はじめに
カルマンフィルタは様々な分野で活用されています。その使いどころや理論については文献が多数あり、Qiitaでも素晴らしい記事がいくつもあります。しかし、あらためて自分なりにまとめてみると、意外にも色々な発見があったので記事にしました。
本記事では、書籍1やそれを短くまとめた解説2に(ある程度)寄せて、線形カルマンフィルタの式の構造についてざっくり解説していきます。ただし、どちらかというと「線形カルマンフィルタの場合にはここまで簡略化できる」という内容を紹介していきます。また本記事では、制御工学徒の読者を想定し、ベイズの定理やベイズフィルタとの関係性は触れません。そうした内容は、多数ある他の良記事を参照してください。強いて言うなら、本記事で条件付期待値については触れるので、その雰囲気からベイズの定理との関係性を想像していただければと思います。
カルマンフィルタの適用対象として、下記の離散時間系を考えます。添え字$k$が時刻ステップを表します。$x_k$が対象の内部状態を表す変数、$y_k$が観測できる変数、プロセスノイズ$v_k$, 観測ノイズ$w_k$は平均がゼロで分散がそれぞれ$\sigma_v^2$、$\sigma_w^2$の正規分布に従うものとします。本記事では簡単化のために$y_k$、$v_k$、$w_k$は一次元とします。
\begin{align}
x_{k+1} &= A x_{k} + b v_k\\
y_k &= c^{T} x_k + w_k
\end{align}
これに対する(時変)線形カルマンフィルタは、下式で表されます。
線形カルマンフィルタ
\begin{aligned}
\text{予測ステップ}
& \left\{
\begin{aligned}
\text{事前状態推定値} \quad \hat{x}^{\scriptscriptstyle -}_k &= A \hat{x}_{k-1} \\
\text{事前誤差共分散行列} \quad P^{-}_k &= A P_{k-1} A^T + \sigma_v^2 b b^T
\end{aligned}
\right. \\
\text{フィルタリングステップ}
& \left\{
\begin{aligned}
\text{カルマンゲイン} \quad K_k &= \frac{P^{-}_k c}{c^T P^{-}_k c + \sigma_w^2}\\
\text{状態推定値} \quad \hat{x}_k &= \hat{x}^{\scriptscriptstyle -}_k + K_k \left( \ y_k - c^T \hat{x}^{\scriptscriptstyle -}_k \ \right) \\
\text{事後誤差共分散行列} \quad P_k &= (I-K_k c^T) P^{-}_k
\end{aligned}
\right.
\end{aligned}
(フィルタリングステップは更新ステップ、イノベーションステップとも呼ばれます)
…と結果をいきなり書きましたが、この式を初見で「あ~ なるほどね~」と思える人は少ないはずです 。本記事では下記の3ステップに分けて、ざっくり理解ができることを目指します。
- カルマンフィルタは離散時間状態オブザーバと似ている。ただし、時刻ステップに注意
- 誤差共分散行列の更新式は、推定式の誤差の分散を立式すると自然にそうなる。実は「線形」カルマンフィルタに限っては、オフラインであらかじめ計算しておくことができる
- カルマンゲインの式は、端的には「推定誤差と観測値の共分散÷観測値の分散」と言える。観測値にノイズが多く載る想定の場合、ゲインは小さくなる。最小二乗推定や条件付期待値でもよく似た式となり、推定誤差の分散の最小化を目指すとこの構造になる
全体的に、つくづく「事前・事後」の概念がわかりにくいと感じます。本記事では極力これらを避けて説明しようと思った次第ですが、そのせいで不正確だったり、かえってわかりにくいところもあるような気がします。厳密なところはさておき、カルマンフィルタの理解の一助になればと思います。検証用のコードはMATLABの他に、Python版も用意しました。 MATLABコードでは一部 Control System Toolboxや、Statistics and Machine Learning Toolboxなども使ってますが、本筋の部分はそれらが無くても動かせます。
間違い、ご指摘等あればコメントいただけると助かります。
カルマンフィルタの式のざっくり解説
最初に、式・変数のおおよその意味や、補足事項などについてまとめておきます。
まず、カルマンフィルタは文献によって表記・記号がしばしば異なります。例えば、推定状態変数について$x_{k|k-1}$や$x_{k|k}$などの添え字で観測の「事前」か「事後」かをあらわすことがあります。書籍1や解説2では、こうした表現ではなく、$\hat{x}^{\scriptscriptstyle -}_k $や$\hat{x}_k$で事前・事後をあらわしていて、本記事もそれに則ります。(個人的にも、プログラムにした際の変数名と対応付けやすいのでこちらの方が好きです)
下記画像で、初見でつまづきそうなポイントに注釈を入れてみました。特に式展開においては、「確率変数ベクトル$X$、$Y$に対し、それらが独立なら、$AX+BY$の分散共分散行列は$A \Sigma_X A^T+B \Sigma_Y B^T$になる」という内容がよく出てくるので、おさえておくと良いと思います。($\Sigma$は分散共分散行列の意味です。$V[\cdot]$と書くと見づらいときなどにそう書くこととします)
また、事後誤差共分散行列は式変形すると別の形で書き表すことができます。個人的にはこちらの式の方が(一見複雑そうですが)他の式との対応関係がわかりやすいと感じます。この表現はJoseph形式と呼ばれ、こちらの方が演算上の性質が良いとも言われています。下記のページが詳しいです。
https://inzkyk.xyz/kalman_filter/kalman_filter_math/

なお、本記事の最後の方のシミュレーションでお見せする線形カルマンフィルタは、ほぼ「観測の事前なのか・事後なのか」を意識しません。下記画像の青枠だけ求めておいて、赤枠だけ実装すれば良いということを確認していきます。なぜ意識しなくていいのか、は随所で述べていきます。

基礎知識
カルマンフィルタでは、推定誤差の分散共分散行列$P_k$が非常に重要な役割を持っています。下式で定義されます。
\begin{align}
P_k = E[(x_k - \hat{x}_k)(x_k - \hat{x}_k)^T]
\end{align}
この行列自体の深堀はあとでするとして、まず分散共分散行列とは何かをおさらいしておきます。
$n$次元の確率変数$X=(X_1,\cdots,X_n)^T$があるとき、その分散共分散行列は下記であらわされます。
\begin{align}
\Sigma_X &= E[(X - E[X])(X - E[X])^T] \\
&= \left(
\begin{array}{ccc}
E[(X_1 - E[X_1])^2] & \cdots & E[(X_1 - E[X_1])(X_n - E[X_n])] \\
\vdots & \ddots & \vdots \\
E[(X_n - E[X_n])(X_1 - E[X_1])] & \cdots & E[(X_n - E[X_n])^2] \\
\end{array}
\right)
\end{align}
この行列の対角要素は分散であり、非対角要素は共分散になっています。その意味で「分散共分散行列」と呼ばれます。ただし、長い名前なのでしばしば共分散行列、共分散、とだけ言ったりします。本記事でも、しばしば「推定誤差の分散共分散行列」「誤差の共分散行列」などの表記ゆれがあるかと思いますが、つねに同じ$P_k$を指しているつもりなのでご承知おきください。
本記事では出力$y$は一次元ですが、内部状態$x$は$n$次元のものを考えていきます。線形カルマンフィルタについてハマるところの多くが、この分散共分散行列に関する内容です。よくわからなくなったら、この周辺の知識をおさらいするのが良いと思われます。
離散時間状態オブザーバとカルマンフィルタとの関係性
離散時間状態オブザーバ
まず、離散時間状態オブザーバについて触れておきます。下記の離散時間系にて、内部状態$x_k$を推定する推定器を構成することを考えます。ノイズなし(制御入力もなし)の系です。
\begin{align}
x_{k+1} &= A x_{k} \\
y_k &= c^{T} x_k
\end{align}
これに対する状態オブザーバとして最も基本的なものは、定数のオブザーバゲインベクトル$L$を用いて下記で表されます。
\begin{align}
\hat{x}_{k+1} &= A \hat{x}_{k} + L (y_k - c^T \hat{x}_k)
\end{align}
この状態オブザーバによる推定誤差$e_k = x_k - \hat{x}_k$を考えると、下式で表されます。
\begin{align}
e_{k+1} &= (A - L c^T) e_{k}
\end{align}
したがって、$(A - L c^T)$の固有値がすべて1未満にできる場合、推定誤差は時刻ステップとともにゼロへ近づきます。それによって、先ほどの状態オブザーバの推定値$\hat{x}_k$は$x_k$を推定できる、というのがオブザーバの概要です。
離散時間状態オブザーバとカルマンフィルタもどき
次は冒頭のカルマンフィルタについて、「最適ではない」カルマンフィルタを考えてみましょう。フィルタゲイン$K_k$を時刻に依存しない、適当な固定のベクトル$K$とすることを考えます。
すると誤差の共分散行列の更新に関わる内容は一切無視でき、通常の離散時間状態オブザーバと似た構造の式になります。逆にいうと、誤差の共分散行列の更新はカルマンゲインの更新にしか使っていない、というわけです。

つまり、事前状態推定値の式を状態推定値の式に代入した、というだけです。下式となります。
\begin{align}
\hat{x}_{k} &= A x_{k-1} + K (y - c^T A \hat{x}_{k-1})
\end{align}
上記の式を、本記事の造語で「カルマンフィルタもどき」と呼ぶことにします。この式と、通常の離散時間状態オブザーバを比較してみましょう。並べると下記となります。
\begin{align}
\text{離散時間状態オブザーバ} \quad \hat{x}_{k+1} &= A \hat{x}_{k} + L (y_k - c^T \hat{x}_k) \\
\text{カルマンフィルタもどき} \quad \hat{x}_k &= A \hat{x}_{k-1} + K \left( \ y_k - c^T A \hat{x}_{k-1} \ \right)
\end{align}
離散時間状態オブザーバの方は、1ステップ先の予測の式となっていることがわかります。両辺の時刻を-1しても動きは変わらないので、カルマンフィルタもどきの方に時刻ステップを合わせて再度書くと下記となります。

違いは赤線部だけです。カルマンフィルタもどきの最後の項は、「ステップ$k-1$での推定値と観測対象の係数行列$A$をもとに、ステップ$k$での(予測)推定値を求めている」と言えます。 ここを$c^T\hat{x}_{k-1}$とだけにしてしまうと、例えば$y$や$x$が一定の変化量で動き続ける場合、$y_k$との時刻ステップの違いによって常に偏差がのり続けるかたちとなってしまいます。
したがって、
- 離散時間状態オブザーバは推定変数と観測値の時刻ステップが揃っている
- カルマンフィルタは推定変数と観測値の時刻ステップが異なっており、観測値の方に合わせるため「1ステップ先の予測値」との差分をとる
という様子が言えます。逆にいうと違いはそれだけで、カルマンゲインの更新を無視すれば、離散時間状態オブザーバとカルマンフィルタの違いは「観測値の時刻が異なるため、推定変数の予測との差をとる」という点のみと言えます。
さらに言うと、離散時間状態オブザーバでプロセスノイズや観測ノイズを定量的に考慮しつつ、ある意味で「最適な」ゲインを実装したものが、カルマンフィルタと言えます。
分散共分散行列の更新
次は、推定誤差の分散共分散行列の更新について述べます。
身も蓋もない言い方をすると、推定誤差の分散共分散行列$P_k$の更新は「上述の推定式に基づく推定誤差の分散から、自然とそうなる」と言えます。当面の間、カルマンゲイン$K_k$は最適なものである必要はなく、「適当な時変ゲイン」でも成り立つ話をします。
カルマンフィルタの、推定誤差の分散共分散行列の式を再掲すると下記です。
\begin{aligned}
