やりたかったこと
Smokepingを使って、ネットワークの特定の区間のレイテンシやパケロス等のネットワーク品質監視をしていましたが、これが古めかしいOSSなのでどうにも辛い…。とはいえ、Pingdom等のサービスでは、ロケーションは選べても厳密な始点は選べず、また、LANの部分は監視できません。そして、Zabbixを立てるのも正直、やりたくなく…
というわけで、Datadogを使って同様の監視をしてみました。ちなみに、お試しだけであれば無償版でも出来ます!
構成概要
登場人物は2種類だけです
Datadog(クラウドサービス)
https://www.datadoghq.com/
メトリクスの保存やグラフ描画をさせます
計測サーバ(クラウド or 物理)
EC2でもGCEでもオンプレの物理サーバでも構いませんが、Datadog Agentをインストールして計測します。こちらが ネットワーク監視の始点になります。
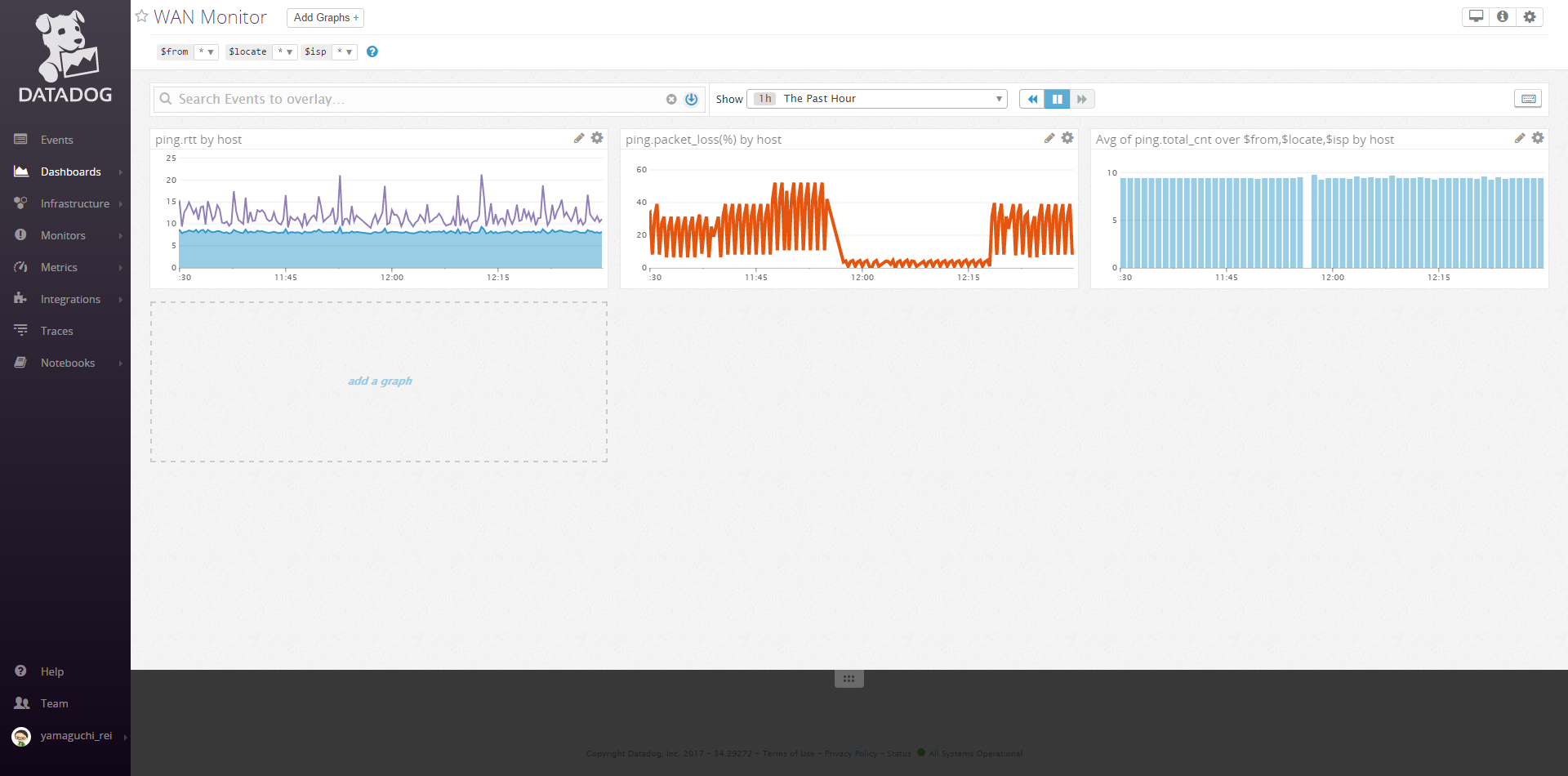
出来上がりイメージ
3つのグラフは左からRTT, パケロス, 試行回数になっています。(試行回数は計測がうまくいっているかの確認用…)
そして、$fromが計測元、$locateが計測先、$ispが計測先回線のISPで、これを選択すると絞り込みが出来るようになっています。
作り方
事前準備
Datadogを使える状態にするところは、以下のような記事を参考にお願いします…
Datadogを導入する
カスタムメトリクスの収集
Datadogのカスタムメトリクスを使いますので、/etc/dd-agent/checks.dと/etc/dd-agent/conf.dに以下のファイルを設置します。(conf.dの方はカスタマイズしてください)
# !/usr/bin/env python
import subprocess
import re
import time
from checks.network_checks import NetworkCheck, Status
class PingCheck(NetworkCheck):
