はじめに
テキストマイニングの手法、トピックモデルを用いて文書の自動分類に挑戦します。
理論的な部分はこちらの本。
先人の拵えた偉大なパッケージ群を活用させてもらい、Rでの実装部分を中心に書いてみたいと思います。
自分の振り返りためにも、困ったポイント、未解決ポイント含めて書いてるので、かなり回りくどいかもしれませんがご了承ください。
トピックモデルとは
テキストマイニングではネット上のブログやニュースなど、多量の文書を取り扱うことが多いですが、トピックモデルを用いることによって、そういった文書を教師なし学習で分類することができます。
ざっくりとしたイメージですが、「文書中に出現する単語の出現確率を推定するモデル」ということ。スポーツなら「サッカー」「野球」「バレーボール」のような単語が出現しやすく、料理なら「レシピ」「献立」「まな板」みたいな単語がきっと多く出てくるのはイメージがわきやすいと思います。
そのような単語の集まりをいくつかの「トピック」とし、それぞれの文書がどんなトピックを、どの程度の割合で持っているか推定することで、文書を分類することができます。
この技術、文書データだけでなく画像や音楽処理にも活用されているそうです。
使用するデータ
今回分類にトライするテキストデータは下記のページから拝借します。
こちらのデータをダウンロードすると、こんな構成になっています。

「ライフハック」「ムービー・エンタメ」「スポーツ」などいくつかのニュースカテゴリに分類されており、下の階層には大量のtxtデータが保存されています。
これらの文書を、一度一括で取り込んでみて、トピックモデルを実施後、同じような分類で振り分けられるかどうか、試してみたいと思います。
大まかな流れ
- 分析するテキストデータ(文字コード:utf-8)を一か所のフォルダに集める
-
tmパッケージにより、コーパスとして取り込む - この時点で可能な前処理を行う(英語ならここまでで前処理が完了だが、日本語の場合はやや面倒)
-
tidytextパッケージにより、コーパスをtibbleに展開する - 展開したtibbleをcsvで出力して、
read.csvで再度dataframeとして読み込む(RMeCabはutf-8のままで処理すると文字化けするため。この操作で解析対象データをutf-8からshift-jisに変換する) - 読み込んだdataframeを
RMeCab::RMeCabDF()関数とpurrr::pmap_df()関数を組み合わせて、文書・単語・品詞ごとの頻度表を作成する(行:文書、列:単語) - 意味のないキーワード(ストップワード)を除外して、解析したい品詞の単語を文書ごとにカウントする
-
tidytext::cast_dtm()関数で、頻度表から文書単語行列(Document Term Matrix)に変換する -
topicmodels::LDA()関数でトピックモデルによる分類を行う。分類実施後、ggplot2で単語・文書の分類結果を可視化する
コード
1.テキストデータを一か所のフォルダに集める
先ほどダウンロードしたtxtファイル群をコーパスとして読み込みたいのですが、今のところ、解析したいtxtファイル群は、textフォルダの各テーマフォルダの中に入ってしまっているので、これらを一括で読み込むため、一度全txtデータをバッチ処理で別フォルダに移しました。
@echo off
dir /b /s *.txt > list.txt
for /f %%a in (list.txt) do (
copy "%%a" ..\
)
各テーマのフォルダに散っていた7368個のtxtファイルが一か所に集まりました。
all_textというフォルダに集めています。
2. tmパッケージにより、コーパスとして取り込む
これで一フォルダにtxt全データが集まったので、tmパッケージで読み込みます。
VCorpus(DirSource(dir="xxx")))で読み込むことで、全txtデータをコーパスとして取り込むことができます。
library(tm)
# encodingはtxtの文字コードに合わせて設定
corpus <- VCorpus(DirSource(dir = "C:/**/**/all_text", encoding = "utf-8"),
readerControl = list(language="eng"))
corpus
# >以下出力-------------------------------
<<VCorpus>>
Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 7368
tmパッケージによって大量のtxtデータ群をコーパスとして読み込みできました。txtの件数も一致しています。
念のため、ちゃんと読み込めているか確認します。inspect関数で概要を確認できます。
# 取り込んだ文書の1つ目を確認(dokujo-tsushin-4778030.txt)
inspect(corpus[[1]])