\text{事前誤差共分散行列} \quad P^{-}_k &= A P_{k-1} A^T + \sigma_v^2 b b^T \\
\text{事後誤差共分散行列} \quad P_k &= (I-K_k c^T) P^{-}_k (I-K_k c^T)^T + K_k \sigma_w^2 K_k^T
\end{aligned}
これらは代入によって1つの式であらわすことができ、下記となります。
P_k = (I-K_k c^T) (A P_{k-1} A^T + \sigma_v^2 b b^T) (I-K_k c^T)^T + K_k \sigma_w^2 K_k^T
もともとの定義に立ち返ると、推定誤差の分散共分散行列とは$P_k = E \left[e_k e_k^T \right]= E \left[(x_k-\hat{x}_k)(x_k-\hat{x}_k)^T \right]$であらわされます。
この定義に状態$x_k$、推定状態$\hat{x}_k$の式を当てはめていくと、自然と上記の式になることを確認していきます。
この分散共分散行列ですが、「あれ?平均$E[e_k]$はどこいった?」という点に違和感を覚えます。通常、分散共分散行列の定義は、平均値からのばらつきを表すものです。一方$P_k$は$E \left[(e_k-E[e_k]) (e_k-E[e_k] )^T \right]$ではなく$E \left[e_k e_k^T \right]$で定義されていて、暗黙のうちに$E[e_k]=0$としているように思えます。この点はのちほど再び触れます。
下記の離散時間状態方程式
\begin{align}
x_{k+1} &= A x_k + b v_k \\
y_k &= c^{T} x_k + w_k
\end{align}
に対する推定式
\hat{x}_{k} = A \hat{x}_{k-1} + K_k (y_k - c^T A \hat{x}_{k-1})
を考えます。ここで考える$K_k$は上述のカルマンゲインでもいいですし、「カルマンフィルタもどき」のような適当なゲインベクトルでも同じ議論ができます。この時、推定誤差$e_k = x_k - \hat{x}_k$の式は下記で得られます。式は長いですが、代入して右辺に$x_{k-1}$や$\hat{x}_{k-1}$でまとまるようにしているだけです。
\begin{align}
e_k &= x_k - \hat{x}_k \\
&= A x_{k-1}+ bv_{k-1} - (A \hat{x}_{k-1} + K_k ( y_k - c^T A \hat{x}_{k-1} )) \\
&= A x_{k-1}+ bv_{k-1} - (A \hat{x}_{k-1} + K_k ( (c^T x_k + w_k) - c^T A \hat{x}_{k-1} )) \\
&= A x_{k-1}+ bv_{k-1} - (A \hat{x}_{k-1} + K_k ( (c^T (A x_{k-1}+ bv_{k-1} ) + w_k) - c^T A \hat{x}_{k-1} )) \\
&= A x_{k-1}+ bv_{k-1} - (A \hat{x}_{k-1} + K_k ( (c^T (A x_{k-1}+ bv_{k-1} ) + w_k) - c^T A \hat{x}_{k-1} )) \\
\end{align}
複雑な様相になってきましたが、$e_{k-1}=x_{k-1}- \hat{x}_{k-1}$を置くことで、下記のようにわかりやすく整理できます。
\begin{align}
e_k &= (I-K_k c^T)A e_{k-1} + (I-K_k c^T)bv_{k-1} -K_k w_k \\
&= (I-K_k c^T)(A e_{k-1} + bv_{k-1}) -K_k w_k \\
\end{align}
ここで、やはり$E[e_k]$が気になるので求めてみます。$v$や$w$の平均はゼロと仮定しているので下記となります。$(I-K_k c^T)A$が安定行列なら誤差が時間とともにゼロに向かうのは納得いく一方、初期誤差$e_0=x_0-\hat{x}_0$がある限り、一見すると常に$E[e_k]=0$とは見えません。
\begin{align}
E[e_k] &= (I-K_k c^T)A E[e_{k-1} ]
\end{align}
…が、ここで$x_0$の素性を考えると多少納得がいきます。$x_0$については、(どこにも明記してませんが)それも平均ゼロの確率変数だと定義するのが妥当な気がします。特に理由が無ければふつう推定器の$\hat{x}_0$はゼロにしますし、$x_0$の平均がゼロなら$e_0$の平均もゼロです。こうした考えで、それを時間発展させた$e_k$の期待値$E[e_k]$もゼロと言って良さそうです。繰り返し期待値の法則などを使うともう少し詳しい議論が出来そうですが、本記事ではこのへんにしておきます。
ここで、いよいよ誤差の共分散行列$E[e_k e^T_k]$を求めてみます。
\begin{align}
E \left[e_k e_k^{T} \right]&= E [((I-K_k c^T)(A e_{k-1} + bv_{k-1}) -K_k w_k) (\cdot)^T ] \\
&= E [ (I-K_k c^T)(A e_{k-1} e_{k-1}^T A^T + b v_{k-1} v_{k-1}^T b^T)(I-K_k c^T)^T] \\
& \quad + E [K_k w_k w_k^T K_k^T ] \\
&= (I-K_k c^T)(A E [e_{k-1} e_{k-1}^T] A^T + b E[v_{k-1} v_{k-1}^T] b^T)(I-K_k c^T)^T \\
& \quad + K_k E [w_k w_k^T] K_k^T \\
&= (I-K_k c^T)(A P_{k-1} A^T + \sigma_v^2 b b^T)(I-K_k c^T)^T + \sigma_w^2K_k K_k^T \\
\end{align}
ちょっと1行目→2行目の式変形がややこしいところがあるので、下図で補足します。$(\cdot)$は長くなるので中身を省略したもので、全部書くと↓になります。また、「$e_{k-1}$と$ v_{k-1}$」や「$e_{k-1}$と$w_{k}$」、「$v_{k-1}$と$w_{k}$」はそれぞれ独立となるため、かけて期待値をとるとゼロになります。つまり、同じ四角の色の項以外は期待値をとるとゼロ、という結果が上記での2行目となっています。

結局、下図で赤の囲い部分が事後誤差共分散行列、青の囲い部分が事前共分散行列に相当します。また、$E[e_{k-1}^{} e_{k-1}^T]=P_{k-1}$とおいていて、これが「1ステップ前での事後誤差共分散」に相当します。「1ステップ前での事後誤差共分散」の$P_{k-1}$と、「事前誤差共分散」の$(A P_{k-1} A^T + \sigma_v^2 b b^T)$とは異なるもの、という点に注意してください。

以上で、誤差共分散行列については終わりです。上式の$K_k$はカルマンゲインである必要はなく、「適当な時変ゲイン」でも成り立ちます。つまり、「観測値を推定則に通したことによる誤差の更新」が上式と言えます。一方、上式右辺の行列を最小化するゲイン$K_k$を求めようとすると、まさにカルマンゲインが導かれます。
また上式について、実は推定時にオンライン(リアルタイム)計算する必要はありません。この点は、カルマンゲインについて述べた最後の方で再び話題に挙げることにします。
カルマンゲインの構造
以下では、いよいよカルマンゲインの式がなぜそうなるか、に関わるところを述べます。
まずカルマンゲインの導出に関する一般的な内容を少し述べたのち、適当な仮定のもとで
- $y=c^T x+w$について、$x$との平均二乗誤差が最小となるような推定式$\hat{x}$
- $x$と$y$が2変量正規分布に従い$y=c^T x+w$の関係があるとき、観測値$y_{\rm obs}$を得た際の$x$の条件付期待値$E \left[x|y=y_{\rm obs} \right] $
がカルマンフィルタの式とほぼ同一なことを紹介していきます。その式の中に表れる「誤差に対するゲイン」部分が、いずれもカルマンゲインの式とそっくりな様子が伝わればと思います。
カルマンゲインの導出
先述のとおり$E \left[e_k e_k^{T} \right]$は下式で得られています。2行目が「事前」誤差分散行列に相当するところを$P^{-}_k$で定義しなおしたものです。
\begin{align}
E \left[e_k e_k^{T} \right] &= (I-K_k C)(A P_{k-1} A^T + \sigma_v^2 b b^T)(I-K_k C)^T + \sigma_w^2K_k K_k^T \\
&= (I-K_k C)P^{-}_k (I-K_k C)^T + \sigma_w^2K_k K_k^T \\
\end{align}
これに対し、行列のトレースの最小化を行う(すなわち、$E \left[e_k e_k^{T} \right] $の対角要素を最小化する)とカルマンゲインが導出できます。(他にも直交射影を用いるなど、導出方法は色々あるようです)
詳しい導出方法は文献が多数あり、話が横道へそれる割に解法特有の内容に踏み込みがちなので本記事では省略します。
1つ補足すると、カルマンゲインの式に含まれているのがなぜ「事前」の誤差分散行列なのかは、上式を眺めれば想像がつきます。最小化しようとしているのが「事後」の誤差分散行列であって、右辺に含まれているのは「事前」の方だからです。
最小二乗推定値との関係性
内部状態が一変数の場合
時系列データのことはいったん無視して、下式の$x$を推定する問題を考えます。まずは、$x$、$y$、$w$はベクトルではなく1次元のものを考えます。係数$c$は既知で、観測値$y$が得られるとします。ただし、ノイズとしての確率変数$w$が加算され、$w$は平均0、分散$\sigma_w^2$の正規分布に従うものとします。また、$x$そのものも確率変数とし、平均$\bar{x}$、分散$\sigma_x^2$の正規分布に従うものとします。$x$と$w$は無相関とします。
\begin{align}
y=c x+w
\end{align}
これは、統計学の書籍などでの問題設定とは異なる場合があるので注意ください。比較的よくある最小二乗法の説明では、$y=\beta_0 + \beta_1 x$について、$y$と$x$を得られる状況で回帰係数$\beta_0$、$\beta_1$を求める問題を考えます。
この問題に対し、最小二乗推定値は下式で得られます。 一見すると、上の式は$w$が平均値ゼロなので「要するに$\hat{x}=y/c$で$x$を推定すればいいのでは?」と思いがちです。 実はそうではない、という点が重要で、このあたりのイメージ図は条件付期待値の話題のところで紹介します。
\begin{align}
\hat{x} &= \bar{x} + \frac{c \sigma_x^2}{c^2 \sigma_x^2+\sigma_w^2}(y-c\bar{x} )
\end{align}
式の導出はこちら
推定式として下記を考えます。$\alpha$、$\beta$は定数です。本記事ではほぼすべて$E[w]=0$と仮定してますが、ここの式の導出だけ$E[w]=\bar{w}$とします。(深い意味はありませんが、$\bar{w}$があってもそれほど複雑にならないので)
\begin{align}
\hat{x} &= \alpha y + \beta
\end{align}
① 推定誤差の平均がゼロになることを考えると、下式が導けます。
\begin{align}
E[e] &= E[x-\hat{x}]\\
&= E[x-\alpha y - \beta] \\
&= E[x-\alpha (cx + w) - \beta] \\
&= \bar{x} - \alpha c (\bar{x}+\bar{w}) - \beta = 0 \\
\end{align}
一番最後の式から、$\beta=\bar{x} - \alpha c \bar{x}$が求まります。
② 推定誤差の分散を最小にすることを考えると
\begin{align}
E[(e-E[e])^2] &= E[(x-\alpha y - \beta - ((1 - \alpha c) \bar{x} - \alpha \bar{w} - \beta))^2]\\
&= E[(x-\alpha (cx+w) - (1 - \alpha c) \bar{x} + \alpha \bar{w} )^2]\\
&= E[((1 - \alpha c) (x-\bar{x}) - \alpha (w-\bar{w}) )^2]\\
