何となくAWSでクラウド設計をしていませんか
AWSを利用する際、多くの方が「設計」というプロセスを簡単に飛ばしてしまう傾向にあります。しかし、クラウド環境の効果的な活用には、適切なアーキテクチャ設計が不可欠です。世の中には、システム設計をする上で指針となる設計原則がいくつかあります。本記事では、以下の3つをピックアップをしてご紹介します。
本記事で取り扱う内容
■ マイクロサービスアーキテクチャ
■ AWS Well-Architected Framework
■ The Twelve-Factor App
1. マイクロサービスアーキテクチャ
マイクロサービスは、独立した小さなサービス群でソフトウェアを構築するアーキテクチャです。これにより、迅速なイノベーションと新機能の迅速な展開が可能となります。一方、モノリシックアーキテクチャは、全てが一つのサービスとして結合され、変更や障害が全体に影響を及ぼしやすいです。マイクロサービスは独立して動作するため、各サービスのアップデートやスケールが容易です。特徴として、自律性、特殊化、俊敏性、スケーリングの柔軟性、容易なデプロイ、技術的自由、コードの再利用、耐障害性が挙げられます。
マイクロサービスの概要に関しては以下の記事が非常にわかりやすくシンプルにまとめられているので、ぜひ読んで頂くのがベストです。なお、本記事ではマイクロサービス支えるアーキテクチャ・技術をAWSのリソースに絞って紹介します。
(1)API Gateway パターン
API ゲートウェイパターンは、大規模なマイクロサービスアプリケーションの設計に適しており、リバースプロキシとして機能し、クライアントに一つのエンドポイントを提供します。このパターンは内部のサービスを抽象化し、リクエストとレスポンスの変換や権限確認などの追加機能を持ちます。
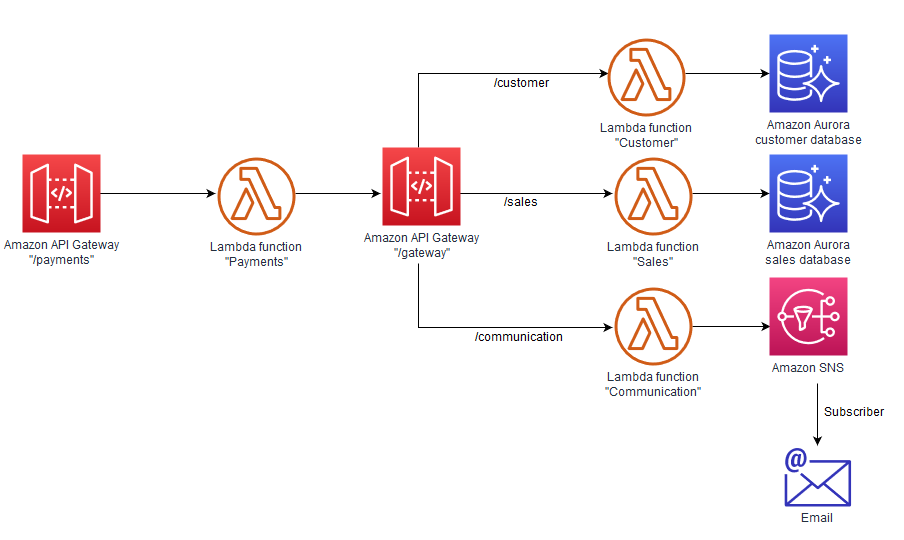
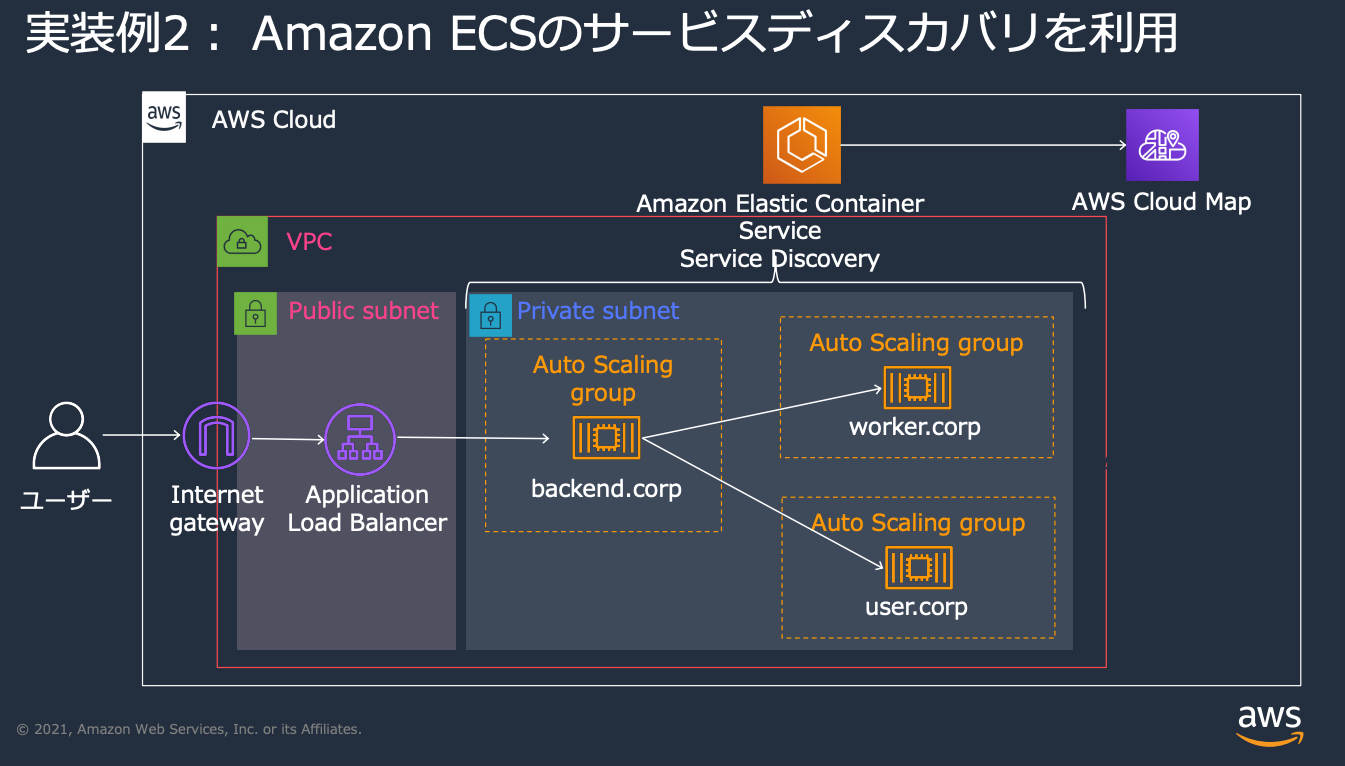
(2)サービスディスカバリパターン
サービスが動的に検出・登録されることで、システムの耐障害性とスケーラビリティが向上します。AWSのRoute53やCloud Mapを利用することで、サービスの位置情報を自動的に見つけ出し、適切にルーティングすることが可能になります。
