お題
第1回の内容はこちら
有名なお題であるkaggleの「House Price」問題にみんなでチャレンジしていくことになったハンズオンの内容をメモしていく企画の第2回。解説というよりはメモのまとめだったりもしますが、どこかの誰かのためになれば幸いです。
- 元々のお題:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
- 参考にした記事:https://yolo-kiyoshi.com/2018/12/17/post-1003/
本日の作業
欠損値の確認(補完までいけなかった)
結論、結構欠損値はあるらしい。
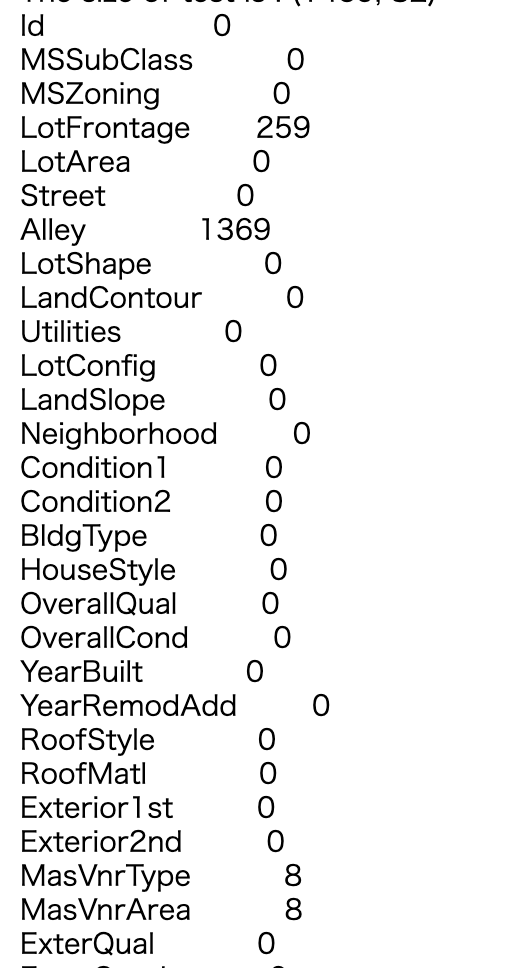
学習データの欠損状況(欠損値)
train.isnull().sum()[train.isnull().sum()>0].sort_values(ascending=False)
欠損値
データファイルを準備する場合には,データが欠落している場合でもなんらかの数値を入力しておかなければならない。ただし,入力される数値は実際にはデータがなかったことを表しているので,分析対象からはずす必要がある。そのため,他の有効なデータと明らかに区別できる値(欠損値)を入力する。
.isnull()
- .isnull():要素ごとにtrue, falseで値が入っているかどうかを確認してくれるわけだ。
- 参考:https://note.nkmk.me/python-pandas-nan-judge-count/
- train.isnull()だけで結果を出力した場合
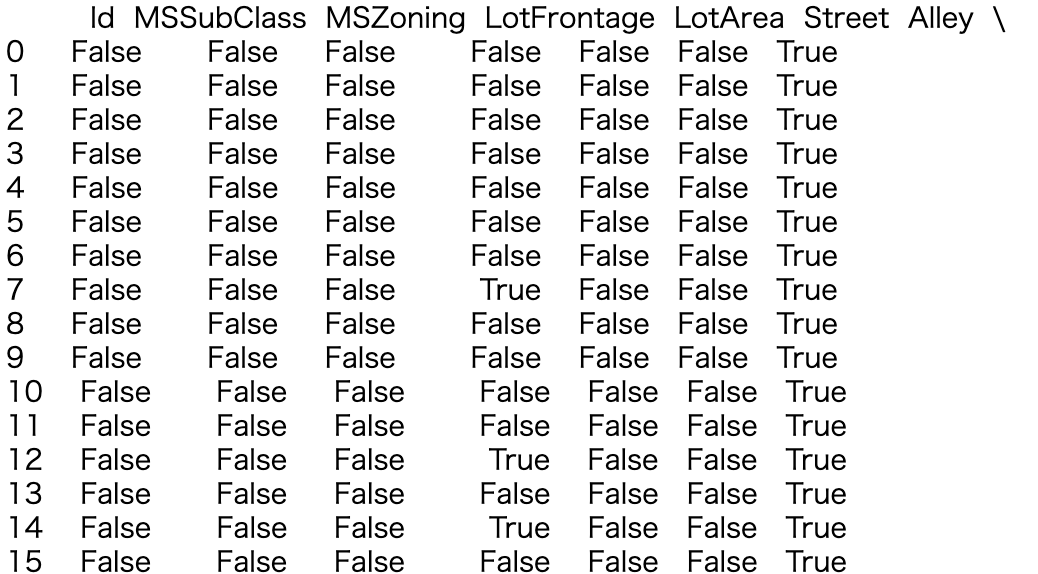
.sum()
-
.sum():おなじみ足し算をしてくれる。引数の指定で縦方向にも横方向にも足し算してくれる。
-
train.isnull().sum()だけで結果を出力した場合
-
[train.isnull().sum()>0]:欠損している項目がある列だけをキーに指定して並べる感じ。
-
train.isnull().sum()[train.isnull().sum()>0]だけで結果を出力した場合