def __init__(self, name, init_config, agentConfig, instances):
NetworkCheck.__init__(self, name, init_config, agentConfig, instances)
for instance in instances:
if not instance.get('isp', None):
raise Exception("All instances should have a 'isp' parameter")
# for initialize loss cnt
self.__simple_increment(instance, 'loss_cnt', 0)
def _check(self, instance):
start = time.time()
p = Ping(instance['addr'], self.init_config.get('ping_timeout', 4))
for i in range(self.init_config.get('check_times', 1)):
try:
p.run()
self.__simple_histogram(instance, 'rtt', p._rtt)
time.sleep(self.init_config.get('interval', 0.1))
ret = (Status.UP, "UP")
except:
self.__simple_increment(instance, 'loss_cnt')
ret = (Status.DOWN, "DOWN")
finally:
self.__simple_increment(instance, 'total_cnt')
elapsed_time = time.time() - start
self.log.info("name:%s, elapsed_time:%s[sec]"
% (instance['name'], round(elapsed_time, 2)))
return ret
def __simple_increment(self, instance, category, value=1):
self.increment(
'%s.%s' % (self.init_config.get('basename', 'ping'),
category),
value,
tags=['isp:%s' % instance['isp'],
'locate:%s' % instance['name']]
)
def __simple_histogram(self, instance, category, value):
self.histogram(
'%s.%s' % (self.init_config.get('basename', 'ping'),
category),
value,
tags=['isp:%s' % instance['isp'],
'locate:%s' % instance['name']]
)
def report_as_service_check(self, sc_name, status, instance, msg=None):
pass
def _create_status_event(self, sc_name, status, msg, instance):
# TODO 5.3 remove that
pass
class Ping(object):
def __init__(self, host, timeout):
self._host = host
self._timeout = timeout
def run(self):
ping = subprocess.Popen(
["ping", "-c", "1", "-W", str(self._timeout), self._host],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
out, error = ping.communicate()
if error:
raise Exception('[NG]: ServerName->%s, Msg->"%s"'
% (self._host, error.rstrip()))
else:
try:
