はじめに
以前SMARTのSelf-Testでservo/seek failureメッセージを出していたHDDを交換した記事を書きました。
今回はとくに異常はレポートされていないのですが、おそらく同時期に購入した他のHDDで、明確に異常はなかったのですが予防的に交換した時の手順をまとめておきました。
問題のありそうなHDDの状態
そもそも製造から10年以上が経過している時点で問題があるのですが、一応24時間稼動が前提のHDDなので壊れるまで使おうとK8sのノードに転用したのでした。
問題がありそうだと気がついたのは、別の理由でHDDを交換した際に、健全な別ノードで実行したhdparmの出力を確認した時でした。
$ sudo hdparm -Tt /dev/sdb
/dev/sdb:
Timing cached reads: 22522 MB in 1.99 seconds = 11316.31 MB/sec
Timing buffered disk reads: 236 MB in 3.00 seconds = 78.63 MB/sec
古い低回転のNAS用HDDとはいえ製品のスペック上は、180MB/sec程度の転送速度があるはずです。
裏では重いRook/CephのPGsのremap処理が発生したので、パフォーマンスに影響があるかなと思ったのですが、同じクラスターの別のノードを確認すると次のようになっていて、先ほどのHDDは明らかにパフォーマンスが悪化しているようでした。
/dev/sdb:
Timing cached reads: 25382 MB in 1.99 seconds = 12762.24 MB/sec
Timing buffered disk reads: 502 MB in 3.01 seconds = 166.60 MB/sec
Cephの状態はあまり関係なさそうなので、Remap処理が終ってからパフォーマンスの低かったHDDで再度ベンチマークを取得すると、やはりパフォーマンスは改善していませんでした。
/dev/sdb:
Timing cached reads: 25232 MB in 1.99 seconds = 12686.92 MB/sec
Timing buffered disk reads: 242 MB in 3.03 seconds = 79.78 MB/sec
作業の前にSMARTのSelf-Testを実行して問題は報告されていなかったのですが、他のノードでも似たような状態のHDDを使用していたので、同時にクラッシュすることを怖れて早めに交換することにしました。
他のノードで発生していた別の状況
他のノードのHDDも交換の準備を進めていますが、対象は2TBのExos 7E2で、RMAサイトで確認すると先々月の2025年9月18日に保証期限が切れています。
SMARTの出力では経年劣化の兆候以外は問題なく、hdparmのベンチマーク結果も150MB/sec以上の数値で良好です。
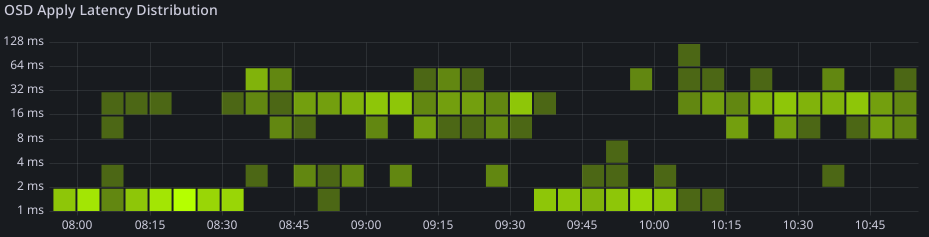
ただGrafanaでOSDの状況をみると、このHDDをBlueStoreとして利用しているOSDだけでlatencyが悪化しています。

ちなみに交換予定のCephクラスターにある他の正常なHDDドライブ(HGST 7K2 2TB)の状態は次のとおりです。

他k8sクラスターで利用しているExos 7E2 (1TBモデル)をみるとlatencyのバラツキは大きいので、Exos 7E2の特性かもしれません。
この1TBのHDDも今年の5月で保証は切れているので、様子をみて交換を検討しますが、まだしばらく利用する予定です。
使っている範囲ではWD(HGST), Seagete, TOSHIBAのいずれのドライブもニアライン級であれば問題はないと思っています。
交換手順
まず試したのは以前の記事を参考にRook/Cephに含まれているosd-purge.yamlを使用する方法ですが、今回はうまく進めることができませんでした。
原因としては以前にosd-purge.yamlを適用した時点では、OSDは既にdownしていた状態でしたが、今回は表面上はエラーはまったくない状態だったので、OSDはupのまま有効なPGsが配置されている状態だったことにあります。
今回はあらかじめOSDをdownさせる手順を追加して進めた形になります。
対象となったOSDは3で、今回の作業の流れは次のようになりました。
- 手動で
rook-ceph-operatorを停止(replicas: 0)した - rook-ceph-toolsのshellから手動で
ceph osd out osd.3を実行した - PGsの退避後、osd-purge.yamlを実行したが、osd.3は削除されなかった
- 手動で
deploy/rook-ceph-osd-3を停止(replicas: 0)した - 再度、osd-purge.yamlを実行し、osd.3を削除した
- 対象ノードをcordon/drainし、shutdownした
- HDDを交換後、ノードを起動し、uncordonして、クラスターに復帰させた
-
rook-ceph-operatorを起動(replicas: 1)した
deploy/rook-ceph-sd-3は停止(replicas: 0, scale down)しただけで、削除(delete)していませんが、osd-purge.yamlを実行したタイミングで削除されています。
最終的にHDDは交換しているので、Operatorが起動するとrook-ceph-sd-prepare-*が起動され、新しいdeploy/rook-ceph-osd-3が作成されます。
準備作業
事前に作業対象のノードとOSD番号の対応を確認します。
$ ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 node3 367G 1495G 1 13.5k 10 236k exists,up
1 node2 411G 1451G 1 12.7k 31 177k exists,up
