はじめに
本記事では「PC の基礎的な扱いや深層学習の基礎的な事項については理解しているが,深層学習の実装をしたことがない」という方に向けたチュートリアル的な記事となっています.最終的には PyTorch による GPU を利用した深層学習の実装ができるようになることを目指します.
なお,以前に以下のような類似の記事を出したのですが,これをベースに再編集したものになります.
というのも,コーディングをしたことがない人でも実装できるようにと考えた結果,非常に冗長な記事になってしまったため,あまり個人的に気に入っていないためです.本記事では,コーディングの基本については除外した簡易版となっており,コーディングに関する前提がある方にとっては読みやすくなっているかなと思います.
目次
本記事では以下の順序で進めます.
- Docker のインストール
- どの OS でも同様の開発環境を提供するために導入
- Docker Compose を用いた実行環境の構築
- コンテナ設定の管理のために導入
- CPU を用いた深層学習の実装
- 比較的容易な CPU による実装で PyTorch の基本について理解
- GPU 環境の構築
- 高速な計算を実現するために GPU 環境を導入
- GPU を用いた深層学習の実装
- これからは深層学習に必須と言っても過言ではない GPU による演算を学び,実践的な実装を理解
最終目標
本記事の最終目標は,先に述べたように,PyTorch による GPU を利用した深層学習の実装です.ご自身で実行環境を準備でき,モデルアーキテクチャの改良・開発に専念できるようになることを目指します.
一方で,一般に公開されていないデータによる学習,モデルアーキテクチャの設計,学習スケジュールの設計,モデルの保存と再利用・再学習,モデルの学習評価,複数 GPU による学習については,本記事では扱いません.(今後,時間ができれば執筆するかもしれませんが)
1. Docker のインストール
まずはじめに,開発環境を構築します.多くの初学者がプログラミングにおいて苦戦することの1つに環境構築があります.そのままでは OS や端末によって挙動が変わり,特にエラーではその原因の特定に苦戦する人が多いです.
さらに,深層学習のライブラリは依存関係が複雑になりがちです.こうした状況では,ホスト OS(普段使っている PC の OS)の環境を汚さずに,クリーンで再現性の高い環境を構築することが非常に重要です.そのために,本記事では Docker を利用します.
1.1. Docker とは?
Docker は,アプリケーションを「コンテナ」と呼ばれる独立した環境にパッケージングし,実行するためのプラットフォームです.より平易に言い換えると,今回の用途であれば,ホスト OS に依存しない PyTorch の実行環境を提供するためのソフトです.
こうした機能を提供するプラットフォームにはいくつかあるのですが,例えば仮想マシン(VirtualBox や VMware など)が OS 全体を仮想化するのに対し,Docker は OS のカーネルを共有し,プロセスやファイルシステムだけを隔離します.これにより,比較的,軽量で高速に起動・停止できるというメリットがあります.
深層学習の文脈では,以下のような利点から広く利用されています.
-
環境の再現性:
Dockerfileという設定ファイルさえあれば,誰でも全く同じ環境を構築できます.「自分のPCでは動いたのに,他の人のPCやサーバでは動かない」といった問題を未然に防げます. - 依存関係の管理: プロジェクトごとに必要なライブラリ(PyTorch, CUDA, Python のバージョンなど)をコンテナ内に閉じ込めることができるため,他のプロジェクトとの依存関係の衝突を気にする必要がありません.
- ポータビリティ: 一度作成したコンテナは,Dockerが動作する環境であればどこでも(ローカル PC,クラウド,オンプレミスサーバなど)動かすことができます.
より詳細な説明は,以下の記事などが参考になるかもしれません.
1.2. Docker のインストール
Docker のインストール手順は利用している OS により異なります.本記事では Linux (Ubuntu) / Windows / Mac の3つをサポートします.
1.2.1. Ubuntu の場合
本記事が古くなった時のことを考え,はじめに公式ドキュメントを提示します.
また,Ubuntu での Docker のインストールについては以下の記事でも紹介しています.
Step 1. apt リポジトリの設定
以下のコマンドを実行してください.
# Add Docker's official GPG key:
sudo apt update
sudo apt install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
Step 2. Docker パッケージのインストール
以下のコマンドを実行してください.
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Step 3. Docker の起動確認
以下のコマンドを実行してください.
sudo docker run hello-world
上記のコマンドを実行して,以下のような出力が得られれば成功です.
Unable to find ... や Pulling ... のような表示がされることもあると思いますが,気にしないで大丈夫です.
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(arm64v8)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
Step 4. (任意) Docker Group の作成・追加
上記のコマンドでもあるように,Docker に関連するコマンドの実行時には sudo (管理者権限)で実行する必要がありますが,実行ユーザを Docker Group に入れることで sudo による実行が不要になります.
以下のコマンドを実行して Docker Group を確認します.
cat /etc/group | grep docker
以下のコマンドを実行してユーザの追加を行います.($USER は自身のユーザ名.Terminal の @ の前.)
sudo gpasswd -a $USER docker
再度 Docker Group の確認コマンドを実行し,反映されていれば再起動を行います.
sudo reboot
共有サーバ等で,再起動が難しい場合は以下のコマンドにより反映します.
newgrp docker
1.2.2. Windows の場合
Windows では WSL (Windows Subsystem for Linux) を利用して Linux 環境を構築し,その上に Docker をインストールする場合が多く見られます.これに倣い,本記事でもこの方法を紹介します.
一見すると回りくどい方法を Windows では取るのかという理由についてはいくつかあるのですが,筆者自身の経験を挙げさせてもらうと
- Docker Desktop for Windows のクセが強い
- Ubuntu や Mac で Docker を利用している場合には発生しない未知のエラーに遭遇することが多い
- Linux と Windows のカーネルの相性が(Mac に比べると)悪いから?(勝手な予想ですが)
- WSL の改良が進んできていて,そちらの機能を使った方が都合が良いことも多い
- ハードウェアの制御とか
- Linux, Mac は概ねコマンドが同じでちょっとした検証をしたい場合に都合が良いのですが,Windows は全くと言って良いほど異なることも個人的には気になるポイントです
他にも理由はあると思いますが,自身の周囲や幾つかの記事を見ていると WSL 上でコーディングする人が多そうです.
