こんにちは。
LocoPartnersでReluxのサーバーサイドを担当している山口です。
この記事は「Relux Advent Calendar 2018」21日目の記事です。
本日はGoogleのBigQueryでデータを参照する際に私が学んだことについて紹介します。
テーブルの一覧をどこから参照するか
Googleにログインした状態でGoogle Cloud Platform - BigQueryにアクセスすると、下記の画面が表示されるのでサイドバーのリソースから検索窓を利用。または目視により必要なテーブルを探すことが可能でした。
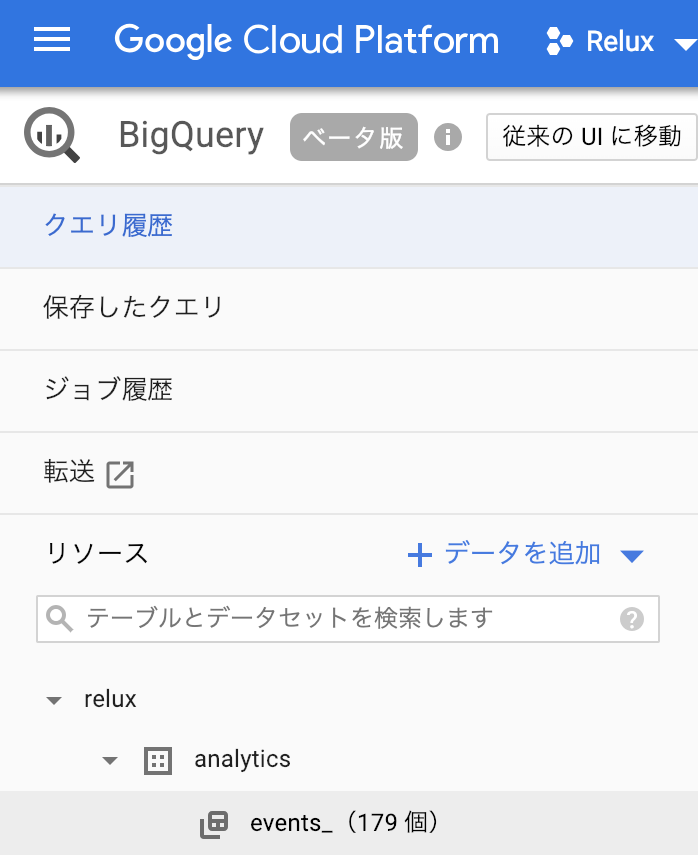
また、上記の画像をみても解るようにBigQueryはリソースを3つの階層で管理しています。 表中のレベル列に記載しているものは正式名称が解らなかったので私が勝手に命名しているものになります。 ご存知の方がいらっしゃれば教えてください。 ![]()
| レベル | 名称 | 画像中で該当する箇所 |
|---|---|---|
| ファーストレベル | project-id | relux |
| セカンドレベル | dataset-id | analytics |
| サードレベル | table-prefix | events |
例でいうとeventsがテーブルになります。 events_(179個) と表示されているのが不思議に感じたので調べてみるとeventsテーブルには分割テーブルという特殊なテーブルを採用しているからでした。
分割テーブルについて
簡単にはなりますが少しだけ分割テーブルについても調べてみました。
このeventsテーブルには毎日膨大な数のデータが蓄積されていくのですが、それを1つのテーブルで扱おうとすると下記のような問題が発生します。
- データ数の増加によってパフォーマンスが低下
- 一度のSQLで読み取られるバイト数増加によるコストパフォーマンスの上昇
たしかに分割するに限りますね。分割テーブルは下記の分割方法で作成が可能です。
| 分割方法 | 説明 |
|---|---|
| 取り込み時間で分割されたテーブル | データの取り込み(読み込む)日付または到着日に基づいて分割されたテーブル |
| 分割テーブル | TIMESTAMP 列または DATE 列に基づいて分割されたテーブル |
ちなみにeventsテーブルの分割には取り込み時間で分割する方法を用いているので、日毎に分割されたeventsテーブル(events_20181101, events_20181102, events_20181103など)が生成されています。
BigQueryで利用可能なSQLの種類
BigQueryでデータを収集する対象テーブルを発見したので早速SQLを記述して必要な情報を取得したいところですが、BigQueryでは 標準SQL と レガシーSQL とよばれる2種類のSQLが用意されており、そのどちらかを利用することが出来る。ということが新たに解りました。
Googleのリファレンスを確認後、下記の理由から私は標準SQLを利用することにしました。