.sort_values()
- .sort_values(ascending=False):データソート。ここでは降順にする引数しか指定してないけど、ソートする項目を選んだりとか、アルゴリズム変えたりとかできるらしい。便利。
- 参考:https://deepage.net/features/pandas-sort-values.html
- train.isnull().sum()[train.isnull().sum()>0].sort_values(ascending=False)だけで表示

テストデータの欠損状況
解説は学習データと同じなので割愛します。
test.isnull().sum()[test.isnull().sum()>0].sort_values(ascending=False)
学習データの欠損状況(データ型)
.index.tolist()
# 欠損を含むカラムのデータ型を確認
na_col_list = alldata.isnull().sum()[alldata.isnull().sum()>0].index.tolist() # 欠損を含むカラムをリスト化
alldata[na_col_list].dtypes.sort_values() #データ型
-
alldata.isnull().sum()[alldata.isnull().sum()>0]までの内容は、欠損値を並べるところまででやったので割愛。 - .index:あれこれ
index()とちがうん?って思ったけど、違うらしい。 - .tolist():カラムだけリストにするのに再度これを使っていた。(ちょっと理解があいまい)
- 参考:https://note.nkmk.me/python-pandas-list/
-
na_col_list = alldata.isnull().sum()[alldata.isnull().sum()>0].index.tolist()の出力結果

.dtypes
- .dtypes:配列にこれを当てると、それぞれのデータ型を調べてくれる。便利。あと類似のdtypeもある。
- 参考:https://www.sejuku.net/blog/62023
-
alldata[na_col_list].dtypesの出力結果(※sort_values()の内容は割愛、昇順ですね)

欠損状況のへの理解と対応
統計的にデータをどう取り扱うかの意見についての記載です。ここは普通に読んで理解することを推奨します。プログラミング的な理解とは別のお話。
学習データ、テストデータともにかなり欠損しています。
こういうときはパパッと欠損が多いカラムは削除してしまいたくなります。
ですが、その前に変数について詳しく説明しているドキュメントがKaggleにあげられているので、まずはそれを見てみましょう。
Kaggleからデータをダウンロードすると、「data_description.txt」というファイルも含まれていることに気がつきます。このファイルには、変数にどんなデータが格納されているのかが詳しく説明されています。すると、大多数の欠損は情報がないことを意味するのではなく、欠損そのものが情報であることがわかります。
たとえば、最も欠損が多い、PoolQC(プールのクオリティ)をみてみましょう。
この変数の欠損はプールが住宅に存在しないことを意味しており、データの欠損そのものが情報となっています。そのほかの変数(カテゴリカル変数)についても、欠損はその施設や設備が存在しないことを意味しているだけなのです。
また、数値型の変数についても、欠損は占有面積がゼロであることを意味しているだけであって、情報がないわけではありません。
したがって、カテゴリカル変数、数値型変数の欠損には以下の補完を行います。
おしまい。
うーむ。データ眺めるだけで終わってしまった。