本稿では、Azure Batch AIを利用して、Chainer MNのMNISTのコードをGPUノードを複数並べて実行してみたいと思います。
Batch AIとは?
Batch AIとは、マイクロソフト社のパブリッククラウドであるAzureの1製品で、GPUの載ったノードを並べたクラスターをオンデマンドで簡単に作成しDockerを利用してディープラーニングの学習をすぐに実行できる環境を提供する仕組みです。
*製品イメージ図
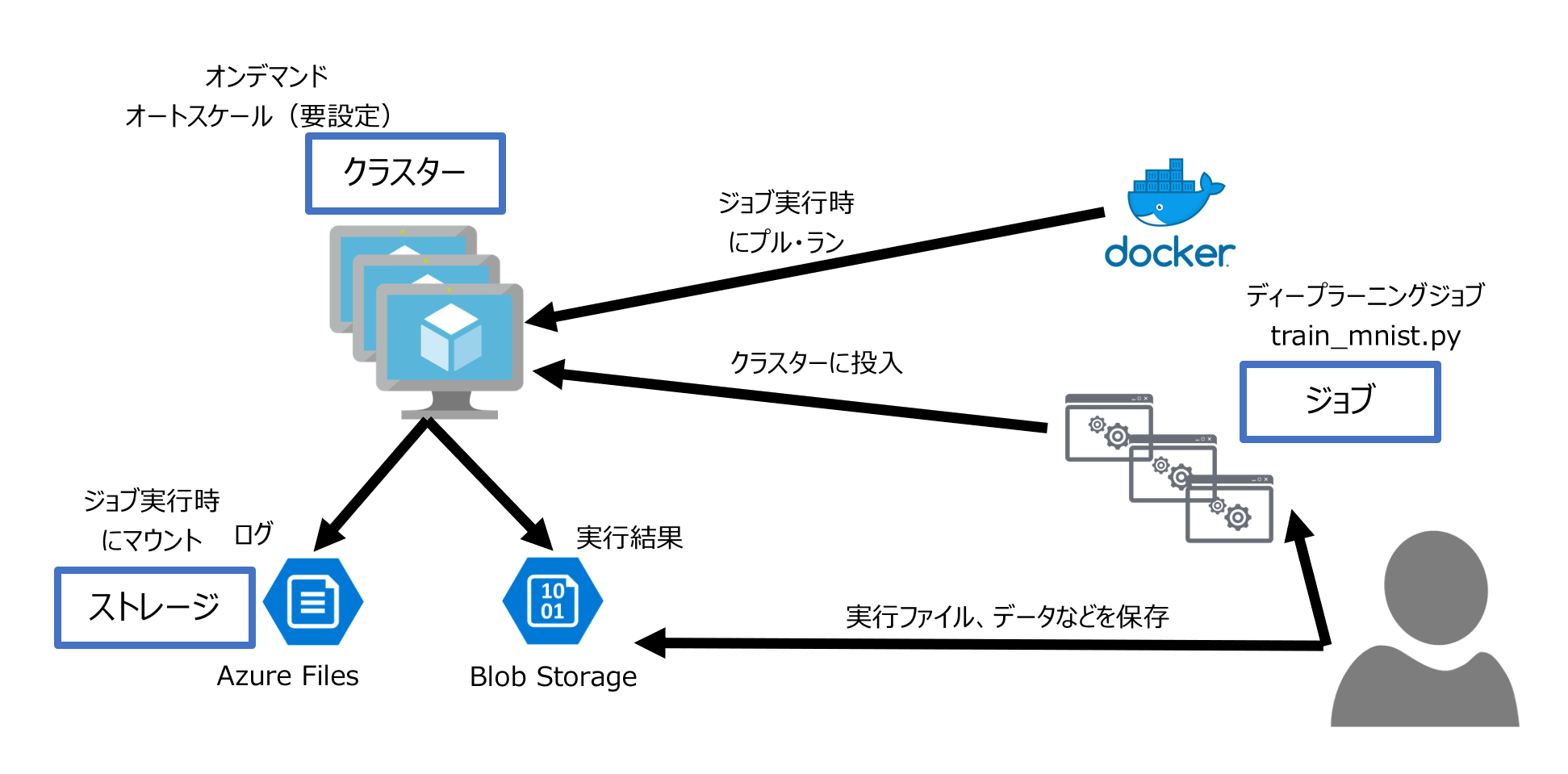
ポイント
・Nvidia社のGPU(Tesla V100, P100, P40, K80)を載せたサーバーを大量に並べたクラスターを、1行のコマンドで作成できます。
・マルチノード時に必要なノード間の通信もAzureが自動設定。低レイテンシーなRDMAネットワークを提供するInfinibandも利用可能です。
・価格が8割引きになる低優先度仮想マシンを利用して、通常利用料の20%の費用でジョブが実行できます。
*低優先度仮想マシン:Azureのサービスのうち、Virtual Machine Scale Set (VMSS), Azure Batch, Azure Batch AIで利用可能な仮想マシン。上記サービスは通常、専用のクラスターの仮想マシンを利用しますが、低優先度の仮想マシンは、通常の仮想マシン用のクラスターの余剰リソースを利用するため、価格が80%引きで提供されます。そのかわり、通常の仮想マシンのリソースが逼迫してくると、ジョブの最中に割り込みが入って取られてしまう可能性があります。
Batch AIの実行の方法
2018年8月現在、Azure CLI(Azureのリソース管理のためのコマンド管理ツール)またはPython SDKから操作可能。ここでは、以下を参考にAzure CLIからChainer MNのtrain_mnist.py をGPUありの2ノードのクラスターで実行してみます。
今回はAzureポータルから Cloud Shell を利用します。Cloud Shellは、自動でAzure Files (Azureのファイルサーバーをサービスとして提供するサービス)をマウントしているので、マウントしているディレクトリに移動します。
cd /usr/$USER/clouddrive
*AzureポータルのCloud Shell (UbuntuのコンテナーでBashが起動)
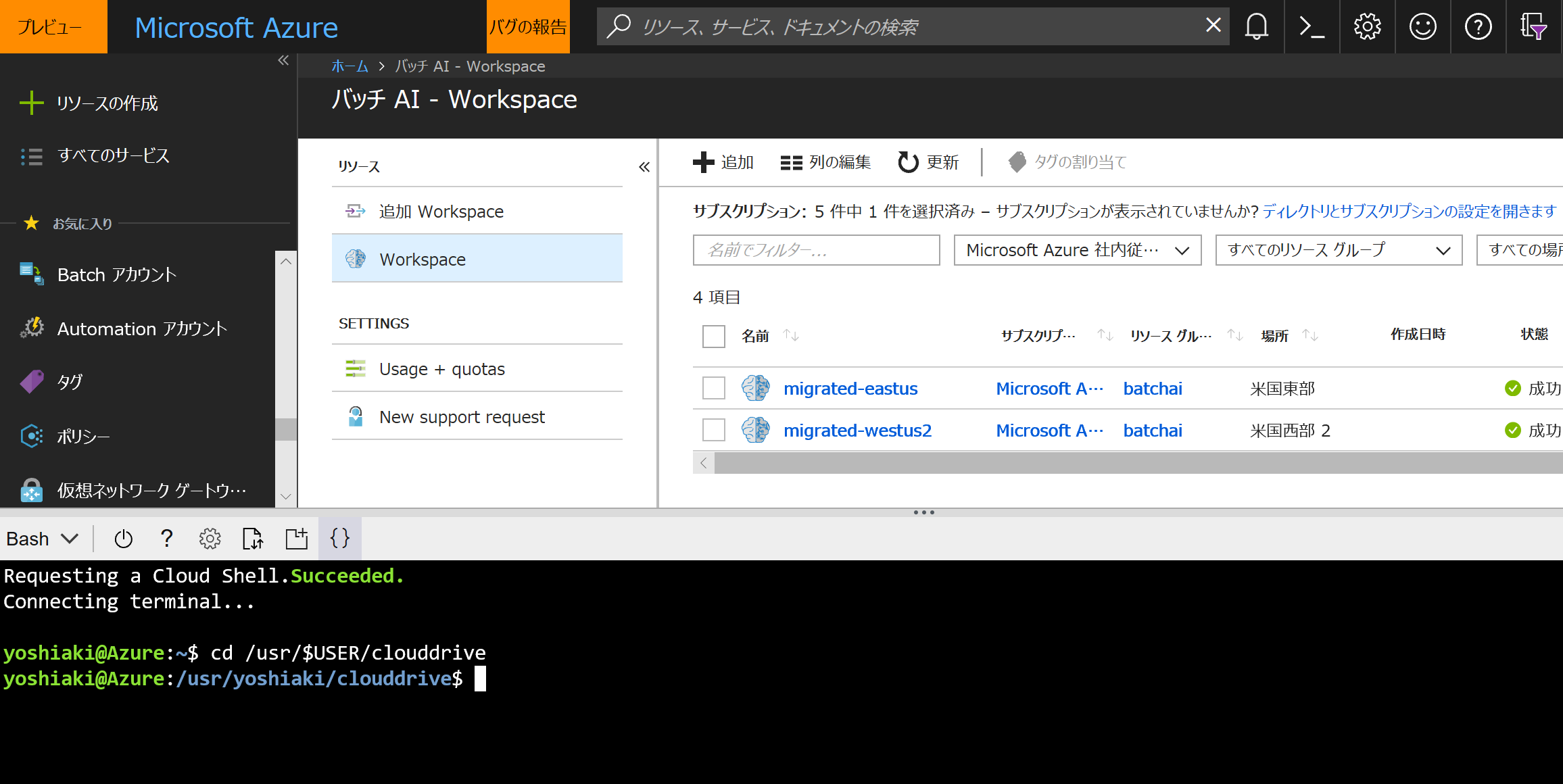
*Bash on WindowsやLinuxのBashから作業を行う場合には、Azure CLIのインストールが必要です。詳細は下記をご覧ください。
