SharePoint ライブラリに置いてあるExcelのテーブルをPower Appsで使いたい!
残念ながらPower Appsでそれは出来ません。
何故なら、Excelテーブル読み出しがSharePoint ライブラリに対応していないからです。
(2019/12/12現在)
Excel は接続のようなものです。 アプリで Excel データを表示するには:
- Excel データをテーブルとして書式設定します。
- Excel ファイルをクラウド ストレージ アカウント (Box、Dropbox、Google Drive、OneDrive、OneDrive for Business など) に保存します。
- クラウド ストレージ アカウントに接続し、データ ソースとして Excel テーブルを追加します。
- アプリを自動的に生成するか、またはギャラリー コントロールのようなものを追加して構成することで、この情報を表示します。
これに限らず、Power Automate経由でテーブルをPower Appsに渡せたら便利な場面は沢山あります。
どうやれば出来るのでしょうか?
前置き
この記事はPower Automate側からPower Appsへ配列が渡された後の話です。
前段階のPower Automateで配列を作る話は後日何か書きます。
結論
結論を先に言うと、有料プレミアムコネクタ「要求」の「応答」アクションを使えば、配列を応答の本文に突っ込むだけで終わります。
Return an Array from Flow to PowerApps (Response Method)
しかし、今回は標準コネクタでお金をかけずにやるお話。
有料で出来ることを無料の範囲でやろうとすると、それなりに面倒かつ手間という記事です。
Power AutomateからPower Appsへ渡せるデータ
Power Appsで呼び出したPower Automateのフローからは、アクションPowerApps または Flow に応答するでPower Appsへ応答を返すことが出来ます。
キャンバス アプリでフローを開始する
返せる応答は以下の通りです。
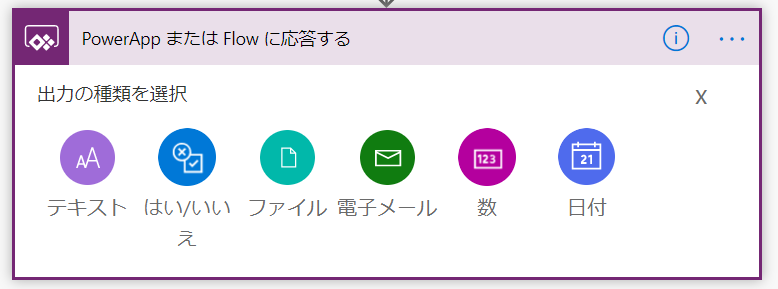
| 表示名 | データ型 | スキーマ |
|---|---|---|
| テキスト | string | Object |
| はい/いいえ | boolean | Object |
| ファイル | string | Object |
| 電子メール | string | Object |
| 数 | number | Object |
| 日付 | string | Object |
私の知る範囲では、これらをPower Appsは全て文字列として受け取ります。
アクションPowerApps または Flow に応答するの弱点
文字列を受け取ったPower Appsは、データ型を自動的にテキスト型として定義します。
Power Appsはコレクションを除いて事前に受け取るデータ型を定義できません。
そして関数でラッピングしない限り、後からデータ型を変更する事もできません。
ラッピングできる関数が存在しない配列はテキスト型のままであり、Power Appsはテーブルとして認識しません。
つまり**PowerApps または Flow に応答するではテーブルを渡せません。**
因みにプレミアムコネクタの「応答」は配列をObjectではなくArrayとして渡せるので、Power Appsは自動でテーブルとして定義します。
Power Appsで文字列として渡された配列をテーブルに変換する
では、どうやってテーブルに変換するのか。
文字列からテーブルを生み出せるSplit 関数を使います。
Power AutomateからPower Appsへ、このテーブルを配列で渡して試してみましょう。
| Column名1 | Column名2 | Column名3 |
|---|---|---|
| 値1 | 値2 | 値3 |
| 値1 | 値2 | 値3 |
前処理
渡された配列をPower Appsで見るとはこんな感じです。
[
{"Column名1":"値1","Column名2":"値2","Column名3":"値3"},
{"Column名1":"値1","Column名2":"値2","Column名3":"値3"},
{"Column名1":"","Column名2":"","Column名3":""}
]
見やすいように改行していますが、文字列なので実際は一行です。
しかもレコードの数だけ長くなります。
[{"Column名1":"値1","Column名2":"値2","Column名3":"値3"},{"Column名1":"値1","Column名2":"値2","Column名3":"値3"},{"Column名1":"","Column名2":"","Column名3":""},...*n]
ここからSplit 関数で1レコード1行になるように整形します。
整形
1レコード1行にするには、レコードの境である"},でSplitすればいいのですが、その前に"},以外をPower Appsで安全に読み込める形式に変える必要があります。
注意すべき点は以下の通りです。
| 問題 | 解決策 |
|---|---|
| 全角の(など、コレクションのColumn名で使えない文字がある | Column名を'で囲んでエスケープする |
値が全て"で囲われている |
Power Apps側でデータ型の自動判別をさせる為、全ての"を消す |
これらの点をSubstitute 関数を使って処理していきます。