Step 1. WSL のインストール
管理者権限で PowerShell かコマンドプロンプトを開き,以下のコマンドを実行します.
wsl --install
インストール完了後,再起動します.
それなりに時間がかかります.放置していても問題はないのですが,電源を落とすことができないため,時間のある時に実行することをお勧めします.
Ubuntu 以外のディストリビューション(OS)をインストールしたければ -d オプションが利用できます.
Step 2. Ubuntu の初期設定
インストールが無事に完了して再起動した後,スタートメニューに Ubuntu (もしくは指定した OS)が追加されているので起動します.
Windows と同様,初回起動時にユーザとパスワードの作成を行います.当たり前ですが,ログイン時に必要になるものなので記憶しておいてください.
Step 3. Docker をインストール
以降,Ubuntu の場合と同じ手順でインストール作業を実行します.
1.2.3. Mac の場合
Mac では Docker Desktop をインストールするのが簡単です.以下のリンクからダウンロードします.
インストール手順はいわゆる普通のアプリのインストールと同じです.ターミナルで以下のコマンドを実行し,インストールの確認をします.
sudo docker run hello-world
上記のコマンドを実行して,以下のような出力が得られれば成功です.
Unable to find ... や Pulling ... のような表示がされることもあると思いますが,気にしないで大丈夫です.
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(arm64v8)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
2. Docker Compose を用いた実行環境の構築
ここまでで Docker が利用できるようになり,異なる OS や端末に依存することなく,コーディングを進めることができるようになりました.PyTorch 環境を手に入れるまであと少しです.
2.1. Docker Compose とは?
Docker Compose は,複数のコンテナ(実行環境のこと.詳細は Docker とは?を参照.)で構成されるアプリケーションを,単一のファイルで定義し,管理するためのツールです.ただし,今回はコンテナは用いないものの,コンテナの設定をファイルで管理できるという利便性から Docker Compose を利用します.
初学者にとっては余計な説明になる可能性もありますが,詰まる方も多いので補足をば.
Docker Compose について調べていると,Docker-Compose (- がある) をしばしば見かけます.これらは別物で,例えば起動時のコマンドが異なります.Docker-Compose は Docker の拡張機能として開発されてきましたが,これと同等の機能を公式がサポートすることになり,サブコマンド化されたものが Docker Compose になります.
要は「Docker Compose と Docker-Compose は別物で,違う記事やドキュメントを見て混乱しないでくださいね」という話でした.
2.2. Docker Compose の設定
それでは,実際に PyTorch の実行環境を構築していきましょう.ここで,今回の最終的なコードや環境設定ファイルは以下のリポジトリに載せています.
上記のリポジトリは必要があれば Fork 等して利用していただいて(自己責任にはなりますが)個人的には問題無いです.また,利用方法は README.md に記載しているのでそちらを参照してください.なお,本記事では以上のリポジトリを利用しない前提で進めます.とりあえず動けばそれで良いという方はリポジトリの README.md を参照してもらえればと思いますが,理解して進めたいという方は飛ばさないので安心してください.
それでは Docker Compose による仮想環境の構築のために必要なパーツを1つずつ説明していきます.
2.2.1. docker-compose.yml の記述
docker-compose.yml とはその名の通り,Docker Compose の制御に関する処理を記述するファイルです.このファイルは作業ディレクトリのトップに配置してください.
services:
pytorch-tutorial:
container_name: pytorch-tutorial
build:
context: ./environment
dockerfile: Dockerfile
volumes:
- ./src:/home/workdir/src
- .env:/home/workdir/.env
tty: true
environment:
- PYTHONPATH=/home/workdir/src
上記について順に説明していきます.
以下の説明については理解できていなくても PyTorch を使用する際には問題にならないので,理解できずに諦める前にスキップしてください.
services
services にはコンテナに関する設定を記述していきます.今回であればコンテナは1つだけで pytorch-tutorial が設定されています.
container_name
container_name は作成されるコンテナの名前を指定します.これを設定しない場合,Docker が自動的にランダムな名前を付けますが,自分で分かりやすい名前を付けておくと,後々コンテナを管理する際やアタッチする(コンテナの中に入る)際に便利です.ここでは pytorch-tutorial という名前に設定しています.
build
build はコンテナの元となる Docker イメージを作成するための設定です.
-
context- Dockerfile があるディレクトリのパスを指定する
- 今回は
environmentというディレクトリを指定しています
-
dockerfile- ビルドに使用する Dockerfile のファイル名を指定する
- 今回は
contextで指定したディレクトリ内,即ち./environment/Dockerfileを使うように指定しています
volumes
volumes はホスト PC とコンテナ内のディレクトリを同期させるための設定です.これを「マウントする」と呼び,この設定をしていないものはコンテナを削除した際に破棄されます.
例えば ./src:/home/workdir/src は,ホスト PC の src ディレクトリをコンテナ内の /home/workdir/src ディレクトリにマウントするという設定です.
tty
tty: true はコンテナを起動した際にコンテナの標準入出力をホストマシンに接続し続ける設定です.これにより対話的に操作できるようになります.
より平易な説明をするなら,コンテナ内でコーディング・分析をする際のオプションと理解しても差し支えないと思います.
environment
environment はコンテナ内で使われる環境変数を設定します.
今回は PYTHONPATH という環境変数を設定していますが,これは Python が他のスクリプトを呼び出すことができるようにするもので,高度な操作をするのでなければ必要ないことも多いですが,比較的便利なので採用しています.
2.2.2. Dockerfile の記述
Dockerfile はコンテナの設計図(正確には Docker Image を管理するファイル)です.必要なライブラリやパッケージ,設定を記述していきます.このファイルは docker-compose.yml の build で指定したディレクトリに配置してください.もし上述の docker-compose.yml を利用している場合は environment/Dockerfile とすれば大丈夫です.