self._ttl = int(re.search("(?<=ttl=)[\d\.]+", out).group())
self._rtt = float(re.search("(?<=time=)[\d\.]+", out).group())
except AttributeError:
raise Exception('[NG]: ServerName->%s, Msg->"%s"'
% (self._host, 'cannot connect'))
※最新版はGistで公開しています
init_config:
basename: ping
check_times: 10
threads_count: 6
interval: 0.1
instances:
- addr: x.x.x.x
isp: HOGEHOGE
name: [location name]
- addr: x.x.x.y
isp: HOGEHOGE2
name: [location name]
これらのファイルを設置したあと、設定がうまくいっているかは以下のコマンドで確認できます
sudo -u dd-agent dd-agent check ping
問題ないようであれば、agentを再起動して、メトリクスの収集を始めます。
ダッシュボード&グラフの作成
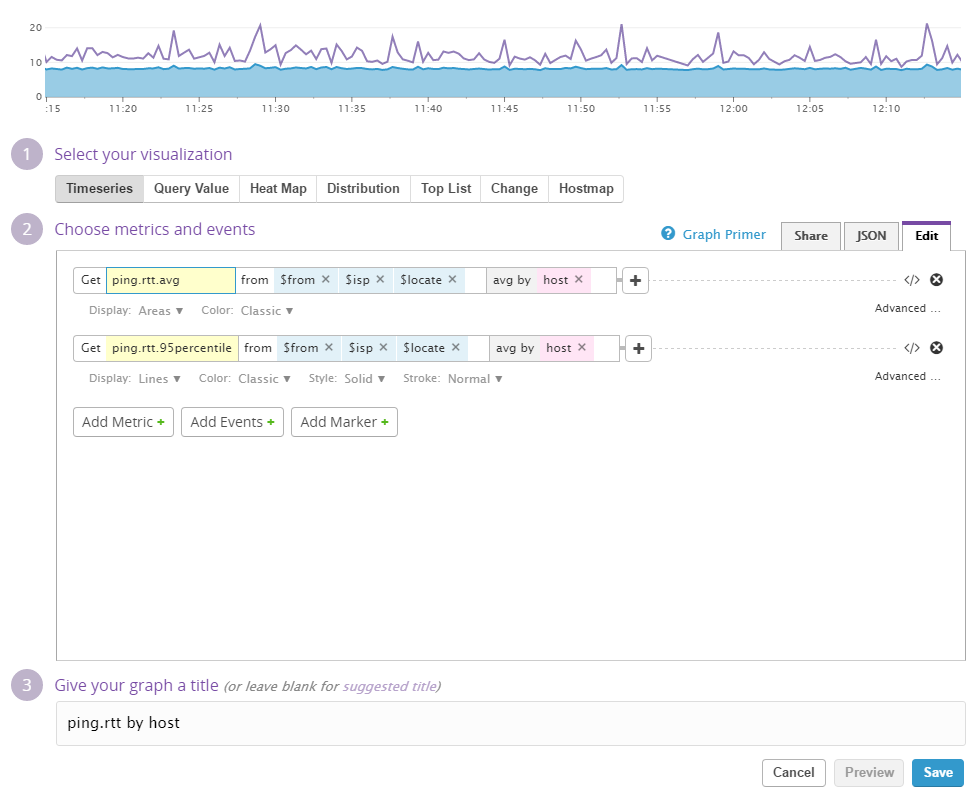
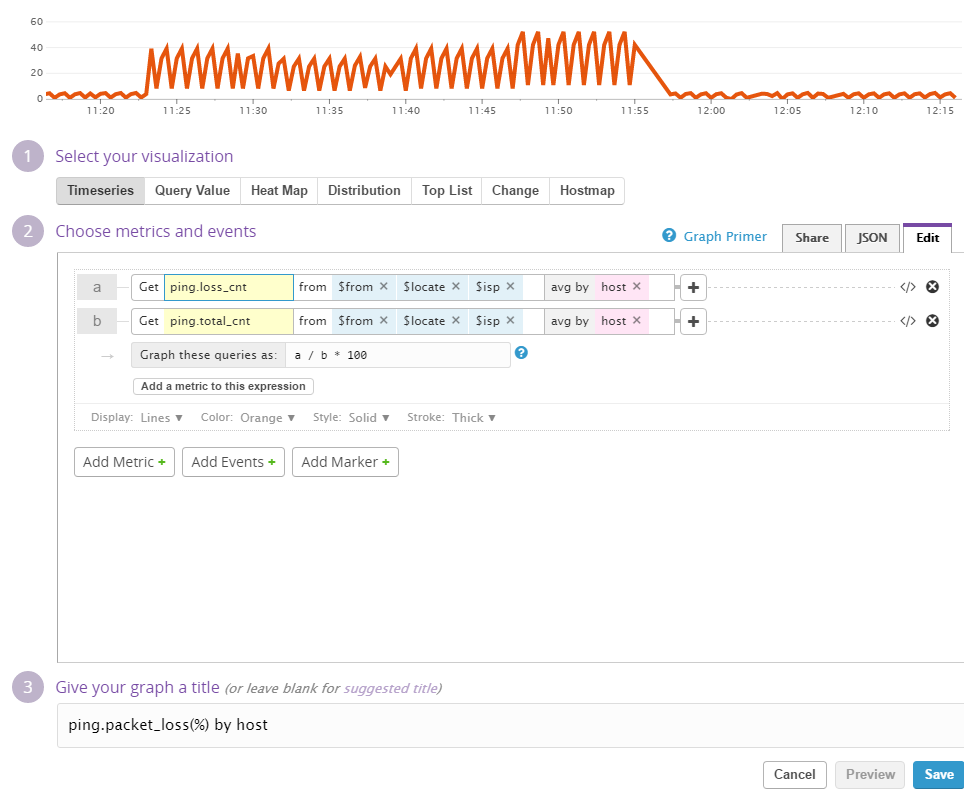
収集されるメトリクスそのものだと、データとしてはちょっと見辛いので、ダッシュボード&グラフを作成して見やすくします。それぞれのグラフの作り方は以下の画像の通りです。
RTT
パケロス
データ取得件数
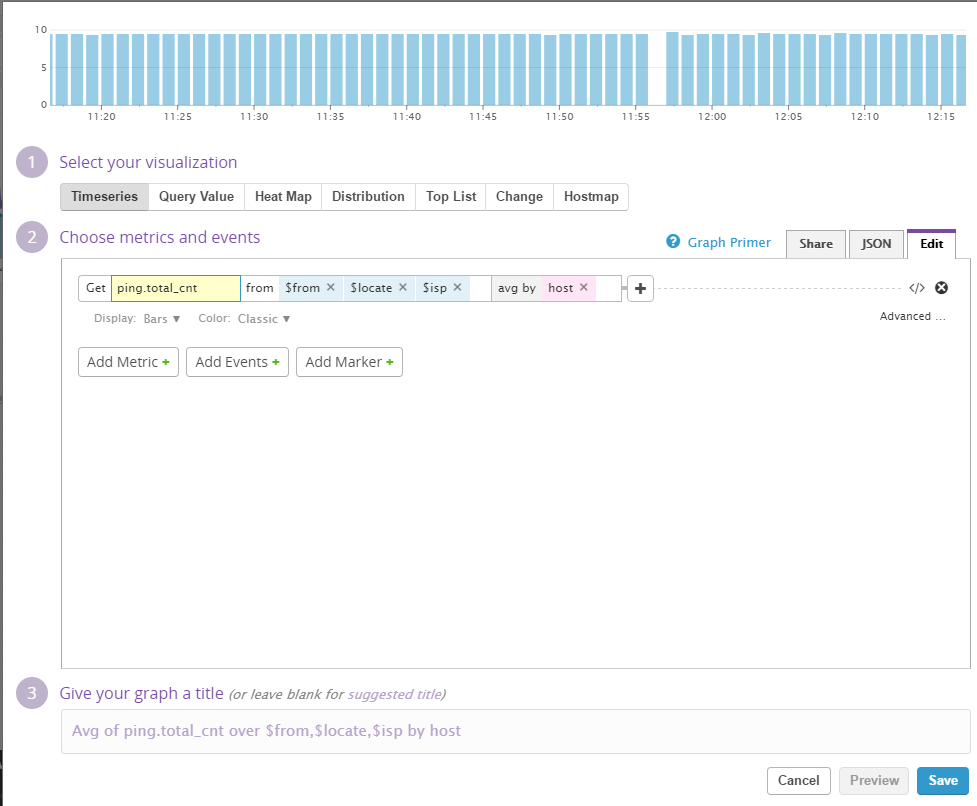
※$fromにはhostタグ(datadogのデフォルト)、$locateにはnameタグ、$ispにはispタグを当てています
おわりに
計測サーバには30カ所くらいを計測させていますが、Pingしてメトリクスを送信しているだけなので、かなりスペックの低いサーバでも動作しています。