https://docs.microsoft.com/ja-jp/cli/azure/install-azure-cli?view=azure-cli-latest
Batch AIのリソースの作成
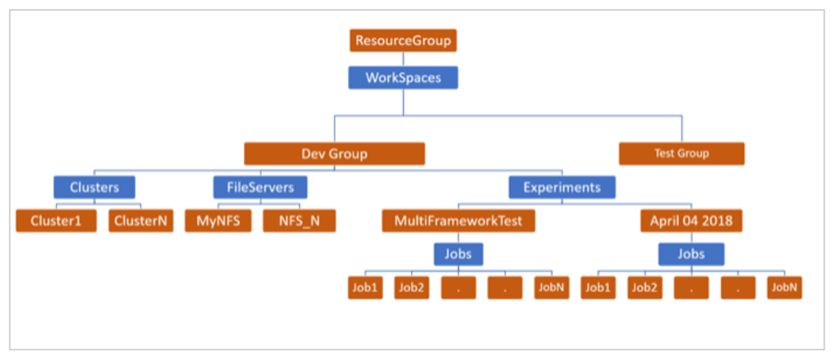
リソース管理の枠組みを作成
Azureのリソースはすべてリソースグループという箱で管理するため、Batch AIで行うディープラーニングのプロジェクトに必要なすべてのリソースを入れるためのリソースグループを作成します。
az group create -n batchai.recipes -l eastus
今回は、Azureのリージョン(データセンターのある場所)の中から米国東部リージョンでリソースを作ります。その他にも、Batch AIは米国西部2や米国東部2、ヨーロッパ西部や北部も利用可能です。
次に、ワークスペースという、ディープラーニングのプロジェクトに必要なリソースであるクラスターやジョブをまとめて管理する箱を作成します。
az batchai workspace create -g batchai.recipes -n recipe_workspace -l eastus
*各コマンド(az batchai ***)の詳細なオプションは、本稿では説明を省いているので以下を参照ください。
https://docs.microsoft.com/en-us/cli/azure/batchai?view=azure-cli-latest
*Batch AIのリソース管理の体系図
ストレージの準備
Batch AIでは、オンデマンドでクラスターを作るため、学習に必要なデータやコード、学習の結果やログなどは、ノード外の永続的なストレージに置く必要があります。Azureには、BlobストレージとFilesという強力なストレージオプションが用意されています。
ストレージのオプション
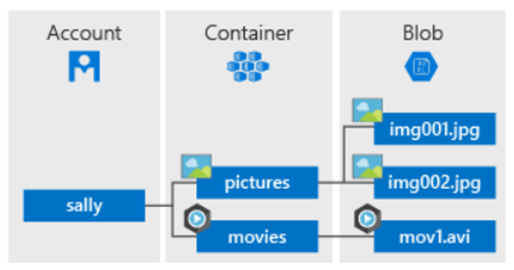
Blobストレージ
Azureの提供するオブジェクトストレージ(オブジェクト単位で保存され、Restでアクセスするストレージ)。ディスクストレージと異なりディレクトリ構造を持っていません、BlobストレージはBlob Fuse機能というBlobストレージをLinuxのサーバーからファイルシステムとしてマウントできる仕組みを持っています(機能は限定)。これは、ローカルキャッシュを利用し、File Open/Close時だけにクラウド上のもとのストレージにアクセスを限定するため、Read-Onlyシナリオ、Writeが1ノードに限られる場合などに高速なストレージとして利用可能です。