出力は載せませんが、上のコードで文書の中身が確認できます。
3. 可能な前処理を行う
読み込んだコーパスには、分析に不要な文字が入っていることが通常です。それらを事前に取り除いて置きます。
<各txtデータの構成例>
http://news.livedoor.・・・・
2010-05-22T14:30:00+0900
本文・・・・
今回のニュース記事には、上記のように本文の冒頭にアドレス・時間等の情報が必ず入っているため、言葉の出現確率に大きな影響を与えそうです。
また、空白/記号/数字削除やアルファベットの大文字小文字統一も必要です。
以下の前処理で、これらの処理を実施していきます。
library(magrittr)
library(stringr)
corpus %<>% tm_map(stripWhitespace)#空白の削除
corpus %<>% tm_map(content_transformer(tolower))#大文字を小文字統一
corpus %<>% tm_map(removePunctuation)#記号の削除
corpus %<>% tm_map(removeNumbers)#数字の削除
corpus %<>% tm_map(removeWords,stopwords("english"))#ストップワードの削除
英語の場合は、以上の処理で前処理がほとんど終わりなのですが、日本語の場合tmパッケージでは上手いこと不要な言葉を処理しきれません。(全角記号があったり、活用形があったり)
その辺の処理は、のちほど実施することにして、次はtidytextパッケージを使用します。
4. tidytextパッケージにより、コーパスをtibble形式に展開する
tidytextパッケージのtidy()関数は、コーパスをtibble形式に展開してくれます。
library(tidytext)
library(dplyr)
# corpusオブジェクトをtidy関数でtibbleに展開
df_1 <- tidy(corpus)
# 不要な列は削除。id/textの要素を持つオブジェクトを作っておきます
df_id <- df_1 %>% select("id", "text")
上の処理で、corpusは以下df_1のtibbleに展開されています。
df_idはdf_1からid/text列を抽出しただけです。
- df_1

- df_id

5.展開したtibbleをcsvで出力後、read.csvで再度dataframeとして読み込む
次に、先ほど作成したdf_idを一度csvファイルで出力して、改めてread.csvで読み込みます。
意味のない操作のようですが、今回読み込んでいる大元のテキストデータは文字コードがutf-8となっています。
もともとのファイルがshift-jisの場合は不要な操作ですが、RMeCabで形態素解析する場合、文字コードはshift-jisに統一しておく必要があります。
csv書き出し⇒再読み込みで強制的に文字コードをshift-jisにしてしまっています。(ほかにも方法ありそう)
df_id2 <- df_id %>% as.data.frame()#この時点では文字コードはutf-8
write.csv(df_id2, "df_id2.csv", row.names = F)
df_id3 <- read.csv("df_id2.csv", header = T)#これでdf_id3は文字コードがshift-jisとして取り込まれている
6.RMeCab::RMeCabDF()関数とpurrr::pmap_df()関数を組み合わせて、文書・単語・品詞ごとの頻度表を作成する
5までの操作で、1列目に文書(ファイル名)、2列目に文章情報を持つ文字コードshift-jisのdataframeが出来上がっています。このデータを元に形態素解析を行います。
なお今回はトピックモデルによる文書分類を行いたいので、「1行1文書1単語」の形式になったデータが必要です。
このようなデータを作成したい時、tidytext::unnest_tokens()関数が便利なのですが、英語であればきれいに形態素解析を行ってくれるのですが、日本語の場合、全角文字があったり、動詞や形容詞の活用形などがあり、上手いこと形態素解析をやり切れません。日本語を形態素解析するのであればRMeCabで行うほうがベターかと思います。RMeCab::RMeCabDF()関数とpurrr::pmap_df()関数を組み合わせて、文書・単語・品詞ごとの頻度表を作成します。
下記ページが非常に勉強になりました。
df_id4 <- df_id3 %>% RMeCabDF("text", 1)
df_id_tokens <- purrr::pmap_df(list(nv = df_id4,
title = df_id2$id),
function(nv, title){
