ok=True)
for i in range(len(images)):
img = cv2.imread(os.path.join(IMAGE_FOLDER_PATH, member, images[i]))
# 回転
for ang in [-10,0,10]:
img_rot = ndimage.rotate(img,ang)
img_rot = cv2.resize(img_rot,(64,64))
fileName=os.path.join(OUTPUT_FOLDER, member, str(i)+"_"+str(ang)+".jpg")
cv2.imwrite(str(fileName),img_rot)
# 閾値
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
fileName=os.path.join(OUTPUT_FOLDER, member, str(i)+"_"+str(ang)+"_thr.jpg")
cv2.imwrite(str(fileName),img_thr)
# ぼかし
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
fileName=os.path.join(OUTPUT_FOLDER, member, str(i)+"_"+str(ang)+"_filter.jpg")
cv2.imwrite(str(fileName),img_filter)
学習
取捨選択した結果、画像は1人あたり83~99枚。
その画像の2割をテストデータに分けた後、残りを訓練データとして9倍に水増しして学習させました。
モデルとソースは以下のような形です。
いろんな記事を参考にして、層を増やした減らしたり、バッチサイズやエポック数を微調整して今の形に落ち着きました。
def learn(target_members):
# 教師データのラベル付け
X_train = []
Y_train = []
for i in range(len(target_members)):
images = os.listdir(os.path.join(TRAIN_FOLDER_PATH, target_members[i]))
for image in images:
img = cv2.imread(os.path.join(TRAIN_FOLDER_PATH, target_members[i], image))
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
X_train.append(img)
Y_train.append(i)
# テストデータのラベル付け
X_test = [] # 画像データ読み込み
Y_test = [] # ラベル(名前)
for i in range(len(target_members)):
images = os.listdir(os.path.join(TEST_FOLDER_PATH, target_members[i]))
for image in images:
img = cv2.imread(os.path.join(TEST_FOLDER_PATH, target_members[i], image))
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
X_test.append(img)
Y_test.append(i)
X_train=np.array(X_train)
X_test=np.array(X_test)
from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D, BatchNormalization, Dropout, GlobalAveragePooling2D
from keras.models import Sequential
from keras.utils.np_utils import to_categorical
from tensorflow.keras import optimizers
y_train = to_categorical(Y_train)
y_test = to_categorical(Y_test)
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu',
input_shape=(64, 64, 3), padding="same"))
model.add(Conv2D(32, (3, 3), activation='relu', padding="same"))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), activation='relu', padding="same"))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu', padding="same"))
model.add(Conv2D(64, (3, 3), activation='relu', padding="same"))
model.add(BatchNormalization())
model.add(Conv2D(64, (3, 3), activation='relu', padding="same"))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(target_members), activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