*Blobストレージの仕組み(後ほどこれに合わせて作成していきます)
ストレージアカウントと呼ばれるストレージすべてを管理する名前空間の中に、コンテナーというBlobストレージの管理体系を作ります。そのなかにオブジェクト(ファイル)を格納します。
*Blob Fuseイメージ図
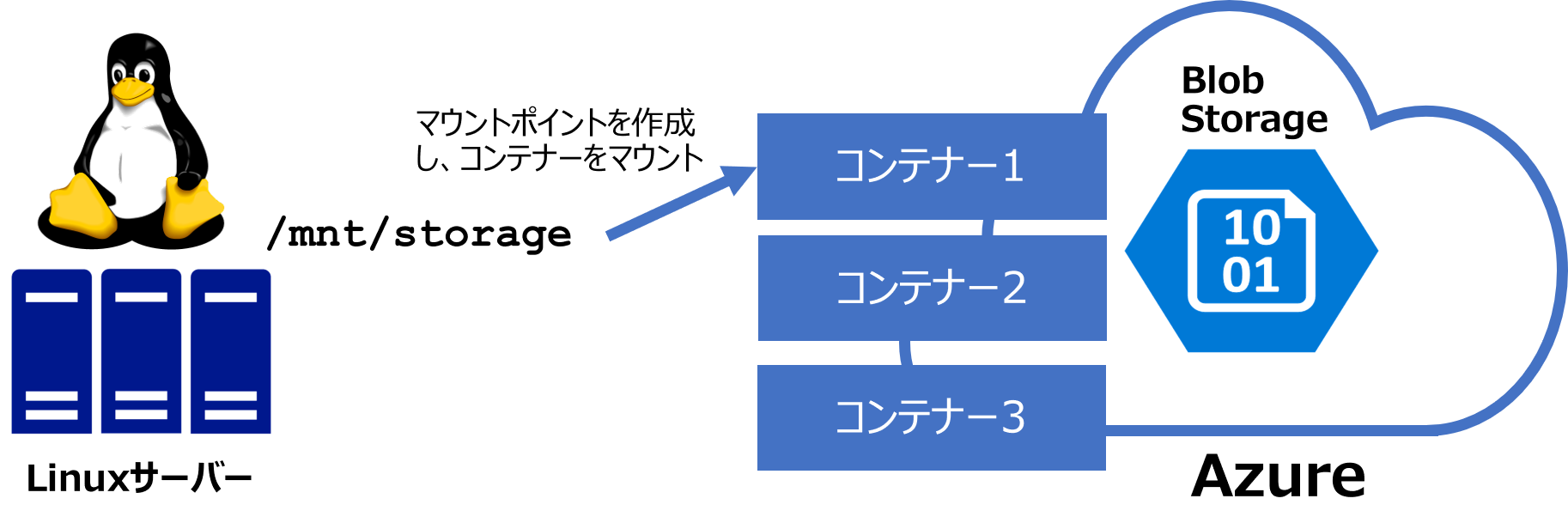
*Blob Fuseの仕組み

(参考)
blobfuse を使用して Blob Storage をファイル システムとしてマウントする方法
https://docs.microsoft.com/ja-jp/azure/storage/blobs/storage-how-to-mount-container-linux
BLOB Storage をLinuxファイルシステムとしてマウント - blobfuse (プレビュー)
http://jm555.hatenablog.jp/entry/2018/04/03/194153
Files
SMBでアクセスでき、ファイルサーバーの機能をサービスとして提供するストレージ。排他制御ができますが、パフォーマンス上限があります。Blobコンテナーに相当するファイル共有という管理単位をストレージアカウント直下に作成し、その中でディレクトリ構造でファイルを管理します。
Batch AIでのストレージ利用
Batch AIでは、ジョブの速度に大きく影響するデータの置き場やモデルのアウトプット先にはBlob (Fuse)、ジョブの最中に書き込み単位でクラウドの大元に最新のものをおいておきたいログファイルの書き出し先にはFilesを利用するのがおすすめです。特にFilesをデータ置き場やアウトプット先に使うと速度が大きく遅くなるので要注意です。
ストレージアカウントの作成
まず、ストレージ管理の名前空間であるストレージアカウントを作成します。今回は利用するすべてのものをこの1つのストレージアカウントに格納します。ストレージアカウントはURLになるため、小文字か数字のみで世界で唯一の名前にしなければなりません。
az storage account create -n <storage account name> --sku Standard_LRS -g batchai.recipes -l eastus
ストレージはワークスペース(クラスター、次項で作成)と同じリージョンに置かなければ、通信のレイテンシーが急激に大きくなり計算が遅くなるので注意が必要です。
Blobコンテナーとファイル共有の作成
