◾️はじめに
前回の記事ではwatsonx.aiとLangGraphで最小限のチャットボットを作ってみました。LangGraphのメモリ管理機能による、チャットの会話履歴がどのように管理されるかを試してみました。
ただ、こちらの記事では単純に会話履歴を全て入れるだけしかやっていないため、今回はある程度会話履歴が溜まったら会話履歴を要約するノードを追加して、入力トークンを抑制する仕組みを作ってみたいと思います。
◾️前提
- 続編的な記事です。初見の方は、前回の記事を読んでから戻ってきていただけると幸いです。
- 初学者向けの記事です。所謂やってみた系の記事です。
- 私自身が非エンジニアなので、間違い、アドバイスあれば、コメントで指摘お願いします!
- 当記事ではプラットフォームはwatsonx.aiを使います。無償評価版などは前回記事から登録可能です。
- 最近のIBMのGraniteモデルの性能を見たいので、使用するLLMは全て”ibm/granite-3-3-8b-instruct”を使っております。
本題の会話履歴の要約につてはこちらから
◾️…本題の前に、LangSmithによる会話トレースについて
前回の記事で面倒だったのは、LLMとのやりとりが意図通りに行われているかの確認でした。いちいち手動でwatsonx.aiのAPIからprintして確認…という原始的で愚かなことを繰り返していたのですが、世の中には便利な「LangSmith」という仕組みがあるらしく、これを使えば、簡単にLLMとの会話の流れを確認できるとのことです。もっと早く知りたかった…
LangSmithについては以下を参考にさせていただきました。概要説明や詳しい使い方はこちらの記事にお任せするとしましょう。
あとは公式のクイックスタートがとても良いです。
あえてLangSmithについて簡単に説明すると、「LLMアプリを本番運用向けに監視・評価・改善するための開発プラットフォーム」であり
- LLMとのやりとりを可視化、応答品質や性能(遅延/エラー率/コスト)をダッシュボードで確認・アラート設定までできる。
- 実際のデータで動作評価。LLMによる自動スコアリングや、人間によるフィードバックも収集可能。
- プロンプトの設計が可能。バージョン管理や、出力結果の比較・改善ができるプレイグラウンドも搭載。
などができるツール、ということができます。今回はLLMとのやりとりを可視化だけ触ってみます。
さて、ではLangSmithを早速使ってみたいと思います。とは言っても前回の記事から追加でやることは少しです。
1.アカウント登録&API Key取得
以下にアクセスして、SignUp してアカウントを作りましょう。
その後、Home画面 → Settings→ API Keys と移動して 「Create API Key」からAPI Keyを作成、コピーしておきましょう。※👇参考画像

2.環境変数に設定
前回作った.envファイルに以下を記述していきましょう。
LANGCHAIN_API_KEY=******* # 1.で取得したもの。LangSmithのAPIキー(認証に使用)
LANGCHAIN_TRACING_V2=true # 新しいトレーシング機能(V2)を有効にする
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com # LangSmithのAPIエンドポイントURL
LANGCHAIN_PROJECT=watsonx-demo # トレースデータを紐づけるプロジェクト名(任意の名前でOK)
3.使ってみる
