本稿について
2018年12月4日に一般提供をされたばかりのサービスである、Azure Machine Learning Serviceの中のAML Computeを使って、Horovod (Pytorch) のMNISTスクリプトを実行してみたいと思います。
(Chainer版も作成しましたので、こちらもあわせてご覧ください。)
注意
現時点でMachine Learning ServiceはGA(一般提供)サービスですが、あくまで筆者が現時点でのSDKを利用して実行した記録となります。最新のSDKではコマンドなどが変更されている可能性があります。
Azure Machine Learning Serviceとは?
データの準備・モデルのトレーニング・モデルの展開と機械学習・深層学習のプロジェクトが必要とするプロセスに必要な環境をAzure上にワンストップとして提供するサービスです。
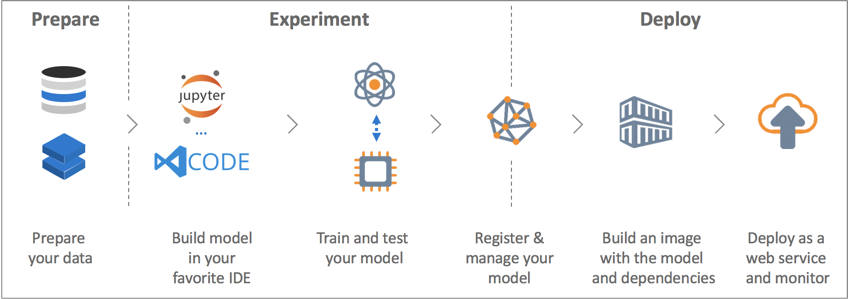
基本的にはPythonのSDKとして提供され、主にJupyter Notebookで利用されることが多いです。現時点では、ディープラーニングフレームワークだとTensorFlowとPytorchがサポートされています。
https://docs.microsoft.com/ja-jp/azure/machine-learning/service/
(補足)Azure Machine Learning ServiceとAzure Machine Learning Studioとの違い
--以下、公式ドキュメントからのコピペ--
"Azure Machine Learning Studio は、共同作業に対応するドラッグアンドドロップ式の視覚的なワークスペースです。コードを記述することなく機械学習ソリューションを構築、テスト、およびデプロイすることができます。 事前に構築および構成された機械学習アルゴリズムとデータ処理モジュールが使用されています。
Machine Learning Studio を使用するのは、機械学習モデルをすばやく簡単に試したいときで、組み込みの機械学習アルゴリズムで十分な場合です。
Machine Learning サービスを使用するのは、Python 環境で作業していて機械学習アルゴリズムを詳細に制御したい場合、またはオープンソースの機械学習ライブラリを使用したい場合です。"
--以上--
まとめると、Azure Machine Learning Serviceはデータサイエンティストが本格的に機械学習・深層学習を行ったり、実際にサービス展開をしたりする際に必要とするツールをまとめてSDKとして提供するものになります。
(補足)Azure Batch AIとの違い
Azure Batch AIは深層学習に必要なクラスター管理・ジョブ管理機能を自動化するサービスでしたが、今後Azure Machine Learning Serviceの中の、Azure ML Computeという一機能という立ち位置になります。クラスター管理・ジョブ管理の機能は変更後も変わりませんが、API/SDKには変更があります。今後、Azure Machine Learning Serviceを使うことで、学習用のクラスター・ジョブ管理だけでなく、モデルの管理やデプロイなど、より多くの行程をワンストップで実行できます。
Azure ML ComputeでHorovod (Pytorch) MNISTを実行してみる!