Substitute(
Substitute(
Substitute(
Mid(
PowerAutomateからの応答,///ここで先頭の[と末尾の}]を消去
2,
Len(PowerAutomateからの応答) - 4
),
"{""",///先頭のColumn名を安全に読み込むため{を'に置き換え
"'"
),
""":""",///Column名を安全に読み込むため":"を':に置き換え
"':"
),
""",""",///二つ名以降のColumn名を安全に読み込むため","を,'に置き換え
",'"
)
この処理を行うと、データは以下のように整形されます。
'Column名1':値1,'Column名2':値2,'Column名3':値3"},
'Column名1':値1,'Column名2':値2,'Column名3':値3"},
'Column名1':,'Column名2':,'Column名3':
Split関数でテーブル化
整形済データをSplitでレコードごとの塊にしてテーブル化します。
Split(整形済データ,"""},")
すると以下のようなテーブルになりました。
Resultにレコードがテキスト型でネストされています。
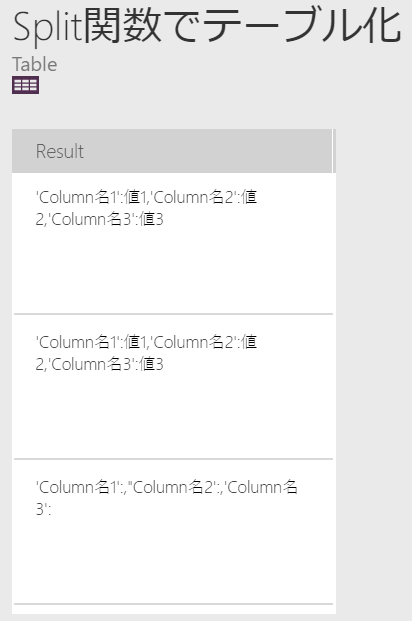
| Result |
|---|
| 'Column名1':値1,'Column名2':値2,'Column名3':値3 |
| 'Column名1':値1,'Column名2':値2,'Column名3':値3 |
| 'Column名1':,'Column名2':,'Column名3': |
ここから元のレコードに変換します。
前処理したテーブルから元のレコードを復元する
ここからが一番面倒です。
まずForAll 関数を使ってネストされたレコードをフィールドに展開します。
そしてCollectで一行ずつCollectionに格納して元のテーブルを復元します。
処理コードはこんな感じ。
ForAll(
Split関数でテーブル化,
Collect(
復元したテーブルCollection,
{
'Column名1':Last(Split(Last(FirstN(Split(Result,","),1)).Result,":")).Result,
'Column名2':Last(Split(Last(FirstN(Split(Result,","),2)).Result,":")).Result,
'Column名3':Last(Split(Last(FirstN(Split(Result,","),3)).Result,":")).Result,
}
)
)
Collect 関数で何をやっているか
Collect内でSplit関数でテーブル化のResultに格納されたレコードをフィールドとして展開し、順番に復元したテーブルCollectionに格納しています。
ネストされたレコードをテーブルにする
テーブルを復元するためにはネストされたレコードのテキストを、個別のフィールドを特定できる形に変える必要があります。
処理するレコードは以下のような形です。
| Result |
|---|
| 'Column名1':値1,'Column名2':値2,'Column名3':値3 |
Resultにはテキストでレコードが格納されているので、これをSplit(Result,",")で以下のようなテーブルに変換します。
| Result |
|---|
| 'Column名1':値1 |
| 'Column名2':値2 |
| 'Column名3':値3 |
Split(Result,",")
ForAllの第一引数がSplit関数でテーブル化なので、Collectの数式内でSplit関数でテーブル化.Resultを呼び出せます。
テキストからフィールドの値だけを取り出す
次にフィールドを復元し、レコードに格納します。
【#PowerApps Tip's】配列のn番目を取得するを参考にフィールドごとにSplitしたテーブルから一つずつフィールドを呼び出します。
Last(FirstN(フィールドごとにSplitしたテーブル,1))
FirstN 関数の第二引数を変えることで、呼び出すフィールドを変えられます。
今回は一行目の処理なので第二引数は1です。
呼び出したフィールドの戻り値は以下のような形です。
| Result |
|---|
| 'Column名1':値1 |
次にフィールドの値だけを取り出すため、呼び出したフィールド.Resultを:でSplitします。
| Result |
|---|
| 'Column名1' |
| 値1 |
そして最後にLast 関数を使えばフィールドの値だけを取り出せます。
Last(Split(呼び出したフィールド.Result,":"))
これでフィールドの値値1が取り出せました。
各関数の挙動はこんな感じ。
Last(
Split(
Last(
FirstN(
Split(
Result,///ネストされたレコードをテーブルにする
","
),
1///取り出すフィールドを数値で指定するLastとFirstNの合わせ技
)
).Result,
":"///フィールド名と値にSplitし、Lastで値だけ取り出す
)
).Result
テーブルに登録するレコードを作成する
Power Appsでは{Column名:値}と記述する事でレコードを作れますが、注意すべき点があります。
Collectionやテーブル、レコードのColumn名に数式を使う事はできません。
つまりColumn名を動的に変更できないため、必ずアプリにハードコーディングする必要があります。