今回はBlobストレージとFilesの両方を使うので、それぞれの管理体系であるBloBコンテナーとファイル共有を以下のように作成します。今回は、Blobストレージのscriptsという名前のコンテナーに実行ファイルを、resultというコンテナーに結果を、それぞれ格納します。また、Filesのlogsというファイル共有にログを出すようにします。
az storage container create -n scripts --account-name <storage account name>
az storage container create -n result --account-name <storage account name>
az storage share create -n logs --account-name <storage account name>
次に、今回使うtrain_mnist.pyを手元にダウンロードしておきます。それを手元から、Blobストレージのコンテナーにアップロードします。Blobストレージはオブジェクトストレージでディレクトリ構造を持ちませんが、URLの/によって仮想的な構造を作ることができます。今回はコンテナーの中にchainerという仮想ディレクトリを作り、その中にtrain_mnist.pyを置きます。これは、実際にノードからBlob Fuseを使ってマウントすると、このディレクトリ構造で扱うことができます。
wget https://raw.githubusercontent.com/chainer/chainermn/v1.3.0/examples/mnist/train_mnist.py
az storage blob upload -f train_mnist.py -n chainer/train_mnist.py --account-name <storage account name> --container scripts
あとはこれから作成するクラスターから、ジョブ実行時にこれらをマウントするだけです。これらのストレージはジョブ実行後にクラスター内のノードを削除しても永続するため、後から利用することができます。
クラスターの作成とジョブの投入
クラスター作成は1行コマンドを実行するだけです。このコマンド内で、仮想マシンのシリーズ(GPUの有無)、仮想マシンの価格帯(専用(通常価格)または低優先度(80%引き))、OSイメージ(デフォルトはUbuntu16.04 LTS)などを指定することができます。
ここでは、NC6シリーズ(K80 1枚の6コアの低優先度の仮想マシン)を2台並べたクラスターを作ります。