※この記事内の説明でも標準SQLを利用しています。
- レガシーSQLリファレンス冒頭に 「BigQuery では標準SQLのクエリ構文を使用してください。」 と記載があること
- レガシーSQLと比較して標準SQLの機能が多いこと
- レガシーSQLと比較して標準ドキュメントが充実していること
また、標準SQLを利用する場合には簡単な設定変更が必要になったのでGoogleのドキュメントを参照して設定を行いました。
標準SQLを利用して単一テーブルを検索する
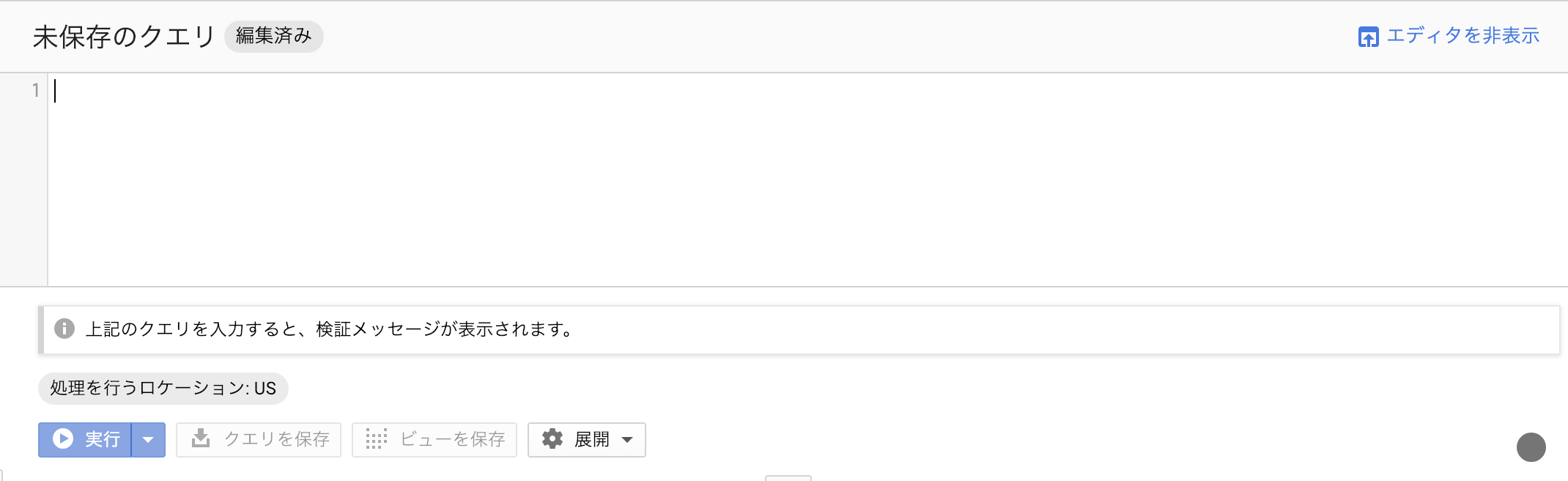
利用するSQLの種類も決定したのでBigQueryで単純なSELECT文のSQLを記述してみます。SQLを記述すると即座にSQLのチェックが行われSQLの文法に誤りがないこと、実行した場合に参照されるデータの量が表示されました。参照されるデータ量はそこそこありましたが一度の実行で凄い金額が請求されるレベルではなかったので、そのままSQLを実行し結果を取得することにしました。
SELECT * FROM `relux.analytics.events_20181219` LIMIT 1000

参照されるデータ量を抑えたい場合
BigQueryは参照したデータ量に応じても課金が行われます。なるたけ低コストで便利なものを使いたいものです。簡単にですがどのように参照されるデータ量を抑えることができるかを確認してみたところ、取得列を絞ることで参照されるデータ量を抑えることが可能でした。
個人的にはWHERE句を用いてもデータ量を参照できないことが以外でした。
| 方法 | データ量の変化 |
|---|---|
| WHERE句を用いる | なし |
| LIMIT句を用いる | なし |
| 列を絞る | あり |
標準SQLを利用して分割したテーブルを纏めて検索する
日毎に分割されたeventsテーブル(events_20181101, events_20181102 ... events_20181130)のそれぞれに対して、日毎にSQLを実行して情報を取得するのは範囲が増加するほど面倒な作業になっていくのは想像に難くないですよね。
BigQueryでは下記のように分割テーブルを纏めて検索することが可能でした。
-- 2018/11月分のeventsテーブルを纏めて検索
SELECT
event_date,
event_name,
event_params
FROM
-- *(asterisk) を用いることで前方一致でテーブルを纏めて検索が可能です
`relux.analytics.events_201811*`
WHERE
-- FROM句で記述された *(asterisk) に当てはまる値を正規表現を用いて限定します
-- 先頭のrは正規表現を用いる場合は必須です。"(double-quotation)の中に正規表現を記述します
REGEXP_CONTAINS(_TABLE_SUFFIX, r"^\d{2}$")
列中の値が配列や構造体で複数の値が含まれる場合
例えば、下記のような料理名と料理に必要な具材を保存しているrecipesテーブルがあったとします。
recipes テーブル
