はじめに
ウェブスクレイピングは、ウェブサイトから効率的にデータを収集する強力な技術です。しかし、プログラミングの知識がない場合や、素早くデータを取得したい場合には、コードを書くのが面倒に感じることがあります。そこで今回は、Easy ScraperというChrome拡張機能を紹介します。この拡張機能を使えば、コードを書かずに直感的な操作でウェブスクレイピングが可能になります。
Easy Scraperとは
Easy Scraperは、ウェブスクレイピングを簡単に行うためのChrome拡張機能です。以下のような特徴があります:
- 使いやすいインターフェース
- 自動化機能
- データエクスポート機能
- カスタマイズ機能
- データ整形機能
主な機能
Easy Scraperには以下のような機能があります:
1. 簡単なデータ抽出
- 特定の要素(テキスト、画像、リンクなど)を簡単に抽出するためのインターフェースを提供
2. 定期的なスクレイピング
- スケジュールを設定して定期的にデータを自動収集し、最新情報を常に取得
3. データエクスポート
- 抽出したデータをCSV、Excel、JSONなどの形式でエクスポート可能
- エクスポートデータのカスタマイズが可能
4. カスタムスクリプト
- JavaScriptやPythonなどのスクリプトを使用して、カスタマイズされたデータ抽出や加工が可能
5. データ整形
- 抽出したデータを整形し、クリーンな形式で保存する機能
- データのフィルタリングや変換をサポート
6. ブラウザの自動操作
- ブラウザを自動で操作し、ログインやフォームの自動入力なども可能
- ページのスクロールやクリック操作など、ユーザーアクションのシミュレーションが可能
7. API連携
- 取得したデータを他のシステムやアプリケーションと連携するためのAPI機能
8. エラー処理
- スクレイピング中に発生するエラーを自動で検出し、リトライや通知を行う機能
9. データストレージ
- 抽出したデータをクラウド上に保存し、後でアクセスやダウンロードが可能
10. ユーザー管理
- 複数ユーザーでの利用をサポートし、役割に応じたアクセス権限を設定
11. GUIおよびCLI
- グラフィカルユーザーインターフェース(GUI)とコマンドラインインターフェース(CLI)の両方を提供し、使い勝手に応じた操作が可能
Easy Scraperの使い方
Easy Scraperを使ってQiitaのタイムラインページをスクレイピングする場合、以下のような手順で行うことができます:
-
Easy Scraperのインストール
- ChromeウェブストアからEasy Scraperをインストールします。
-
スクレイピングの設定
-
Qiitaのタイムラインページ(https://qiita.com/timeline)に移動します。
-

-
Easy Scraperのアイコンをクリックします。
-
画面上でデータを抽出したい要素(記事のタイトルやタグなど)を選択します。
-
-
-
データの確認とエクスポート
-
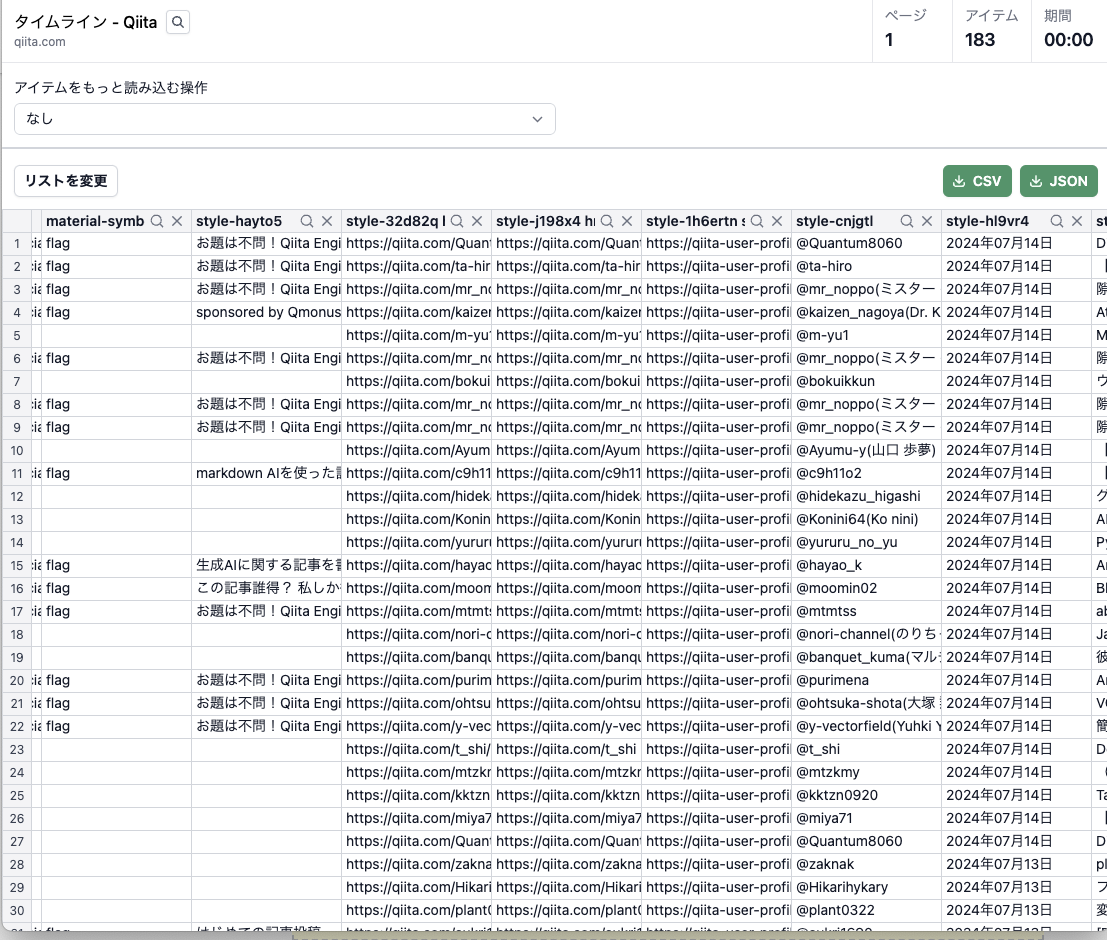