&= (1 - \alpha c)^2 E[(x-\bar{x})^2] + \alpha^2 E[(w-\bar{w})^2]\\
&= (1 - \alpha c)^2 \sigma_x^2 + \alpha^2 \sigma_w^2\\
\end{align}
最初の行で$E[e]=0$を使わなかったことで、$\beta$を早々に消去しました。
また3行目→4行目にて、$x$と$w$が独立なので$E[(x-\bar{x})(w-\bar{w})]=0$を使いました。
さらに平方完成を用いて、上式を最小化する$\alpha$の条件が導けます。
\begin{align}
E[(e-E[e])^2] &= (1 - \alpha c)^2 \sigma_x^2 + \alpha^2 \sigma_w^2\\
&= (c^2 \sigma_x^2 + \sigma_w^2)\alpha^2 - 2c \sigma_x^2 \alpha + \sigma_w^2 \\
&= (c^2 \sigma_x^2 + \sigma_w^2)\left(\alpha - \frac{c \sigma_x^2}{c^2 \sigma_x^2 + \sigma_w^2}\right)^2 + \sigma_x^2 - \frac{c^2 \sigma_x^4}{c^2 \sigma_x^2 + \sigma_w^2} \\
&= (c^2 \sigma_x^2 + \sigma_w^2)\left(\alpha - \frac{c \sigma_x^2}{c^2 \sigma_x^2 + \sigma_w^2}\right)^2 + \frac{ \sigma_x^2 \sigma_w^2}{c^2 \sigma_x^2 + \sigma_w^2} \\
\end{align}
上式は、$\alpha = \frac{c \sigma_x^2}{c^2 \sigma_x^2 + \sigma_w^2}$のとき最小となります。
①と②の結論から得た$\alpha$、$\beta$から、推定式は下式となります。
\begin{align}
\hat{x} &= \alpha y + \beta \\
&= \frac{c \sigma_x^2}{c^2 \sigma_x^2 + \sigma_w^2} y + \bar{x} - \frac{c \sigma_x^2}{c^2 \sigma_x^2 + \sigma_w^2}c \bar{x}\\
&= \bar{x} + \frac{c \sigma_x^2}{c^2 \sigma_x^2 + \sigma_w^2}( y - c \bar{x})\\
\end{align}
内部状態が多変数の場合
多変数の場合も、得られる式の構造はほぼ同じです。一部が、係数→行列、分散→分散共分散行列に一般化される点に注意ください。
おおまかには一変数版と同一ですが、今度は$x$が$n$次元の縦長のベクトルとします。ここでは書籍1→文献2に設定を寄せるため、$y$と$w$は1次元とします(話の大筋に違いはありません)。$x$は平均$\bar{x}$、共分散行列$E[(x-\bar{x})(x-\bar{x})^T]=\Sigma_x$であらわされるものとし、$w$は平均0、分散$\sigma_w^2$であらわされるものとします。
\begin{align}
y=c^T x+w
\end{align}
これに対する最小二乗推定値$\hat{x}$は下式で得られます。
\begin{align}
\hat{x} &= \bar{x} + \frac{\Sigma_x c}{c^T \Sigma_x c+\sigma_w^2}(y-c^T\bar{x} )
\end{align}
(この式の導出は省略します。書籍1 第1版の(4.56)の式と同一です。文献2に寄せて$c$が行列ではなくベクトルであり、それを転置している点に注意ください。$c$がベクトルなので、$c^T \Sigma_x c$はスカラになります)
ここで載せた最小二乗推定値(一変数・多変数)と、冒頭のカルマンフィルタの式を並べると下記となります。
\begin{align}
\text{最小二乗推定値(状態が一変数)} \quad \hat{x} &= \bar{x} + \frac{c \sigma_x^2}{c^2 \sigma_x^2+\sigma_w^2}(y-c\bar{x} )\\
\text{最小二乗推定値(状態が多変数)} \quad \hat{x} &= \bar{x} + \frac{\Sigma_x c}{c^T \Sigma_x c+\sigma_w^2}(y-c^T\bar{x} )\\
\text{カルマンフィルタ 状態推定値} \quad \hat{x}_k &= \hat{x}^{\scriptscriptstyle -}_k + \frac{P^{-}_k c}{c^T P^{-}_k c + \sigma_w^2} \left( \ y_k - c^T \hat{x}^{\scriptscriptstyle -}_k \ \right) \\
\end{align}
並べて比較すると、やはり非常に似通った構造であることがわかります。係数$\frac{\Sigma_x c}{c^T \Sigma_x c+\sigma_w^2}$の部分が気になりますが、ここの掘り下げは後ほど行います。
多変量正規分布の条件付期待値
2変量正規分布の条件付期待値
一方、正規分布の条件付期待値を考えると、そちらも先ほどの最小二乗推定値同様、カルマンフィルタの式とよく似た構造があらわれます。
確率変数$x$と$y$が2変量正規分布に従うとし、$y$の観測値$y_{\rm obs}$が得られたときの$x$の期待値を考えます。ノイズ$w$のことはいったん忘れてください。2変量正規分布に従う、を下式で表現することがあり、本記事もそれにならいます。$\rho$は相関係数であり、$x$と$y$の間の相関関係を-1~1の実数としてあらわします。
\begin{align}
\left(
\begin{array}{l}
x \\
y
\end{array}
\right) \sim N \left[\left( \
\begin{array}{l}
\bar{x} \\
\bar{y}
\end{array} \
\right) ,\left(
\begin{array}{c}
\sigma_x^2 & \rho \sigma_x \sigma_y \\
\rho \sigma_x \sigma_y & \sigma_y^2
\end{array}
\right)
\right]
\end{align}
これに対し、$y$の実現値として$y_{\rm obs}$が観測されたもとで、確率変数$x$の期待値は下式であらわされます。
\begin{align}
E \left[x|y=y_{\rm obs} \right] &= \bar{x} + \frac{\rho \sigma_x \sigma_y}{\sigma_y^2} \left( \ y_{\rm obs} -\bar{y} \ \right)
\end{align}
これも、式の導出については省略します。下記のサイトなどを参照ください。本記事とは$x$と$y$が逆だったりするのでご注意ください。
https://math-note.com/conditional-probability-of-multivariate-normal-distribution/
https://note.com/tak661/n/n33bf30a5860d ※有料記事ですが大変わかりやすいです
この式も、カルマンゲインに相当する部分が係数として表れてきています。特に、「$x$と$y$の共分散 ÷ $y$の分散」となっていることに注目してください。
上式ではあえて分母分子に$\sigma_y$を残してますが、それを消去すると相関係数×$x$の標準偏差÷$y$の標準偏差 とも解釈できます。このあたりも、カルマンゲインに様々な解釈がある要因と言えそうです。
上式は一見するとカルマンゲインの式とは似てないように見えますが、ある仮定を入れると再び全く同じような式が出てきます。この点は2変量→多変量に一般化したあとで掘り下げていきます。
条件付期待値の意味
ここで、コードベースで2変量正規分布と条件付期待値についておさらいしておきます。まずは、下記のコードで2変量正規分布を確認します。
Toolbox不要版はこちら
%--------------------------------------------
% 2変量正規分布の3Dプロット & 2D等高線プロット例 (Toolbox不要版)
%--------------------------------------------
clear;
%% パラメータ設定
mu_x = 1;
mu_y = 1;
sigma_x = 1;
sigma_y = sqrt(2);
rho = 0.8;
mu = [mu_x, mu_y];
% 分散共分散行列
Sigma = [sigma_x^2, rho*sigma_x*sigma_y;
rho*sigma_x*sigma_y, sigma_y^2];
%% プロット用の格子点を生成
x1 = -4:0.1:4; % x方向の値
x2 = -4:0.1:4; % y方向の値
[x, y] = meshgrid(x1, x2);
%% 2変量正規分布の確率密度関数を計算 (mvnpdf の代替)
% 各点について中心化
X = [x(:)-mu_x, y(:)-mu_y];
invSigma = inv(Sigma);
detSigma = det(Sigma);
d = 2; % 次元数
factor = 1 / ((2*pi)^(d/2) * sqrt(detSigma));
quadform = sum((X * invSigma) .* X, 2); % 各点の2乗距離 (マハラノビス距離)
F = factor * exp(-0.5 * quadform);
F = reshape(F, length(x2), length(x1));
%% 1) 3次元サーフェスプロット
figure('Name','3D Surface');
surf(x1, x2, F);
xlabel('x');
ylabel('y');
zlabel('f(x,y)');
title('2変量正規分布の同時確率');
shading interp; % 補間表示
colormap jet; % カラーマップ設定
%% 2) 2次元等高線プロット
figure('Name','2D Contour');
contour(x1, x2, F, 20); % 等高線20本
xlabel('x');
ylabel('y');
title('2変量正規分布の等高線プロット');
axis equal; % スケールを等倍にする
colormap jet; % カラーマップ設定
colorbar; % カラーバー表示
%% 条件付期待値のプロット
% サンプルの生成 (mvnrnd の代替)
rng(1, "twister");
num_samples = 500;
% Cholesky分解により下三角行列 L を取得
L = chol(Sigma, 'lower');
% 標準正規乱数からの変換
xy_samples = repmat(mu, num_samples, 1) + randn(num_samples, 2) * L';
% 条件付期待値の式 (yが固定されたときの x の期待値)
mu_x_given_y = mu_x + rho * (sigma_x / sigma_y) * (y(:,1) - mu_y);
figure;
contour(x, y, F, 20);
axis equal; % スケールを等倍にする
colormap jet; % カラーマップ設定
colorbar; % カラーバー表示
hold on;
% サンプルの散布図
scatter(xy_samples(:, 1), xy_samples(:, 2), 10, 'b', 'filled', 'MarkerFaceAlpha', 0.4);
% 条件付期待値曲線のプロット
plot(mu_x_given_y, y(:, 1), 'r', 'LineWidth', 2);
% plot(temp, y(:, 1), 'm', 'LineWidth', 2); % 別式の場合
xlabel('x');
ylabel('y');
title('Joint PDF, Simulated Data, and Conditional Expectation');
grid on;
legend('Joint PDF', 'Samples', 'E[x|y]', 'Location', 'northwest');
xlim([-4 4]);
ylim([-4 4]);