tibble(title = title,
term = nv,
hinshi = names(nv))
})
# これで文書ごとのキーワードの品詞別リストが作成できる。1文書1単語状態かつ品詞情報が付与
# df_id_tokensは以下のようなtibbleとなっています。
tail(df_id_tokens,40)
# A tibble: 40 x 3
title term hinshi
<chr> <chr> <chr>
1 topic-news-6918105.txt の 助詞
2 topic-news-6918105.txt コメント 名詞
3 topic-news-6918105.txt の 助詞
4 topic-news-6918105.txt 通り 名詞
5 topic-news-6918105.txt 、 記号
6 topic-news-6918105.txt 濱田 名詞
7 topic-news-6918105.txt 氏 名詞
8 topic-news-6918105.txt の 助詞
9 topic-news-6918105.txt 描写 名詞
10 topic-news-6918105.txt を 助詞
# ... with 30 more rows
7.意味のないキーワード(ストップワード)を除外して、解析したい品詞の単語を文書ごとにカウント
ここまでで、作成したdf_id_tokensは文書・単語・品詞情報を持つtibble形式のデータとなっています。
ストップワードの除去、解析したい単語のカウントを行い、さらにデータを整理していきます。
日本語のストップワードってどこかにまとまっていないかな・・・と、探したところ、ありました!
こちらのストップワードに、単体のアルファベットや明らかな不要ワードをいくつか追加して、stop_wordとして取り込み使用することにしました。
# ストップワードの読み込み
stop_word <- read.csv("jpn_stopword.csv", header = T, fileEncoding = "UTF-8-BOM")
stop_word$term <- as.character(stop_word$term)
# stopword削除、品詞を名詞と形容詞に限定、絞り込んだ単語をカウント
df_id_tokens %<>% anti_join(stop_word, by="term") %>% filter(hinshi %in% c("名詞","形容詞")) %>%
group_by(title,term) %>% summarise(count=n()) %>% ungroup()
tail(df_id_tokens,40)
# A tibble: 40 x 3
title term count
<chr> <chr> <int>
1 topic-news-6918105.txt 作者 1
2 topic-news-6918105.txt 作品 3
3 topic-news-6918105.txt 散見 1
4 topic-news-6918105.txt 残念 2
5 topic-news-6918105.txt 氏 2
6 topic-news-6918105.txt 主人公 1
7 topic-news-6918105.txt 終了 4
8 topic-news-6918105.txt 週刊 2
9 topic-news-6918105.txt 集英社 1
10 topic-news-6918105.txt 重視 1
# ... with 30 more rows
8.tidytext::cast_dtm()関数で、頻度表から文書単語行列(Document Term Matrix)に変換する
先ほどのdf_id_tokensをさらに加工していきます。現状、文書・単語の頻度表になっていますが、この後tidytext::LDA()関数でトピックモデルによる解析を行うにあたり、データ形式をDTM(Document Term Matrix)に変換しておく必要があります。頻度表からDTMの作成に当たっては、tidytext::cast_dtm()関数を使用します。
イメージとしては、DTMは以下のような形です。
|id|単語1|単語2|・・・|単語n|
|---|:---|:---|:---|:---|:---|
|文書1|1|0|・・・|0|
|文書2|0|1|・・・|1|
|:|:|:|・・・|:|
|文書m|0|1|・・・|0|
DTM_id <- cast_dtm(df_id_tokens, document = "title", term = "term", value = "count")
これで解析にかけるためのデータの準備が整いました。
9.topicmodels::LDA()関数でトピックモデルによる分類を行う。分類実施後、ggplot2で単語・文書の分類結果を可視化する
単語ごとのトピック
先ほど作成したDTM_idをtopicmodels::LDA()関数に放り込んで解析にかけてみます。