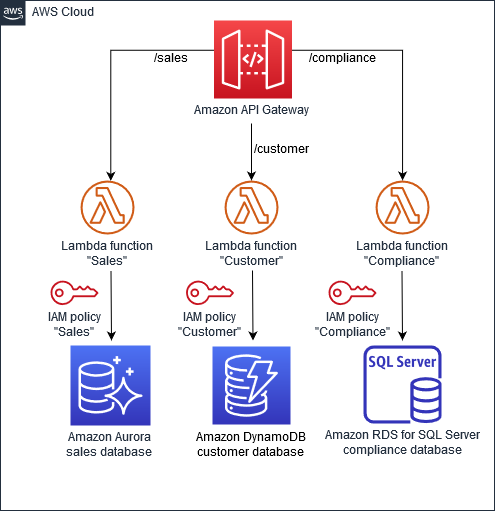
(3)データストアの分離
マイクロサービスアーキテクチャでは、各サービスは独自のデータストアを持ち、他のマイクロサービスの影響を受けずにデータを格納・取得します。これにより、アプリケーションの耐障害性が向上します。AWSの環境では、異なるマイクロサービスがAmazon Aurora、DynamoDB、RDSなどの適切なデータベースを使用し、API GatewayやIAMを通じてセキュアにアクセス管理されます。
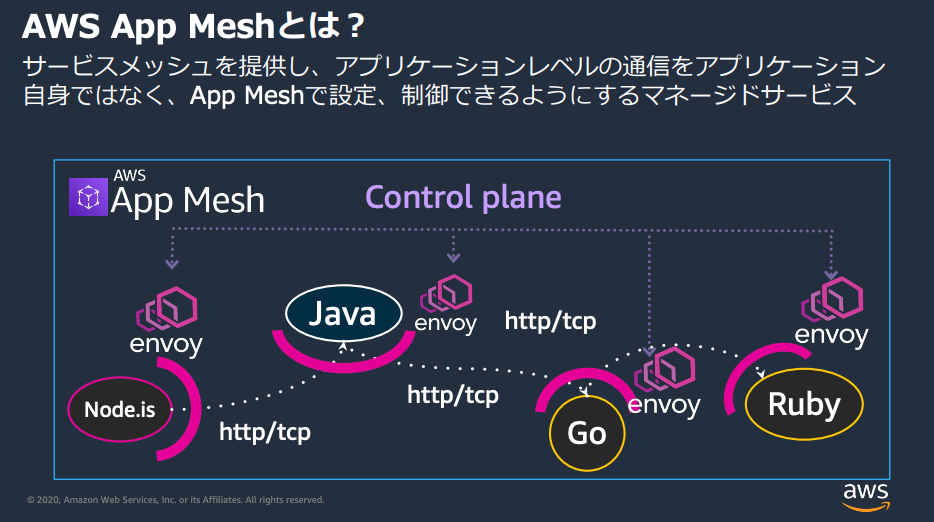
(4)サービスメッシュ
マイクロサービスアーキテクチャでは、アプリケーションを独立した小さなソフトウェア群に分割し、各部分が独立してスケールし、APIを通じて相互に作用します。しかし、アプリケーション内のマイクロサービスが増えると、問題の特定やトラフィックのルーティングが難しくなるという問題があります。これに対応するためのツールは導入や管理が複雑です。AWS App Meshはこれらの課題を解決し、マイクロサービス間の通信をproxyを通じて一元的に管理・モニタリングする方法を提供します。
(5)イベント駆動アーキテクチャ
AWSを使用してマイクロサービスを構築する際、イベント駆動アーキテクチャを採用することで、システム全体の反応性と拡張性を向上させることができます。具体的には、SQSを用いてイベントメッセージをキューイングし、Lambdaで非同期にメッセージを処理することで、各サービスが独立してスケールし、迅速に応答する仕組みを実現します。
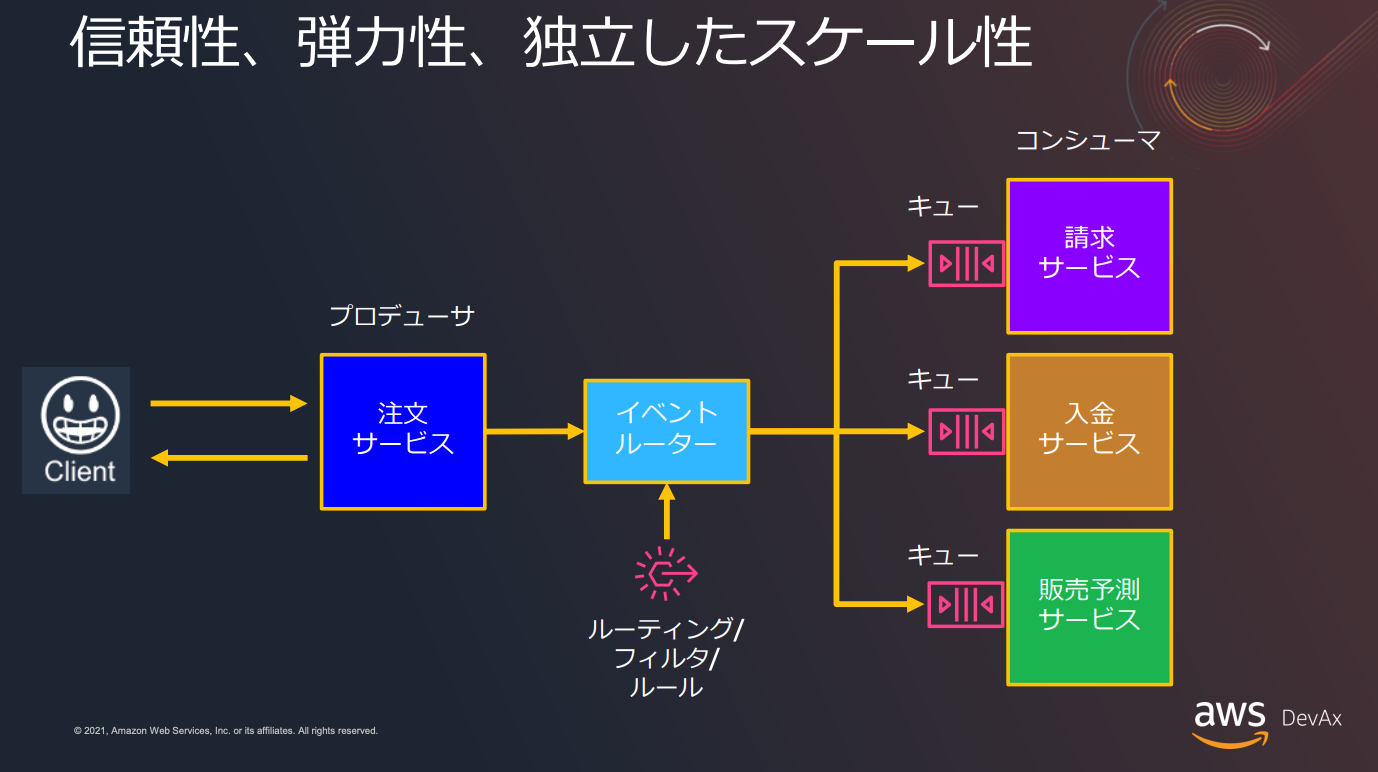
以下の記事も参考になると思うのでぜひご覧ください。
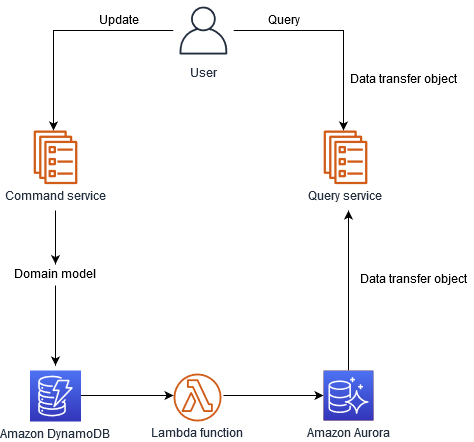
(6)CQRS
コマンドクエリ責任分離 (CQRS) パターンは、データの更新と取得を分離する設計手法です。システムがコマンド部分でデータを変更し、クエリ部分でデータを参照します。DynamoDBは高い書き込みスケーラビリティを持ち、Auroraは複雑なクエリに適しています。DynamoDB ストリームを使い、Lambda 関数でAuroraを更新することができます。