FROM ubuntu:22.04
WORKDIR /home/workdir
# Install Python3.10
RUN apt update
RUN apt upgrade -y
RUN apt install -y python3.10
# For initial setting of Python
RUN update-alternatives --install /usr/bin/python python /usr/bin/python3.10 1
RUN apt install -y python3-pip
RUN pip install -U pip
# Installation of basic libraries
RUN pip install python-dotenv icecream tqdm
# Installation of libraries for data analysis
RUN pip install polars
# Installation of libraries for visualization
RUN pip install matplotlib japanize-matplotlib seaborn
# Installation of libraries for deep learning
RUN pip install torch torcheval tensorboard
上記について順に説明します.
こちらも同様で,以下の説明については理解できていなくても PyTorch を使用する際には問題にならないので,理解できずに諦める前にスキップしてください.
FROM
FROM はベースとなるイメージを指定するものです.自作の環境とはいえど全てを1から設計するのではなく,大抵の場合,既にあるものを拝借します.今回は Ubuntu 22.04 を指定しています.
なお,PyTorch 公式が提供しているイメージもありますが,Ubuntu をベースとしていないため,個人的には使い勝手が悪く採用していません.(個人のお好みで選択してください)
WORKDIR
WORKDIR はそれ以下のコマンドを指定のディレクトリで実行するという意味です.しかし今回は,ディレクトリを作成する意図で指定しており,以降のコマンドはディレクトリに依存していません.
RUN
RUN は後に続くコマンドを実行するものです.今回はほとんどパッケージ・ライブラリのインストールのみを行なっています.
2.3. 仮想環境・実行環境の立ち上げ
ここまで準備ができたら環境を立ち上げるだけです.以下のコマンドを実行してイメージを作成します.なお,このコマンドは初回実行時のみで大丈夫です.
docker compose build --no-cache
上記の実行が完了したら,続いて環境を立ち上げるコマンドを実行します.
docker compose up -d
以上を実行して,Started という表示が出たら成功です.
コンテナにアタッチ(コンテナ内に入ること)してみましょう.コマンドでもアタッチできますが,今回は VSCode の拡張機能を利用します.
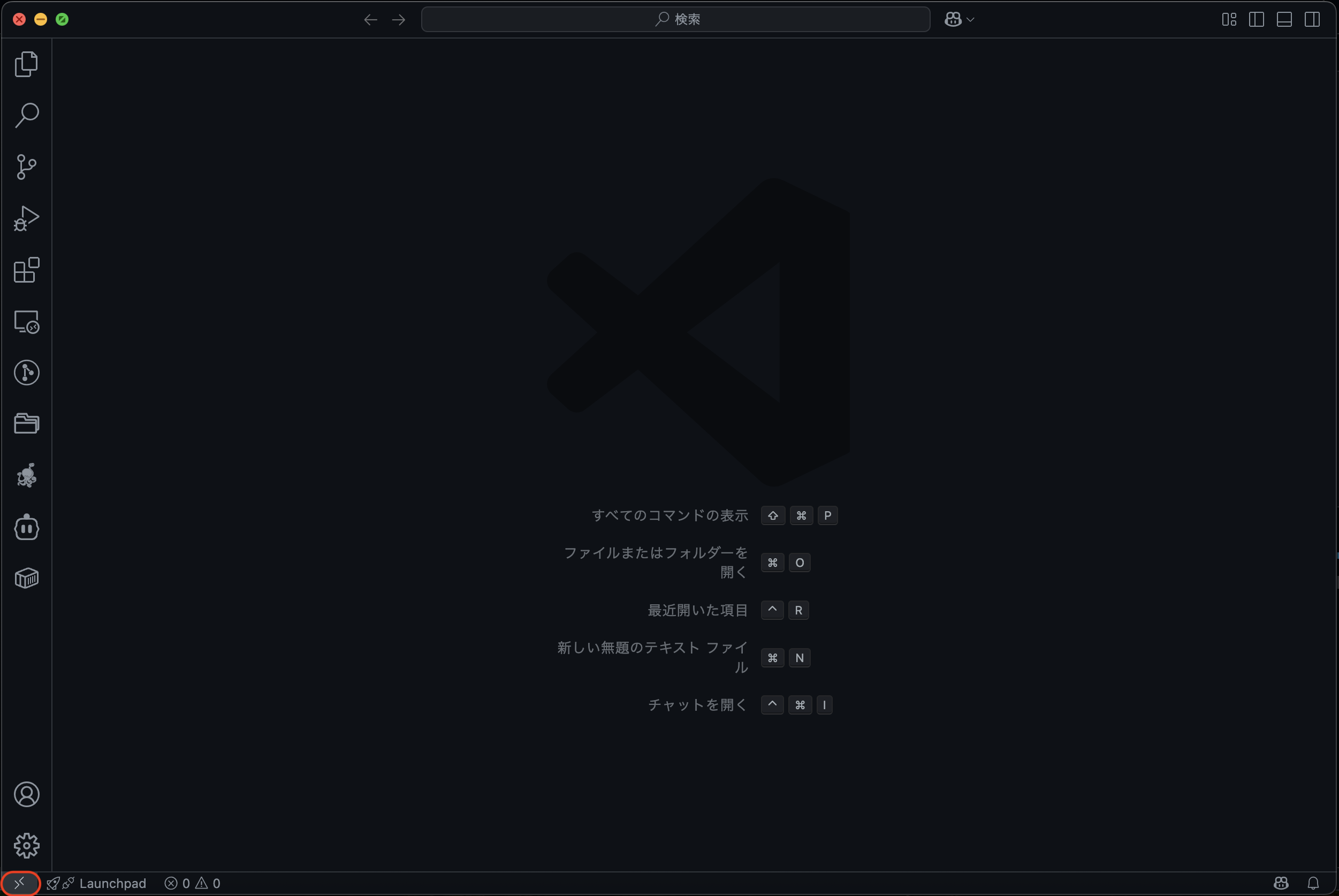
上図の左下,赤枠で囲われた部分を選択し,「実行中のコンテナにアタッチ」を選択.コンテナの一覧が表示されるので,作成したコンテナを選択しましょう.(そのままコピペをしていれば pytorch-tutorial が表示されます)
無事にコンテナにアタッチすることができれば仮想環境・実行環境の設定が終了です.お疲れ様でした!
赤枠の部分を選択しても「実行中のコンテナにアタッチ」が表示されない場合は,拡張機能がインストールされていない可能性が高いです.拡張機能の章を参考に確認してみてください.