指定するトピック数は、最初の分類数に合わせて9を指定してみます。
library(topicmodels)
# kはトピックをいくつに振り分けるかを決める引数。9分類で設定してみる。
topic_id <- LDA(DTM_id, k = 9)
# LDA関数で解析後、tidy関数にかけることで、解析結果(単語ごとのトピック分類)をtibble⇒dataframe化できる
topic_id_2 <- topic_id %>% tidy() %>% as.data.frame()
head(topic_id_2,40)
topic term beta
1 1 6月 8.074811e-05
2 2 6月 3.462118e-05
3 3 6月 1.468245e-13
4 4 6月 5.099869e-12
5 5 6月 1.038670e-05
6 6 6月 1.774455e-07
7 7 6月 1.650989e-05
8 8 6月 2.377170e-05
9 9 6月 3.165368e-21
10 1 あれこれ 7.990530e-05
11 2 あれこれ 1.082210e-04
12 3 あれこれ 1.262849e-05
13 4 あれこれ 5.686734e-24
14 5 あれこれ 3.250061e-24
15 6 あれこれ 2.680373e-21
16 7 あれこれ 3.819399e-05
17 8 あれこれ 3.475295e-06
18 9 あれこれ 4.022147e-17
19 1 いい 3.394916e-03
20 2 いい 8.413145e-03
21 3 いい 4.019415e-03
22 4 いい 7.586816e-04
23 5 いい 8.420638e-04
24 6 いい 2.709541e-04
25 7 いい 8.694297e-04
26 8 いい 1.276097e-03
27 9 いい 6.937953e-04
28 1 インターネット 1.239272e-04
29 2 インターネット 1.060997e-03
30 3 インターネット 1.808337e-04
31 4 インターネット 1.504355e-05
32 5 インターネット 1.412649e-05
33 6 インターネット 3.225929e-04
34 7 インターネット 1.675844e-03
35 8 インターネット 4.165411e-04
36 9 インターネット 3.011798e-04
37 1 お願い 1.291281e-04
38 2 お願い 4.381324e-04
39 3 お願い 1.667731e-04
40 4 お願い 1.665965e-04
単語ごとにtopicが1~9に振り分けられていることが分かります。
betaは数字がtopicへの出現確率を示しています。数字が大きいほどそのtopicに関連が深いということですね。
だいぶ情報が整理されてきました。
次は、ggplot2で単語ごとの出現確率を可視化してみたいと思います。
library(ggplot2)
# トピックに関連の深い単語トップ20を取り出し並び替え
topic_id_3 <- group_by(topic_id_2,topic) %>% top_n(20,beta) %>% ungroup() %>%
mutate(term=reorder(term,beta)) %>% arrange(topic,-beta)
# トピックの数値が降順で並ぶようfactor調整、ラベル書き換え
topic_id_3 %>% mutate(term=reorder(term,beta)) %>%
group_by(topic,term) %>%
arrange(desc(beta)) %>%
ungroup() %>%
mutate(term=factor(paste(term,topic,sep="_"),
levels=rev(paste(term,topic,sep="_")))) %>%
ggplot(aes(x=term,y=beta,fill=beta))+
geom_bar(stat="identity")+
facet_wrap(~topic,scales = "free")+
coord_flip()+
scale_x_discrete(labels = function(x)gsub("_.+$","",x))
 それらしくまとまりました。
各トピックはどのような話題が多かったのか、その傾向から元のカテゴリが推測できるか見てみます。
それらしくまとまりました。
各トピックはどのような話題が多かったのか、その傾向から元のカテゴリが推測できるか見てみます。
- 女性の美容に関する話題?
- 女性の恋愛・結婚に関する話題?
- 国、試合、サッカーなど、スポーツの話題?
- 映画、作品、女優などエンタメにかかわる話題?
- 4と似ている?