前回作ったチャットボットapp.pyをもう一回実行、全く同じやりとりをしてみます。
その後、もう一回LangSmithにアクセスしSign UpしてみるとマイページのHome画面のObservabilityに 2.のLANGCHAIN_PROJECT=~ で設定したプロジェクト名が表示されます(当記事の通りにやっていれば、watsonx-demoと表示されるはず)※👇参考画像
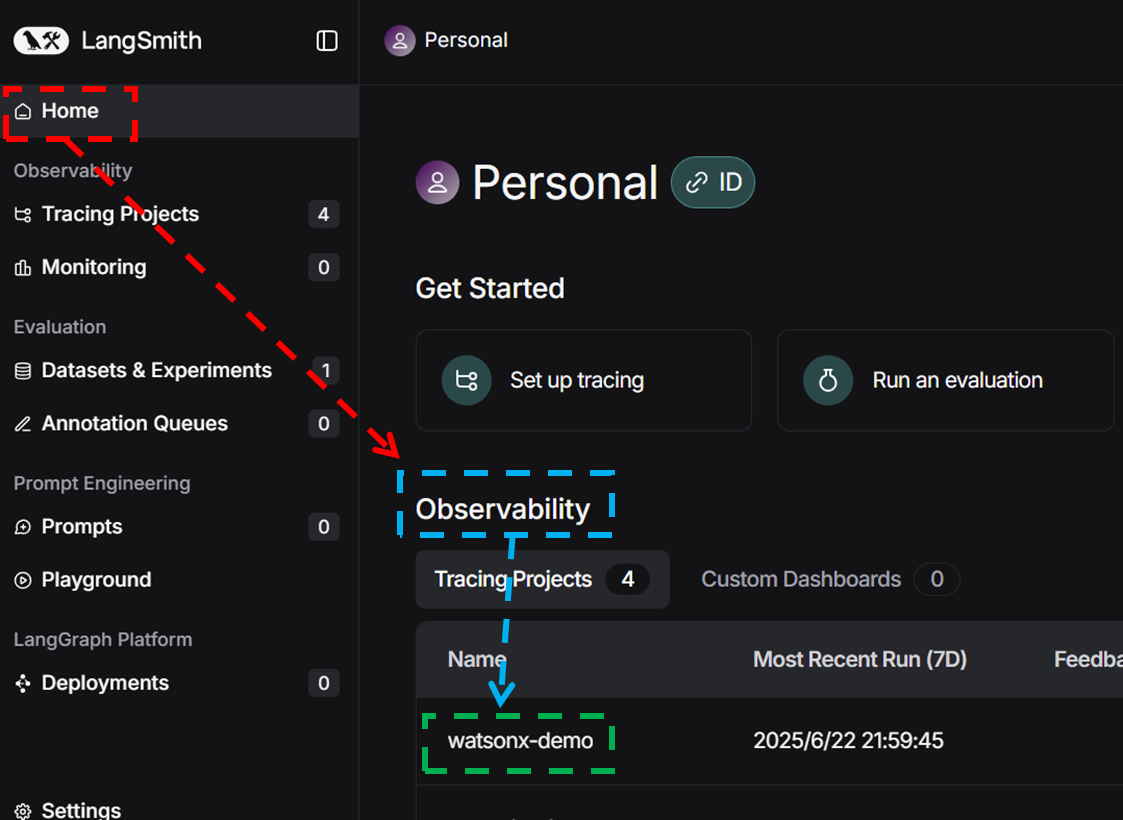
このプロジェクト名watsonx-demoをクリックしてみましょう。するとLLMとの一回のやり取り、つまり実行結果(Run)ごとの結果が表示されています。列に表示される情報は以下の通り、
| カラム | 説明・内容 |
|---|---|
| Name | 実行の名前(例:chain名/LLM呼び出し名) |
| Input | ユーザー入力またはプロンプト内容 |
| Output | LLMの応答内容 |
| Error | エラー有無(✔は成功、✕は失敗) |
| Start Time | 実行の開始日時 |
| Latency | 応答までの総時間(秒) |
| Cost | このRunにかかった推定コスト(トークン×単価) |
| First Token | 最初の応答トークンが出るまでの時間(初速) |
| Tokens | 使用されたトークン数(入力+出力) |
| Dataset | このRunが属する評価用データセット |
| Annotation Queue | 人手評価待ち状態かどうか |
| Tags | SDKやAPIで設定された任意のタグ(例:バージョン名) |
| Metadata | 補足情報(例:thread_id, session_idなど) |
| Feedback | 人や自動評価ツールによるスコア・コメント |
| Reference Example | 正解例(リファレンス)との比較基準出力 |
例えば、InputとOutputが分かったり、使ったトークン数が、LLMの一回の利用当たりに行毎に表示される。そしてこのプロジェクト(watsonx-demo)全体を通してどれくらいトークン数がかかったのかなど、全体感も確認できます。
※👇参考画像

一つ行を選んでLLM一回の利用について、もう少し詳しく見てみましょう。今回は2回目にLLMに投げかけた時のRun結果を見てみます。※該当行をクリック。
するとどのような構造でLLMに投げられたのかが階層ごとに、Input、Outputが見て取れます。前回の記事のチャットボットの場合だと、watsonx.aiのAPIの呼び出しに関わっている部分を、階層別に書いてみると、
-
Graph全体(GraphState)がとしての…
入力:ユーザーの入力だけ
出力:ユーザー入力に対するAIの回答含む、会話履歴全て -
GraphStateの中で定義されている'llm'ノード(実体はこの関数)としての…
入力:Stateに保持されているそれ以前の会話履歴 + ユーザー入力
出力:AIの回答 -
'llm'ノードとして扱われる関数の中で使われているLangChainとしての…
入力:システムプロンプト + Stateに保持されているそれ以前の会話履歴 + ユーザー入力
出力:AIの回答
となります。以下画像の様に
画面左側の階層を切り替えていくと、各々のInputOutputが確認でき、処理の流れがよくわかります。これをみる限り、しっかりとChatWatsonxが会話履歴を認識して、Graniteが返答をしているのがよくわかりますね!