Python版のコードはこちら
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 3D プロット用
from scipy.stats import multivariate_normal
plt.rcParams['font.sans-serif'] = ['Yu Gothic']
#===========================
# パラメータ設定
#===========================
mu_x = 1
mu_y = 1
sigma_x = 1
sigma_y = np.sqrt(2) # または sigma_y = 0.8 とする場合もあり
rho = 0.8
mu = np.array([mu_x, mu_y])
# 分散共分散行列の作成
Sigma = np.array([[sigma_x**2, rho*sigma_x*sigma_y],
[rho*sigma_x*sigma_y, sigma_y**2]])
#===========================
# 格子点の作成
#===========================
# MATLAB の -4:0.1:4 に対応
x1 = np.arange(-4, 4.1, 0.1) # x 軸方向の値
x2 = np.arange(-4, 4.1, 0.1) # y 軸方向の値
X, Y = np.meshgrid(x1, x2) # X, Y はそれぞれグリッド上の座標
#===========================
# 2変量正規分布の確率密度関数の計算
#===========================
# 各点の (x,y) 座標を格納する配列を作成
pos = np.empty(X.shape + (2,))
pos[:, :, 0] = X
pos[:, :, 1] = Y
# 各点における確率密度を計算(F の形状は (len(x2), len(x1)) となる)
F = multivariate_normal.pdf(pos, mean=mu, cov=Sigma)
#===========================
# 1) 3次元サーフェスプロット
#===========================
fig1 = plt.figure('3D Surface')
ax1 = fig1.add_subplot(111, projection='3d')
# surf: 補間表示は plot_surface 内部で行われる(edgecolor をなしに設定)
surf = ax1.plot_surface(X, Y, F, cmap='jet', edgecolor='none')
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax1.set_zlabel('f(x,y)')
ax1.set_title('2変量正規分布の同時確率')
fig1.colorbar(surf, shrink=0.5, aspect=5)
#===========================
# 2) 2次元等高線プロット
#===========================
fig2 = plt.figure('2D Contour')
cs = plt.contour(X, Y, F, levels=20, cmap='jet') # 等高線 20 本指定
plt.xlabel('x')
plt.ylabel('y')
plt.title('2変量正規分布の等高線プロット')
plt.axis('equal') # スケールを等倍にする
plt.colorbar(cs)
#===========================
# 条件付期待値のプロット
#===========================
# サンプル生成(乱数のシードを固定)
np.random.seed(1)
num_samples = 500
xy_samples = np.random.multivariate_normal(mu, Sigma, num_samples)
# 条件付期待値の式: mu_x_given_y = mu_x + rho*(sigma_x/sigma_y)*(y - mu_y)
# MATLAB では meshgrid により y(:,1) を利用しているので、Python では Y の1列目(Y[:, 0])を利用
y_for_curve = Y[:, 0] # 1列目:各行ごとに一定の y 値(x2 の値)
mu_x_given_y = mu_x + rho * (sigma_x / sigma_y) * (y_for_curve - mu_y)
# プロット
fig3, ax3 = plt.subplots()
# 等高線プロット
cs3 = ax3.contour(X, Y, F, levels=20, cmap='jet')
plt.colorbar(cs3, ax=ax3)
ax3.axis('equal')
# サンプルの散布図(マーカーサイズ 10, 青、透明度 0.4)
ax3.scatter(xy_samples[:, 0], xy_samples[:, 1], s=10, color='b', alpha=0.4, label='Samples')
# 条件付期待値の曲線(赤、線幅2)
ax3.plot(mu_x_given_y, y_for_curve, 'r', linewidth=2, label='E[x|y]')
ax3.set_xlabel('x')
ax3.set_ylabel('y')
ax3.set_title('Joint PDF, Simulated Data, and Conditional Expectation')
ax3.grid(True)
ax3.legend(loc='upper left')
ax3.set_xlim([-4, 4])
ax3.set_ylim([-4, 4])
plt.show()
% パラメータ設定
mu = [1 1]; % [mu_x, mu_y]
Sigma = [1 1.2; % 分散共分散行列
1.2 2];
% プロット用の格子点を生成
x1 = -4:0.1:4; % x方向の値
x2 = -4:0.1:4; % y方向の値
[X1, X2] = meshgrid(x1, x2);
% 2変量正規分布の確率密度関数を計算
F = mvnpdf([X1(:), X2(:)], mu, Sigma);
F = reshape(F, length(x2), length(x1));
%=== 1) 3次元サーフェスプロット ===
figure('Name','3D Surface');
surf(x1, x2, F);
xlabel('x');
ylabel('y');
zlabel('f(x,y)');
title('2変量正規分布の同時確率');
shading interp; % 補間表示
colormap jet; % カラーマップ設定
%=== 2) 2次元等高線プロット ===
figure('Name','2D Contour');
contour(x1, x2, F, 20); % 第3引数で等高線の数(20本)を指定
xlabel('x');
ylabel('y');
title('2変量正規分布の等高線プロット');
axis equal; % スケールを等倍にする
colormap jet; % カラーマップ設定
colorbar; % カラーバー表示
このコードでプロットすると、下図が表示されます。左図がコードをそのまま実行した結果で右図が相関係数の符号を反転したものです。左右の図で相関係数$\rho$は異なりますが、「x方向からの見た目(緑矢印)」、「y方向からの見た目(青矢印)」の見え方は、左右どちらも同じベルカーブに見える点に注意ください。(左右の青矢印同士が同じ見た目という意味で、青矢印と緑矢印の見た目が同じわけではありません)

さらに、この正規分布に従う2変数のサンプルを表示しつつ、先に示した条件付期待値の式も描画するコードが下記です。(先のコードの続きです)
% サンプルの設定
rng(1,"twister");
num_samples = 500;
xy_samples = mvnrnd(mu, Sigma, num_samples);
% 条件付期待値の式
mu_x_given_y = mu_x + rho * (sigma_x / sigma_y) * (y(:, 1) - mu_y);
figure;
contour(x, y, F, 20);
axis equal; % スケールを等倍にする
colormap jet; % カラーマップ設定
colorbar; % カラーバー表示
hold on;
% Scatter plot of samples
scatter(xy_samples(:, 1), xy_samples(:, 2), 10, 'b', 'filled', 'MarkerFaceAlpha', 0.4);
% Plot Conditional Expectation Curve
plot(mu_x_given_y, y(:, 1), 'r', 'LineWidth', 2);
xlabel('x');
ylabel('y');
title('Joint PDF, Simulated Data, and Conditional Expectation');
grid on;
legend('Joint PDF', 'Samples', 'E[x|y]', 'Location', 'northwest');
xlim([-4 4]);
ylim([-4 4]);

赤線は、条件付期待値をあらわします。それを$x$の推定式$\hat{x} = \bar{x} + \frac{\rho \sigma_x \sigma_y}{\sigma_y^2} \left( \ y_{\rm obs} -\bar{y} \ \right)$だとみなすと、下図のようなイメージで$x$が推定されます。つまり例として、
- $y_{\rm obs}=2$のサンプリングが得られたとき、赤線に従うと$\hat{x}=1.566$
- $y_{\rm obs}=-2$のサンプリングが得られたとき、赤線に従うと$\hat{x}=-0.697$
と推定できるわけです。一見すると当たり前のようにも感じられますが、この推定式から
- $y$のばらつきが大きいとき、$y_{\rm obs}$の値の大小で$x$の推定値はあまり大きく変化しない
- $x$のばらつきが大きいとき、$y_{\rm obs}$の値の大小が$x$の推定値に大きく影響する。また、そもそも$x$の真値は求めづらくなる
- 相関係数$\rho$が正なら、$y_{\rm obs}$が増えたとき$x$の推定値も増える
- 相関係数$\rho$が負なら、$y_{\rm obs}$が増えたとき$x$の推定値は減る
- 相関係数$\rho$が0に近いとき、$y_{\rm obs}$の値は参考にせず$\bar{x}$を重視したほうが良い
などなどの様子が想像できるわけです。これに近いことがカルマンフィルタによる推定にも言えます。

ちなみに、等高線の接線に直交する形で線が引かれておらず、微妙にずれている気がしますがこれはそういうもののようです。
等高線の接線に直交する線を引きたい場合
固有ベクトル$v_1$、$v_2$($v_1$の方がより大きい固有値に対応)とすると、そのベクトルの比$v_2/v_1$を使って
\begin{align}
\hat{x} &= \mu_x + \frac{v_2}{v_1} (y_{\rm obs}-\mu_x) \\
&= \mu_x + \frac{(\sigma_x^2 - \sigma_y^2) + \sqrt{(\sigma_x^2 - \sigma_y^2)^2 + 4 \rho^2 \sigma_x^2 \sigma_y^2}}{2 \rho \sigma_x \sigma_y} (y_{\rm obs}-\mu_x) \\
\end{align}
を使えばよいようです。興味があれば下記をプロットしてみてください。
orthogonal_contour_x = mu_x + ((sigma_x^2 - sigma_y^2) + sqrt((sigma_x^2 - sigma_y^2)^2 + 4*rho^2*sigma_x^2*sigma_y^2) ) / (2*rho*sigma_x*sigma_y) * (y(:, 1) - mu_y);
plot(orthogonal_contour_x, y(:, 1), 'c--', 'LineWidth', 2);
多変量正規分布の条件付期待値
先の条件付期待値の式は$x$、$y$ともに1次元で計2変量の正規分布に従う、という内容でした。
