お題
有名なお題であるkaggleの「House Price」問題にみんなでチャレンジしていくことになったハンズオンの内容をメモしていく企画の第7回。解説というよりはメモのまとめだったりもしますが、どこかの誰かのためになれば幸いです。前回で準備がおわり、いよいよ解析段階に。
- 元々のお題:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
- 参考にした記事:https://yolo-kiyoshi.com/2018/12/17/post-1003/
本日の作業
予測モデルの構築
# マージデータを学習データとテストデータに分割
train_ = all_data[all_data['WhatIsData']=='Train'].drop(['WhatIsData','Id'], axis=1).reset_index(drop=True)
test_ = all_data[all_data['WhatIsData']=='Test'].drop(['WhatIsData','SalePrice'], axis=1).reset_index(drop=True)
# 学習データ内の分割
train_x = train_.drop('SalePrice',axis=1)
train_y = np.log(train_['SalePrice'])
# テストデータ内の分割
test_id = test_['Id']
test_data = test_.drop('Id',axis=1)
マージデータを学習データとテストデータに分割
trainの方で確認します。
all_data[all_data['WhatIsData']=='Train'].drop(['WhatIsData','Id'], axis=1).reset_index(drop=True)
まずはall_data[all_data['WhatIsData']=='Train']の中身を確認。all_data内のTrainだけをとってくるわけです。
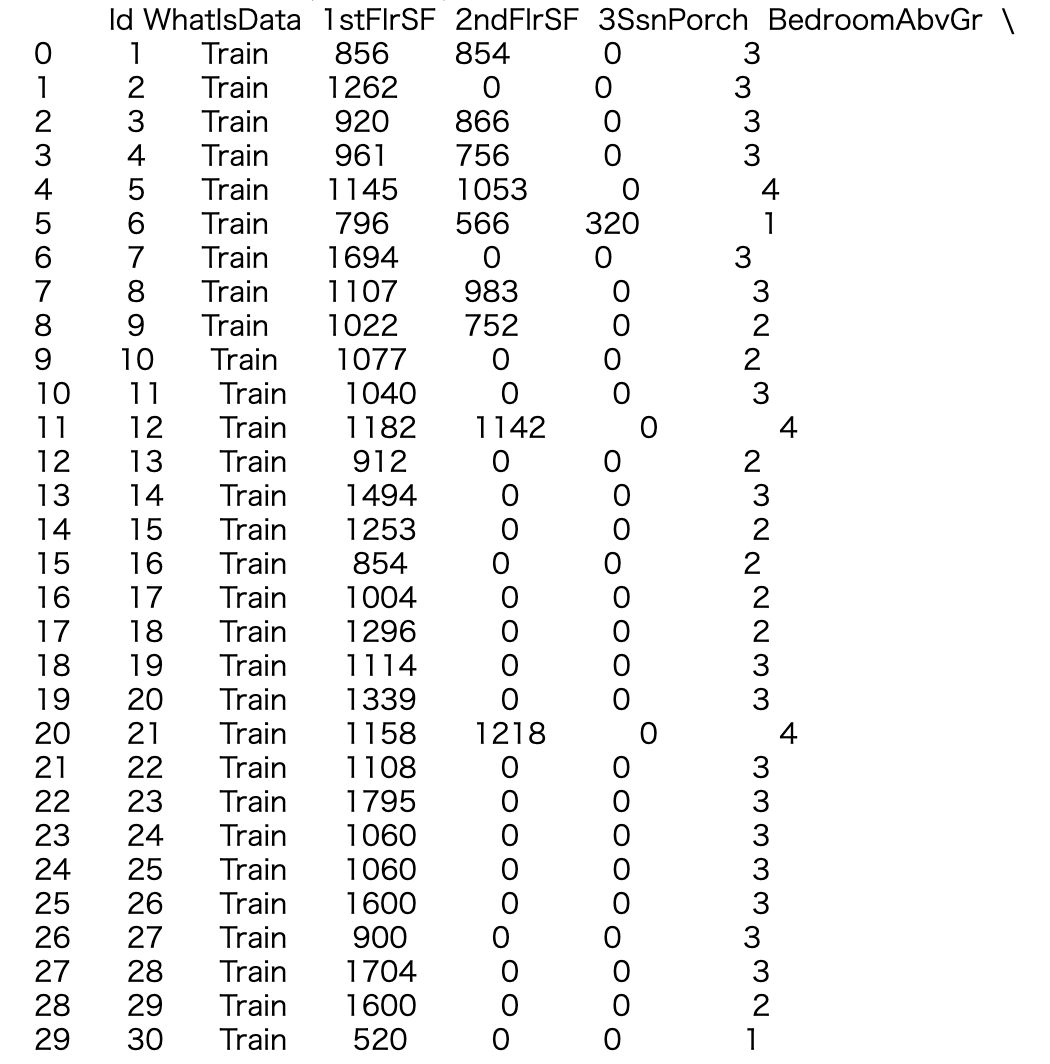
all_data[all_data['WhatIsData']=='Train'].drop(['WhatIsData','Id'], axis=1)の中身確認WhatIsData, Idを列から落とす。