※👇参考画像

これらを利用することで、エラーの原因究明やコスト管理、テストに役立つほか、さらにはPlayGroundによりちょっとしたプロンプトの確認ができるため、テストのたびに全て回さなくても都度確認ができるため実験の費用が浮くわけです。
あと、価格と性能の比較をサッとしたい時にいいかもしれないです。
以後、このLangSmithを使って会話の履歴管理がうまくいっているのかの確認と、トークン数がどうか等を確認していきたいと思います。
◾️[本題]LangGraphで“会話履歴の自動要約”を組み込む
前置きが長くなりましたが、ここから本題の前回作ったチャットボットの会話履歴を要約して圧縮する仕組みを実装していきましょう。
とはいえ、やることはシンプルで、一定の会話往復量を超えた場合、LLMに要約をさせて結果をシステムプロンプトに設定する、というノードをLLMを呼び出すノードの前に組み込んでいきます。色んなやり方があると思いますが、今回は、
- 会話の往復「回数」を見て要約するか否かを決めるパターンと、
- 「トークン数」を見て要約するか否かを決める
の2パターンを実装してみようと思います。
1.会話の往復「回数」を見て要約するか否かを決めるパターン
1-1.実装例
基本的には前回のチャットボットをベースにしますが、要約を保持・随時更新するための変数と要約をした時点での会話回数のながさをState側で保持できるようしておきます。
また、どのくらい会話回数が貯まったら要約するかのメッセージ数と、要約するとは言っても最新の会話くらいはそのまま残しておきたいので、そのメッセージ数をここで指定してます。
class GraphState(MessagesState):
summary_text: str | None = None # 直近の要約
last_summarized_len: int = 0 # 要約を作った時点での messages の長さ
SUMMARY_TRIGGER = 7 # 要約を走らせるメッセージ増分
TAIL_KEEP = 3 # 要約の他に保持する最新メッセージ数
準備が整ったところで、要約用のsummaryノードとしてGraphに組み込む関数を作っていきます。
まず現在のメッセージ数を取り出し、前回要約した位置(last_summarized_len)から SUMMARY_TRIGGER 分以上(ここでは 7 件)メッセージが増えているかを判定します。増えていなければ要約はスキップしてそのまま state を返します。
要約が必要な場合は、直近の 7 件のうち “最新の 3 件” はそのまま残し、それ以前の 4 件を要約対象に選びます(これはTAIL_KEEPでコントロール)。さらに、既に作成済みの要約summary_textがあればそれも要約入力に加え、過去のやり取りを一つのまとまった要約に連結できるようにします。
それらを ChatPromptTemplate を使って「以下の会話を簡潔に日本語で要約してください」というシステムプロンプトを組み、LLMに送り新しい要約文を取得します。最後に summary_text をこの新しい要約で更新し、last_summarized_len を「今回要約した分だけ」増やしておくことで、同じメッセージを重複して要約するのを防ぎます。
※ファイル名がapp.pyだと混同するのでcount_sum_app.pyとしておきます。
# システムプロンプト用。前回インポートしていなかったので…
from langchain_core.messages import SystemMessage
def call_summary(state: GraphState) -> dict:
msgs = state["messages"]
# 前回要約した位置から SUMMARY_TRIGGER 件以上増えたら要約する。
last_len = state.get("last_summarized_len", 0)
if len(msgs) - last_len < SUMMARY_TRIGGER:
return state
# 要約対象のメッセージだけ抽出。すでにある要約とつなげる。
old_part = msgs[-SUMMARY_TRIGGER:-TAIL_KEEP]
summary_input = []
if "summary_text" in state:
summary_input.append(SystemMessage(content=state["summary_text"]))
summary_input.extend(old_part)
# あとはLLMに要約させるだけ。
summary_prompt = ChatPromptTemplate.from_messages(
[
("system", "以下の会話履歴を箇条書きで簡潔に要約してください。単なる繰り返しではなく、話の流れ・論点・意図を短く整理してください。230文字以内を目安にしてください。"),
MessagesPlaceholder("messages"),
]
)
chain = summary_prompt | model | StrOutputParser()
new_summary = chain.invoke({"messages": summary_input})
# stateに保持される、要約とこの時点での要約済みのメッセージ数を更新。
state["summary_text"] = new_summary
state["last_summarized_len"] = last_len + (SUMMARY_TRIGGER - TAIL_KEEP)
return state
LLMを実際に呼び出す関数も、少し手を加えましょう。とは言っても、要約があればシステムプロンプトに足す処理と、残しておきたい最新の会話部分で入力するプロンプトを作る工程を入れているだけです。
以下だと、3メッセージ以前は生のメッセージが残らないことになり、要約が更新される前だと若干過去のメッセージ文がプロンプトに反映されないことになります。
def call_llm(state: GraphState) -> dict:
# 直近までの summary があれば system メッセージとして投入。
prompt_msgs = []
summary = state.get("summary_text")
if summary:
prompt_msgs.append(SystemMessage(content=summary))
# そのまま残しておきたいメッセージをプロンプトに追加。
msgs = state["messages"]
tail_part = msgs[-TAIL_KEEP:]
prompt_msgs.extend(tail_part)
# 以下は変更なし。
prompt = ChatPromptTemplate.from_messages([
("system","あなたはIBM SPSS Modelerの専門家です。簡潔に日本語で回答してください。"),
MessagesPlaceholder("messages"),
])
chain = prompt | model | StrOutputParser()
answer = chain.invoke({"messages": prompt_msgs})
return {"messages": [AIMessage(content=answer)]}
そして上記をsummaryノードとして作成。エッジを設定してllmノード(LLMを呼び出して質問するノード)の前に挿入します。
また、後から識別しやすくするために、run_nameをつけておきましょう。後述しますが、LangSmithのNameに反映されます。
builder = StateGraph(GraphState)