*本来は同じGPU枚数であれば、シングルノードで枚数を増やしたほうが早くなります(今回であればNC12シリーズ)。ここではマルチノードで並べることを試すためにこのような設定で行っています。
az batchai cluster create -n nc6 -g batchai.recipes -w recipe_workspace -s Standard_NC6 -t 2 --generate-ssh-keys --vm-priority lowpriority
クラスターができたら、次はジョブの投入です。
まず、Jobの管理体系であるExperimentを作成します。
az batchai experiment create -g batchai.recipes -w recipe_workspace -n chainer_experiment
次に、ジョブの投入時に詳細な設定を行うJSONファイルを作成します。ここではカレントディレクトリにjob.jsonというファイルを以下のように作成します。< >は適宜変更が必要です。<Storage Account Key>はストレージアカウントのキーで、ストレージアカウントの中身にアクセスするために必要なものです。
{
"$schema": "https://raw.githubusercontent.com/Azure/BatchAI/master/schemas/2018-05-01/job.json",
"properties": {
"nodeCount": 2,
"chainerSettings": {
"processCount": 2,
"pythonScriptFilePath": "$AZ_BATCHAI_JOB_MOUNT_ROOT/scripts/chainer/train_mnist.py",
"commandLineArgs": "-g -o $AZ_BATCHAI_OUTPUT_MODEL"
},
"stdOutErrPathPrefix": "$AZ_BATCHAI_JOB_MOUNT_ROOT/logs",
"mountVolumes": {
"azureFileShares": [
{
"azureFileUrl": "https://<AZURE_BATCHAI_STORAGE_ACCOUNT>.file.core.windows.net/logs",
"relativeMountPath": "logs"
}
],
"azureBlobFileSystems" :[
{
"accountName": "<Storage Account Name>",
"containerName": "scripts",
"credentials": {
"accountKey": "<Storage Account Key>"