3. CPU を用いた深層学習の実装
準備が整ったので,いよいよ PyTorch を用いた深層学習の実装に入ります.まずは基本となる CPU での実装を通して,PyTorch の主要な機能と考え方を学んでいきます.
本章で説明するコードについては以下を参照してください.なお,記事を追っていけば,以下のコードを使わずとも実装できるようにはしたいと思います.
3.1. なぜ PyTorch を使うのか?
深層学習フレームワークには TensorFlow (Keras) や JAX など様々な選択肢があり,数年前までは TensorFlow の方が主流でしたが,ここ最近では(特に研究の分野において)PyTorch の採用が増加しています.いくつかの要因が重なっていると考えられますが,個人的には GPU の利用が大きいと感じています.(効率というよりも実装・管理のしやすさという面で.)
本記事でそれらについて詳細に話し始めると混乱の原因になるためこの程度にしておきますが,最近のトレンドであるという認識を持っていただければと思います.
3.2. PyTorch とは?
PyTorch は Facebook AI Research (現在は Meta) によって開発されたオープンソースの機械学習ライブラリです.その中核は2つの機能にあります.
-
多次元配列(テンソル): NumPyの
ndarrayに似ていますが,GPU上での高速な計算が可能なテンソルを提供します. -
自動微分機能: テンソルに対する演算を追跡し,自動で勾配(微分)を計算する機能(
autograd)を持っています.これにより,ニューラルネットワークの学習に必要な誤差逆伝播法を簡単に実装できます.
これらを基盤として,ニューラルネットワークを構築するための豊富なモジュール(torch.nn)や,データを効率的に扱うためのツール(Dataset, DataLoader)などが提供されています.
3.3. 基本となる機能群
PyTorch で必要となる機能群(コンポーネント)について,順番に解説していきます.
3.3.1. nn.Module
nn.Module は,PyTorchでニューラルネットワークのモデルやレイヤーを構築するための基本となるクラスです.自作のモデルは,必ずこの nn.Module を継承して作成します.このクラスを実装する上で重要なのは,主に2つのメソッドです.
__init__(self)
モデルの構造,つまり層(レイヤー)を定義する場所です.nn.Linear(全結合層)や nn.Conv2d(畳み込み層),nn.ReLU(活性化関数)などをここでインスタンス化(クラスから具体的な実体を作成すること)します.
forward(self, x)
モデルの順伝播,つまりデータがどのように層を通過していくかを定義する場所です.__init__ で定義した層を使って,入力 x から出力 y を計算する処理を記述します.
3.3.2. Dataset / DataLoader
DatasetとDataLoaderは,モデルにデータを効率的に供給するための仕組みです.これらを使用しなくても PyTorch で作成したモデルによる推論は可能ですが,データの処理が非効率的になる上,実装が非常に複雑になります.
Dataset
データセットそのものを表現する抽象クラスです.1つのデータサンプルとその対応するラベルを取得するロジックをカプセル化します.カスタムデータセットを作るには,torch.utils.data.Datasetを継承し,以下の2つのメソッドを実装する必要があります.
-
__init__(self)- 初期化処理を行う関数であり,モデルに与えるデータを
Datasetクラスに渡します.
- 初期化処理を行う関数であり,モデルに与えるデータを
-
__len__(self)- データセットの総サンプル数を返す関数.
-
__getitem__(self, idx)- 指定されたインデックス
idxのデータを返す関数.
- 指定されたインデックス
DataLoader
Datasetからデータを引き出し,ミニバッチを作成し,データをシャッフルするなど,モデルへのデータ供給を自動化してくれる便利なクラスです.原則として Dataset クラスのインスタンスを受け取ります.
3.3.3. 自動微分と torch.no_grad()
PyTorch ライブラリの特徴的な要素の1つに自動微分があります.自動微分とは何かについては(少なくとも初学者にとっては)難しすぎることと,理解していなくても実装自体はできることから,本記事では省略します.(これについての記事を将来的に追加するかもしれませんが)
PyTorch の実装においては,loss.backward() が呼び出されると,その記録を遡って各パラメータの勾配を自動で計算します.この機能のおかげで,複雑な誤差逆伝播の数式を実装する必要が無くなっています.
これに対し,torch.no_grad() を用いることで,勾配計算を無効化することができます.モデルの評価(推論)時や検証時には,パラメータの更新は不要なので勾配計算も必要ありません.with torch.no_grad(): ブロック内で実行される計算は,勾配計算の対象外となり,メモリ使用量の削減と計算速度の向上につながります.特に大規模なデータやモデルを用いた実装では重要な要素になりますが,演算機の性能に対して十分に小さいデータ・モデルの実行においては大きく影響しません.
3.3.4. Optimizer
Optimizer は自動微分によって計算された勾配を用いて,モデルのパラメータ(重みやバイアス)を更新する役割を担います.どの Optimizer を使うかによって,学習の収束速度や安定性が変わります.
代表的な Optimizer には以下のようなものがあります.
-
torch.optim.SGD: 確率的勾配降下法.最も基本的なアルゴリズム. -
torch.optim.Adam: 近年の研究で最も広く使われているアルゴリズムの一つ.多くの場合で安定して高い性能を発揮すると言われており,迷ったらこれにしておくと良いかもしれません.
3.3.5. Scheduler
Scheduler は,学習の進捗に応じて学習率を動的に調整するためのツールです.学習の初期段階では大きな学習率で素早くパラメータを更新し,学習が進むにつれて学習率を小さくして最適解に細かく近づけていく,といった戦略を自動化できます.
代表的な Scheduler には以下のようなものがあります.
-
torch.optim.lr_scheduler.StepLR: 指定したステップ数ごとに学習率を一定の割合で減衰させます. -
torch.optim.lr_scheduler.CosineAnnealingLR: コサインカーブに従って学習率を周期的に変動させます.
Scheduler は必須ではありませんが,モデルの性能をさらに引き出すために有効なテクニックであり,実装の難易度もそれほど高くないものです.