ここから、実際にクラスター作成・ジョブ実行を行っていきます。本記事は以下のGithubレポジトリをベースにしています。
https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/training-with-deep-learning/distributed-pytorch-with-horovod/distributed-pytorch-with-horovod.ipynb
なお、本記事のNotebookとコードは下記に置いてあります。ただし、SDKの変更を随時キャッチアップしていないため、最新の情報については上記レポジトリを参照してください。
https://github.com/YoshiakiOi/AMLCompute/tree/master/Horovod_Pytorch_MNIST
本記事の実行環境について
基本的にMachine Learning ServiceはJupyter Notebookを利用して使います。本稿ではサーバーレスでJupyter Notebookを利用できるAzure Notebookを使用します。
https://notebooks.azure.com/
自分のJupyter Notebookを使うこともできますが、その場合は別途環境設定が必要です。詳細は下記をご参照ください。
https://docs.microsoft.com/ja-jp/azure/machine-learning/service/how-to-configure-environment
(補足)Azure Notebookと最新のアップデートについて
Azure NotebookはMicrosoft社が提供する無料(一部機能は有料)で利用できるクラウド上のJupyter Notebookです。2018年12月に開催されたConnect()で多くの機能更新がありました。特に主な変更として、もともと実行環境として無料のコンピュート環境が提供されていたのですが、オプションとしてユーザーのデータサイエンス仮想マシン(Linux版、GPUが搭載されたマシンシリーズのものも利用可)を実行環境とすることができるようになりました。これにより、Azure Notebookから直接GPU環境でジョブを実行することができるようになります。詳細は下記をご参照ください。
https://github.com/Microsoft/AzureNotebooks/wiki/Azure-Notebooks-at-Microsoft-Connect()-2018
①SDKのインストール
SDKをインストールします。本記事執筆時の実行はバージョン1.0.2で行っています。
import azureml.core
print("SDK version:", azureml.core.VERSION)
また、合わせて診断ツールをインストールします。
from azureml.telemetry import set_diagnostics_collection
set_diagnostics_collection(send_diagnostics=True)
(補足)Machine Learning SDKについて
Azure NotebookはMachine Learning Serviceとネイティブに連携しているため、すぐにMachine Learning Serviceを使うことができます。一方、ユーザー自身のJupyter Notebook環境を利用して使うこともできます。その際はPythonのバージョンは3.6台である必要があります。環境準備の詳細は下記をご参照ください。
https://docs.microsoft.com/ja-jp/azure/machine-learning/service/how-to-configure-environment
②ワークスペースの作成
次にML Serviceの管理単位(クラスター・ジョブなどを管理)であるワークスペースを作成します。下記<>に必要な引数を入力します。また、最初にワークスペースを作成する際には、ワークスペースを含むリソースグループの中に、Azure Storage Account, Azure Container Registry, Azure Application Insights, Key Vaultコンテナーが一緒に作成され、裏側で連携するようになっています。なお、下記のプロセスではAzure ADの認証が発生する場合があります。