$x$の次数が$n$次元のベクトルとする場合、下記のように一般化されます。本記事では$n$次元の状態変数と1出力を考えるため$\Sigma_{x}$は$n\times n$の行列、$\Sigma_{y}$はスカラとなります。$\Sigma_{xy}$は$x$と$y$の共分散で、$n$行のベクトルです。
\begin{align}
\left(
\begin{array}{l}
x \\
y
\end{array}
\right) \sim N \left[\left( \
\begin{array}{l}
\bar{x} \\
\bar{y}
\end{array} \
\right) ,\left(
\begin{array}{c}
\Sigma_{x} & \Sigma_{xy} \\
\Sigma_{xy}^T & \Sigma_{y}
\end{array}
\right)
\right]
\end{align}
これに対して2変量正規分布と同様、$y$の実現値として$y_{\rm obs}$が観測されたもとで、確率変数$x$の条件付期待値は下式となります。
\begin{align}
E \left[x|y=y_{\rm obs} \right] &= \bar{x} +\Sigma_{xy}\Sigma_{y}^{-1} \left( \ y_{\rm obs} -\bar{y} \ \right)
\end{align}
(この式の導出も省略します。文献は多数ありますが、例えば3などがおすすめです)
最小二乗推定値と条件付期待値との関係性
先ほどまでの内容で、条件付期待値においては「$x$と$y$の共分散 ÷ $y$の分散」がカルマンゲインに相当する部分だと述べました。さらに再び最小二乗推定値と同様、下記の関係式を考えることで、そのゲインがどういう構造になるかを確認します。
\begin{align}
y=c^T x+w
\end{align}
この式に対して、まず$x$と$y$の共分散${\rm Cov}[x, y]$は下記のとおり求まります。
\begin{align}
{\rm Cov}[x, y] &= {\rm Cov}[x, \ c^T x+w] \\
&= {\rm Cov}[x, \ c^T x] \\
&= E \left[(x-\bar{x})\left(c^T x - c^T \bar{x}\right)^T \right] \\
&= E \left[(x-\bar{x}) \left(c^T \left(x - \bar{x}\right) \right)^T \right] \\
&= E \left[(x-\bar{x}) \left(x - \bar{x}\right)^T c \right] \\
&= V[x] c = \Sigma_x c \\
\end{align}
1→2行目で、$w$と$x$が無相関であることを使いました。4→5行目で、$(a^T b)^T = b^T a$の転置の性質を使いました。
一方、$y$の分散は下記のとおり求まります。
\begin{align}
V[y] &= V[c^T x+w] \\
&= c^T V[x]c + 2 {\rm Cov} [x, w]c + V[w] \\
&= c^T V[x]c + V[w] = c^T \Sigma_x c + \sigma_w^2 \\
\end{align}
したがって、$y=c^T x+w$の関係にある多変量正規分布は下記の式であらわされます。
\begin{align}
\left(
\begin{array}{l}
x \\
y
\end{array}
\right) \sim N \left[\left( \
\begin{array}{c}
\bar{x} \\
c^T \bar{x}
\end{array} \
\right) ,\left(
\begin{array}{c}
\Sigma_{x} & \Sigma_x c \\
(\Sigma_x c)^T & c^T \Sigma_x c + \sigma_w^2
\end{array}
\right)
\right]
\end{align}
分散共分散行列の右上:$x$と$y$の共分散、右下:$y$の分散、がまさに最小二乗推定の式と全く同じものになっている様子がわかります。したがって、条件付期待値の式は、$x$と$y$の間の関係性に$y=c^T x+w$の式を持たせると、最小二乗推定値と全く同じになります。
ちょっとくどいですが、これまでに得てきた、最小二乗推定値と条件付期待値、そしてカルマンフィルタの式を並べると下記です。
\begin{align}
\text{最小二乗推定値 or 条件付期待値(状態が多変数)} \quad \hat{x} &= \bar{x} + \frac{\Sigma_x c}{c^T \Sigma_x c+\sigma_w^2}(y-c^T\bar{x} )\\
\text{カルマンフィルタ 状態推定値} \quad \hat{x}_k &= \hat{x}^{\scriptscriptstyle -}_k + \frac{P^{-}_k c}{c^T P^{-}_k c + \sigma_w^2} \left( \ y_k - c^T \hat{x}^{\scriptscriptstyle -}_k \ \right) \\
\end{align}
大きな違いは$\Sigma_x$と$P_k^{-}$だけです。この違いを追求するために、カルマンフィルタの式は時系列データを扱うことをあらためて意識する必要があります。
余談ですが、$y=c^T x + w$での条件付期待値のプロットもしておきます。先ほどのプロットでは相関係数$\rho$を明示的に与えましたが、今度は$x$と$w$の分散で決まるので傾きが異なります。また、「$y=c^T x + w$で$w$の平均がゼロなら、$\hat{x}=y_{\rm obs}/c$で推定すればいいのでは?」ということで、緑の点線も載せています。画像でわかる通り、それでは「$x$の平均値」や「データのばらつきによる傾き」が考慮されないため、特徴を捉えられていない様子がわかります。( 緑線は$(\bar{x},\bar{y})=(1,1)$を通ってますが、これはたまたまです。また、「$y$の観測値が+1されたとき、ノイズの影響があるので推定値は単純に+1としてはならない」などの解釈が良いと思います)
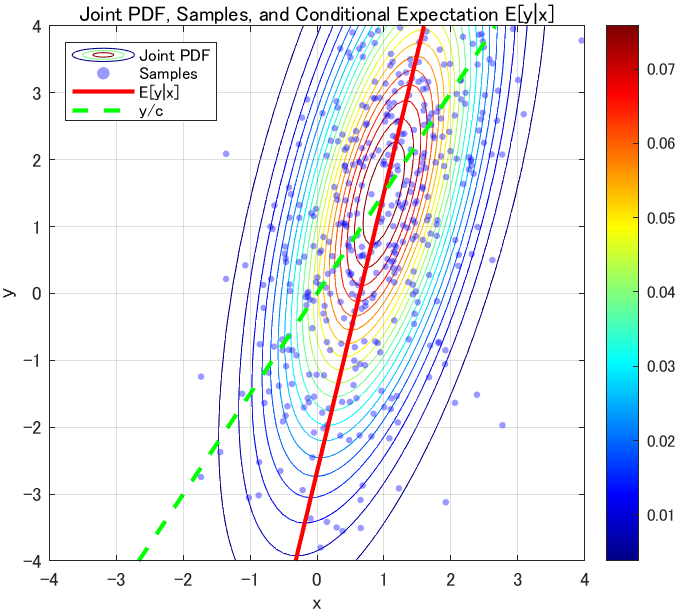
コードは先ほどと同様なので、隠して載せておきます
%--------------------------------------------
% y = c*x + w の場合の分布・サンプル・条件付期待値のプロット例
%--------------------------------------------
clear;
%% パラメータ設定
c = 1.5; % 定数 c
mu_x = 1; % xの平均
sigma_x = 1; % xの標準偏差
mu_w = 0; % wの平均
sigma_w = 2; % wの標準偏差
% y = c*x + w のときのyの平均・分散、xとyの共分散の計算
mu_y = c * mu_x + mu_w;
sigma_y = sqrt(c^2 * sigma_x^2 + sigma_w^2);
cov_xy = c * sigma_x^2;
% (x,y)の2変量正規分布のパラメータ
mu = [mu_x, mu_y];
Sigma = [sigma_x^2, cov_xy;
cov_xy, c^2*sigma_x^2 + sigma_w^2];
%% プロット用の格子点の生成
x1 = -4:0.1:4; % x軸の値
x2 = -4:0.1:4; % y軸の値
[x, y] = meshgrid(x1, x2);
% 2変量正規分布の確率密度関数を計算
F = mvnpdf([x(:), y(:)], mu, Sigma);
F = reshape(F, length(x2), length(x1));
%% 1) 3次元サーフェスプロット
figure('Name','3D Surface');
surf(x1, x2, F);
xlabel('x');
ylabel('y');
zlabel('f(x,y)');
title('y = c*x + w の同時確率');
shading interp; % 補間表示
colormap jet;
%% 2) 2次元等高線プロット
figure('Name','2D Contour');
contour(x1, x2, F, 20); % 等高線20本
xlabel('x');
ylabel('y');
title('y = c*x + w の等高線プロット');
axis equal; % 軸のスケールを等倍に
colormap jet;
colorbar;
%% 条件付期待値のプロット
% サンプル生成
rng(1, "twister"); % 乱数シードの設定
num_samples = 500;
x_samples = normrnd(mu_x, sigma_x, num_samples, 1);
w_samples = normrnd(mu_w, sigma_w, num_samples, 1);
y_samples = c * x_samples + w_samples;
xy_samples = [x_samples, y_samples];
figure;
contour(x1, x2, F, 20);
axis equal;
colormap jet;
colorbar;
hold on;
% サンプルの散布図プロット
scatter(xy_samples(:,1), xy_samples(:,2), 10, 'b', 'filled', 'MarkerFaceAlpha', 0.4);
% 条件付期待値曲線
y_line = linspace(-4, 4, 100);
mu_x_given_y = mu_x + sigma_x*c/(c*sigma_x*c+sigma_w^2)* (y(:, 1) - mu_y);
plot(mu_x_given_y, y(:, 1), 'r', 'LineWidth', 2);
simple_x = y(:, 1)/c;
plot(simple_x, y(:, 1), 'g--', 'LineWidth', 2);
xlabel('x');
ylabel('y');
title('Joint PDF, Samples, and Conditional Expectation E[y|x]');
grid on;
legend('Joint PDF', 'Samples', 'E[y|x]' , 'y/c', 'Location', 'northwest');
xlim([-4 4]);
ylim([-4 4]);
誤差共分散行列の意味合い
なぜ最小二乗推定では$x$の分散$\Sigma_x$があらわれて、カルマンフィルタの式では$x$そのものの分散ではなく推定誤差の分散共分散行列$P_k^{-}$が出てくるのかを考えてみましょう。
最小二乗推定では、時系列データではなく、静的な内容を推定するものでした。一方、カルマンフィルタでは時系列データを扱います。イメージとしては下図のようになっていて、観測値$y$や推定したい内部変数$x$は時間とともにドリフトしていくこともあり得ます(図で$x$ではなく$c^Tx$としているのは、観測値の成分と合わせるためです。$x$は一般には多次元で、$y$と直接比較はできません)。このドリフトの様子が係数行列$A$で決まっている、というわけです。

したがって、カルマンフィルタでは$x$そのものの分散ではなく、推定誤差$e_k=x_k-\hat{x}_k$を考えます(両辺に$c^T$を書けると推定誤差の観測成分:イノベーションと言われる指標になり、それが重要だという見方もできます)。条件付期待値のところで考えた、多変量正規分布のフォーマットに合わせると、下式を考えていることになります。
\begin{align}
\left(
\begin{array}{c}
e_k \\
y_k
\end{array}
\right) =
\left(
\begin{array}{c}
x_k-\hat{x}_k \\
y_k
\end{array}
\right) \sim N \left[\left( \
\begin{array}{c}
0 \\
c^T \bar{x}
\end{array} \
\right) ,\left(
\begin{array}{c}
P_k & P_k c \\
(P_k c)^T & c^T P_k c + \sigma_w^2
\end{array}
\right)
\right]
\end{align}