# 学習
history = model.fit(X_train, y_train, batch_size=128,
epochs=40, verbose=1, validation_data=(X_test, y_test))
# 汎化制度の評価・表示
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
#モデルを保存
model.save("my_model")
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 64, 64, 32) 896
conv2d_1 (Conv2D) (None, 64, 64, 32) 9248
batch_normalization (BatchN (None, 64, 64, 32) 128
ormalization)
conv2d_2 (Conv2D) (None, 64, 64, 32) 9248
max_pooling2d (MaxPooling2D (None, 32, 32, 32) 0
)
dropout (Dropout) (None, 32, 32, 32) 0
conv2d_3 (Conv2D) (None, 32, 32, 64) 18496
conv2d_4 (Conv2D) (None, 32, 32, 64) 36928
batch_normalization_1 (Batc (None, 32, 32, 64) 256
hNormalization)
conv2d_5 (Conv2D) (None, 32, 32, 64) 36928
max_pooling2d_1 (MaxPooling (None, 16, 16, 64) 0
2D)
dropout_1 (Dropout) (None, 16, 16, 64) 0
flatten (Flatten) (None, 16384) 0
dense (Dense) (None, 128) 2097280
dropout_2 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 128) 16512
dropout_3 (Dropout) (None, 128) 0
dense_2 (Dense) (None, 9) 1161
=================================================================
Total params: 2,227,081
Trainable params: 2,226,889
Non-trainable params: 192
最終的な精度は約48%でした。
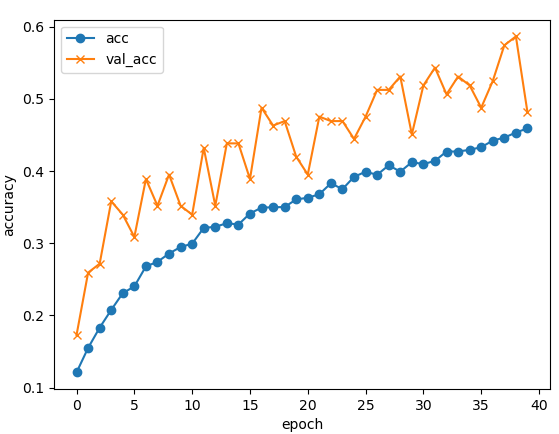
もう少しエポック数を増やせば精度は上がるのですが、写真を判別させた際に1人のメンバーに対して80%超えとなったりします。
Webアプリとして「そっくり度」を表示する想定なので、1人のメンバーに対して高確率として似ていると判断されるより多少確率が分散していたほうがいいのかなと思い、今のエポック数にしています。
このモデルを利用して、NiziU公式ホームページのメンバーの写真を判別した結果以下のようになりました。
Mako
['Ayaka' '33.2%']
['Mako' '27.4%']
['Maya' '15.2%']
Rio
['Rio' '35.2%']
['Mayuka' '17.2%']
['Ayaka' '15.9%']
Maya
['Maya' '29.2%']
['Mayuka' '23.9%']
['Ayaka' '11.8%']
Riku
['Riku' '62.6%']
['Mako' '11.7%']
['Miihi' '9.9%']
Ayaka
['Mayuka' '16.8%']
['Riku' '15.8%']
['Rio' '13.8%']
Mayuka
['Rio' '32.5%']
['Mayuka' '22.0%']
['Mako' '7.8%']
Rima
['Miihi' '38.9%']
['Nina' '28.0%']
['Riku' '27.2%']
Miihi
['Miihi' '31.2%']
['Nina' '29.6%']
['Riku' '22.8%']
Nina
['Mayuka' '16.5%']
['Rio' '16.1%']
['Maya' '12.6%']
ちなみに、epoch=60の時では以下のような結果でした。
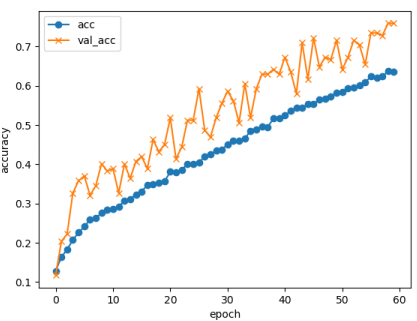
学習の際の精度は上がっているはずなのですが、全然別の人として判定されることも多くなりました…。
Mako
['Riku' '25.0%']
['Nina' '19.3%']
['Rio' '12.5%']
Rio
['Mayuka' '46.4%']
['Rio' '16.5%']
['Mako' '7.5%']
Maya
['Maya' '32.4%']
['Rima' '17.5%']
['Rio' '17.4%']
Riku
['Riku' '64.8%']
['Nina' '26.0%']
['Miihi' '8.3%']
Ayaka
['Mako' '19.4%']
['Mayuka' '15.4%']
['Ayaka' '15.0%']
Mayuka
['Mayuka' '87.9%']
['Rio' '7.9%']
['Nina' '1.3%']
Rima
['Miihi' '100.0%']
['Nina' '0.0%']
