概要
(当記事から)3年前に書かれたものですが、次のようなSQL記事がありました。
SQLite3で地名を調べるときの始め方 - Qiita
この記事において、次のような手順でSQLを叩いていました。
- リレーショナル・データベースとしてSQLiteを使用
- 土台となるデータとして住所.jpの郵便番号データを使用
- 「鮎」「梅」「荻」など、地名に含まれていると過去に災害が起きた土地である可能性を暗示させるキーワードを含む地名を検索
- 検索にはもちろんLIKE句を使用
この記事では「SQLも簡単に書けるレベルで使用しています」とあるのでツッコミは入れるべきではないと思っていたのですが、流石に1000秒を超えるクエリを放って置けないと感じたので、解説記事風にクエリ改善を試みることにしました。
当該クエリの問題点について
上記記事では、次のようなクエリが使用されていました。
ここでad_addressは「住所.jpの郵便番号データにある、郵便番号毎の住所データ」、wordsは「キーワードを1つ1行で並べたもの」です。前者は2018/02/09更新分で149102行、後者は漢字1~2文字のものが26行あります。
# キーワードを1つ以上含む地名一覧
select zip,ken_name,city_name,town_name from ad_address as ad,words as w1 where ad.town_name like '%'||w1.word||'%'||'%'
# キーワードを2つ以上含む地名一覧
# Run Time: real 33.766 user 33.564572 sys 0.133176
select zip,ken_name,city_name,town_name from ad_address as ad,words as w1,words as w2 where ad.town_name like '%'||w1.word||'%'||w2.word||'%'
# キーワードを3つ以上含む地名一覧
# Run Time: real 1047.457 user 1041.483093 sys 2.566790
select zip,ken_name,city_name,town_name from ad_address as ad,words as w1,words as w2,words as w3 where ad.town_name like '%'||w1.word||'%'||w2.word||'%'||w3.word||'%'
ここでまず目を引くのはクエリの実行時間でしょう。「キーワードを1つ以上」における実行時間は載っていませんでしたが、「2つ以上」「3つ以上」の実行時間は載っています。これによると、キーワードを1つ追加した結果計算時間が30倍以上になったことが分かります。
その原因について詳しく知るため、「キーワードを2つ以上含む地名一覧」クエリにおける実行計画を読んでみましょう。
# 「キーワードを2つ以上含む地名一覧」のクエリに対して実行計画を表示するようにした
explain query plan select zip,ken_name,city_name,town_name from ad_address as ad,words as w1,words as w2 where ad.town_name like '%'||w1.word||'%'||w2.word||'%'
とした結果は次の通りです(PupSQLiteで表示)。
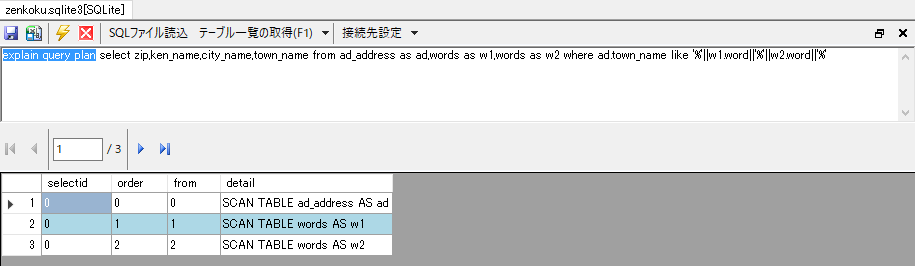
ここでSCAN TABLEはSQLiteにおけるフルテーブルスキャンを指し、orderはテーブル結合のネストレベルを表します。つまり、ad_addressテーブルにwordsテーブルが2重に結合されたということですね。
SQLiteのJOINは「Nested Loop Join」……行数が単純な掛け算で増えていくタイプのJOINですので、結局100,792,952行のデータの全行に対してLIKE句による判定を行ったということになります。そりゃ時間も掛かりますわ……。
解決策
フルテーブルスキャンする範囲が大きすぎるのが問題なので、事前にWHERE句で絞ってしまいましょう。可読性を優先してWITH句も使いますと、次のようなクエリになります。
これにより、当初100,792,952行のデータをスキャンしていたのが、3,876,652行のスキャン→検索結果(temp_table)の行数×26×26行のスキャンにまで収まります(削減したとはいえ結構高コストですが)。2018/02/09更新分の住所データではtemp_tableの行数は5673行でしたので、2段目のフルテーブルスキャンは3,834,948行で収まっています。
WITH temp_table AS (
SELECT DISTINCT zip,ken_name,city_name,town_name
