過去の記事はこちらになります。
第一回、第二回
第三回、第四回
第五回、第六回
4章では「if-else」コマンドや「for loop」コマンドなどの一般的なプログラミング機能を使ってデータセットに対してさまざまな操作を実行するための独自の関数を記述できるようにしてくれるそうです。
1.よく使う条件式
プログラミングでよく使う以下のようなif-else形式の記述を例にとってRで実行しましょう。
> a <- 2
> if(a!=0){
print(1/a)
}else{
print("No reciprocal for 0.")
}
[1]0.5
0が分母になったらダメってことですね。次は単純にTrue or False 返すものです。次に実際のデータセットを使ってみます。
> library(dslabs)
> data("murders")
> murder_rate <- murders$total/murders$population*100000
> ind <-which.min(murder_rate)
10万人あたりの殺人件数をVectorに入れ、そのVectorの最小のエントリをindに入れてやります。
> if(murder_rate[ind] < 0.5){
+ print(murders$state[ind])
+ }else{
+ print("No state has murder rate that low")
+ }
[1] "Vermont"
もし10万人当たりの発生件数が閾値よりも高いものしかなかった場合はelse内のメッセージを出力します。
続けてifelseという一言で実行する便利なファンクションがあるとのこと。どうやって使うのでしょうか?英語で言ってる感じからするとエクセルのIF関数みたいな感じっぽいです。
> a <- 0
> ifelse(a > 0, 1/a, NA)
[1] NA
> a <- 1
> ifelse(a > 0, 1/a, NA)
[1] 1
aが0より大きければa分の1を返します。まんまエクセルのIF関数ですね。さっきのif-elseとともに、ネストできるのかな?(試せ)
実際の使い道として、こんな書き方があるようです。NAだったら0にして計算できるVectorにするってことかと思います。na_example唐突に出てきましたが、dslabsの中に入ってるものっぽいです。
> data("na_example")
> sum(is.na(na_example))
[1] 145
> no_nas <- ifelse(is.na(na_example), 0, na_example)
> sum(is.na(no_nas))
[1] 0
他にも便利なファンクションでany と all があるとのこと。どう使うのでしょうか?
> z <- c(TRUE, TRUE, FALSE)
> any(z)
[1] TRUE
> all(z)
[1] FALSE
> z <- c(FALSE, FALSE, FALSE)
> any(z)
[1] FALSE
> all(z)
[1] FALSE
> z <- c(TRUE, TRUE, TRUE)
> any(z)
[1] TRUE
> all(z)
[1] TRUE
うーん、これ本当に便利ですか?と聞きたくなる。
2.平均のバリエーション
データサイエンスといえば平均値をとるのは至極普通にされていることかと思います。実はmean というファンクションを使って何度も平均値は求めていますが、今後単純に平均を求めるだけでは対応できないことも多々あります。どのように対処していくのか学びましょう。まずは普通に記述してみます。
> avg <- function(x){
+ s <- sum(x)
+ n <- length(x)
+ s/n
+ }