2 node4 335G 1527G 4 36.0k 14 320k exists,up
3 node1 350G 1512G 5 86.3k 86 336k exists,up
Operatorの停止 (1)
一般的な方法はscaleを利用して、deploymentオブジェクトでreplicasを0に設定することです。
$ kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas=0
kubectlから直接editコマンドでreplicas:行を編集することもできます。
手動でのOSDの停止方法 (2)
最初にceph osd out osd.3を実行すると、PGsが他のノードに再配置され始めます。
500GBほどの利用状況で、この処理に24時間ほどかかっています。その間はOSDのステータスはupのままです。
$ ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
3 hdd 1.81940 1.00000 1.8 TiB 310 GiB 308 GiB 34 KiB 2.0 GiB 1.5 TiB 16.64 0.84 76 up
1 hdd 1.81940 1.00000 1.8 TiB 410 GiB 409 GiB 41 KiB 1.1 GiB 1.4 TiB 22.02 1.12 74 up
0 hdd 1.81940 1.00000 1.8 TiB 367 GiB 364 GiB 34 KiB 2.1 GiB 1.5 TiB 19.68 1.00 66 up
2 hdd 1.81940 1.00000 1.8 TiB 382 GiB 379 GiB 30 KiB 2.6 GiB 1.4 TiB 20.49 1.04 75 up
TOTAL 7.3 TiB 1.4 TiB 1.4 TiB 141 KiB 7.8 GiB 5.8 TiB 19.71
MIN/MAX VAR: 0.84/1.12 STDDEV: 1.96
pod/rook-ceph-osd-3-*が動作している間は、OSDのステータスはUPのままです。
osd-purge.yamlの編集と反映 (3)
このファイルは必ずOSDの番号を記入してから適用する必要があります。
diff --git a/deploy/examples/osd-purge.yaml b/deploy/examples/osd-purge.yaml
index 4c62da285..09f074b49 100644
--- a/deploy/examples/osd-purge.yaml
+++ b/deploy/examples/osd-purge.yaml
@@ -44,7 +44,7 @@ spec:
- "--force-osd-removal"
- "false"
- "--osd-ids"
- - "<OSD-IDs>"
+ - "3"
env:
- name: POD_NAMESPACE
valueFrom:
編集後に、kubectlコマンドからapplyします。
$ kubectl -n rook-ceph apply -f osd-purge.yaml
初回は次のようなログが記録され、期待した動作はしませんでした。
2025-11-05 00:18:02.615364 I | cephosd: validating status of osd.3
2025-11-05 00:18:02.615389 I | cephosd: osd.3 is healthy. It cannot be removed unless it is 'down'
今回、これはうまく動作しませんでしたが、次の工程を終えてから、再度実行します。
手動でのpod/rook-ceph-osd-3-*の停止 (4)
Operatorと同様にscaleを利用するか、手動でdeployオブジェクトの定義を編集します。
$ kubectl -n rook-ceph scale deploy rook-ceph-osd-3 --replicas=0
これを実行してからpod/rook-ceph-osd-3-*が消えていることを確認して、再度osd-purge.yamlを反映する手順(5)を行います。
再度osd-purge.yaml(5)を実行する
繰り返し実施する時には、名前が同じJOBが既に登録されているので削除してから反映させます。
$ kubectl -n rook-ceph delete -f osd-purge.yaml
$ kubectl -n rook-ceph apply -f osd-purge.yaml
今度は次のようなログがPODに記録され、無事にOSDが削除されました。
2025-11-05 00:24:50.407275 I | cephosd: no ceph crash to silence
2025-11-05 00:24:50.407308 I | cephosd: completed removal of OSD 3
残りの作業 (6〜8) と、よくある失敗
あとは繰り返しや他で説明している内容なので省略します。
問題になりそうなところは交換するHDDが新品でない場合に、適切に初期化されていない場合でしょう。
HDDの初期化についてはrook.ioのドキュメントに記述があるので、交換してからuncordonする前にsgdisk --zap-all /dev/sdNなどを適切に実行しましょう。
まとめ
HDDを予防的に交換するといってもSMARTなどで異常が報告されてから対応する場合がほとんどだと思います。
今回の交換対象HDDは、ニアラインHDDではなく、初期の低回転なNAS用HDDでした。
ディスクの回転数が低いため全体のパフォーマンスも低かったのですが、さらに悪化してしまいアプリケーションレベルでもファイルの保存に体感で時間がかかっているのが分かるほどでした。
SMARTの出力もhdparmの出力も、これ自体は異常ではないと思います。
パフォーマンスが我慢できるならそのまま使い続ける選択もありましたが、今回はとりあえず全て7200rpmのニアラインHDDに揃えることにしました。