幸い値は数式を使えるので、先ほどの取り出した値と合わせてレコードを作っていきます。
取り出した値の戻り値はResultにフィールドの値が格納されています。
| Result |
|---|
| 値1 |
なので{'Column名1':取り出した値.Result}と記述してフィールドColumn名1を復元します。
フィールドの数だけ同じ手順を繰り返す
次に同じ手順を繰り返し、Column名とテキストからフィールドの値だけを取り出すのFirstN第二引数を変えて全てのフィールドを復元します。
{
'Column名1':Last(Split(Last(FirstN(Split(Result,","),1)).Result,":")).Result,
'Column名2':Last(Split(Last(FirstN(Split(Result,","),2)).Result,":")).Result,
'Column名3':Last(Split(Last(FirstN(Split(Result,","),3)).Result,":")).Result
}
これでPower Automateから渡された配列をテーブルにすることが出来ました。
| Column名1 | Column名2 | Column名3 |
|---|---|---|
| 値1 | 値2 | 値3 |
最後に復元したテーブルCollectionにCollectして終わりです。
これがForAllで繰り返され、テーブルが復元されます。
| Column名1 | Column名2 | Column名3 |
|---|---|---|
| 値1 | 値2 | 値3 |
| 値1 | 値2 | 値3 |
おまけ:インデックスを追加する
Collectするレコードにインデックス:CountRows(復元したテーブルCollection)を加えると連番のインデックス列が生成されます。
| インデックス | Column名1 | Column名2 | Column名3 |
|---|---|---|---|
| 0 | 値1 | 値2 | 値3 |
| 1 | 値1 | 値2 | 値3 |
| 2 |
これはCollectで1レコードずつCollectionに追加しているため、CollectionをCountRowsすると何行目を追加しているか分かるのを利用しています。
インデックス込みの構文はこんな感じ。
ForAll(
Split関数でテーブル化,
Collect(
復元したテーブルCollection,
{
インデックス:CountRows(復元したテーブルCollection),
'Column名1':Last(Split(Last(FirstN(Split(Result,","),1)).Result,":")).Result,
'Column名2':Last(Split(Last(FirstN(Split(Result,","),2)).Result,":")).Result,
'Column名3':Last(Split(Last(FirstN(Split(Result,","),3)).Result,":")).Result
}
)
)
まとめ
-
非常に面倒
- 大事なことなので
-
テキストはSplit 関数でテーブルにできる
- 覚えておくと便利に使えます
-
「自分のしたい事を実現するにはどういうデータが必要か」を意識しよう
- データの整形は大事
-
Power Appsの仕様を理解しよう
- 「Power Appsが出来る事・出来ない事」を知っていれば結構抜け道が見つかります
なお今回紹介した方法のパフォーマンスですが、以下の条件で概ね20秒から30秒で取り込めました。
- データソースのテーブル
- 300行
- 39列
- アプリを実行したPC
- Core i5
- メモリ8G
素直にプレミアムコネクタを使おう
冒頭でも書きましたが、プレミアムコネクタならここに書いた手順は全て不要です。
お金で、しかも少額で解決できることはなるべくお金で解決しましょう。
月額¥1,637のPower Automate ユーザーごとのプランがお手軽です。
備忘
最後に自分用も兼ねて今回の構文を全体を置いておきます。
以下を参考に設定を書き換えればすぐに使えるはず。
-
PowerAutomateからの応答をPower Automateから渡された配列を格納した変数に置き換え -
復元したテーブルCollectionをお好きな名前に変更 - Column名を元のテーブルと同じ名前に手打ち
Clear(復元したテーブルCollection);
ForAll(
Split(
Substitute(
Substitute(
Substitute(
Mid(
PowerAutomateからの応答,
2,
Len(PowerAutomateからの応答) - 4
),
"{""",
"'"
),
""":""",
"':"
),
""",""",
",'"
),
"""},"
),
Collect(
復元したテーブルCollection,
{
インデックス: CountRows(復元したテーブルCollection),
'Column名1':Last(Split(Last(FirstN(Split(Result,","),1)).Result,":")).Result,
'Column名2':Last(Split(Last(FirstN(Split(Result,","),2)).Result,":")).Result,
'Column名3':Last(Split(Last(FirstN(Split(Result,","),3)).Result,":")).Result
}
)
)