FROM ad_address,words
WHERE ad_address.town_name LIKE '%'||words.word||'%'
)
SELECT zip,ken_name,city_name,town_name
FROM temp_table,words AS w1,words AS w2
WHERE temp_table.town_name like '%'||w1.word||'%'||w2.word||'%'
上記の改善効果を実行計画でも確認しましょう。フルテーブルスキャンになってしまうのは避けられませんが、w1およびw2とJOINされるのはad_addressそのものではなく「SUBQUERY 1(temp_table)」であることが分かります。
(なお、「B-TREE」は重複行を避けるためのDISTINCT制約によるものなので、今回の話とは直接は関係しません)
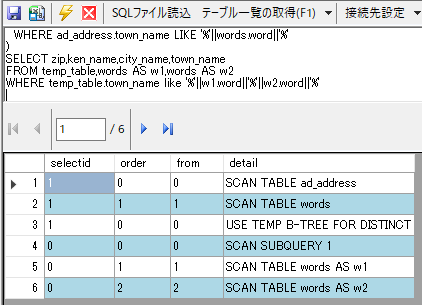
同様にして、「キーワードを3つ以上含む地名一覧」も次のように書き表すことができます。
WITH temp_table AS (
SELECT distinct zip,ken_name,city_name,town_name
FROM ad_address,words
WHERE ad_address.town_name LIKE '%'||words.word||'%'
),
temp_table2 AS (
SELECT zip,ken_name,city_name,town_name
FROM temp_table,words AS w1,words AS w2
WHERE temp_table.town_name like '%'||w1.word||'%'||w2.word||'%'
)
SELECT zip,ken_name,city_name,town_name
FROM temp_table2,words AS w1,words AS w2,words AS w3
WHERE temp_table2.town_name like '%'||w1.word||'%'||w2.word||'%'||w3.word||'%'
手元の環境(Windows 10,Core i7-4790K)で試してみたところ、実行時間は次のようになりました。
| ケース | 1つ以上 | 2つ以上 | 3つ以上 |
|---|---|---|---|
| 改善前 | 0.669[s] | 16.0[s] | ―(計測してない) |
| 改善後 | 0.549[s] | 1.13[s] | 16.7[s] |
まとめ
- 計算時間が長いなと思ったら実行計画を読む
- なるべくLIKE句は前方一致で使用する(今回のケースでは無理ですが)
- やむを得ずフルテーブルスキャンする際はWHERE句などで対象行数を減らせないか考える
- JOINは計算時間増加の要因になりやすいので(暗黙的なものについても)使用には注意する
質問コーナー
実行計画って何?
そもそもSQLは、検索を行うための細かな手順(アルゴリズム)を指定しなくてもデータを検索できる言語です。
これにより、細かなことを考えなくてもサクサク検索することができるわけですが、その裏では「クエリオプティマイザ」と呼ばれるプログラムが色々と頑張っています。具体的には、与えられたSQLを解釈し、「こういった手順で検索すれば速いはず」といった手順書(実行計画)を作成し、その通りにデータベースを検索するのです。
実行計画の詳細については、次のスライドがとてもわかり易いのでよろしければどうぞ。
より深く知るオプティマイザとそのチューニング - SlideShare
事前にインデックスをad_addressテーブルのtown_name列に張っておけば速くなったりしない?
結論から言うと今回のケースでは無駄です。
SQLite(に限らず普通のRDB)のLIKE検索におけるインデックスは、前方一致検索でしか使えません。またSQLiteの場合、コンパイルオプションによって前方一致検索でも使えなくされている場合があります。なので、「LIKE %単語%」といったケースは原理的にSQL向きではないのです。
LIKEがインデックスを使うようにSQLをチューニングする
sqliteのLIKE演算でインデックスを使う方法 — ありえるえりあ
元のクエリにはJOINなんて書いてないのに実行計画を見るとJOINしていたのはなんで?
SQLiteのマニュアルを読み込んだわけではないので推測ですが、X LIKE '%'||Y||'%'||'%'などと書くと、当然XとYの各項目を比較する必要があります。一致検索ではなくLIKE検索なのでインデックスが使えず、結果として全通り試さなければならないとなったのではないでしょうか。同様にX LIKE '%'||Y||'%'||Z||'%'などと書くとこれがネストして(ry