- 家電に関する話題?
- ソフトウェア、更新などITにかかわる話題?
- アプリ、iphone、androidなど、携帯端末にかかわる話題?
- 応募、プレゼントなど、懸賞などの話題でしょうか。
何となくですが、各トピックごとに話題の傾向が見える気がします。
文書ごとのトピック
最後に、これらの推測があっているのか、確かめてみます。
LDA()関数で解析した結果をtidy()関数でdataframeに展開する際、tidyのmatrix引数に"gamma"を指定すると、単語ごとではなく文書のトピック分類が確認できます。
# matrixに"gamma"指定で文書ごとのトピックのdataframeになる
topic_id_gamma <- topic_id %>% tidy(matrix = "gamma") %>% as.data.frame()
# 可視化
library(ggplot2)
topic_id_gamma2 <- group_by(topic_id_gamma,topic) %>% top_n(20,gamma) %>% ungroup() %>%
mutate(document=reorder(document,gamma)) %>% arrange(topic,-gamma)
ggplot(topic_id_gamma2,aes(x=document,y=gamma,fill=gamma))+
geom_bar(stat="identity")+
facet_wrap(~topic,scales = "free")+
coord_flip()
 各トピックのトップ20文書のみしか可視化してませんが、実際は全文書のトピック割合がdataframe化できています。
振り分けが確認できました。
各トピックのトップ20文書のみしか可視化してませんが、実際は全文書のトピック割合がdataframe化できています。
振り分けが確認できました。
- peachyが多い。美容に関する話題が中心のニュースでまとまっています。
- livedoor-hommeが多い。ファッションに関する話題が中心のニュースでまとまっています。
- スポーツに関する話題が中心のニュースでまとまっています。
- ムービー、エンタメにかかわる話題が中心のニュースでまとまっています。
- エンタメとライフハックが混じってますね。
- 6-8はsmax、アプリとかIT系の話題がおおいですね。
- 同上
- 同上
- これもPeachy?
