(2019/6/12追記)
現在は以下のスライドのほうが情報が新しいです。本記事は残しておきますが、新しい情報はこちらをご参照ください。
https://www.slideshare.net/ygotokernel/nvdimmlinux-137104084
はじめに
この記事はFujitsu Advent Calender 2017 Part2 4日目の記事ですが、公開は24日です。最初は全部24日の記事にまとめるつもりだったのですが、量が多いので分割して急遽こちらにpart2を登録することにしました。
こちらは、NVDIMMの仕様の補足、2017年のNVDIMMのACPIの仕様の更新や、Linuxコミュニティでの動向など、残りの雑多な話を記載します。
お断り(お約束)
本記事の内容は私個人の見解であり、所属する組織として意見を代表したり保証したりするものではありません。
内容については誤りを含む可能性もありますのでご注意ください。(誤りについてご指摘していただけると助かります。)
仕様についての補足
regionとnamespace
プラットフォームがNVDIMMを正式にサポートする場合、エミュレーションで使ったようなe820のメモリマップだけでなくregionというまとまりの情報をファームからOSに伝える必要があります。これについては、まずはkernelのソースのドキュメントから図を引用してみましょう。
$ less Documentation/nvdimm/nvdimm.txt
:
:
Example NVDIMM Platform
-----------------------
For the remainder of this document the following diagram will be
referenced for any example sysfs layouts.
(a) (b) DIMM BLK-REGION
+-------------------+--------+--------+--------+
+------+ | pm0.0 | blk2.0 | pm1.0 | blk2.1 | 0 region2
| imc0 +--+- - - region0- - - +--------+ +--------+
+--+---+ | pm0.0 | blk3.0 | pm1.0 | blk3.1 | 1 region3
| +-------------------+--------v v--------+
+--+---+ | |
| cpu0 | region1
+--+---+ | |
| +----------------------------^ ^--------+
+--+---+ | blk4.0 | pm1.0 | blk4.0 | 2 region4
| imc1 +--+----------------------------| +--------+
+------+ | blk5.0 | pm1.0 | blk5.0 | 3 region5
+----------------------------+--------+--------+
:
:
難しく見える図ですが、この例は以下を示しています。
- cpu0に対して2つのmemory controller(imc0, imc1)が接続されており、それぞれにNVDIMMが2つずつ接続されている構成を例としている
- NVDIMMはその中の領域をregionとして分割して利用することができる。
- RAMと同じようにNVDIMMもInterleaveすることができる。図では、NVDIMMの0,1をInterleaveしているregion0, 0,1,2,3すべてをInterleaveするregion1が定義されている。
- Interleaveしている領域はpersistent memoryとしてのnamespace(pm0.0, pm1.0)が割り当てられている。
- 残りの領域をblock namespaceとして割り当てられている。
このような領域を適切に表現するには、e820のメモリマップだけでは不可能です。ファームウェアはACPIのNFITテーブルで、これらの情報を伝えることになります。
NFITのエミュレーション
不揮発メモリを持たないプラットフォーム上ではNFITテーブルの実装がありませんから、筆者はなかなかどんなものかイメージがつかめなかったのですが、ndctlコマンドのunitテストのために作られている、NFITをエミュレーションしてくれるカーネルモジュールnfit_test.koを使うことで大分見えてくるようになりました。
nfit_test.koを利用するには、通常のkernelのbuildのほか、kernel source中のtools/testing/nvdimm/ のソースを別途コンパイルする必要があります。kernelのbuildの知識が必要なのでここには書きませんが、方法はndctlのページのunit testの項に記載されているので、挑戦してみるのも面白いでしょう。
なお、筆者の感覚的なものですが、このnfit_test.koは非常によくできたテストモジュールです。ndctlコマンドのテストのためとはいえ、下手なプラットフォームのファームウェアよりもnfit_test.koのほうが、NFITの仕様を網羅的に抑えているのではないかと推測しています。
2017年の動向
ACPIの仕様の更新
ACPIの仕様がver6.2以降になって、NVDIMM関連の仕様が大きく更新されています。
最も重要なのは、多くの仕様がACPIの__標準として策定された__ことにあるでしょう。特に、NVDIMM deviceに対する_DSMメソッドについては、昨年はIntelのほかHPEやMSKKなどからExampleとして仕様が提案された形でしたが、多くの仕様がACPI6.2のspecに取り込まれたほか、残りについてもver1.6として仕様がupdateされ、Exampleではなく正式な仕様となっています。
また、そのほかにも重要な仕様の追加があります。
新仕様 Heterogeneous Memory Attribute Table (HMAT)
従来のACPI仕様では、CPUとMemory間のアクセス速度は相対的な値しか表現できませんでした。 System Locality Distance Information Table (SLIT)と呼ばれるもので、これはCPUから最も近いnodeへのアクセス速度に対して、他のnodeへのアクセス速度はその何倍になるか(1.5倍など)を表現するものです。
この値はkernelが使って物理メモリの割り当てのための情報として使ったり、numactlコマンドで値を取得してソフトを最適化するときに使われていました。しかし、非常に大雑把な値ですから、実際にどれくらいの性能値になるのかは分かりませんでした。
これに対して、ACPI6.2 では、HMATによってlatencyやbandwidthも表現できるようになりました。今後はSLITよりもHMATの情報を優先することになるようです。
また、Memory Side Cacheという概念も同時に公開されています。これは、ACPIの仕様書から図を引用したほうが良いでしょう。
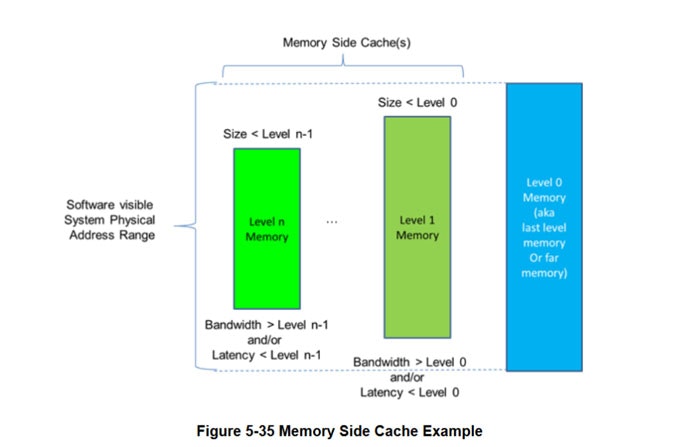
実際のメモリアドレス(System Physical Address)に対して、速度の速いメモリが遅いメモリのキャッシュ、すなわちMemory Side Cacheとして働くことを示しています。そして、この図の次には以下のように記載されています。
If Non-Volatile memory is cached by memory side cache, then platform is responsible for persisting the modified contents of the memory side cache corresponding to the Non-Volatile memory area on power failure, system crash or other faults.