3.3.6. train() / eval() モード
nn.Moduleから作成されたモデルは,「訓練モード(train mode)」と「評価モード(evaluation mode)」の2つの状態を持ちます.これらはそれぞれ model.train() / model.eval() により変更されます.この切り替えが重要なのは,一部の層(Dropout や BatchNorm など)が訓練時と評価時で異なる振る舞いをするためです.初めのうちはどのようなアーキテクチャが対象となるのかという判断が難しいと思いますので,いずれのモデルについてもモードを明示的に切り替えておくのが良いかもしれません.
3.4. CPU での学習ループ全体像
以上のコンポーネントを踏まえて順番に実装していきます.
3.4.1. ライブラリのインポート
まずはライブラリのインポートから.
from tqdm import tqdm
from icecream import ic
import torch
from torchvision.datasets import FashionMNIST
from torchvision.transforms import ToTensor, Lambda
from torch.utils.data import DataLoader
import torch
from torch import nn
from torch.optim import Adam
from torch.optim.lr_scheduler import StepLR
from torcheval.metrics import MulticlassAccuracy
いくつか説明していなかったライブラリについて,以下に説明します.
- tqdm
- ループ処理の状況をわかりやすく可視化してくれるライブラリ
- 特に深層学習の場面では1回のループ処理に多くの時間がかかり,進捗が見にくくなるため,こうしたライブラリを利用することが有効です
- torchvision
- PyTorch の中でも画像処理に特化した処理群を提供するライブラリ
- 今回はチュートリアルとして広く一般に利用されている FashionMNIST というデータセットを取得するために利用
- torcheval
- PyTorch の中でも性能評価に特化した処理群を提供するライブラリ
- 今回はミニバッチ処理 & マルチクラス分類という少し面倒なスコア算出を簡単にするために導入
3.4.2. データのロード
続いて,データのロードを行います.
train_data = FashionMNIST(
root=data_root_dir,
train=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(NUM_TARGET, dtype=torch.float).scatter(0, torch.tensor(y), value=1)),
download=True,
)
test_data = FashionMNIST(
root=data_root_dir,
train=False,
transform=ToTensor(),
download=True,
)
train_dataloader = DataLoader(
dataset=train_data,
batch_size=64,
shuffle=True,
)
test_dataloader = DataLoader(
dataset=test_data,
batch_size=64,
shuffle=False,
)
Dataset に関する説明では Dataset クラスを定義する必要があると述べましたが,TorchVision を用いることで Dataset クラスのインスタンスを複雑な処理をすることなく取得することができます.
これを DataLoader に与えることで目的のインスタンスを取得することができます.
3.4.3. 深層学習モデルの定義
続いて,深層学習モデルを定義します.
class ConvolutionalNeuralNetwork(nn.Module):
def __init__(self):
'''
ネットワークの要素を定義する関数
ここで定義した要素を forward 関数で呼び出し,順伝播の計算を定義する
'''
super().__init__()
self.conv1 = nn.Conv2d(
in_channels=1,
out_channels=6,
kernel_size=3,
stride=1,
padding=0
)
self.pool1 = nn.MaxPool2d(
kernel_size=2,
padding=0
)
self.conv2 = nn.Conv2d(
in_channels=6,
out_channels=16,
kernel_size=3,
stride=2,
padding=1
)
self.pool2 = nn.MaxPool2d(
kernel_size=2,
padding=1
)
self.flatten = nn.Flatten(
start_dim=1
)
self.fc = nn.Linear(
in_features=(4 ** 2) * 16,
out_features=1024
)
self.fc_out = nn.Linear(
in_features=1024,
out_features=NUM_TARGET
)
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
def forward(self, X):
'''
順伝播の計算を定義する関数
ネットワークの要素を定義した __init__ 関数で定義した要素を呼び出して,計算の順序を定義する
'''
h = self.conv1(X)
h = self.pool1(h)
h = self.relu(self.conv2(h))
h = self.pool2(h)
h = self.flatten(h)
h = self.relu(self.fc(h))
y = self.fc_out(h)
return self.softmax(y)
cnn = ConvolutionalNeuralNetwork()
ic(cnn)
3.4.4. 学習と評価
最後に,学習と評価を行います.
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=LEARNING_RATE)
scheduler = StepLR(optimizer, step_size=LR_STEP_SIZE, gamma=LR_GAMMA)
criterion = MulticlassAccuracy()
model = cnn
for epoch in tqdm(range(EPOCHS), desc='Epoch'):
current_lr = scheduler.get_last_lr()[0]
ic(epoch, current_lr)
'''
学習フェーズ
1. ミニバッチ単位でデータを取得
2. モデルによる推論(順伝播)
3. 損失関数の計算
4. 勾配の計算(逆伝播)
5. パラメータの更新
'''
model.train() # 学習モードに設定(Dropout や BatchNorm を利用する場合に必要)
for inputs, targets in tqdm(train_dataloader, desc=f'Epoch {epoch+1} / {EPOCHS}', leave=False): # 1. ミニバッチ単位でデータを取得
predicts = model(inputs) # 2. モデルによる推論(順伝播)
loss = loss_fn(predicts, targets) # 3. 損失関数の計算
optimizer.zero_grad() # optimizer の勾配を初期化
loss.backward() # 4. 勾配の計算(逆伝播)
optimizer.step() # 5. パラメータの更新
predicts = predicts.argmax(dim=1)
targets = targets.argmax(dim=1)
criterion.update(predicts, targets) # 推論結果の記録
acc = criterion.compute() # スコアの計算(今回は multiclass_accuracy を利用)
ic('Train', epoch, acc)
criterion.reset() # スコア計算のための状態をリセット
'''
評価フェーズ
1. ミニバッチ単位でデータを取得
2. モデルによる推論(順伝播)
3. スコアの計算
また,評価フェーズではモデルのパラメータを更新しないため,torch.no_grad() を利用して,勾配計算を無効化することで,メモリ使用量の削減と計算高速化を図る
'''
model.eval() # 評価モードに設定(Dropout や BatchNorm を利用する場合に必要)
with torch.no_grad():
for inputs, targets in tqdm(test_dataloader, desc=f'Epoch {epoch+1} / {EPOCHS}', leave=False): # 1. ミニバッチ単位でデータを取得
predicts = model(inputs) # 2. モデルによる推論(順伝播)
predicts = predicts.argmax(dim=1)
# targets = targets.argmax(dim=1)
criterion.update(predicts, targets) # 推論結果の記録
acc = criterion.compute() # 3. スコアの計算
ic('Evaluate', epoch, acc)
criterion.reset() # スコア計算のための状態をリセット
scheduler.step() # 学習率スケジューラの更新
3.5. 学習の実行
ここまで説明してきた内容を .py スクリプトに保存して実行すると学習がスタートします.例えば私の環境(CPU: AMD Ryzen 9 7950X)では,7分22秒で実行が完了し,学習データで 94.86%,評価データで 89.92% を達成しました.