…と思いきや、実はちょっと違います。 この式だと、事後誤差共分散行列$P_k$があらわれてきてしまいます。もともとのカルマンフィルタの式ありきでの解釈になってしまいますが、何かが違っているわけです。
ここで、本記事では使用を避けてきた $\hat{x}_{k|k}$ や$\hat{x}_{k|k-1}$ の概念を導入します。 $\hat{x}_{k|k-1}$ は予測ステップでの$x$の推定値であり、$y$の観測をする前の、状態方程式の予測の部分での推定値です。「$k|k-1$」は、「$k-1$までの観測情報を使ってステップ$k$での値を推定した値」のような意味合いになります。この「事前」の推定値と実際の$x$との差を $e_{k \mid k-1}=x_k-\hat{x}_{k \mid k-1}$ とあらわすと、下記の多変量正規分布に従います。
\begin{align}
\left(
\begin{array}{c}
e_{k|k-1} \\
y_k
\end{array}
\right) =
\left(
\begin{array}{c}
x_k-\hat{x}_{k|k-1} \\
y_k
\end{array}
\right) \sim N \left[\left( \
\begin{array}{c}
0 \\
c^T \bar{x}
\end{array} \
\right) ,\left(
\begin{array}{c}
P^{-}_k & P^{-}_k c \\
(P^{-}_k c)^T & c^T P^{-}_k c + \sigma_w^2
\end{array}
\right)
\right]
\end{align}
上式の解釈としては、カルマンフィルタでやっているのは、「事前分布の条件付期待値を求める」行為だということです。先に述べた多変量正規分布の条件付期待値の式は「観測が得られたとき、どのような推定をするのがいいか」を考えていました。そこで出てきた$x$の分布も、あくまで「事前」分布だったわけです。もし「事後分布の条件付期待値を求める」をしてしまうと、さらに追加で観測値を得た場合の期待値を求めることになってしまう、という解釈が良いと思います。
(事後の)推定誤差$e_k$の平均値については、「分散共分散行列の更新」の項で言及しました。
事前の推定誤差$e_{k|k-1}$についても、直感的には「初期誤差の平均がゼロだから、それを時間発展させた推定誤差も(誤差系が安定なら)平均ゼロ」ととらえるのが良さそうです。
推定誤差の平均についてもう少し踏み込むと
カルマンフィルタの推定式は下式のように、時刻1から$k$ステップまでの観測値をもとに、状態変数$x_k$の期待値を求めている、と言えます。
\begin{align}
\hat{x}_{k | k-1} &= E[x_k | y_{1:k}] \\
\end{align}
繰り返し期待値の法則を使うことで、両辺の期待値をとると右辺は$E[x_k]$に一致します。
\begin{align}
E[\hat{x}_{k | k-1}] &= E[E[x_k | y_{1:k}]] = E[x_k]\\
\end{align}
右辺と左辺の差が$E[e_{k | k-1}]$なので、この観点でも$E[e_{k | k-1}]=0$と言えそうです。(が、私自身あまり腑に落ちてません)
分散共分散行列の対角要素は、「分散共分散行列の更新」で行った計算とほぼ全く同じ内容なので省略して、非対角要素の$P^{-}_k c$のところだけ確認します。下記の計算となります。
\begin{align}
{\rm Cov}[e_{k|k-1}, y_k] &= {\rm Cov}[e_{k|k-1}, \ c^T x_k+w_k] \\
&= {\rm Cov}[e_{k|k-1}, \ c^T x_k] \\
&= E[e_{k|k-1} (c^T x_k)] - E[e_{k|k-1}] E[(c^T x_k)] \\
&= E[e_{k|k-1} (c^T x_k)] \\
&= E[e_{k|k-1} x_k^T] c \\
&= E[e_{k|k-1} (e_{k|k-1}+\hat{x}_{k | k-1})^T] c \\
&= E[e_{k|k-1} e_{k|k-1}^T]c+E[e_{k|k-1}\hat{x}_{k | k-1}^T] c \\
&= E[e_{k|k-1} e_{k|k-1}^T]c\\
&= P^{-}_k c \\
\end{align}
1→2行目は、推定誤差$e$と観測ノイズ$w$の無相関性を使いました。3→4行目は、先述の$E[e_{k | k-1}]=0$を使いました。7→8行目は、推定誤差$e$と推定値$\hat{x}$の無相関性により$E[e_{k|k-1}\hat{x}_{k | k-1}^T] =0$を使いました。
カルマンゲインのオフライン計算
ここまでで、誤差共分散行列やそれに基づくカルマンゲインの計算について触れました。しかし実は、「線形」カルマンフィルタにおいては、これらを推定時にオンライン(リアルタイム)計算する必要はありません。式を再掲すると下記で、観測値$y_k$や状態$x_k$はこれらの式に一切含まれていないためです。ある意味、これらの式は「ノイズや観測値そのものを得なくても、ノイズの分散や各係数行列がわかれば、時々刻々の推定誤差の分散はわかる」ということを示しています。
\begin{aligned}
\text{事前誤差共分散行列} \quad P^{-}_k &= A P_{k-1} A^T + \sigma_v^2 b b^T\\
\text{カルマンゲイン} \quad K_k &= \frac{P^{-}_k c}{c^T P^{-}_k c + \sigma_w^2}\\
\text{事後誤差共分散行列} \quad P_k &= (I-K_k c^T) P^{-}_k(I-K_k c^T)^T + \sigma_w^2 K_k K_k^T
\end{aligned}
EKF(Extended Kalman Filter)をはじめとした非線形カルマンフィルタでは係数行列$A$が非線形関数となったり、状態$x$に応じて変わるためオンライン計算が必要です。
つまり、推定誤差共分散行列$P_k$についての初期値$P_0$を定めておき、$P_k$が一定値に収束するまで反復計算させる…という計算を、観測値を与えることなくシミュレートできます。そうして求まった$P_0$、$P_1$…$P_{k^\ast}$と時変カルマンゲイン$K_0$、$K_1$…$K_{k^\ast}$のうち、カルマンゲインだけをオンラインでの推定式に使います。${k^\ast}$は$P_k$が収束したとみなせる時刻ステップを表します。そして、そのステップ以降は時不変のゲイン$K_{k^\ast}$を使い続ければよい、ということです。
定常カルマンフィルタ
誤差共分散行列がいずれ収束するなら、初めからその収束後の分散を見積もって固定のゲインにすればよいのでは?というのが定常カルマンフィルタです。誤差共分散行列の更新が不要となったことで推定式は非常にシンプルになり、下式であらわされます。
\hat{x}_{k} = A \hat{x}_{k-1} + K_{k^\ast} (y_k - c^T A \hat{x}_{k-1})
これと微妙に異なる推定式もあります。上記は先述の「カルマンフィルタもどき」に最適ゲインを代入した形ですが、例えば、最初の方で紹介した離散時間状態オブザーバにゲイン$K_{k^\ast}$を与えた式も定常カルマンフィルタと呼べると思われます。ただし、実用上は時刻ステップに注意が必要です。
実際、誤差共分散行列を先述の反復計算で収束するまで求めることは、「定常カルマンフィルタの誤差共分散行列とゲインを求める」という数値解法の一種とも言えます。後述のシミュレーションでは、MATLABのkalman()関数で求めたゲインと、上記の式を反復計算して求めたものが一致することを確認していきます。
さらに言うと、私の所感では「線形・時不変」の系に限っては、誤差共分散行列を更新しないこの「定常」カルマンフィルタで十分ではと思っています。時変ゲイン版では初めに$P_0$を与える必要があり、これはつまり初期値$x_0$の見積もりで決まりますが、通常ゼロと置くしかないのでは…と感じます。特に$P_k$の時系列は観測値を得ることなく求められるので、
- $P_0=0$を与えて$P_{k^\ast}$に収束するまでのステップ数を見て、過渡期はあまり精度を期待しない(待ち時間を設けるなど)
- 初めから$P_{k^\ast}$だと見積もる
などでもいい気がします。この点も後述のシミュレーションで確認することにします。
シミュレーション
本記事の総まとめとして、シミュレーションで線形カルマンフィルタの動きを確認します。
シミュレーション条件
簡単な例題として、位置$p$、速度$q$の状態を持つ系の位置のみが観測できる状況で、速度$q$を推定する問題を考えます。(速度が$v$じゃないのは、プロセスノイズとの混同を防ぐためです)
$A$行列の意味合いは、1行目:「次ステップの位置は現在位置と、サンプリング時間$T_s$×現在速度で決まる」、2行目:「次ステップの速度は現在の速度を引き継ぐ」となっています。
$B$行列が、意外と悩ましいです。$A$行列の意味合い的に、「速度は一定値のみで変化しない」となっています。それを緩和させるために$\left(0 \quad 1
\right)^T $で速度にプロセスノイズが印可されるとしたいところですが、それだとあまり速度推定が上手くいってる様子が見せられないため、微調整しました。本来はきちんとモデリングする必要があるので、ご注意ください。
\begin{align}
\left(
\begin{array}{c}
p_{k+1}\\
q_{k+1}
\end{array}
\right) &= \left(
\begin{array}{c}
1 & T_s \\
0 & 1
\end{array}
\right) \left(
\begin{array}{c}
p_{k}\\
q_{k}
\end{array}
\right) + \left(
\begin{array}{c}
0.2 \\
1
\end{array}
\right) v_k \\
y &= (\quad 1 \quad 0 \quad )\left(
\begin{array}{c}
p_{k}\\
q_{k}
\end{array}
\right) + w_k
\end{align}
シミュレーション用コード
下記にMATLAB/Pythonコードを示します。詳細な条件はコードを確認ください。実際に組み込みソフトへ実装する場合には各種変数を配列にする必要はないですが、多くの変数が時刻の配列になっているのはあとから時間経過の履歴を見たいためです。また、シミュレーションループの内部で「x_k = x(:,k)」や「P_k = P_(:,:,k)」の置き換えを行っているのは、配列の添え字の煩わしさを低減するためです。
シミュレーションでの検証内容としては、本筋のほかに下記3点も盛り込んでます。その部分はコメント欄に明記してますので、本筋だけ追いたい場合は読み飛ばす、もしくはコード削除してください。
(1) オフライン計算でもゲインや分散共分散行列が変わらない点
(2) オフライン計算で求めた分散共分散行列とkalmanで求めたものが一致する点
(3) 定常カルマンフィルタを用いても、ある程度時間が経った後の動きは同じ点
stepend = 500; %シミュレーションステップ数
steps = 1:stepend;
% 状態変数、推定状態変数、観測値の定義
x = zeros(2,stepend);
x(:,1) = [0;0.1]; % 状態変数の初期値をセット
hatx = zeros(2,stepend);
hatx(:,1) = [0;0]; % 推定状態変数の初期値をセット
y = zeros(1,stepend);
% 誤差の分散共分散行列(1ステップ分)の定義
P_k = [0 0; 0 0];
% 誤差の分散共分散行列(各ステップ毎の値を保持する)の定義
P = zeros(2,2,stepend);
P(:,:,1) = P_k; % Pの初期値をセット
P_ = zeros(2,2,stepend); % 事前誤差共分散行列(事後と共通の変数にもできる)
P_(:,:,1) = P_k; % Pの初期値をセット
% プロセスノイズv、観測ノイズwの定義
sigmav = 0.1;
sigmaw = 0.5;
Q = sigmav*sigmav;
R = sigmaw*sigmaw;
Ts = 0.01;
A = [1 Ts; 0 1];
b = [0.2;1];
c = [1;0];
rng(5,"twister");
% (2)オフライン計算で求めた分散共分散行列とkalmanで求めたものが一致する点の検証
% シミュレーションには使わない。結果の比較にのみ使う。