| 行 | cooking | ingredient.key | ingredient.value |
|:--|--:|--:|--:|--:|
| 1 | 麻婆豆腐 | 1 | 絹ごし豆腐 |
| | | 2 | 豚ひき肉 |
| | | 3 | 韮 |
| | | 4 | 味噌 |
| | | 5 | 豆板醤 |
| | | 6 | 大蒜 |
| | | 7 | 山椒 |
| | | 8 | 片栗粉 |
| 2 | 冷奴 | 1 | 絹ごし豆腐 |
| | | 2 | 生姜 |
| | | 3 | 葱 |
このデータに対して料理の具材で絹ごし豆腐を利用している料理だけを取得したいと考えたので下記のSQLを記述してみました。
SELECT
recipes.cooking,
recipes.ingredient.key,
recipes.ingredient.value
FROM
recipes
WHERE
recipes.ingredient.value = '絹ごし豆腐'
しかし、このSQLを記述すると Cannot access field value on a value with type ARRAY<STRUCT<key INT64, value STRING>> という、エラーメッセージが表示されました。
これはingredient自体が文字列でないことが原因で発生しています。調べていくうちに、このingredientの中にあるvalueを取り出すにはCROSS JOIN句, WITH句, UNNEST関数の3つを用いる必要があることが解りました。
CROSS JOIN句
CROSS JOIN句について知ってはいましたが改めて動作を確認しました。
例えば、下記のようなテーブルが存在していたとします。
osake テーブル
| ID | 酒名 |
|---|---|
| 1 | Kavalan Solist Manzanilla Cask |
| 2 | OCTOMORE 08.2 |
| 3 | 磯自慢 特別純米 雄町55 |
okashi テーブル
| ID | 菓子名 |
|---|---|
| 1 | 柿ピー |
| 2 | ポテチ |
| 3 | 明太子 |
SELECT
*
FROM
osake
CROSS JOIN
okashi
==========結果==========
| id | 酒名 | id | 菓子名 |
|---|---|---|---|
| 1 | Kavalan Solist Manzanilla Cask | 1 | 柿ピー |
| 2 | OCTOMORE 08.2 | 1 | 柿ピー |
| 3 | 磯自慢 特別純米 雄町55 | 1 | 柿ピー |
| 1 | Kavalan Solist Manzanilla Cask | 2 | ポテチ |
| 2 | OCTOMORE 08.2 | 2 | ポテチ |
| 3 | 磯自慢 特別純米 雄町55 | 2 | ポテチ |
| 1 | Kavalan Solist Manzanilla Cask | 3 | 明太子 |
| 2 | OCTOMORE 08.2 | 3 | 明太子 |