builder.add_node("summary", call_summary)
builder.add_node("llm", call_llm)
builder.add_edge(START, "summary")
builder.add_edge("summary", "llm")
builder.add_edge("llm", END)
memory = InMemorySaver()
graph = builder.compile(checkpointer=memory).with_config(
{"run_name": "count_sum_app"}
)
因みにこのやり方だと、StateにもInMemorySaverにも、すべての会話がそのまま残る形になります。もちろん必要な部分だけ要約・抜粋してLLMに入力しているので、プロンプトの圧縮はされてますが、百ターンとかの会話になってRAMが膨らむのがイヤな場合は RemoveMessage で履歴を削除する仕組みを加える必要があります。
※ここをクリックでcount_sum_app.pyのコード全文表示
import os
import uuid
from dotenv import load_dotenv
from ibm_watsonx_ai.foundation_models.schema import TextChatParameters
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph.message import MessagesState
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_ibm import ChatWatsonx
import gradio as gr
load_dotenv()
project_id = os.getenv("WATSONX_PROJECT_ID")
parameters = TextChatParameters(
max_tokens=2000,
temperature=0.3,
frequency_penalty=0.3,
time_limit=800000,
)
model = ChatWatsonx(
model_id="ibm/granite-3-3-8b-instruct",
project_id=project_id,
params=parameters,
)
class GraphState(MessagesState):
summary_text: str | None = None
last_summarized_len: int = 0
SUMMARY_TRIGGER = 7
TAIL_KEEP = 3
def call_summary(state: GraphState) -> dict:
msgs = state["messages"]
last_len = state.get("last_summarized_len", 0)
if len(msgs) - last_len < SUMMARY_TRIGGER:
return state
old_part = msgs[-SUMMARY_TRIGGER:-TAIL_KEEP]
summary_input = []
if "summary_text" in state:
summary_input.append(SystemMessage(content=state["summary_text"]))
summary_input.extend(old_part)
summary_prompt = ChatPromptTemplate.from_messages(
[
("system", "以下の会話履歴を箇条書きで簡潔に要約してください。単なる繰り返しではなく、話の流れ・論点・意図を短く整理してください。230文字以内を目安にしてください。"),
MessagesPlaceholder("messages"),
]
)
chain = summary_prompt | model | StrOutputParser()
new_summary = chain.invoke({"messages": summary_input})
state["summary_text"] = new_summary
state["last_summarized_len"] = last_len + (SUMMARY_TRIGGER - TAIL_KEEP)
return state
def call_llm(state: GraphState) -> dict:
prompt_msgs = []
summary = state.get("summary_text")
if summary:
prompt_msgs.append(SystemMessage(content=summary))
msgs = state["messages"]
tail_part = msgs[-TAIL_KEEP:]
prompt_msgs.extend(tail_part)
prompt = ChatPromptTemplate.from_messages([
("system","あなたはIBM SPSS Modelerの専門家です。簡潔に日本語で回答してください。"),
MessagesPlaceholder("messages")])
chain = prompt | model | StrOutputParser()
answer = chain.invoke({"messages": prompt_msgs})
return {"messages": [AIMessage(content=answer)]}
builder = StateGraph(GraphState)
builder.add_node("summary", call_summary)
builder.add_node("llm", call_llm)
builder.add_edge(START, "summary")
builder.add_edge("summary", "llm")
builder.add_edge("llm", END)
memory = InMemorySaver()
graph = builder.compile(checkpointer=memory).with_config(
{"run_name": "count_sum_app"}
)
SESSION_ID = str(uuid.uuid4())
def gen_response(message: str):
global SESSION_ID
result = graph.invoke(
{"messages": [HumanMessage(content=message)]},
config={"configurable": {"thread_id": SESSION_ID}},
)
return result["messages"][-1].content
demo = gr.Interface(
fn=gen_response,
inputs=gr.Textbox(lines=2, label="質問を入力してください"),
outputs=gr.Textbox(label="回答", lines=6),
title="SPSS Modeler Q&Aチャットボット",
description="IBM SPSS Modeler に関する質問をどうぞ。日本語で回答します。",
allow_flagging="never",
)
if __name__ == "__main__":
try:
demo.launch()
except KeyboardInterrupt:
print("Stopping Gradio...")