},
"relativeMountPath": "scripts"
},
{
"accountName": "<Storage Account Name>",
"containerName":"result",
"credentials": {
"accountKey": "<Storage Account Key>"
},
"relativeMountPath": "result"
}
]
},
"outputDirectories": [{
"id": "MODEL",
"pathPrefix": "$AZ_BATCHAI_JOB_MOUNT_ROOT/result"
}],
"containerSettings": {
"imageSourceRegistry": {
"image": "batchaitraining/chainermn:openMPI"
}
}
}
}
nodeCountでノード数、processCountでトータルのGPU数(今回は1枚✕2ノードなので2枚と設定)、実行コマンド(mpirun/mpiexec, python/python3は内部に隠蔽されている)、ストレージ、コンテナーのイメージがあるリポジトリなどを指定しています。
ストレージアカウントのキーは以下のコマンドからも確認できます。
az storage account keys list -g batchai.recipes --account-name <storage account name>
コンテナーは、Docker Hubにあるマイクロソフト社のBatch AIの開発チームが作成したイメージ(Open MPI版)を利用していますが、自分で作成しDocker HubやAzureのプライベートなコンテナーレジストリであるAzure Container Registry (ACR)に置いたものを利用することもできます。
また、ここで使われている環境変数の一覧は以下にあります。
https://github.com/Azure/BatchAI/blob/master/documentation/using-batchai-environment-variables.md
JSONファイルができたら、あとは実行するだけです。
az batchai job create -n distributed_chainer -c nc6 -g batchai.recipes -w recipe_workspace -e chainer_experiment -f job.json --storage-account-name <storage account name>