ここまで来れば,1つの大きな山を越えることができたと思います!この先の GPU を用いた深層学習の実装に向けて休憩を挟んでも良いかもしれません.
4. GPU 環境の構築
CPU での実装ができ,一段落してみると,実行速度の遅さが気になってくると思います.深層学習の特徴の1つに GPU による計算の効率化・高速化が挙げられます.なぜ高速化されるのかという部分については深く理解しようとすると意外と高度な話ではあるのですが,以下の記事は非常によくまとまっており,初学者でも比較的理解しやすいかもしれません.
本章以降では GPU を用いた深層学習の実装のために必要となる要素について,順に説明していきたいと考えていますが,多くの人が挫折するポイントではあるので,先に代替案を提示しておきます.先にも述べたように,研究という場面を想定して Docker を用いたオンプレミスサーバ上での実行を説明していましたが,これが中々に厄介です.そこで,外部に出せないデータを使っている場合には注意が必要となりますが,無料で GPU が利用可能なサービスがあります.
Google Colaboratory についての説明は上記の記事に任せることにして,以下ではオンプレミスサーバでの実行について順に説明していきます.
4.1. 制限
以降の章では以下の制限・前提のもとで説明していきます.
- GPU を搭載した Linux (Ubuntu) サーバ上
- GPU は Nvidia 製のもので,マウント済み
- シングルノード・シングル GPU
最近では徐々に機能が充実されつつあるものの,依然として PyTorch では Nvidia 製の GPU で実行する場合が簡単です.また,複数の GPU を用いた実装はチュートリアルとしては必要以上に難しくなりすぎるため,除外します.
4.2. NVIDIA Driver, NVIDIA Container Runtime, CUDA Toolkit とは?
GPU を Docker コンテナから利用するためには,ホストサーバ(Linux サーバ本体)にいくつかのコンポーネントを正しくインストールする必要があります.これらの関係性を理解していなくとも実装自体は可能だと思いますが,トラブルシューティングにおいてはその対処を容易にするという点で是非とも理解しておきたいところになります.ただ,ここで断念してしまうよりはスキップしてでも続けた方が良いので,負担にならない程度に進めてみてください!
4.2.1. NVIDIA Driver
NVIDIA Driver とは GPU ハードウェアと OS(Linuxカーネル)を繋ぐ最も基本的なソフトウェアです.これがなければ,OS は GPU を認識・制御できません.全ての GPU 関連ソフトウェアの土台となります.
ホストサーバにインストールして利用します.
4.2.2. NVIDIA Container Runtime
NVIDIA Container Runtime とは Docker コンテナがホストサーバの NVIDIA Driver を介して GPU にアクセスできるようにするための「橋渡し役」です.コンテナ実行時に,ホストの GPU デバイスやドライバファイルをコンテナ内にマウントする処理を担います.
ホストサーバにインストールして利用します.
4.2.3. CUDA Toolkit
CUDA Toolkit とは GPU 上で汎用的な並列計算を行うための NVIDIA のプラットフォームです.コンパイラ(nvcc),ライブラリ(cuBLAS, cuDNN など),APIが含まれます.アプリケーションを開発・コンパイルする際に必要となります.
ホストサーバにインストールする必要はありません.
4.3. なぜホストサーバに CUDA Toolkit は不要なのか?
この点が最も悩ましいポイントです.従来はホストサーバにも CUDA Toolkit をインストールする必要があり,ドライバとのバージョン互換性に悩まされることが多々ありました.しかし,NVIDIA Container Runtime の登場により,アーキテクチャは以下のように変わりました.
- ホストサーバ: 物理GPUと通信するための NVIDIA-Driver と,コンテナに GPU を公開するための NVIDIA Container Runtime さえあれば良い
- Dockerコンテナ: アプリケーションの実行に必要な CUDA を配置
- 実行時: コンテナ内のアプリケーション(今回であれば PyTorch)は,コンテナ内の CUDA ライブラリを利用します.そして,実際の GPU への命令は,NVIDIA Container Runtime を介してホストの NVIDIA Driver に伝えられ,実行されます
この仕組みにより,ホストの環境は最小限(ドライバのみ)に保ちつつ,プロジェクトごとに異なる CUDA バージョンのコンテナを自由に使い分けることが可能になりました.
こうした仕様の変更により,複数の GPU 環境の構築に関する記事によって異なる説明がなされ,周りでも混乱する人が多くいらっしゃいます.記事の作成日についてはよくチェックしてもらえればと思います.
4.4. NVIDIA Driver のインストール
先ず,以下のコマンドでドライバの一覧を取得します.
$ ubuntu-drivers devices
以下のような一覧が表示されます.
vendor : NVIDIA Corporation
model : TU104 [GeForce RTX 2080]
driver : nvidia-driver-418-server - distro non-free
driver : nvidia-driver-525 - distro non-free
driver : nvidia-driver-535-server-open - distro non-free
driver : nvidia-driver-535 - distro non-free recommended
driver : nvidia-driver-525-server - distro non-free
driver : nvidia-driver-525-open - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-535-open - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : nvidia-driver-470-server - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
以上のリストから,1つ適切なものを選択し,以下のコマンドでインストールを実行してください.
$ sudo apt install nvidia-driver-***
基本的にrecommendedと書いてあるものを選択すれば問題ないと思います.
なお,自身で選択する以外の方法もあり,下記のコマンドであれば,面倒な確認は必要なく,これだけでインストールが可能なようです.ただ,エラーが出るという記事もそれなりに多く見受けられるので,ご自身で手間を天秤にかけてご判断下さい.