demo.close()
except Exception as e:
print(f"Error: {e}")
demo.close()
1-2.実行結果を確認
さて、早速実行結果のトレースを確認してみましょう。適当に5回くらい会話して、LangSmithのプロジェクトからRunsを見てみましょう。四回会話目の実行結果の summary ノードのトレースを見るとちゃんと要約されているのがわかります。

また、今度はllm ノードの結果を見ると、要約の結果と直近の会話そのままが入力プロンプトとして投入されているのがわかります。

また、5回目は要約が行われておらず、ちゃんと「溜まったら要約」という意図通りの結果が見れます。利用トークン数は後ほど比較を行うのでそこで確認します。
2.会話履歴の「トークン数」を見て要約するか否かを決めるパターン
2-1.LangMemについて
前節では 「会話の往復回数」 を基準に要約するかどうかを判断しました。本節は「履歴全体のトークン数」 を基準にします。トークン数が指定しきい値を超えた場合のみ要約を行い、チャットボットが扱う履歴を自動で圧縮します。
以下の実装ではLangMemを使ってみます。LangMemは、エージェントが会話から学習・適応するためのメモリ管理ツールです。重要情報を抽出し、プロンプト最適化や長期記憶の維持を支援します。どのストレージにも対応するAPIと、LangGraphとのネイティブ統合により、セッションをまたいだ一貫した応答やパーソナライズが可能になります。
以下の解説が分かりやすいです。
これって長期記憶や永続的なプロンプト管理が目的だから、本記事の論旨と関係ないのでは?と思われるかと思いますが、以下の様に長いコンテキストを要約する使い方もできるのです。
LangMemの短期記憶を扱えるAPIは以下にまとめられています。今回の実装では short_term.SummarizationNode をLangGraphに組み込みたいと思います。
2-2.実装例
さて、こちらも基本的には前回作ったチャットボットをベースにしていきます。
langmemをインストールしたら、先ほどのSummarizationNodeを使って実装していくわけですが、このノードを使う場合、実装の返り値例のフォーマットを見ると、"context"というキーを参照して内部状態のやり取りを行っているようです。
一方現状の実装ではGraphStateを楽に実装するためにMessagesStateクラスを使っており、これは"messages"というキーで会話履歴を扱います。ですので以下の様に"context"というキーを設定して、short_term.SummarizationNode のやり取りを授受できる受け皿を作ってあげます。
あと、要約したメッセージを保存しておくリストを、ここで定義しておきます。
※混同するのでファイル名をtoken_sum_app.pyとしておきます。
# 前回インポートしてないやつ。
from typing import Any
from langchain_core.messages import AnyMessage
from langmem.short_term import SummarizationNode
class GraphState(MessagesState):
summarized_messages: list[AnyMessage] # ここに要約が入る
context: dict[str, Any] = {} # SummarizationNode用
SummarizationNodeのドキュメントを見ながら、パラメータを設定していきましょう。これがそのままノードのもとになります。
以下の実装例では、すべての会話履歴のトークン数が320を超えた段階で要約し、LLmが要約してほしい長さ max_summary_tokens が大体256になるように設定。max_tokensもそれに合わせて調整。
またこの実装ではトークンで勘定をしているため、実際の会話履歴(日本語)のトークン数を計算する必要があります。(例えばMaxTokenを超えているかどうかをチェックするときとか)そのためにLancChainの count_tokens_approximately を使ってざっくり計算します。これをtoken_counterに渡します。
あと、普通にこのまま使うと、英語で出てくる&あまり意図しない要約結果が出てきてしまうので、japanese_summary_promptでサマリー用のプロンプトを作成。これをinital_summary_promptにわたすことで、意図したサマリーを生成してもらいます。
このパラメーターのトークン数の調整によって要約が途中で切れたりして、回答制度に影響します。実際に利用するのユースケースで、どれくらいのトークンがかかるのか把握して、パラメーターを決めてください。
下記は1.のパターンと大体同じになるように調整してます。
# サマリーを生成する用のプロンプト
japanese_summary_prompt = ChatPromptTemplate.from_messages([
("system", "以下の会話履歴を箇条書きで簡潔に要約してください。単なる繰り返しではなく、話の流れ・論点・意図を短く整理してください。230文字以内を目安にしてください。"),
MessagesPlaceholder("messages"),
])
summarization_node = SummarizationNode(
model=model.bind(max_tokens=256), # LLMが1回の要約生成で出力できる最大トークン数
token_counter=count_tokens_approximately, # メッセージのトークン数を数える関数
max_tokens_before_summary=500, # 要約を発火させるしきい値
max_tokens=500, # LLMが出力する最大トークン数
max_summary_tokens=256, # SummarizationNodeが要約文に割り当てるトークンの目安
initial_summary_prompt=japanese_summary_prompt # 上記でセットしたサマリー生成プロンプトをセット
)
上記を"summary"ノードとして設定。1.のパターンとおなじようにllmノードの前につなげる。llmの中身であるcall_llmはStateで定義した"summarized_messsages"を挿入。それ以外の実装は変わらずです。
# 入力するプロンプトだけ変える
def call_llm(state: GraphState) -> dict:
prompt = ChatPromptTemplate.from_messages([
("system", "あなたはIBM SPSS Modelerの専門家です。簡潔に日本語で回答してください。"),
MessagesPlaceholder("summarized_messages"), # ←ここにStateで定義したリストを入れる
])
chain = prompt | model | StrOutputParser()
# ここにもStateで定義したリストを入れる↓
answer = chain.invoke({"summarized_messages": state["summarized_messages"]})
return {"messages": [AIMessage(content=answer)]}
# グラフ構築
builder = StateGraph(GraphState)
builder.add_node("summary", summarization_node)
builder.add_node("llm", call_llm)
builder.add_edge(START, "summary")
builder.add_edge("summary", "llm")
builder.add_edge("llm", END)
memory=InMemorySaver()
graph = builder.compile(checkpointer=memory).with_config(
{"run_name": "token_sum_app"} # トークン数で要約してることがわかるように名付け
)
※ここをクリックでtoken_sum_app.pyのコード全文表示
import os, uuid
from dotenv import load_dotenv
from typing import Any
from ibm_watsonx_ai.foundation_models.schema import TextChatParameters