['Mayuka' '0.0%']
Miihi
['Nina' '99.8%']
['Riku' '0.2%']
['Miihi' '0.1%']
Nina
['Nina' '85.0%']
['Miihi' '6.3%']
['Mayuka' '4.8%']
その他学び
実装を一通りして調整の段階で、どの顔写真でも特定のメンバーとしてしか判定されないというような偏った結果になることがありました。
判定結果として出てこないメンバーの元画像を見てみると、マイクや自分の手が重なっていたり、横を向きすぎていたり目をつぶっていたり、顔がはっきりとわからない画像が多く含まれていました。
そこで、確率高くなるメンバーと2人だけで分類してみて、自分自身の写真で自分と判定されるまで画像の収集と不要な画像の削除を繰り返しました。
そうすることで、各メンバーの写真を判定させてかなり自分自身として判定結果が出てくるようになりました。
ただ、いまだに「Rima」は判定結果として出てくることがほとんどなく、利用した画像にまだ問題があるような気がしています...。
層の数やバッチサイズの調整でも今くらいの数値が限界でした。
9人の分類として精度を上げるためには、まだまだ画像が足りてなさそうなので、まずはもう少し元の画像を増やす必要があるのかなと思いました。
Webアプリの実装
こちらもflaskを利用してPythonで開発し、herokuにデプロイしています。
ソースの全容は以下のリンクから確認できます。
Webの実装に関してはポイントのみかいつまんで解説していきます。
画像アップロードボタンの実装
アップロードボタンをそのまま利用しようとすると、ファイル選択と送信ボタンがセットになった以下のような形になると思います。
<form>
<input type="file">
<button type="submit">送信する</button>
</form>
ただ、画像を選ぶ → 送信するの2回ボタンを押すのは手間だなーと思ったので、画像アップロードボタンひとつで送信までされるようにしました。
javascriptで画像を選択する画面から実際に画像が選ばれたら、非表示にしていた送信ボタンを押す事で実現しています。
送信ボタン押下後アニメーションを表示させたかったので、ほんの少しの待ち時間も入れています。
$('#upload').change(function () {
$('#mdl_loading').fadeIn();
sleep(0.1, function () {
$("#btn_submit").click();
});
});
faviconについて
他の端末でfaviconを正しく設定できていても、iPhoneのSafariからお気に入りに登録画面に遷移した際にアイコンが表示されないという問題がありました。
iPhoneでもホーム画面に追加する際には正しくアイコンが設定されるのに、お気に入り登録画面だけアイコンが表示されずかなり悩まされました。iPhoneの設定画面からキャッシュを削除したりいろいろ試行錯誤しましたが、一向に解決できませんでした。
懸命に調査した結果、iPhoneのお気に入り登録画面のアイコンは内部で保存され、いっとき変わることがないそうでした。キャッシュクリアをしたとしても無駄で待つしかないとのことでした。
私の場合も、数日経ってから久々にお気に入り登録画面を確認してみると、いつのまにか正しく表示されるようになっていました。
herokuのslug size容量オーバー
herokuにデプロイする際に、無料枠の500MBを超えてslug size容量オーバーエラーで悩まされました。
Compiled slug size: 504.7M is too large (max is 500M).
今回は学習させたモデルを利用して判別するのでtensorflowを利用する必要があったのですが、それが容量をかなり圧迫しているようでした。
容量オーバーエラーについて調べてみると、tensorflowをtensorflow-cpuに変えるだけでかなり容量が減らせることがわかりました。
それでもほんの少し容量オーバーすることがあったので、その他のモジュールのバージョンを下げてみたりしてなんとか500MBに収めることができました。
最終的に「requirements.txt」はこうなりました。
flask==2.0.2
gunicorn==20.1.0
keras==2.7.0
numpy==1.21.0
opencv-python-headless==3.4.16.59
tensorflow-cpu==2.7.0
matplotlib==3.1.1
おわりに
画像を集めて取捨選択、足りなくなればまた集めての繰り返しで、画像の準備がかなり大変でした。
「データ分析は前処理の時間が8割」と言われていますが、それを身に染みて感じることができました。
付け焼き刃の知識ですが、1か月程度でAIを利用したそれらしいサイトを完成させることができて達成感を得ることができました。
ただ、いまだにCNNがどんなことをやっているのかあまり理解できていないところがあります。
ここで燃え尽きることなく、今後は各層がどんな役割なのかもう少し理解を深めていきたいと思います。
また今回は画像の分類を行いましたが、機械学習にはそのほかに回帰やクラスタリング、強化学習などもあります。
ほかの学習方法に関しても、実際に何かを作りながら学んでいけたらなーと思います。
参考
乃木坂メンバーの顔をCNNで分類
CIFAR-10でaccuracy95%--CNNで精度を上げるテクニック--
Webアプリ初心者のFlaskチュートリアル
画像収集の方法
アプリ制作 herokuでのslug sizeについて