つまり、Level 0のMemoryがNVDIMMの領域であるとき、Level nのMemory Side Cacheの内容は、突然の電源断などの時でもプラットフォーム側でデータを確実に更新する必要があるわけです。
ちなみに、IntelはこのHMATの仕様についてはかなり気合を入れており、ACPI6.2の仕様公開とほぼ同時にコミュニティに初版パッチを投稿しています。これは、仕様公開前から耽々と準備してきたに違いありません。
このパッチは諸事情でまだ開発中の状態ですが、いずれHMATの情報はsysfsを経由してユーザープロセスから参照できるようになる模様です。
LinuxのNVDIMMコミュニティ動向
さて、最後にLinuxコミュニティの現在の動向について述べます。
kernel/driver
使い方でも示した通り、Filesystem DAXは、まだExperimental、つまりまだ開発中の未完成の機能とされていて、mountするとsyslogに警告が表示されます。
Dec 23 12:29:20 localhost kernel: XFS (pmem0p1): DAX enabled. Warning: EXPERIMENTAL, use at your own risk
理由の一つとして、既存のFilesystemのInterfaceとFilesyste DAXの仕組みの間で、APIの整合性が取れないことが上がっているようです。
meta dataの更新
Filesystem DAXでは、NVDIMM上のファイルのデータをmmap()でマッピングし、データを更新してcpuのキャッシュをflushしたら、それでもうデータがNVDIMMに反映が終わるというのが理想です。
しかし、問題はその時の当該ファイルのmeta dataについてです。データの更新時にはこれまでmsync()のようなシステムコールを呼び出していたため、kernel側がそのタイミングでmeta dataを更新することができました。しかし、上記のようなルートでは、kernelが__meta dataを更新するべきかどうか__を判断するチャンスがありません。そうすると、truncate()を呼び出したときなどにmetadataの一貫性を保証することができず、問題が生じることになります。
このため、今のところはFilesystem DAXを使うときは、アプリケーション側でcpu cache flushをするのではなく、msync()などのシステムコールを呼び出す必要があります。
ただ、さすがにこれだとsystem callを呼ぶ時間などで遅くなりそうですし、せっかくのNVDIMMの特徴を生かしたアクセス方法とは言えません。このため、コミュニティでは以下のアプローチが試みられています。いずれの方法も新規のフラグを追加しています。
- 強制sync
mmap()にMAP_SYNCフラグを指定すると、カーネルは基本的に全pageを書き込み禁止にして、データ更新時には強制的にpage faultを発生させ、その時にmeta dataの更新を行う方法のようです。Jan Karaによって開発され、まもなく取り込まれそうな見込みです。
また、新しいフラグが適切に設定されているかどうかをmmap()システムコールが確認できるようにするために、MAP_SHARED_VALIDATEという指定ができるようにもなっています。 - metadata更新を拒否
mmap()にMAP_DIRECTフラグを指定することで、metadataの更新する操作を拒否する方法のようです。NVDIMMのメンテナであるDan Williamsによって開発されています。ただ、コーナーケースが多い方法でもあり、上記と比べるとやや開発は難航しているようにも見えます。
この問題ように、Filesystem DAXには、まだ解決が必要な問題がいくつかある模様です。筆者もまだ勉強中なので全容はわかりませんが、Experimentalが外れるにはもう少しかかりそうですね。
ライブラリ
まず、名前についてです。
これは今月の話なのですが、NVDIMMを使うためのライブラリ群であるNVMLがPMDK(Persistent Memory Development Kit)と名前を変えました。もちろんこれはDPDKやSPDKを意識した名前です。変更した理由としては、NVMLという名前からは一つのライブラリという印象を持たれがちですが、実際にはすでに様々な種類のライブラリを提供しているためとしています。(しかし、本当にそれだけか?という気がしなくもありません…。)。なお、方向性や内容はNVMLから特に変わらないとのことです。
また、このPMDKはいくつかのデータ構造向けの機能や、低レイヤとしての非常に多くの新規APIがあり、使いこなすためにはかなり勉強する必要があります。このため、使い方に関してチュートリアルが作成されています。私もまだ試していないのですが、これを研究してみるのもおもしろいかもしれません。
まとめと今後
NVDIMMの仕様や動向について、私のわかる範囲でまとめてみました。(正直、もう少し絵を追加してわかりやすくしたほうが良いかとも思うのですが、力が付きました。)
しかし、徐々にカーネルやライブラリの方向性も見えてきており、そろそろアプリやミドルウェアでのNVDIMMの使い方を考えるのも面白いと思います。
ではでは。