$ sudo ubuntu-drivers autoinstall
インストールが完了したら,動作確認をおこないます.以下のコマンドを実行してください.
$ nvidia-smi
以下のような出力が得られれば成功です.
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 2080 Off | 00000000:01:00.0 On | N/A |
| 28% 52C P8 4W / 215W | 300MiB / 8192MiB | 1% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 2058 G /usr/lib/xorg/Xorg 64MiB |
| 0 N/A N/A 2167 C+G ...libexec/gnome-remote-desktop-daemon 112MiB |
| 0 N/A N/A 2204 G /usr/bin/gnome-shell 118MiB |
+---------------------------------------------------------------------------------------+
4.5. NVIDIA Container Runtime のインストール
以下のコマンドを順に実行します.
$ curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | sudo apt-key add -
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
$ sudo apt update
$ sudo apt install nvidia-container-runtime
$ service docker restart
これにより Docker から GPU を認識することができるようになります.
4.6. エラー対処について
しばしば遭遇するエラーに以下のようなものがあります.

Your system has UEFI Secure Boot enabled.
UEFI Secure Boot requires additional configuration to work with third-party drivers.
The system will assist you in configuring UEFI Secure Boot. To permit the use of third-party drivers, a new Machine-Owner Key (MOK) has been generated. This key now needs to be enrolled in your system's firmware.
To ensure that this change is being made by you as an authorized user, and not by an attacker, you must choose a password now and then confirm the change after reboot using the same password , in both the "Enroll MOK" and "Change Secure Boot state" menus that will be presented to you when this system reboots.
If you proceed but do not confirm the password upon reboot, Ubuntu will still be able to boot on your system but any hardware that requires third-party drivers to work correctly may not be usable.
こちらのトラブルシューティングについては,以下の記事を以前に公開しているので,こちらを参考にしてもらえればと思います.
4.7. Docker Compose の設定
以上まででホストサーバの設定は完了です.お疲れ様でした!
しかし,このままではコンテナ内で GPU が利用できないため,Docker Compose の設定を変更してあげる必要があります.編集すべきファイルは docker-compose.yml で,以下のようにしてください.
services:
pytorch-tutorial:
container_name: pytorch-tutorial
build:
context: ./environment
dockerfile: Dockerfile
volumes:
- ./src:/home/workdir/src
- .env:/home/workdir/.env
tty: true
environment:
- PYTHONPATH=/home/workdir/src
- "NVIDIA_VISIBLE_DEVICES=all"
- "NVIDIA_DRIVER_CAPABILITIES=all"
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities:
- gpu
変更箇所は2点あり,
-
environmentに以下の2つを追加"NVIDIA_VISIBLE_DEVICES=all""NVIDIA_DRIVER_CAPABILITIES=all"
-
deployブロックを設定
となっています.
Docker のバージョンによって書き方が変わる可能性もあるので,詳細は以下の公式ドキュメントを参照してください.
以上の設定が完了したらコンテナの再起動を実行し,コンテナ内で GPU が利用できるかを確認(nvidia-smi を実行)してください.
5. GPU を用いた深層学習の実装
GPU 環境が整ったらいよいよ実装です.CPU を用いた実装コードに少し変更を加えるだけで GPU が利用可能となりますが,CPU とは異なるいくつかの注意点が存在します.
5.1. GPU を用いた実装の注意事項
GPU は非常に強力なデバイスですが,まだまだ限られたリソースであることがほとんどだと思います.こうした状況では CPU を使っている時にはあまり意識しない問題が発生します.
5.1.1. 他プロセスとの競合
GPU は共有リソースのため,他のユーザが利用しているところに新たなプロセスを投げることで,そのユーザの実行速度が低下したり,場合によっては停止することがあります.学習を実行する前に GPU の利用状況を確認し,可能であれば空いているデバイスを用いるといった選択をすることが望ましいかもしれません.
ここで,注意が必要なポイントがあり,一見すると余裕があるように見える使用状況でも,様々な要因により停止する可能性があるということです.実際に私が遭遇した例では,電力不足がありました.そのため,上述のように空いているデバイスを用いる方が良いという訳です.
5.1.2. Out of Memory (OOM)
GPU 実装で最も頻繁に遭遇するのが OOMエラー といっても過言ではないと思います.これは,モデルのパラメータ,中間層の出力,勾配などを保存するための GPU メモリ(VRAM)が足りなくなった場合に発生します.
こうした場合の対策のうち,バッチサイズの調整については(個人的な感覚ですが)比較的簡単なため,まずはこちらを試すのが良いかもしれません.これ以外の主な対策として以下のものが挙げられます.
- CPU Offloading / NVMe Offloading
- Parallelism
- 混合精度の導入
これらについてはかなりのボリュームのキャッチアップが必要となるため,根本的な解決になってはいませんが,より性能の良い GPU を用いるように変更することが最速かもしれません.
5.2. ミニバッチ処理
実は既に CPU を用いた実装において登場していますが,詳細な説明はしていませんでした.上述の通り OOM 対策の1つとなるのがミニバッチ処理です.データセット全体を一度に処理するのではなく,batch_size で指定された小さな塊(ミニバッチ)に分割して処理する手法です.DataLoader はまさにこのミニバッチを自動で作成してくれるクラスです.
5.3. GPU を用いた学習コード
上述の通り,CPU のコードを少し変更するだけで GPU が利用できるようになります.主な変更はテンソルやモデルをGPUに転送する処理の追加ですが,移動させるべきものとそうでないものが最初のうちはわかりにくいと思います.本記事では差分を確認しながら,移動させるべきものを確認していきます.
なお,GPU 版のコードの全体像は以下のリンクから確認いただけます.
コードの差分は以下の通りです.