sys = ss(A,[[0;0] b],c',[0 0],Ts);
[syskalmf,L_kalmf,P_kalmf,Mx,Z_kalmf,My] = kalman(sys,Q,R,0);
% 時変カルマンゲインの定義
K = zeros(2,stepend);
% 推定誤差を保存する配列
e_stored = zeros(2,stepend);
P_act_stored = zeros(2,2,stepend);
score = 0;
sigmaP = zeros(2,stepend);
% (1)オフライン計算でもゲインや分散共分散行列が変わらない点の検証
% 事前に、時変ゲインと誤差共分散行列だけを求める。
P_bef = zeros(2,2,stepend);
K_bef = zeros(2,stepend);
for k =2:stepend
P_bef(:,:,k) = A*P_bef(:,:,k-1)*A' + b*Q*b';
K_bef(:,k) = P_bef(:,:,k)*c/(c'*P_bef(:,:,k)*c+R);
P_bef(:,:,k) = (eye(2)-K_bef(:,k)*c')*P_bef(:,:,k)*(eye(2)-K_bef(:,k)*c')' + K_bef(:,k)*R*K_bef(:,k)';
end
% (3)定常カルマンフィルタを用いても、ある程度時間が経ったときの動きはまったく同じ点
% 定常カルマンフィルタを使った場合の状態変数、時変カルマンゲインの定義
hatx_fix = zeros(2,stepend);
hatx_fix(:,1) = [0;0];
K_fix = K_bef(:,end);
% シミュレーションループ
for k =2:stepend
% 観測対象からのサンプリング
x(:,k) = A * x(:,k-1) + b*randn*sigmav;
x_k = x(:,k);
y(k) = c'*x_k + randn*sigmaw;
% (3)定常カルマンフィルタを用いても、ある程度時間が経った後の動きは同じ点の検証
hatx_fix(:,k) = A * hatx_fix(:,k-1) + K_fix * (y(k)-c'*A*hatx_fix(:,k-1));
% 予測ステップ
hatx_ = A * hatx(:,k-1);
% 事前誤差共分散行列の更新
P_(:,:,k) = A*P(:,:,k-1)*A' + b*Q*b';
P_k = P_(:,:,k);
% カルマンゲインの算出
K(:,k) = P_k*c/(c'*P_k*c+R);
K_k = K(:,k);
% 更新ステップ
hatx(:,k) = hatx_ + K_k * (y(k)-c'*hatx_);
% 事後誤差共分散行列の更新
P(:,:,k) = (eye(2)-K_k*c')*P_k*(eye(2)-K_k*c')' + K_k*R*K_k';
e_k = x(:,k) - hatx(:,k);
P_act_stored(:,:,k) = e_k * e_k';
score = score + trace(P_act_stored(:,:,k));
sigmaP(:,k)=sqrt(diag(P(:,:,k)));
end
%%
% 推定結果のプロット
figure; hold on;
plot(x(1,:),'-b');
plot(y,'.r');
plot(hatx(1,:),'-m');
plot(hatx(1,:)+2*sigmaP(1,:),'-g');
plot(hatx(1,:)-2*sigmaP(1,:),'-g');
legend({'真の位置','観測値y','推定位置','推定位置±2σ'})
title('位置推定の様子')
ylim([-2 2]);
figure; hold on;
plot(x(2,:),'-b');
plot(hatx(2,:),'-m');
plot(hatx(2,:)+2*sigmaP(2,:),'-g');
plot(hatx(2,:)-2*sigmaP(2,:),'-g');
legend({'真の速度','推定速度','推定速度±2σ'})
title('速度推定の様子')
ylim([-2 2]);
lowerBound = hatx(1,:) - 2*sigmaP(1,:);
upperBound = hatx(1,:) + 2*sigmaP(1,:);
numOutside = sum( x(1,:) < lowerBound | x(1,:) > upperBound );
fprintf('推定位置が±2σから逸脱した割合:%.2f',(1-numOutside/stepend))
% シミュレーション内の誤差分散共分散行列Pの計算
% 簡易的に、移動平均によって求める。
window = 10; % 移動平均の点数
[rows, cols, ~] = size(P_act_stored);
P_act_movavg = zeros(rows, cols, stepend);
%% 分散共分散行列Pの要素のプロット
%-- プロットしたいPの要素と、それを表示するサブプロット番号を対応付け --
plotElems = [1 1; 1 2; 2 2]; % (2,1)は省略
subPositions = [1, 2, 4]; % subplot(2,2,1), (2,2,2), (2,2,4) を使う
for k = 1:stepend
if k < window
% 初期の k が window 未満の場合は、1 から k までの平均を計算
P_act_movavg(:,:,k) = mean(P_act_stored(:,:,1:k), 3);
else
% k >= window のときは、直近 window 点の平均
P_act_movavg(:,:,k) = mean(P_act_stored(:,:,(k-window+1):k), 3);
end
end
figure;
for n = 1:size(plotElems,1)
i1 = plotElems(n,1);
i2 = plotElems(n,2);
subplot(2,2, subPositions(n));
hold on;grid on;
%-- カルマンフィルタの推定P --
plot(squeeze(P(i1,i2,:)), '-g', 'LineWidth',1);
%-- 実測誤差から計算したP --
plot(squeeze(P_act_movavg(i1,i2,:)), '-r', 'LineWidth',1);
title(sprintf('P(%d,%d)', i1, i2));
xlabel('step');
ylabel('(x-hatx)^2');
legend('Predicted(KF)','Actual','Location','northeast');
ylim([0 0.3]);
end
%-- 余白にしたい (2,1)成分の箇所を subplot(2,2,3) で空ける場合 --
subplot(2,2,3);
axis off;
hold off;
% 誤差共分散行列P のトレースの累積値
fprintf('Pの対角要素の累積(スコア):%s',score)
% (1)オフライン計算でもゲインや分散共分散行列が変わらない点の検証
% 演算場所が違うだけなので、計算結果は(浮動小数であることを加味しても)まったく同じになる
if (isequal(K_bef, K) && isequal(P_bef, P))
fprintf('KとPの計算結果は、事前計算・シミュレーションループ内での計算どちらも一致。');
end
% ゲインの時系列の表示
figure;
plot(steps,K(1,:),steps,K(2,:))
legend({'K(1)','K(2)'});
title('カルマンゲインの時間変化')
% 推定誤差の平均がほぼゼロになることの確認
fprintf('位置推定誤差の平均:%s',mean(x(1,:)-hatx(1,:)))
fprintf('速度推定誤差の平均:%s',mean(x(2,:)-hatx(2,:)))
%%
% 時変のカルマンフィルタと定常カルマンフィルタの比較
figure;
tiledlayout(2,1, 'TileSpacing','compact', 'Padding','compact');
% (3)定常カルマンフィルタを用いても、ある程度時間が経った後の動きは同じ点の検証
nexttile
plot(steps,x(1,:)-hatx(1,:),'-m',steps,x(1,:)-hatx_fix(1,:),'-c');
legend({'位置誤差(時変)','位置誤差(定常)'})
title('時変カルマンフィルタと定常カルマンフィルタの位置推定誤差の比較')
nexttile;
plot(steps,x(2,:)-hatx(2,:),'-m',steps,x(2,:)-hatx_fix(2,:),'-c');
legend({'速度誤差(時変)','速度誤差(定常)'})
title('時変カルマンフィルタと定常カルマンフィルタの速度推定誤差の比較')
% (2)オフライン計算で求めた分散共分散行列とkalmanで求めたものが一致する点の検証
% kalmanで求めた誤差共分散行列と、シミュレーション内の定常値はほぼ一致する
fprintf('kalman関数でのPとシミュレーション結果のP(の定常値)の差:%s',trace(Z_kalmf-P(:,:,end)))
Python版のコードはこちら
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import control
plt.rcParams['font.sans-serif'] = ['Yu Gothic']
# ----- シミュレーション設定 -----
stepend = 500
steps = np.arange(1, stepend + 1)
# 状態変数(真の状態)・推定状態・観測値の初期化
x = np.zeros((stepend, 2))
x[0] = [0, 0.1] # 初期状態
hatx = np.zeros((stepend, 2))
hatx[0] = [0, 0] # 初期推定状態
y = np.zeros(stepend)
# 1ステップ分の誤差分散共分散行列(初期値)
P_k = np.zeros((2, 2))
# 各ステップ毎の事後誤差共分散行列 P と事前誤差共分散行列 P_prior
P = np.zeros((stepend, 2, 2))
P[0] = P_k.copy()
P_prior = np.zeros((stepend, 2, 2))
P_prior[0] = P_k.copy()
# プロセスノイズと観測ノイズの設定
sigmav = 0.1
sigmaw = 0.5
Q = sigmav ** 2
R = sigmaw ** 2
Ts = 0.01
A = np.array([[1, Ts],
[0, 1]])
b = np.array([[0.2],
[1]])
c = np.array([[1],
[0]])
np.random.seed(5)
# ----- (2) オフライン計算:MATLABの kalman 関数相当の計算(比較用) -----
# システム: x[k+1] = A*x[k] + b*v[k] , y[k] = c' * x[k] + w[k]
# control.dlqe で定常カルマンゲインと誤差共分散行列を求める
L_kalmf, P_kalmf, eigVals = control.dlqe(A, b, c.T, Q, R)
Z_kalmf = P_kalmf.copy() # MATLAB の Z_kalmf の代用(比較用)
# ----- 時変カルマンゲインの配列 -----
K = np.zeros((stepend, 2))
# 推定誤差と実測誤差から計算した誤差共分散行列を保存するための配列
e_stored = np.zeros((stepend, 2))
P_act_stored = np.zeros((stepend, 2, 2))
score = 0.0
sigmaP = np.zeros((stepend, 2))
# ----- (1) オフライン計算による時変ゲイン・誤差共分散行列の計算(検証用) -----
P_bef = np.zeros((stepend, 2, 2))
K_bef = np.zeros((stepend, 2))
for k in range(1, stepend):
P_bef[k] = A @ P_bef[k - 1] @ A.T + (b @ b.T) * Q
denom = (c.T @ P_bef[k] @ c + R)[0, 0]