> x <- 1:100
> avg(x)
[1] 50.5
わざわざ作りましたが、これはもとからあるmeanと同じことです。でも、この同じことを確かめるファンクション「identical」があるとのこと。
> mean(x)
[1] 50.5
> identical(mean(x), avg(x))
[1] TRUE
注意点として少しややこしい話をされました。先ほどavgの中でsとnに合計値と値の式を割り当てしましたが、その変数はavgの中でだけ有効なので、変数として保存されているわけではありません。他に変数を定義して別の内容にするにはavgの中身を再定義してやる必要があります。
> s <- 3
# sが再定義されたので結果も変わるはず...と思いきや。
> avg(1:10)
[1] 5.5
> s
[1] 3
そのあと何言ってるのか正直あんまり把握できませんでした。とりあえずファンクションを定義してやるとその中の最後の行を値として返すということを言いたかったように思えますが...。4章は進みが早いです。
3.ForLoopを使ってnを使った数式を書く
1+2+...+n =(n+1)*n/2
のような数式をRで書いてみます。こういうときはfunction()を使います。
> compute_s_n <- function(n){
+ x <- 1:n
+ sum(x)
+ }
# function(n)に実際の数値を入れる
> compute_s_n(3)
[1] 6
> compute_s_n(100)
[1] 5050
> compute_s_n(2017)
[1] 2035153
sum(x)だとわかりにくいですけど要はsumの中に繰り返しになる式を表現して入れてやればよいです。1^2+2^2+.......+n^2 だったらsum(x^2)になります。
続けて、次のようなnを考えてみます。
n=1,,,,,25
> for(i in 1:5){
+ print(i)
+ }
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
# iにはForLoopの最後の値が入っている。
> i
[1] 5
最後の値を変数にして1から25までの計算をしてグラフにしてみます。compute_s_nは先ほどの続きで、既に式が入っています。
> m <- 25
> #create an empty vector
> s_n <- vector(length = m)
> for(n in 1:m){
+ s_n[n] <- compute_s_n(n)
+ }
# x軸の値をつくる
> n <- 1:m
# n と s_nでグラフを描く
> plot(n, s_n)
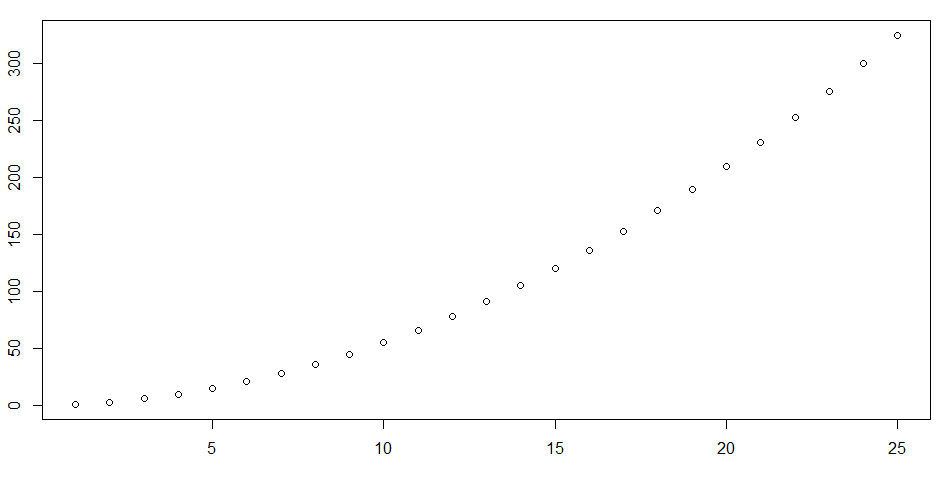
さらに以下のコマンドで線をつけてみます。
> lines(n, n*(n+1)/2)
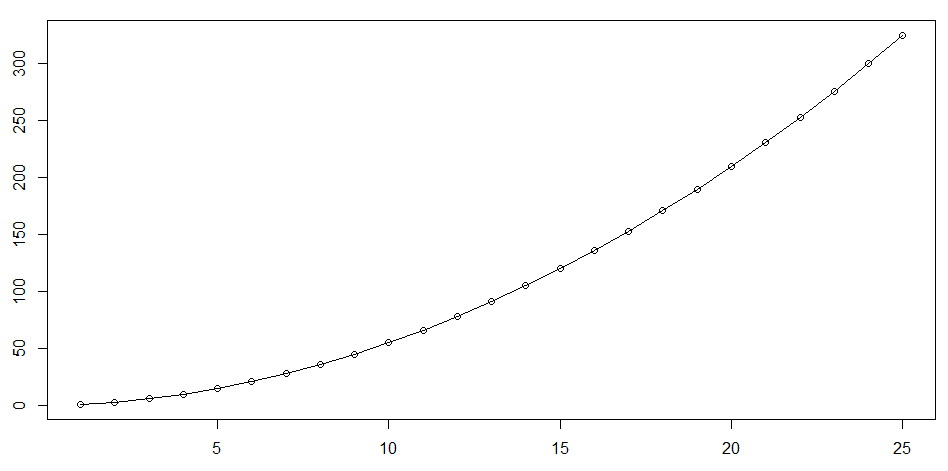
このようにプロットと関数を比較することでプロットを検証するということだと思います。今回は全く同じものでやっていますが。
4.この講座ではやらなかったけど、よく使うので勉強しておいた方が良い関数
サラッとやっただけだったのであまり驚きはありませんでしたが、ForLoopを実際の仕事で使うのはほぼないだろうとのこと。先生っ....!そのかわり、apply、sapply、tapply、mapply をForLoopの代わりに使用するとのことでした。
他にもsplit, cut, quantile, reduce, identical, unique等はここから先データサイエンスをやるうえでは学んでおいた方が良いでしょうとのこと。そちらについてはこの記事の続きでできたらいいな~と思います。
ひっそりと続きを書いています。