瞬時にスクレイピング完了!
-
選択した要素が正しく認識されていることを確認します。
-
-
データをCSVやExcel形式でエクスポートします。
-
Easy Scraperの効果的な利用例
Pythonコードとの比較
通常、Qiitaのタイムラインページをスクレイピングする場合、以下のようなPythonコードを書く必要があります:
import requests
from bs4 import BeautifulSoup
# QiitaのタイムラインURL
url = "https://qiita.com/timeline"
# ヘッダー情報を追加して、リクエストがブロックされないようにします
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# ページをリクエスト
response = requests.get(url, headers=headers)
# レスポンスをパース
soup = BeautifulSoup(response.content, "html.parser")
# グリーン色で囲まれた部分の情報を抽出
# ここでは、記事のタイトルとタグを例として抽出します
articles = soup.find_all("article") # 具体的なセレクターはHTML構造により調整する必要があります
for article in articles:
title = article.find("h2").get_text(strip=True) # タイトルの取得
tags = [tag.get_text(strip=True) for tag in article.find_all("a", class_="item-tag")] # タグの取得
print(f"Title: {title}")
print(f"Tags: {', '.join(tags)}")
print("---")
このコードでは、requestsとBeautifulSoupライブラリを使用してHTMLを解析し、必要な情報を抽出しています。しかし、Easy Scraperを使用すれば、このようなコードを書く必要がなく、直感的な操作でデータを抽出できます。
まとめ
Easy Scraperを使用することで、プログラミングの知識がなくても、直感的な操作でウェブスクレイピングを行うことができます。特に、以下のような場合に便利です:
- スクレイピングに慣れていない方
- 手軽にデータを取得したい場合
- プロトタイピングや小規模なデータ収集プロジェクト
ただし、大規模なスクレイピングや複雑なデータ抽出が必要な場合は、従来のプログラミング手法も検討する必要があります。また、スクレイピングを行う際は、対象ウェブサイトの利用規約を確認し、倫理的な配慮を忘れずに行いましょう。
Easy Scraperは、ウェブスクレイピングの世界への入口として、またはクイックなデータ収集ツールとして、多くの方の作業効率を向上させることができる出来ます。様々な分野での活用例を参考に、自身のニーズに合わせてEasy Scraperを活用してみてください。