from azureml.core.workspace import Workspace
ws = Workspace.create(name='<ワークスペース名>',
subscription_id='<サブスクリプションID>',
resource_group='<リソースグループ名>',
create_resource_group=True,
location='<リージョン: 例: eastus>'
)

また、下記コマンドで設定情報をカレントディレクトリ配下の/aml_configディレクトリにあるconfigファイルに書き出せます。
ws.write_config()
2度め以降の場合
2度目以降は、既存のワークスペースに接続します。
from azureml.core.workspace import Workspace
ws = Workspace.get(name='<ワークスペース名>',
subscription_id='<サブスクリプションID>',
resource_group='<リソースグループ名>'
)
または、書き出したconfigファイルからも可能です。
ws = Workspace.from_config()
(補足)Machine Learning Serviceで利用されるストレージについて
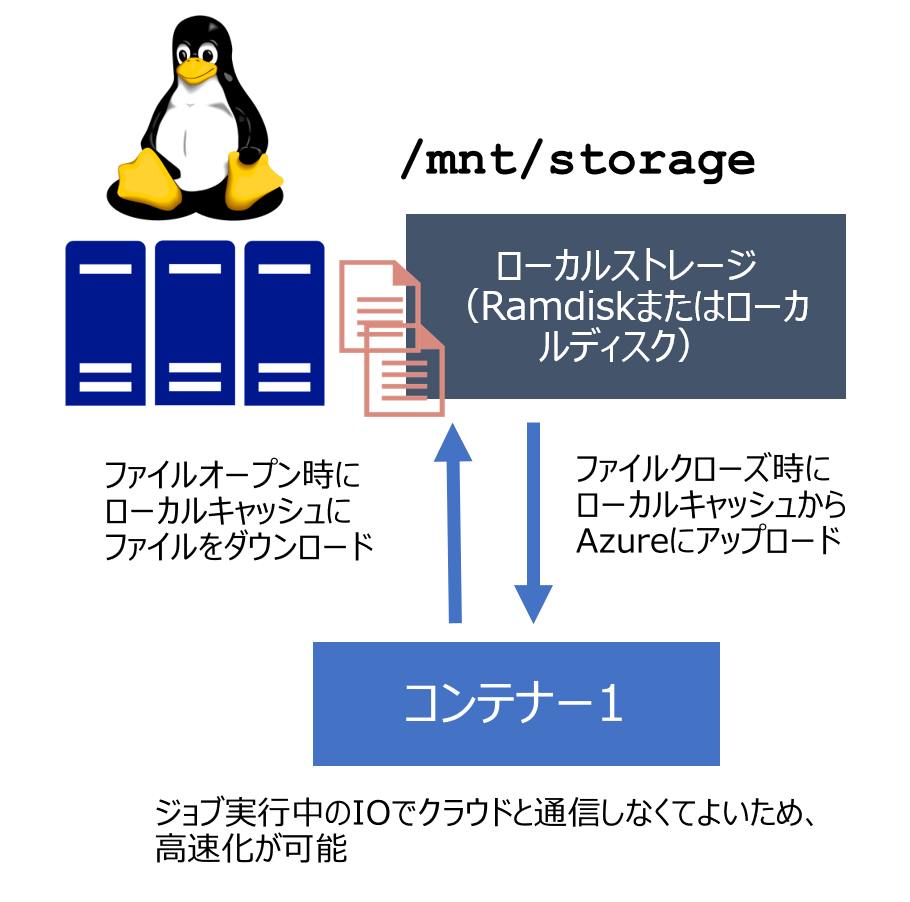
Machine Learning Service (ML Compute)はBatch AIと裏側の仕組みは同じなため、SDKは違えど仕組みは同じです。どちらも基本的には、AzureのオブジェクトストレージであるBlob StorageをノードからBlob Fuseを使ってマウントして使います。
ただし、Machine Learning Serviceは、DataStoreというオブジェクトを作成し、このオブジェクトを使って共有ストレージを操作します。これはラッパーなので、利用いただくとより簡単にストレージを扱えますが、裏側の仕組みやストレージとしての制限事項などは変わりません。
Blob Fuseの詳細について、特にディープラーニングジョブ実行時の注意点については、下記をご参照ください。
https://qiita.com/YoshiakiOi/items/2f143e62bcf5d7daa8e9#blob%E3%82%B9%E3%83%88%E3%83%AC%E3%83%BC%E3%82%B8
Blob Fuseではストレージをマウントする際、キャッシュの置き場所やタイムアウトの時間など、詳細に設定を行います。Machine Learning Serviceでは、マウントは自動化されており、その際のパラメータも決まったものが利用されています。特にキャッシュのタイムアウト時間については長時間に設定がされており、一度ローカルノードに配布されたデータは長時間そのままアクセス先として利用されます。そのため、パフォーマンスはローカルストレージ利用時になるべく近くなるようになっておりますが、クラウドのデータが参照されないため、NFSのような共有ストレージとは動きが異なります。固定的なデータを参照する際には有利な設定ですが、変化するデータの参照先としては不適です。
Blob Fuseイメージ図
③AML Compute クラスターの作成
Azure Machine Learning Serviceのリモート分散実行環境である、AML Computeクラスターを作成します。下記コマンドでは、既存のクラスターが存在する場合はクラスターを接続、ない場合は新規にクラスターを作成します。クラスターはジョブが必要とするノード数に合わせてオートスケールするようになっています。(ジョブが終了と認識されないエラーが出ている場合は、スケールされずジョブが実行中になったままになる可能性があるのでご注意ください。)
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# choose a name for your cluster
cluster_name = "gpucluster"
try:
compute_target = ComputeTarget(workspace=ws, name=cluster_name)
print('Found existing compute target.')
except ComputeTargetException:
print('Creating a new compute target...')