もう少し解釈してみるために、documentから発番を消去して、カテゴリ毎のtopicの数値の平均値を比較してみることにします。
# 正規表現で発番を削除してカテゴリを作って可視化してみる
topic_id_gamma$document %<>% str_remove_all("-\\d{7}.txt")
topic_id_gamma_cat <- topic_id_gamma %>% group_by(document,topic) %>%
summarise(mean = mean(gamma)) %>%
ggplot(aes(x=topic,y=mean,fill=as.factor(topic)))+
geom_bar(stat="identity")+
facet_wrap(~document)+
scale_x_continuous(breaks = seq(1,9,by=1),labels=c(1,2,3,4,5,6,7,8,9))
topic_id_gamma_cat
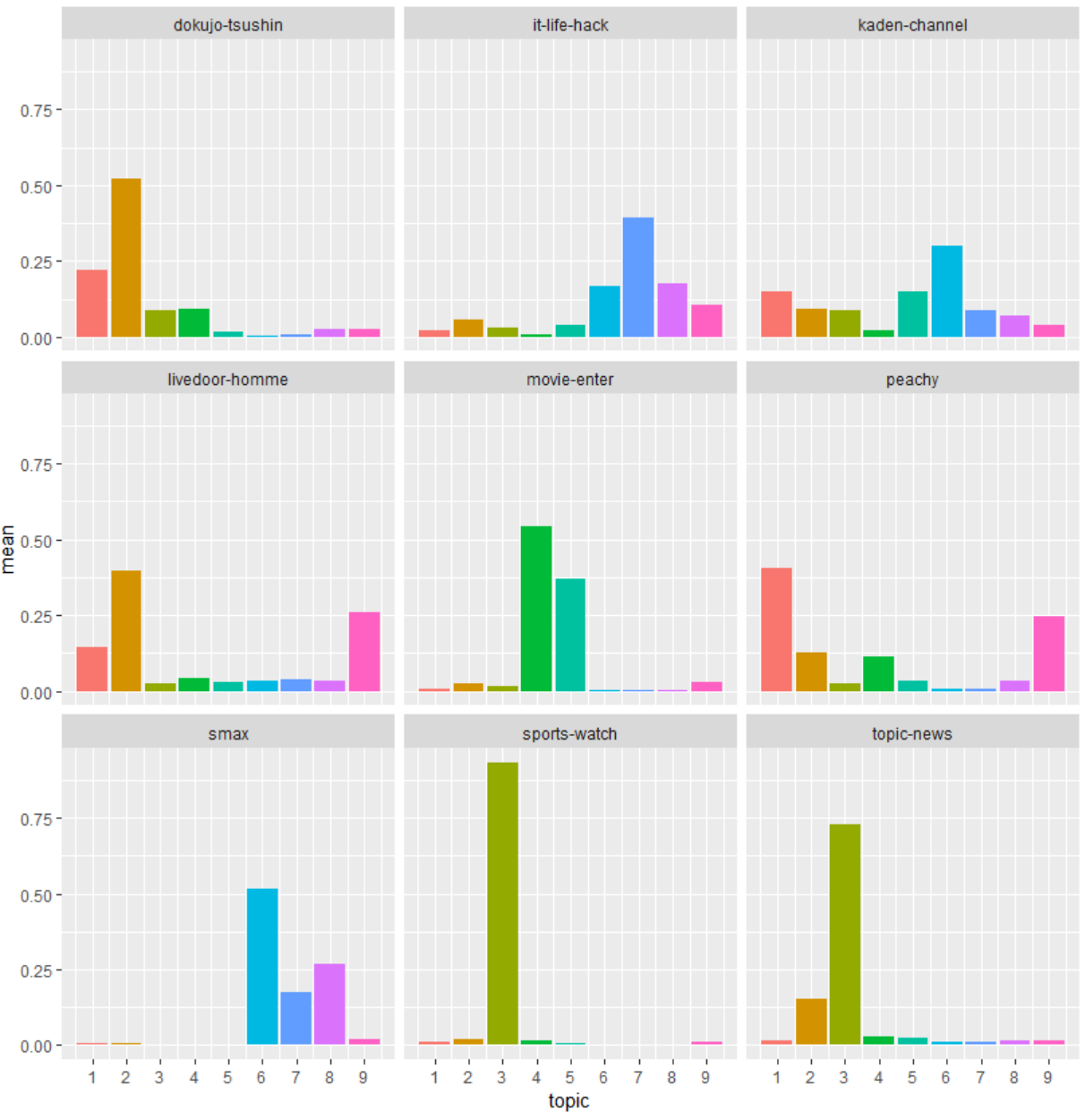
独女通信とlivedoor-homme(ファッション関連)がともに、トピック2が最大ですね。
女性の話題が多いということで同じトピックが集中しているのでしょうか。
トピックニュースとスポーツもトピック3が最大になっています。
smaxと家電チャンネルはトピック6が最大です。
どれも何となく似たような話題になりそうな気はします。
もともとカテゴリに振り分けられているものの、違うカテゴリでも似た文章があってこの結果になっている可能性はあります。
seed変更したり、topic数変更したり、いろいろいじればもう少し確認範囲広げれば別の見解も得られそうですが、ほぼ追加設定なし、デフォルトの操作でここまで分類できるとは面白いです。
今回は、もともと分類されている文書で試していますが、会社とかの整理されていない文書を解析にかけて分類して、テーブル作成検索性向上!なんてのも面白そうです。
最後に
ひたすらデータ操作に終始した、とりとめのない投稿になってしまいましたが非常に難しい処理をしているはずなのに、こんなに短いコードで可視化までたどり着けてしまうのは、Rの威力、パッケージ様様です。
引き続き精進あるのみですね!
参考にした本
「Rによるテキストマイニング入門」森北出版
「Rによるテキストマイニング―tidytextを活用したデータ分析と可視化の基礎」オライリージャパン