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph.message import MessagesState
from langchain_core.messages import HumanMessage, AIMessage, AnyMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages.utils import count_tokens_approximately
from langchain_ibm import ChatWatsonx
from langmem.short_term import SummarizationNode
import gradio as gr
load_dotenv()
project_id = os.getenv("WATSONX_PROJECT_ID")
parameters = TextChatParameters(
max_tokens=2000, temperature=0.3,
frequency_penalty=0.3, time_limit=600000
)
model = ChatWatsonx(
model_id="ibm/granite-3-3-8b-instruct",
project_id=project_id,
params=parameters,
)
class GraphState(MessagesState):
summarized_messages: list[AnyMessage]
context: dict[str, Any] = {}
japanese_summary_prompt = ChatPromptTemplate.from_messages([
("system", "以下の会話履歴を箇条書きで簡潔に要約してください。単なる繰り返しではなく、話の流れ・論点・意図を短く整理してください。230文字以内を目安にしてください。"),
MessagesPlaceholder("messages"),
])
summarization_node = SummarizationNode(
model=model.bind(max_tokens=256),
token_counter=count_tokens_approximately,
max_tokens_before_summary=500,
max_tokens=500,
max_summary_tokens=256,
initial_summary_prompt=japanese_summary_prompt
)
def call_llm(state: GraphState) -> dict:
prompt = ChatPromptTemplate.from_messages([
("system", "あなたはIBM SPSS Modelerの専門家です。簡潔に日本語で回答してください。"),
MessagesPlaceholder("summarized_messages"),
])
chain = prompt | model | StrOutputParser()
answer = chain.invoke({"summarized_messages": state["summarized_messages"]})
return {"messages": [AIMessage(content=answer)]}
builder = StateGraph(GraphState)
builder.add_node("summary", summarization_node)
builder.add_node("llm", call_llm)
builder.add_edge(START, "summary")
builder.add_edge("summary", "llm")
builder.add_edge("llm", END)
memory=InMemorySaver()
graph = builder.compile(checkpointer=memory).with_config(
{"run_name": "token_sum_app"}
)
SESSION_ID = str(uuid.uuid4())
def gen_response(message: str):
global SESSION_ID
result = graph.invoke(
{"messages": [HumanMessage(content=message)]},
config={"configurable": {"thread_id": SESSION_ID}}
)
return result["messages"][-1].content
demo = gr.Interface(
fn=gen_response,
inputs=gr.Textbox(lines=2, label="質問を入力してください"),
outputs=gr.Textbox(label="回答", lines=6),
title="SPSS Modeler Q&Aチャットボット",
description="IBM SPSS Modeler に関する質問をどうぞ。日本語で回答します。",
allow_flagging="never"
)
if __name__ == "__main__":
try:
demo.launch()
except KeyboardInterrupt:
print("Stopping Gradio...")
demo.close()
except Exception as e:
print(f"Error: {e}")
demo.close()
2-3.実行結果を確認
実行結果のトレースをみてみます。また5回くらい会話して、LangSmithを見ましょう。今度は三回会話目で要約が発動してます。(会話の内容によってタイミングは違ったりします。)
実行結果の summary ノードのトレースを見るとちゃんと要約されているのがわかります。

また、llm ノードの結果を見ると、要約の結果が入力プロンプトとして投入されていますが、一つ前の会話は入力として入っていません。(実際のチャットでは前回の会話内容を正確に記憶していたため、LangSmith側の表示上の問題かもしれません)

この様に要約の長さや内容に含む事柄は、トークン数の調整や要約生成用のプロンプトによって調整が必要です。これが割と難しい…。良い使い方を知っている人がいたら教えてほしいです。
◾️それぞれの会話履歴要約パターンを比較してみる
上記2パターンに加えて、前回試した会話の前履歴を投入するパターンを試して、LangSmithで要約内容を確認してみたいと思います。今回は比較をするため会話の流れは全パターン以下の流れ(10回分の会話往復)を試します。
- SPSSModelerの具体的な使い方を聞く
- モデルの構築について詳しく聞く
- SPSSModelerで使えるモデルを聞く
- 初心者でも使いやすいモデルを聞く
- モデルを1つ指定して具体例を交えて使い方を聞く
- 5でどんな示唆を得ることができるか聞く
- 5のモデルに関連して次に試すべきモデルについて聞く
- 7のモデルについて具体例を交えて使い方を聞く
- 8でどんな示唆を得ることができるか聞く
- 最後に今までの会話の流れを箇条書きで書いてもらう
その後、 使ったトークン数とレイテンシ、そして簡単に最後の要約内容を比較したいともいます。
LangSmithで見れる、使ったトークン数とレイテンシは、以下画像の様にLangGraphの実行ごとに確認できます。実装時に .with_config で "run_name" に名前を付けているので、 Nameカラムに反映されており、どのパターンかがすぐ判別できますね。
All Runsというタブから、もっと細かくRun毎に確認することもできます。

消費トークンを比較
さてかかったトークンを比べてみると合計で以下の様になり、要約した方がトータルのトークン節約になることがよくわかります。
- 前回作った全履歴投入 :30,651トークン
- 会話「回数」で要約する :29,574トークン
- 会話「トークン数」で要約する :18,068トークン
もう少し詳しく会話回数毎、要約に使ったトークン、llmによる回答生成に使ったトークンに分けて表にしてみました。
以下を見る限り、llmによる回答生成に使ったトークン(:llm列)を比べると、要約を実施すれば会話回数の増加に伴って入力プロンプトが増加していくのを避けられるため、長いスパンでの会話も耐えられそうですね!