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority="lowpriority",
max_nodes=2)
# create the cluster
compute_target = ComputeTarget.create(ws, cluster_name, compute_config)
compute_target.wait_for_completion(show_output=True)
# Use the 'status' property to get a detailed status for the current AmlCompute.
print(compute_target.status.serialize())
(補足)オプションの紹介
・vm_sizeでは、仮想マシンのサイズを指定します。上記ではNC6 (K80 1枚) の仮想マシンを選択しています。
・vm_priorityでは、仮想マシンの優先度タイプを指定しています。"dedicated"にすると通常価格の仮想マシンになります。"lowpriority"を選択すると、最大80%引きですが、ジョブ中に割り込みが入る可能性がある低優先度仮想マシンのクラスターを作成します。
・max_nodeではそのクラスターの最大ノード数を指定します。(min_nodesはデフォルト0ですが、明示的に指定も可能です。)
・ここでは入れていませんが、特定のVNETへのデプロイも可能です。
その他詳細は下記をご参照ください。
https://docs.microsoft.com/ja-jp/python/api/azureml-core/azureml.core.compute.amlcompute(class)?view=azure-ml-py
④サンプルコードの用意
実行コードはローカル側(Jupyter Notebookの実行環境側)に用意します。本例では、まずカレントディレクトリ配下にpytorch-distr-hvdという実行時にML Serviceに渡すディレクトリを作成しておきます。
import os
project_folder = './pytorch-distr-hvd'
os.makedirs(project_folder, exist_ok=True)
次に実際に実行するHorovod (Pytorch) のMNISTのコードをダウンロードし、このディレクトリにコピーします。
import shutil
!wget "https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/training-with-deep-learning/distributed-pytorch-with-horovod/pytorch_horovod_mnist.py"
shutil.copy('pytorch_horovod_mnist.py', project_folder)
⑤Experimentの作成
ワークスペース配下でジョブの管理を行う箱である、Experiment(実験)を作成します。
from azureml.core import Experiment
experiment_name = 'pytorch-distr-hvd'
experiment = Experiment(ws, name=experiment_name)
⑥Estimatorの作成
ジョブの実行情報やコンテナーの環境情報をまとめて記載した設定オブジェクトである、Estimatorを作成します。Estimatorでは、さきほど作成したディレクトリや実行コード、実行時のノードの数や各ノードでのプロセス数、mpiやGPUの利用有無などを指定します。基本的には、設定に沿ってDockerが各ノードで実行される仕組みです。現在、TensorFlowとPytorchには専用のEstimator(コンテナーイメージ)が用意されており、これらのユーザーは特段設定をしなくてもすぐに利用開始できるようになっています。それ以外のユーザーや自分でパッケージを追加する必要があるユーザーはカスタマイズしたEstimatorを利用することも可能です。詳細は下記をご参照ください。