| 3 | 磯自慢 特別純米 雄町55 | 3 | 明太子 |
CROSS JOIN した結果は 酒テーブル と 菓子テーブル のすべての組み合わせになります。レコード数は JOINされる側のテーブルのレコード数 * JOINする側のテーブルのレコード数 になります。
WITH句
WITH句は複数回同じ副問合せを記述する場合やSQLの見易さを考慮する際にとても有効です。自分にとって都合の良いデータが集まったテーブルをSQLの実行中に一時的に定義しておくものと自分は考えています。
下記は具体例になります。
-- 11月分の取得したいイベントのデータのみが集まった表を作成
WITH event_params_201811 AS (
SELECT
event_date,
event_name,
event_params
FROM
-- *(asterisk) を用いることで前方一致でテーブルを纏めて検索可能
`relux.analytics.events_201811*`
WHERE
-- FROM句で記述された *(asterisk) に当てはまる値を正規表現を用いて限定します
-- 先頭のrは正規表現を用いる場合は必須です。"(double-quotation)の中に正規表現を記述してください
REGEXP_CONTAINS(_TABLE_SUFFIX, r"^\d{2}$")
)
-- WITHで作成したテーブルに対してSELECTを行える。
SELECT * FROM event_params_201811
UNNEST関数
UNNEST関数は配列や配列に含まれる構造体を値テーブルにして返す関数です。
冒頭で例としたrecipesテーブルを利用して具体的な例を紹介します。
recipes テーブル
| 行 | cooking | ingredient.key | ingredient.value |
|:--|--:|--:|--:|--:|
| 1 | 麻婆豆腐 | 1 | 絹ごし豆腐 |
| | | 2 | 豚ひき肉 |
| | | 3 | 韮 |
| | | 4 | 味噌 |
| | | 5 | 豆板醤 |
| | | 6 | 大蒜 |
| | | 7 | 山椒 |
| | | 8 | 片栗粉 |
| 2 | 冷奴 | 1 | 絹ごし豆腐 |
| | | 2 | 生姜 |
| | | 3 | 葱 |
このテーブルのingredient列は複数の値(配列の構造体)が含まれているので、1行のingredientに複数の値が含まれています。このingredient列を展開して考えると下記のようにkey列とvalue列のテーブルになっていることになります。
ingredient列を展開したテーブル
| key | value |
|---|---|
| 1 | 絹ごし豆腐 |
| 2 | 豚ひき肉 |
| 3 | 韮 |
| 4 | 味噌 |
| 5 | 豆板醤 |
| 6 | 大蒜 |
| 7 | 山椒 |
| 8 | 片栗粉 |
| 1 | 絹ごし豆腐 |
| 2 | 生姜 |
| 3 | 葱 |
上記のingredient列を展開して得られるテーブルを、元のrecipesテーブルの各行に紐づけることができれば、配列の中身を条件に行を絞ることが可能になりそうだということが解りました。