ジョブがcreateされると、queueに入り、ノードが確保されると実行が始まります。指定したコンテナーが各ノードで動き始め、各コンテナーがSSHでパスワードなしで通信ができるよう自動で設定がなされます。これにより、ユーザー側はノード間の通信を設定することなく、マルチノードでジョブを実行することが簡単にできます。
ジョブのモニタリング
標準出力に出てくるものは、以下のコマンドでCloud Shellからも確認できます。
az batchai job file stream -j distributed_chainer -g batchai.recipes -w recipe_workspace -e chainer_experiment -f stdout.txt
こちらをCLIではなく、Azureポータルから確認すると以下の様に見ることができます。
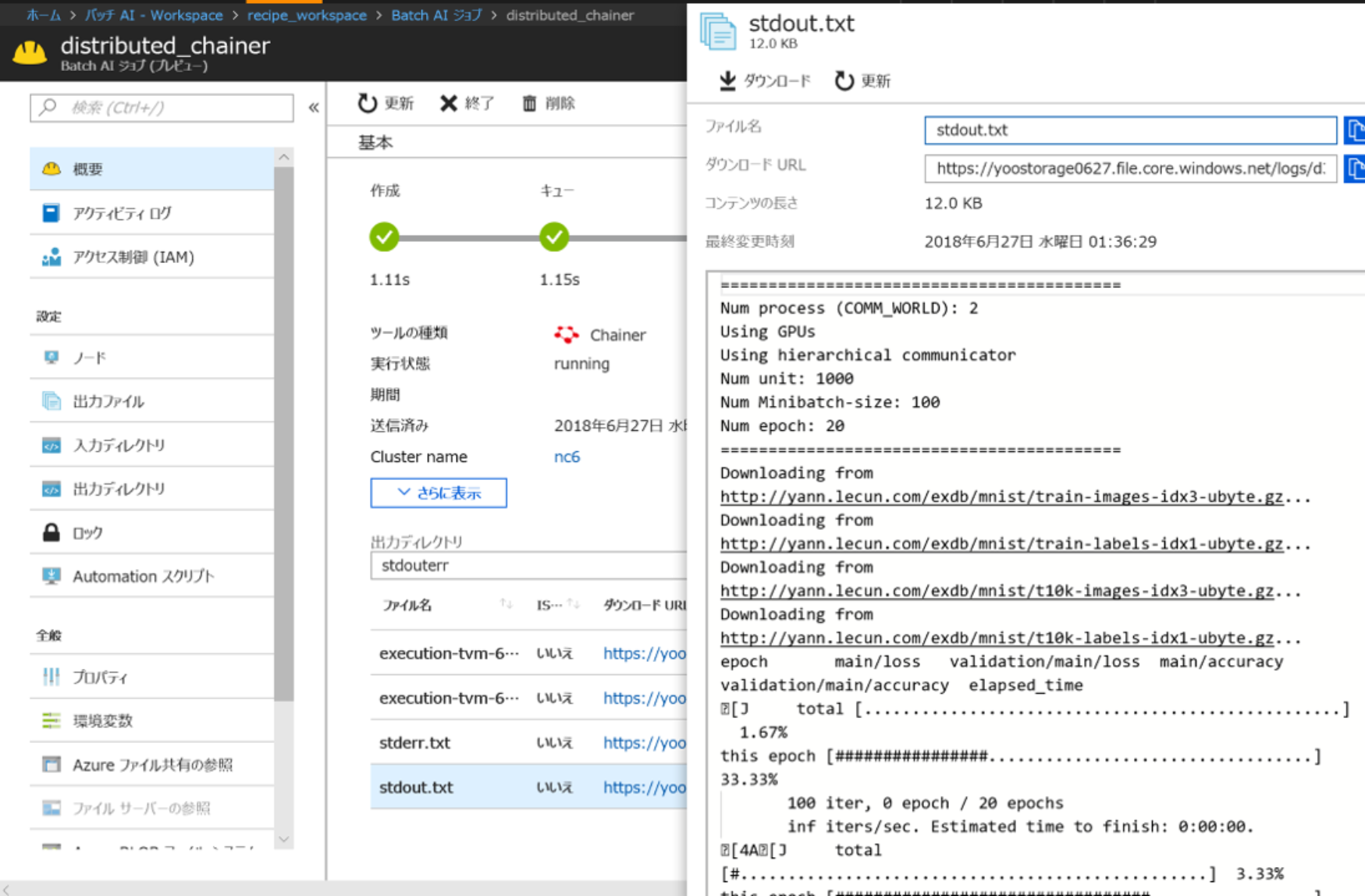
アウトプットの確認
以下のコマンドで、先のJSONで指定したoutputDirectoriesのなかのid=MODELに入っているアウトプットのファイルを確認できます。
az batchai job file list -j distributed_chainer -g batchai.recipes -w recipe_workspace -e chainer_experiment -g batchai.recipes -d MODEL
リソースの後処理
クラスターのノード関係
さきほど作成したクラスターは手動でノード数を指定したので、ジョブ実行後も確保され続けます。課金は、2018年8月現在、クラスターが持っているノード数に対してかかるので(ストレージなどは別料金です)、ジョブが終了したら手動でノードを減らす・クラスターごと削除するか、またはクラスターを自動スケールするよう設定することが大事です。
・クラスターのノード数を減らす(0ノードにする)
az batchai cluster resize -n nc6 -g batchai.recipes -w recipe_workspace -t 0
・クラスターを削除する
az batchai cluster delete -n nc6 -g batchai.recipes -w recipe_workspace
・クラスターを自動スケールする(最小0ノード、最大10ノードの例)
az batchai cluster auto-scale -n nc6 -g batchai.recipes -w recipe_workspace --min 0 --max 10
*このあたりの作業は、Azureポータルからするのも便利です。