https://docs.microsoft.com/ja-jp/python/api/azureml-train-core/azureml.train.estimator.estimator?view=azure-ml-py
from azureml.train.dnn import PyTorch
estimator = PyTorch(source_directory=project_folder,
compute_target=compute_target,
entry_script='pytorch_horovod_mnist.py',
node_count=2,
process_count_per_node=1,
distributed_backend='mpi',
use_gpu=True)
⑦ジョブの実行
あとは、このEstimatorに沿ってジョブを実行するだけです。下記コマンドですぐに実行できます。
run = experiment.submit(estimator)
print(run)
ジョブの監視
ジョブの監視は下記コマンドで、10-15秒単位で非同期にデータを収集することができます。(Azure Notebookだとうまく表示されない場合があるようです。)
from azureml.widgets import RunDetails
RunDetails(run).show()
また、Jupyterをブロックして、ログを表示し続けることもできます。
run.wait_for_completion(show_output=True)
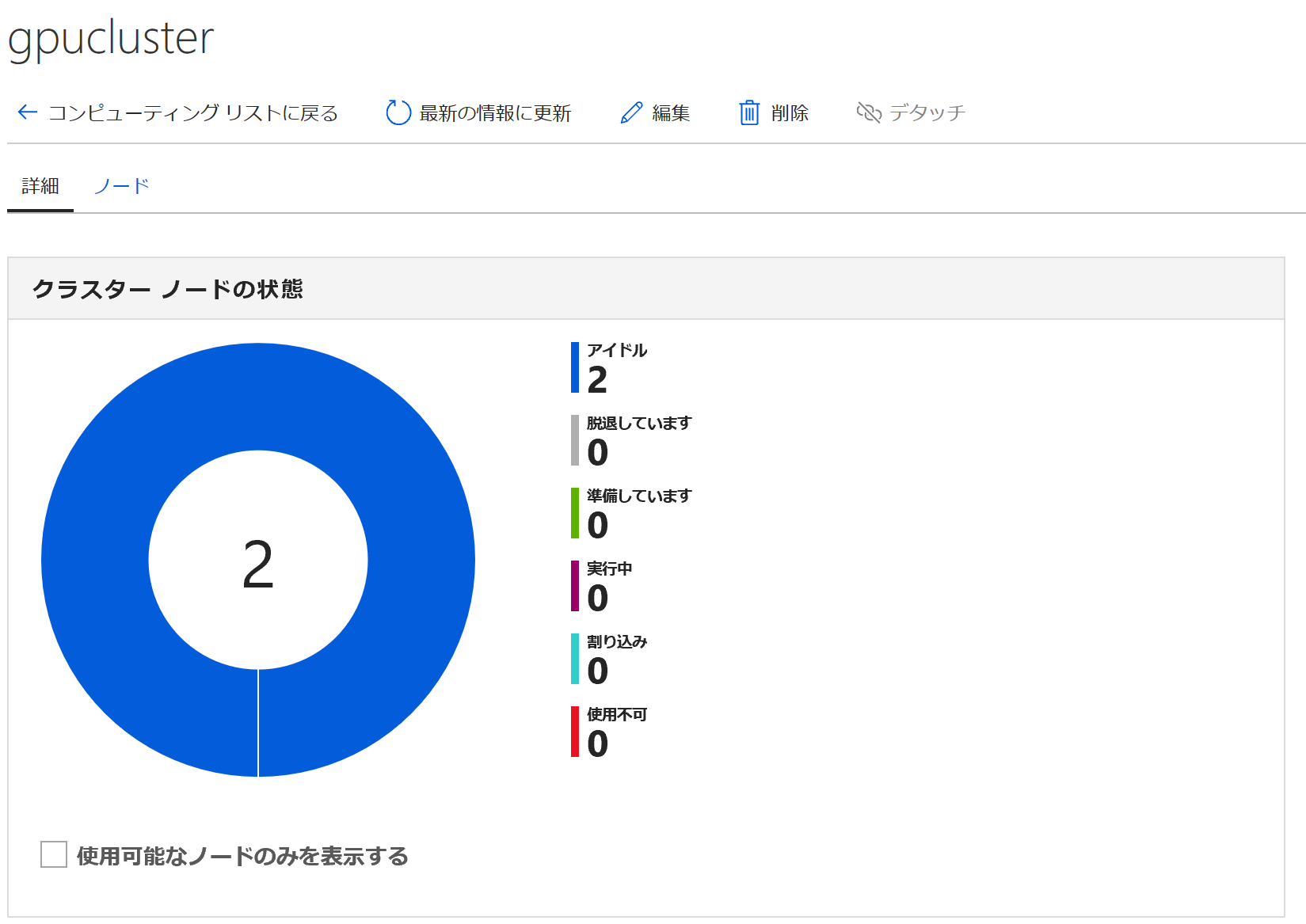
もちろんAzure Portalからも確認できます。Azure Portalからはクラスターの状態やリアルタイムで送られてくるログを見ることができます。
クラスター情報
ログ
以上がAML ComputeでのHorovod(Pytorch) MNISTコードの実行の流れになります。終了後はリソースの片づけをして完了です。
参考
〇Azure Machine Learning Serviceについて
公式ドキュメント
https://docs.microsoft.com/ja-jp/azure/machine-learning/service/
SDKのリファレンス
https://docs.microsoft.com/ja-jp/python/api/overview/azure/ml/intro?view=azure-ml-py
サンプルのNoteBook (Github)
https://github.com/Azure/MachineLearningNotebooks
〇過去のBatch AIの記事
Azure Batch AI - AzureでGPU/マルチノードでディープラーニング計算を簡単に行う!(Chainer MN編)
https://qiita.com/YoshiakiOi/items/2f143e62bcf5d7daa8e9
Azure Batch AI - Chainer MNをInfiniband / GPU付きノードで高速並列実行する!
https://qiita.com/YoshiakiOi/items/16dd1d28b4d2b328dcc5
*本稿は、個人の見解に基づいた内容であり、所属する会社の公式見解ではありません。また、いかなる保証を与えるものでもありません。正式な情報は、各製品の販売元にご確認ください。