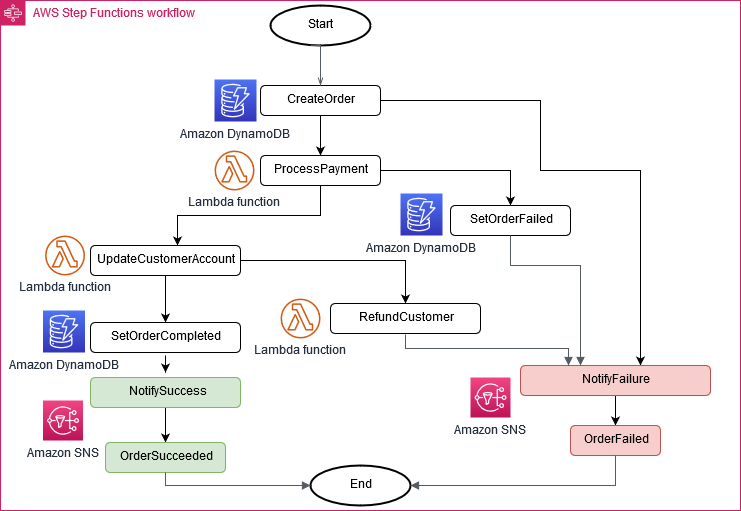
(7)サーガパターン
このパターンは、分散アプリケーションの一貫性を確立し、複数のマイクロサービス間のトランザクションを調整してデータの一貫性を維持するのに役立つ障害管理パターンです。マイクロサービスはトランザクションごとにイベントを公開し、イベントの結果に基づいて次のトランザクションが開始されます。トランザクションの成功または失敗によって、2 つの異なる経路をたどることができます。
2. The Twelve-Factor App
The Twelve-Aactor App と呼ばれる方法論は、モダンでスケーラブル、かつメンテナンス性に優れた Software-as-a-Service アプリケーションの構築に役立ちます。この方法論はテクノロジーにとらわれず、クラウドネイティブアプリケーションを開発するためのアプローチとして広く採用されています。
以下の記事では、Amazon ECSのFargate起動タイプを使用して開発されたサンプルソリューションを通じて、この方法論の要点を説明しています。
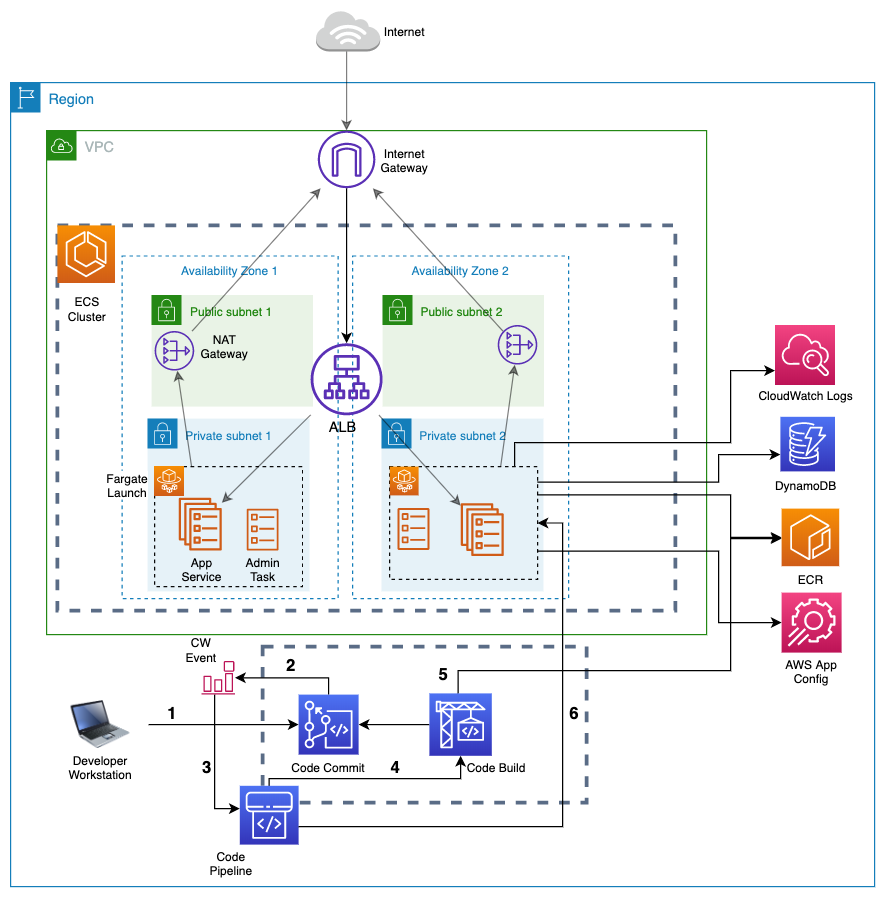
(1)コードベース (Codebase)
アプリケーション毎に一つのコードベースをソースコントロールシステム(例:Git)で管理する。各コンテナアプリは独立したリポジトリで格納される必要があり、例としてAWS CodeCommitが使用される。
(2)依存関係 (Dependencies)
アプリケーションの依存関係は明確に宣言され、実行環境からは独立しているべき。Dockerfileを用いてコンテナイメージの指示をまとめ、依存関係をパッケージシステムで管理する。例:PythonのPipでboto3やFlaskをインストール。
(3)設定 (Config)
構成はコードから完全に分離されるべきで、アプリケーションのコードはどの環境でも同じでなければならない。設定は環境変数で提供され、ECSではコンテナ定義内で指定可能。
(4)バックエンドサービス (Backing services)