あと面白いのは要約(:summary列)をするタイミングや消費トークンが違うという事です。当然ですが「回数で要約」の場合、定間隔で要約が発生するのに対して、「トークン数で要約」の場合はタイミングはまちまちという事です。ここはおそらくパラメータの設定如何によって結構変わるところだと思うので、試行錯誤を重ねる必要がありそうですね。
| 会話回数 | 全投入:llm | 回数要約:llm | 回数要約:summary | トークン要約:llm | トークン要約:summary |
|---|---|---|---|---|---|
| 1 | 475 | 594 | 0 | 575 | 0 |
| 2 | 997 | 1,098 | 0 | 1,213 | 0 |
| 3 | 1,470 | 1,117 | 0 | 1,965 | 0 |
| 4 | 1,834 | 2,012 | 1,516 | 760 | 1,721 |
| 5 | 2,504 | 2,217 | 0 | 1,426 | 0 |
| 6 | 3,113 | 2,498 | 2,674 | 2,084 | 0 |
| 7 | 3,913 | 2,689 | 0 | 1,126 | 1,251 |
| 8 | 4,803 | 2,657 | 3,337 | 2,112 | 0 |
| 9 | 5,513 | 2,690 | 0 | 826 | 1,580 |
| 10 | 6,029 | 1,647 | 2,828 | 1,429 | 0 |
| 合計 | 30,651 | 19,219 | 10,355 | 13,516 | 4,552 |
グラフで見ると、以下のような感じ。
縦軸:トークン数、横軸:会話回数
網掛け:要約summary、そのまま:回答生成llm
色分け:全会話履歴投入、回数要約、トークン数要約

レイテンシを比較
要約している二つは、要約の分が乗っているため増加しており、後半は10sを超えてます。
トークン数要約の方は安定しており、比較的10s以内もしくは同じくらいに抑えられている。チャットとしてのUXを考えるとトークン数要約が妥当かなーという印象でした。
10sを超えると結構AIの返信が遅いかな…と感じることが多かったので、要約のノード(summary)の実行はLLMとは別で行うか、並列で走らせるとか工夫が必要ですね。
あと、この会話回数、内容だと、全会話履歴投入しても回答が早いので、用途によっては全投入もありかもしれないです。
| 会話回数 | 全投入 | 回数要約 | トークン要約 |
|---|---|---|---|
| 1 | 4.61 s | 5.50 s | 6.69 s |
| 2 | 6.22 s | 4.66 s | 7.74 s |
| 3 | 7.52 s | 5.50 s | 7.44 s |
| 4 | 3.45 s | 15.46 s | 9.52 s |
| 5 | 5.78 s | 8.02 s | 7.47 s |
| 6 | 6.85 s | 18.73 s | 8.09 s |
| 7 | 4.53 s | 11.01 s | 14.46 s |
| 8 | 5.33 s | 16.62 s | 9.87 s |
| 9 | 6.78 s | 10.81 s | 8.72 s |
| 10 | 5.99 s | 6.24 s | 6.28 s |
グラフも

要約内容を比較
それぞれ会話の最後に今までの全ての会話の流れを要約させるプロンプトを投げました(10回目のメッセージ)。これを見る事でそれまでの会話の流れを捉えられているのか否かを確認できるはずです。
以下の出力結果は、基盤モデル「Granite」の出力をそのまま載せているので、一部ハルシネーションを含んでいます。SPSSModelerの正しい情報ではありません。
-
全会話履歴投入
以下が結果なのですが、全会話履歴投入すると、概要の確認から分類モデル、回帰モデルの追加等、一通り会話した内容が要約されています。ただ、会話の流れ通り時系列順に並んでいるわけではないので、ここは投げるプロンプトを工夫する必要がありそうです。
1. IBM SPSS Modelerの概要
- データマイニング、テキスト分析、統計分析に使用されるツール
- ノードベースのビジュアルインターフェース
2. K-Means Clusteringの使い方
- データの準備とインポート
- データの前処理(選択、変換、カテゴリ化など)
- K-Means Clusteringノードの設定と実行
- クラスタの評価と解釈
3. ロジスティック回帰の使い方
- データの準備とインポート
- データの前処理(選択、変換、カテゴリ化など)
- ロジスティック回帰ノードの設定と実行
- モデルの評価と解釈
4. 他の回帰分析の紹介
- 線形回帰、ロバスト回帰、ローリング平均回帰、モニタリング回帰、LOESS/LOWESS、SVM回帰など
5. SPSS Modelerの柔軟性
- さまざまなモデルやノードのカスタマイズ可能性
- 大規模データセットへの対応
-
会話回数で要約
会話後半の内容は捉えられているのですが、SPSSModeler自体の概要など前半の部分の流れについて記載がないです。何回か試しましたが、要約の要約をしているので直近の会話内容が優先される傾向があるようです。