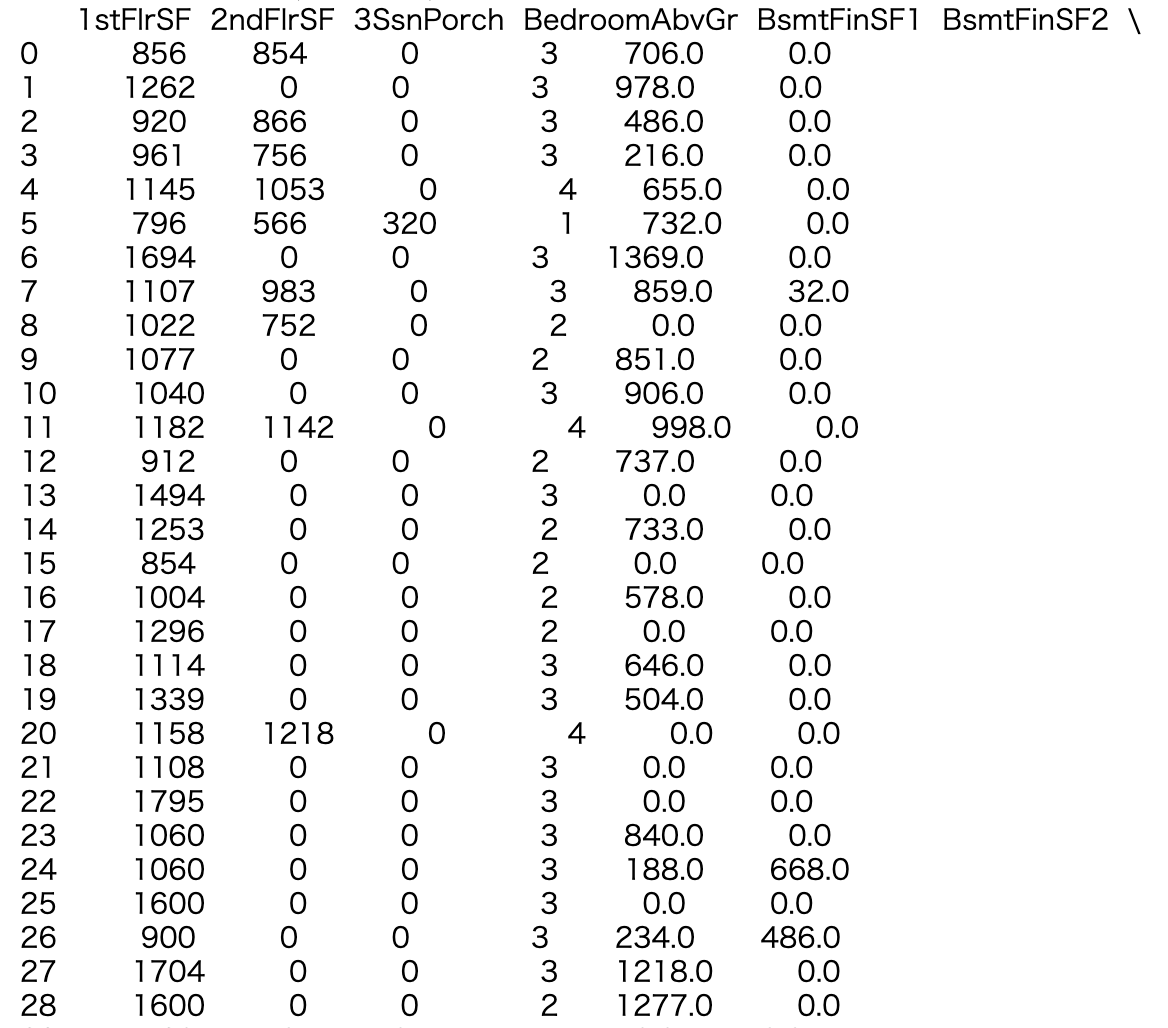
all_data[all_data['WhatIsData']=='Train'].drop(['WhatIsData','Id'], axis=1)の中身確認。indexをリセット(キャプチャ画像だと一切替わって見えねえ…)
(ちなみに、trainもtestも、以前配列をわざわざ作ったような。。。そこらへんの全体像をもっかいおさらいする必要があるなと思いました)
学習データ内の分割
train_x = train_.drop('SalePrice',axis=1)
train_y = np.log(train_['SalePrice'])
train_x = train_.drop('SalePrice',axis=1)で、SalePrice以外のカラムを説明変数にするわけですね。
train_y = np.log(train_['SalePrice'])で、目的変数を用意。(前回の対数変換をお忘れなく)
テストデータ内の分割
test_id = test_['Id']
test_data = test_.drop('Id',axis=1)
もはや見たままか。。。流石にここはtest_id, test_dataそれぞれの確認は省略します。
予測モデルの構築
に、入ろうと思ったんですが、いかんせんわからないことがもりもりになってきたので、入らずに準備に徹します。主に単語調べ。
StandardScaler() #スケーリング
- スケール変換について:https://aizine.ai/preprocessing0614/
- Scikit-learnのスケール変換クラスについて:https://helve-python.hatenablog.jp/entry/scikitlearn-scale-conversion
[0.001, 0.01, 0.1, 1.0, 10.0,100.0,1000.0] #パラメータグリッド
make_pipeline(scaler, ls) #パイプライン生成
おしまい。
この宿題をまずは全部読み込みをするところからか。
思ったこと言っていいですかね。「そろそろ終盤」とか思ってましたが、ここまでやってたこと全部前処理だったという。