アプリケーションは、RDSやDynamoDBのようなサービスをアタッチされたリソースとして扱い、その構成を理解するが緊密に依存しない。例えば、DynamoDBのテーブル名をAppConfigから取得し、ダウンタイムなしに切り替えることで、異なるデータセットでのA/Bテストも実現できる。
(5)ビルド、リリース、実行 (Build, release and run)
AWS CodePipelineでビルド、リリース、実行を分離。アプリコードをパッケージ化、例: Dockerイメージ。構成はランタイムで供給、ECSとFargateでデプロイ。
(6)プロセス (Processes)
アプリはステートレスなプロセスとして構築。状態はバッキングストアに持続。このソリューションでは、PythonアプリケーションがAPIエンドポイントを提供。
(7)ポートバインディング (Port binding)
アプリは実行環境のポートにバインド。コンテナはDockerfileでポート公開。Fargateではawsvpcネットワークモードを使用し、サンプルではポート80にバインド。
(8)並行性 (Concurrency)
ECS サービスはアプリ負荷に応じてタスク数を調整。失敗タスクは自動再起動し、スケールニーズに適応。
(9)廃棄容易性 (Disposability)
コンテナは高速起動、グレースフルシャットダウン。ECS はタスク停止時にシグナル処理を行う。
(10)開発/本番一致 (Dev/prod parity)
本番・非本番環境を同様に。Dockerイメージ共通利用。ステージングクラスタでのテストと承認後に本番デプロイ。
(11)ログ (Logs)
ログはイベント流れとして。ECSでstdout, stderrをCloudWatch Logsへ。FireLensで複数サービスへログルーティング。
(12)管理プロセス (Admin processes)
管理タスクはアプリと同環境で。ECSのスケジューリングで管理機能を実行。サンプルはDynamoDBバックアップタスク。
3. AWS Well-Architected Framework
AWS Well-Architectedフレームワークは、AWS社が公式に公開しているAWSを使ったシステム設計の基本指針となります。同社のサービスを用いてシステムを設計する際に、どのような観点を気をつければ、安全で信頼性が高く、効率的で、費用対効果が高く、持続可能なワークロードを構築することができるかが公開されています。