- K-meansクラスタリングと線形回帰を組み合わせたアプローチは、顧客セグメンテーションとターゲティング戦略のための有益な洞察を提供します。
- 線形回帰以外にも、SPSS Modelerで利用可能な代替回帰モデル:
- ロジスティック回帰(二値結果)
- 多項ロジスティック回帰(複数のカテゴリ)
- ポアソン回帰(頻度データ)
- ネガティブ・バインド・ポアソン回帰(0発生が多いデータ)
- 一般化線形モデル(GLM)
- ロジスティック回帰と決定木を組み合わせたランダムフォレスト回帰
- サポートベクターリグレッション(SVR)
- ニューラルネットワーク
- これらのモデルは、K-meansクラスタリングの結果に基づいて、平均年間支出や購入行動などの顧客セグメントごとの特性を予測するために使用できます。
- 適切なモデルとハイパーパラメーターを選択し、`Score`ノードを使用して新しいデータ上でモデルの性能を評価します。
- この分析により、ビジネスはマーケティングキャンペーン、製品開発、サービス改善をカスタマイズでき、顧客満足度、売上高、競争優位性を向上させることができます。
-
会話トークン数で要約
回数要約 と同じく前半部分の会話内容が抜け落ちているのと、会話した内容以外のことが入っています。これは要約のさせ方と出力のさせ方かなーという感じです。
また要約生成のプロンプトに全ての履歴内容を踏まえさせる事と、回答生成用のシステムプロンプトに会話した内容以外のことには触れない事を入れる事で改善できる?と思いながら途中であきらめました笑。何か良い方法あったら教えてください。
あと今回使ったLLMはGraniteだけでしたが、モデルの性能、性質にもよると思います。別の機会で他のモデルを試してみたいと思います。
以下は、IBM SPSS Modelerで利用可能な主なモデルタイプの要点です。
1. **分類モデル**
- 顧客の行動(購入やサービス利用)を予測
- アルゴリズム:ロジスティック回帰、決定木、ナイーブベイズ、サポートベクターマシン(SVM)
- 顧客のチャーンル予測
- クロスセリングとアップセリングの機会の特定
2. **分散モデル**
- データポイント間の関係を分析
- アルゴリズム:線形回帰、多項式回帰、ロジスティック回帰
- 変数間の相関関係を理解
3. **クラスタリングモデル**
- データポイントを類似性に基づいてグループ化
- アルゴリズム:K-メANS、階層的クラスタリング
- 顧客セグメンテーションや市場調査
4. **関連性モデル**
- データセット内の変数間の関連性を特定
- アルゴリズム:相関分析、相互情報量(MI)
- 特徴選択や変数削減
5. **予測モデル**
- 時系列データに基づいて将来の値を予測
- アルゴリズム:ARIMA、指数滑らか化(ETS)
- 需要予測や在庫管理
6. **ネットワーク分析**
- データポイント間の関係を視覚化および分析
- アルゴリズム:中心性測定、コミュニティ検出
- 社会ネットワーク分析やサプライチェーン最適化
7. **テキスト分析**
- テキストデータから意味を抽出および分析する方法を提供します。アルゴリズムには感情分析、トピックモデリングが含まれます。これにより、顧客フィードバックやソーシャルメディア投稿から洞察を得ることができます。
◾️反省点、次やりたいこと。
今回の焦点は、会話履歴の要約でしたが、要約して会話履歴を圧縮するタイミング、どう要約するかについては、調整が難しく今後の課題になりました。具体的な問題としては…
- どの程度会話がたまったら要約をするのか(トークン数、会話数どちらでカウントするにしても)
- 要約のまとめ方(例えば時系列順なのか、ユーザーの関心だけを抽出するのか)
- レイテンシの問題(要約を並列で実行できないか)
等が挙げられるほか、当記事では試していないですが、要約用と回答生成用で、使用する基盤モデルを変更するのも試してみたいと思います。(例えば要約はGranite、回答生成はllamaとか)
長くなりすぎたので、会話の要約についてはここまでにします…
次にやりたい事としては、RAGで外部情報を取り込んだり、MCPでWebツールを使って最新の情報を取り込んだりしていきたいと思います。現状は結構ハルシネーションしているので…
◾️まとめ
当記事では「LangSmithでのLLM実行結果のトレース」と「チャットボットの会話履歴をどう要約して管理するか」について扱いました。パラメーターの調整等、要約に関する設定は実際に使ってみてトレース結果を確認して、調整する必要があり、とても時間がかかりました。
そのうえでLangSmithは非常に役立ったわけですが、その前にwatsonx.aiのPrompt Labなどである程度プロンプトや消費トークンに当たりをつけてから実装に移すのも良いかなーと思いました。
私はエンジニアではないので、当記事では簡単な実験にとどめますが、開発のノウハウについてはまなんでいく必要があるなーと感じました。
あとIBM Granite3ですが、学習量の割に日本語もスムーズですし賢い…私よりも笑。そして安いからいっぱい試せる…
◾️参考