ここで上述したCROSS JOINとUNNEST関数を利用して、上記で検討したことを実現してみました。
SELECT
cooking,
ingredient,
key,
value
FROM
recipes
CROSS JOIN
UNNEST(ingredient) AS unnested_ingredient
==========結果==========
複雑な箇所だと思うので改めてrecipesテーブルとingredient列を展開して得られるテーブル。そして2つのテーブルを結合した結果をまとめて載せておきます。
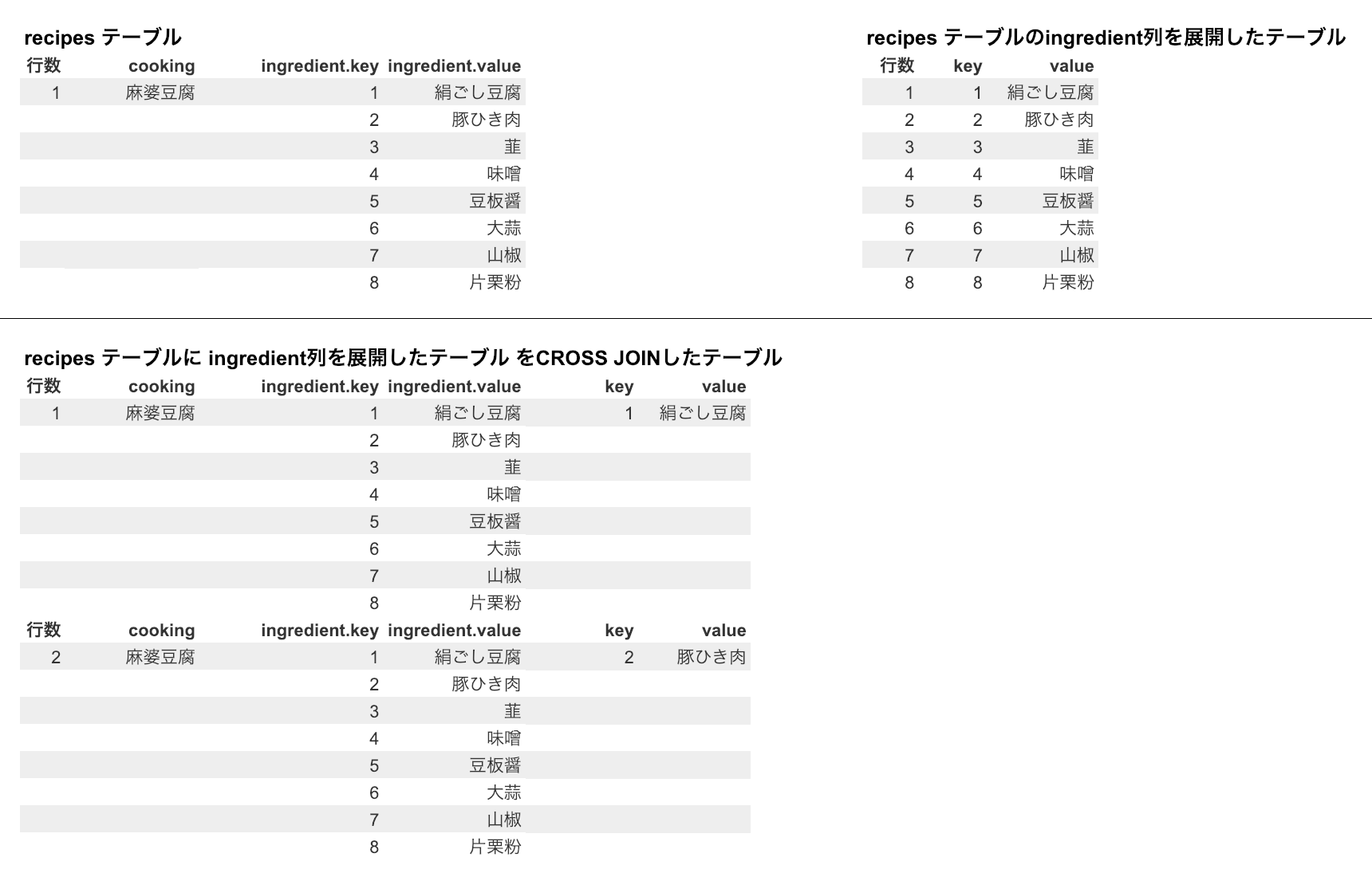
CROSS JOINによって出来上がったテーブルからingredient列を省いたほうが解りやすい人もいるかもしれないので別バージョンも載せておきます。
SELECT
cooking,
key,
value
FROM
recipes
CROSS JOIN
UNNEST(ingredient) AS unnested_ingredient
==========結果==========
| 行数 | cooking | key | value |
|---|---|---|---|
| 1 | 麻婆豆腐 | 1 | 絹ごし豆腐 |
| 2 | 麻婆豆腐 | 2 | 豚ひき肉 |
| 3 | 麻婆豆腐 | 3 | 韮 |
| 4 | 麻婆豆腐 | 4 | 味噌 |
| 5 | 麻婆豆腐 | 5 | 豆板醤 |
| 6 | 麻婆豆腐 | 6 | 大蒜 |
| 7 | 麻婆豆腐 | 7 | 山椒 |
| 8 | 麻婆豆腐 | 8 | 片栗粉 |
これで列中の値が配列であったとしても1つの行として扱う方法を修得できたはずです。
最後に、当初の目的であった 絹ごし豆腐 を利用したレシピのみを抽出してみましょう。
後は、いつものようにWHERE句を足すだけです。
SELECT
recipes.cooking,
unnested_ingredient.key,
unnested_ingredient.value
FROM
recipes
CROSS JOIN
UNNEST(ingredient) AS unnested_ingredient
WHERE
unnested_ingredient.value = '絹ごし豆腐'
==========結果==========
| 行数 | cooking | key | value |
|---|---|---|---|
| 1 | 麻婆豆腐 | 1 | 絹ごし豆腐 |
| 2 | 冷奴 | 1 | 絹ごし豆腐 |
さいごに
近頃では、Software Developerと呼ばれる職種以外の方達が自身でSQLを記述し、必要な情報の取得と分析を行われているのを社内外を問わず見かけるようになりました。当記事を参考にBigQueryに未だ触れたことがないSoftwareDeveloper以外の方達の助けになれば幸いです。
それでは、明日も引き続きRelux Advent Calendar 2018をお楽しみください。