AWS ソリューションアーキテクトは、さまざまな業種やユースケースに対応したソリューションのアーキテクトとして長年の経験を持っています。これまで何千ものお客様の AWS でのアーキテクチャの設計とレビューをお手伝いしてきました。その経験に基づいて、クラウド対応システムを設計するための核となる戦略とベストプラクティスを確立しました。
上記のように、AWS社が長年培ったノウハウを元に作成された設計原則・指針であり、現在では合計6つの項目によって構成されています。
(1)運用上の優秀性
クラウド環境と運用をコード化して効率を向上し、小規模で可逆的な更新を行います。運用手順は定期的に見直され、障害対応の手順を検証します。障害時には、教訓を共有し改善を図ります。
具体例
- AWS Organizations: アカウント間で環境を一元管理できるツールやサービスを使用
- AWS CloudFormation: インフラストラクチャをコードとして管理し、再現可能な環境を提供。
- Amazon CloudWatch: システムの監視やログ収集を通じて、運用上の問題を早期に検知。
(2)セキュリティ
AWSセキュリティの原則として、強固なアイデンティティ管理と最小特権の原則があります。また、全レイヤーでのセキュリティ適用、リアルタイムの監視とトレーサビリティを行い、データの保護と暗号化を適切に行います。そして、危機察知・及び迅速なインシデント対応が重要です。
具体例
-
Amazon IAM (Identity and Access Management): ユーザーやサービスのアクセス権限を詳細に制御し、最小特権の原則に基づいた権限の付与や役割の管理を行います。
-
Amazon GuardDuty: 継続的な脅威検知サービスを利用して、不正なアクティビティや潜在的な危険な行動を検出し、リアルタイムのセキュリティ監視を強化します。
-
AWS Key Management Service (KMS): 保存データや通信中のデータの暗号化キーをセキュアに管理し、データの保護とアクセスのコントロールを強化します。
(3)信頼性