リソースグループごと削除する
すべて削除する場合は、リソースグループごと削除します。
az group delete -n batchai.recipes -y
以上で、簡単にディープラーニングに必要なクラスターをオンデマンドで作成し、ジョブを実行することができます。
注意点
Batch AIには、Azureの仮想マシンやAzure Batchとは異なるクオータ(リソースの制限値)が課せられています。例えば仮想マシンのコア数をトータルで25以上使う場合などは、サポートリクエストを上げていただき、クオータを変更する必要があります。
参考資料
(公式)Azure Document
https://docs.microsoft.com/ja-jp/azure/batch-ai/
(公式)Github Batch AI
https://github.com/Azure/BatchAI
*ドキュメントよりもGithubのほうが内容が充実しており、各フレームワークのレシピ(例)が揃っています。
(手前味噌ですが)Deep Learning Lab MeetUp (2018年6月27日) 学習編資料
https://www.slideshare.net/ssuser147cbc/deep-learning-lab-meetup-azurebatch-ai
(ディープラーニングで使えるAzureのインフラのまとめ)de:code 2018 Online CI06 Cloud Infrastructure ディープ ラーニング & HPC を支える Azure インフラ
https://info.microsoft.com/JA-AzureINFRA-CNTNT-FY18-06Jun-21-SupportdeeplearningHPCdecode18Online-MGC0002654_01Registration-ForminBody.html
続編
Azure Batch AI - Chainer MNをInfiniband / GPU付きノードで高速並列実行する!
https://qiita.com/YoshiakiOi/items/16dd1d28b4d2b328dcc5
同様のジョブをInfiniband(Intel MPI)を使って実行しています。
Batch AIのネットワークの説明は、上記記事の以下もご参照ください。
https://qiita.com/YoshiakiOi/items/16dd1d28b4d2b328dcc5
*本稿は、個人の見解に基づいた内容であり、所属する会社の公式見解ではありません。また、いかなる保証を与えるものでもありません。正式な情報は、各製品の販売元にご確認ください。