--- pytorch-cpu-tutorial.py 2025-09-06 08:09:13.205878897 +0000
+++ pytorch-gpu-tutorial.py 2025-09-07 05:23:08.268295590 +0000
@@ -31,6 +31,7 @@
EPOCHS = 100
LR_STEP_SIZE = 10
LR_GAMMA = 0.5
+DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # GPU が利用可能であれば GPU を利用する
data_root_dir = '/home/workdir/datasets' # データセットの保存先ディレクトリ.複数回読み込む場合に,ダウンロードすることなく,保存したデータセットを利用することができる
@@ -156,11 +157,11 @@
2. 最適化手法:今回は Adam を利用する
3. (任意)学習率スケジューラ:今回は StepLR を利用する
'''
-loss_fn = nn.CrossEntropyLoss()
+loss_fn = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(cnn.parameters(), lr=LEARNING_RATE)
scheduler = StepLR(optimizer, step_size=LR_STEP_SIZE, gamma=LR_GAMMA)
-criterion = MulticlassAccuracy()
-model = cnn
+criterion = MulticlassAccuracy().to(DEVICE)
+model = cnn.to(DEVICE)
'''
@@ -183,6 +184,8 @@
'''
model.train() # 学習モードに設定(Dropout や BatchNorm を利用する場合に必要)
for inputs, targets in tqdm(train_dataloader, desc=f'Epoch {epoch+1} / {EPOCHS}', leave=False): # 1. ミニバッチ単位でデータを取得
+ inputs, targets = inputs.to(DEVICE), targets.to(DEVICE)
+
predicts = model(inputs) # 2. モデルによる推論(順伝播)
loss = loss_fn(predicts, targets) # 3. 損失関数の計算
@@ -209,6 +212,8 @@
model.eval() # 評価モードに設定(Dropout や BatchNorm を利用する場合に必要)
with torch.no_grad():
for inputs, targets in tqdm(test_dataloader, desc=f'Epoch {epoch+1} / {EPOCHS}', leave=False): # 1. ミニバッチ単位でデータを取得
+ inputs, targets = inputs.to(DEVICE), targets.to(DEVICE)
+
predicts = model(inputs) # 2. モデルによる推論(順伝播)
predicts = predicts.argmax(dim=1)
順番に変更点を確認します.
5.3.1. Device の指定
利用するデバイス(CPU / GPU)を指定します.単に GPU と記述しても良いのですが,GPU が利用可能かを判定してからデバイスを指定するコードを記述するのが一般的です.
--- pytorch-cpu-tutorial.py 2025-09-06 08:09:13.205878897 +0000
+++ pytorch-gpu-tutorial.py 2025-09-07 05:23:08.268295590 +0000
@@ -31,6 +31,7 @@
EPOCHS = 100
LR_STEP_SIZE = 10
LR_GAMMA = 0.5
+DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # GPU が利用可能であれば GPU を利用する
data_root_dir = '/home/workdir/datasets' # データセットの保存先ディレクトリ.複数回読み込む場合に,ダウンロードすることなく,保存したデータセットを利用することができる
5.3.2. GPU へのロード
GPU にロードすべきデータとして,以下のものがあります.
- Loss 関数
- 評価関数
- モデル
- バッチ(入出力データ)
それ以外についてはロードする必要はありません.これらがなぜロードするべきかを理解するためには GPU 上でどのように演算が行われているかを理解するところから始める必要はありますが,単に使うだけで良いという方や初学者にとっては上記のコンポーネントのロードが必要であると暗記しておくので十分かなと個人的には思っています.
--- pytorch-cpu-tutorial.py 2025-09-06 08:09:13.205878897 +0000
+++ pytorch-gpu-tutorial.py 2025-09-07 05:23:08.268295590 +0000
@@ -156,11 +157,11 @@
2. 最適化手法:今回は Adam を利用する
3. (任意)学習率スケジューラ:今回は StepLR を利用する
'''
-loss_fn = nn.CrossEntropyLoss()
+loss_fn = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(cnn.parameters(), lr=LEARNING_RATE)
scheduler = StepLR(optimizer, step_size=LR_STEP_SIZE, gamma=LR_GAMMA)
-criterion = MulticlassAccuracy()
-model = cnn
+criterion = MulticlassAccuracy().to(DEVICE)
+model = cnn.to(DEVICE)
'''
@@ -183,6 +184,8 @@
'''
model.train() # 学習モードに設定(Dropout や BatchNorm を利用する場合に必要)
for inputs, targets in tqdm(train_dataloader, desc=f'Epoch {epoch+1} / {EPOCHS}', leave=False): # 1. ミニバッチ単位でデータを取得
+ inputs, targets = inputs.to(DEVICE), targets.to(DEVICE)
+
predicts = model(inputs) # 2. モデルによる推論(順伝播)
loss = loss_fn(predicts, targets) # 3. 損失関数の計算
@@ -209,6 +212,8 @@
model.eval() # 評価モードに設定(Dropout や BatchNorm を利用する場合に必要)
with torch.no_grad():
for inputs, targets in tqdm(test_dataloader, desc=f'Epoch {epoch+1} / {EPOCHS}', leave=False): # 1. ミニバッチ単位でデータを取得
+ inputs, targets = inputs.to(DEVICE), targets.to(DEVICE)
+
predicts = model(inputs) # 2. モデルによる推論(順伝播)
predicts = predicts.argmax(dim=1)
5.4. 学習の実行
CPU 版と同様に実行することができます.私の環境(CPU: AMD Ryzen 9 7950X)では7分22秒で実行が完了しましたが,GPU (NVIDIA GeForce RTX 4090) を用いた実行では5分45秒で実行が完了しました.
よくある勘違いとして GPU を用いることで何千倍にも学習速度が高速になるというものがありますが,設定次第では数倍程度の高速化にしかならないこともあります.本記事では取り扱いませんが,学習の高速化も奥が深く,精度とのトレードオフを考慮する必要があります.本記事で提示しているコードは比較的 VRAM が小さい GPU でも利用可能なように設定していますが,例えば pinn_memory / num_worker / batch_size を調整してあげることで,学習時間は50秒になりました.
最後に
以上で,全くの初学者から GPU を用いた深層学習の実装までの一連のチュートリアルは完了です.冒頭でも述べたように,本記事は最低限の内容のみを扱っているため,トラブルシューティングや個別具体的な知識については不足しています.
また,本記事は構想から公開まで1日で走ったものになりますので,誤字脱字・乱文,説明の不足が十分に考えられます.今後,気力があれば補足説明を追加する可能性もありますが,主にこうした文章の修正を進める予定のため,文章の違和感については多めにみてもらえると幸いです.