ワークロードのKPIをモニタリングして障害時には自動復旧を行います。クラウドの特性を活かし、障害シミュレーションと復旧手順のテストを行うことも可能です。コンテナリソースを用いることで水平にスケールし、全体の可用性を強化できます。クラウドのキャパシティは実際の需要に応じて調整され、予測の必要ありません。変更はオートメーションを通じて一貫して管理していきます。
具体例
- Amazon CloudWatch Alarms: KPIの監視に使用し、特定のしきい値を超えた際にアラートを生成してオートメーションをトリガーします。これにより、障害時の迅速な対応をサポートします。
- Amazon EC2 Auto Scaling: 水平方向のスケーリングをサポートし、ワークロード全体の可用性を向上させるために、単一の障害が全体の影響を最小限にするように小規模なリソースに自動的に調整します。
- AWS Lambda: 障害発生時や特定のトリガーに基づいて、自動的な復旧処理や修正スクリプトを実行します。これにより、システムの自動復旧を実現します。
(4)パフォーマンス効率
最新の技術を簡単に活用し、世界中に迅速に展開するサービスを活用します。さらに、サーバーレスアーキテクチャの導入により運用の負担が減少し、仮想リソースを使って頻繁に実験を行うことも可能です。また、各ワークロードの目標に応じて最適な技術を選択することが重要です。
具体例
-
Amazon RDS: 最新のデータベース技術を容易に導入し、データベースの管理タスクをAWSに委託することで、開発チームはアプリケーションの機能に集中できます。
-
Amazon CloudFront: グローバルに分散したエッジロケーションを通じてコンテンツを配信することで、低レイテンシーでのユーザーエクスペリエンスを実現します。
-
AWS Lambda: サーバーレスのコンピューティングサービスであり、コードの実行のみに焦点を当て、インフラの管理やプロビジョニングの手間を排除します。
(5)コスト最適化
クラウドのコスト最適化の5つの原則は、クラウド財務管理の実装、消費モデルの採用、ワークロードの効率測定、データセンター作業の簡素化、および費用分析と帰属明確化にあります。財務管理でビジネス価値を追求し、消費モデルで必要分のみの支払いを行う。ワークロードの効果とコストを結びつけ、重作業はAWSに委託し、コスト明確化でROIの可視化を実現します。
具体例
-
Amazon CloudWatch Alarms: これは「ワークロードの効率測定」の具体例として適しています。特定のKPIを監視して、目標とする効率が達成されているかを確認します。目標を下回った場合や特定のしきい値を超えた場合にアラートを生成することで、迅速な対応をサポートし、コスト効率を最適化します。
-
Amazon EC2 Auto Scaling: これは「消費モデルの採用」に関連する具体例です。使用量に基づいてリソースを自動的にスケールアップまたはスケールダウンすることで、必要なリソースのみを利用し、余分なコストを発生させることなくサービスの可用性を確保します。
-
AWS Lambda: 「データセンター作業の簡素化」の具体例として考えることができます。サーバーレスのコンピューティングモデルを採用することで、サーバーの運用やメンテナンスの手間を省き、特定のイベントやトリガーに基づいて必要な処理やスクリプトを実行します。これにより、ITインフラの管理にかかるコストと手間を最適化し、より重要なビジネス活動に集中することができます。
(6)サステナビリティ
クラウドの持続可能性には6つの原則があります。まず、クラウドワークロードの影響を計測し、KPIを作成して生産性を最適化します。次に、持続可能性の長期目標を設定し、それをサポートするリソースを確保します。使用率を最大化するために効率的なハードウェアやソフトウェアの採用、マネージドサービスの利用、および顧客の影響を最小限に抑える方法を採用して、全体的な影響を最小限に抑えます。
具体例
-
リージョン選択: Amazon の再生可能エネルギープロジェクトに近いリージョンであり、グリッドの公開されている炭素集約度が他の場所 (またはリージョン) よりも低いリージョンを選択します。
-
ハードウェア選択: 最小量のハードウェアを使用してニーズを満たす: クラウドの能力を使用して、ワークロードの実装を頻繁に変更できます。ニーズの変化に応じて、デプロイされたコンポーネントを更新します。
-
GPUの使用を最適化する: グラフィック処理ユニット (GPU) は高い電力消費のソースになることがあります。GPU インスタンスは必要な時間だけ実行し、必要がないときはオートメーションで廃棄して、消費されるリソースを最小化します。