K_bef[k] = (P_bef[k] @ c).flatten() / denom
I = np.eye(2)
P_bef[k] = (I - np.outer(K_bef[k], c.flatten())) @ P_bef[k] @ (I - np.outer(K_bef[k], c.flatten())).T + np.outer(K_bef[k], K_bef[k]) * R
# ----- (3) 定常カルマンフィルタ(定常ゲイン)による推定 -----
hatx_fix = np.zeros((stepend, 2))
hatx_fix[0] = [0, 0]
K_fix = K_bef[-1].copy() # 定常カルマンゲイン(シミュレーション後半の値)
# ----- シミュレーションループ -----
for k in range(1, stepend):
# 観測対象(真のシステム)からサンプリング
x[k] = A.dot(x[k - 1]) + b.flatten() * (np.random.randn() * sigmav)
y[k] = c.flatten().dot(x[k]) + np.random.randn() * sigmaw
# 定常カルマンフィルタによる更新
hatx_fix[k] = A.dot(hatx_fix[k - 1]) + K_fix * (y[k] - c.flatten().dot(A.dot(hatx_fix[k - 1])))
# 予測ステップ
hatx_pred = A.dot(hatx[k - 1])
# 事前誤差共分散行列の更新
P_prior[k] = A.dot(P[k - 1]).dot(A.T) + (b @ b.T) * Q
P_k_current = P_prior[k].copy()
# カルマンゲインの算出
denom = (c.T @ P_k_current @ c + R)[0, 0]
K[k] = (P_k_current @ c).flatten() / denom
K_k = K[k].copy()
# 更新ステップ
hatx[k] = hatx_pred + K_k * (y[k] - c.flatten().dot(hatx_pred))
# 事後誤差共分散行列の更新(Joseph の形)
I = np.eye(2)
P[k] = (I - np.outer(K_k, c.flatten())) @ P_k_current @ (I - np.outer(K_k, c.flatten())).T + np.outer(K_k, K_k) * R
# 推定誤差とスコア更新
e_k = x[k] - hatx[k]
P_act_stored[k] = np.outer(e_k, e_k)
score += np.trace(P_act_stored[k])
sigmaP[k] = np.sqrt(np.diag(P[k]))
# ----- 推定結果のプロット -----
# ① 位置推定
plt.figure()
plt.plot(steps, x[:, 0], '-b', label='真の位置')
plt.plot(steps, y, '.r', label='観測値y')
plt.plot(steps, hatx[:, 0], '-m', label='推定位置')
plt.plot(steps, hatx[:, 0] + 2 * sigmaP[:, 0], '-g', label='推定位置±2σ')
plt.plot(steps, hatx[:, 0] - 2 * sigmaP[:, 0], '-g')
plt.legend()
plt.title('位置推定の様子')
plt.ylim([-2, 2])
# ② 速度推定
plt.figure()
plt.plot(steps, x[:, 1], '-b', label='真の速度')
plt.plot(steps, hatx[:, 1], '-m', label='推定速度')
plt.plot(steps, hatx[:, 1] + 2 * sigmaP[:, 1], '-g', label='推定速度±2σ')
plt.plot(steps, hatx[:, 1] - 2 * sigmaP[:, 1], '-g')
plt.legend()
plt.title('速度推定の様子')
plt.ylim([-2, 2])
# ±2σからの逸脱率
lowerBound = hatx[:, 0] - 2 * sigmaP[:, 0]
upperBound = hatx[:, 0] + 2 * sigmaP[:, 0]
numOutside = np.sum((x[:, 0] < lowerBound) | (x[:, 0] > upperBound))
print('推定位置が±2σから逸脱した割合: {:.2f}'.format(1 - numOutside / stepend))
# ----- 移動平均による実際の誤差共分散行列の算出 -----
window = 10 # 移動平均のウィンドウサイズ
P_act_movavg = np.zeros((stepend, 2, 2))
for k in range(stepend):
if k < window:
P_act_movavg[k] = np.mean(P_act_stored[:k + 1], axis=0)
else:
P_act_movavg[k] = np.mean(P_act_stored[k - window + 1:k + 1], axis=0)
# ----- 誤差共分散行列の各要素のプロット -----
# プロット対象: P(1,1), P(1,2), P(2,2) (MATLAB では (2,1) は省略)
plotElems = np.array([[1, 1],
[1, 2],
[2, 2]])
subPositions = [1, 2, 4] # 2×2 のサブプロットの位置 (1, 2, 4)
plt.figure()
for n in range(plotElems.shape[0]):
i1 = int(plotElems[n, 0]) - 1 # Python の 0 始まりに合わせる
i2 = int(plotElems[n, 1]) - 1
plt.subplot(2, 2, subPositions[n])
plt.grid(True)
# カルマンフィルタで予測された P(緑)
plt.plot(P[:, i1, i2], '-g', linewidth=1, label='Predicted(KF)')
# 実際の誤差から計算した P(赤)
plt.plot(P_act_movavg[:, i1, i2], '-r', linewidth=1, label='Actual')
plt.title('P({},{})'.format(i1 + 1, i2 + 1))
plt.xlabel('step')
plt.ylabel('(x-hatx)^2')
plt.legend(loc='upper right')
plt.ylim([0, 0.3])
# 空白にするサブプロット(MATLAB では subplot(2,2,3) を空ける)
plt.subplot(2, 2, 3)
plt.axis('off')
plt.tight_layout()
print('Pの対角要素の累積(スコア):', score)
# ----- オフライン計算とシミュレーション内の計算結果の検証 -----
if np.allclose(K_bef, K) and np.allclose(P_bef, P):
print('KとPの計算結果は、事前計算・シミュレーションループ内での計算どちらも一致。')
# ----- カルマンゲインの時系列の表示 -----
plt.figure()
plt.plot(steps, K[:, 0], label='K(1)')
plt.plot(steps, K[:, 1], label='K(2)')
plt.legend()
plt.title('カルマンゲインの時間変化')
# ----- 推定誤差の平均(位置・速度)を表示 -----
print('位置推定誤差の平均:', np.mean(x[:, 0] - hatx[:, 0]))
print('速度推定誤差の平均:', np.mean(x[:, 1] - hatx[:, 1]))
# ----- 時変カルマンフィルタと定常カルマンフィルタの比較 -----
fig, axs = plt.subplots(2, 1, tight_layout=True)
axs[0].plot(steps, x[:, 0] - hatx[:, 0], '-m', label='位置誤差(時変)')
axs[0].plot(steps, x[:, 0] - hatx_fix[:, 0], '-c', label='位置誤差(定常)')
axs[0].legend()
axs[0].set_title('時変カルマンフィルタと定常カルマンフィルタの位置推定誤差の比較')
axs[1].plot(steps, x[:, 1] - hatx[:, 1], '-m', label='速度誤差(時変)')
axs[1].plot(steps, x[:, 1] - hatx_fix[:, 1], '-c', label='速度誤差(定常)')
axs[1].legend()
axs[1].set_title('時変カルマンフィルタと定常カルマンフィルタの速度推定誤差の比較')
print('kalman関数でのPとシミュレーション結果のP(の定常値)の差:', np.trace(Z_kalmf - P[-1]))
# ----- カルマンフィルタの伝達関数による位置・速度推定 -----
# 定常時のゲインを用いる(シミュレーション最終時刻の値)
k1 = K[-1, 0]
k2 = K[-1, 1]
# 伝達関数 hatp_flt: (k1*(z-1)+k2*Ts)*z / ((z-1)**2 + (k1+k2*Ts)*(z-1) + k2*Ts)
# 伝達関数 hatq_flt: k2*(z-1)*z / ((z-1)**2 + (k1+k2*Ts)*(z-1) + k2*Ts)
# ※ z-1 は多項式 [1, -1] で表現する。
num_hatp = [k1, -k1 + k2 * Ts, 0] # z^2, z^1, z^0 の係数((k1*z - k1 + k2*Ts)*z)
den_hatp = [1 + k1 + k2 * Ts, -2 - k1 - k2 * Ts, 1 + k2 * Ts] # (z-1)^2 + (k1+k2*Ts)*(z-1) + k2*Ts
hatp_flt = control.TransferFunction(num_hatp, den_hatp, Ts)
num_hatq = [k2, -k2, 0] # k2*(z-1)*z
den_hatq = den_hatp.copy()
hatq_flt = control.TransferFunction(num_hatq, den_hatq, Ts)
# 測定値 y に対する伝達関数の応答をシミュレーション(lsim 相当)
t = np.arange(0, stepend * Ts, Ts)
t, psim = control.forced_response(hatp_flt, T=t, U=y)
t, qsim = control.forced_response(hatq_flt, T=t, U=y)
# 伝達関数の応答と定常カルマンフィルタの推定結果の比較
fig, axs = plt.subplots(2, 1, tight_layout=True)
axs[0].plot(t, psim, label='位置誤差(時変)')
axs[0].plot(t, hatx_fix[:, 0], label='位置誤差(定常)')
axs[0].legend()
axs[1].plot(t, qsim, label='速度誤差(時変)')
axs[1].plot(t, hatx_fix[:, 1], label='速度誤差(定常)')
axs[1].legend()
print('max(|psim - hatx_fix(位置)|):', np.max(np.abs(psim - hatx_fix[:, 0])))
print('max(|qsim - hatx_fix(速度)|):', np.max(np.abs(qsim - hatx_fix[:, 1])))
# Bode プロット(伝達関数の周波数応答)
plt.figure()
control.bode_plot([hatp_flt, hatq_flt], dB=True)
plt.grid(True)
plt.show()
シミュレーション結果の解釈
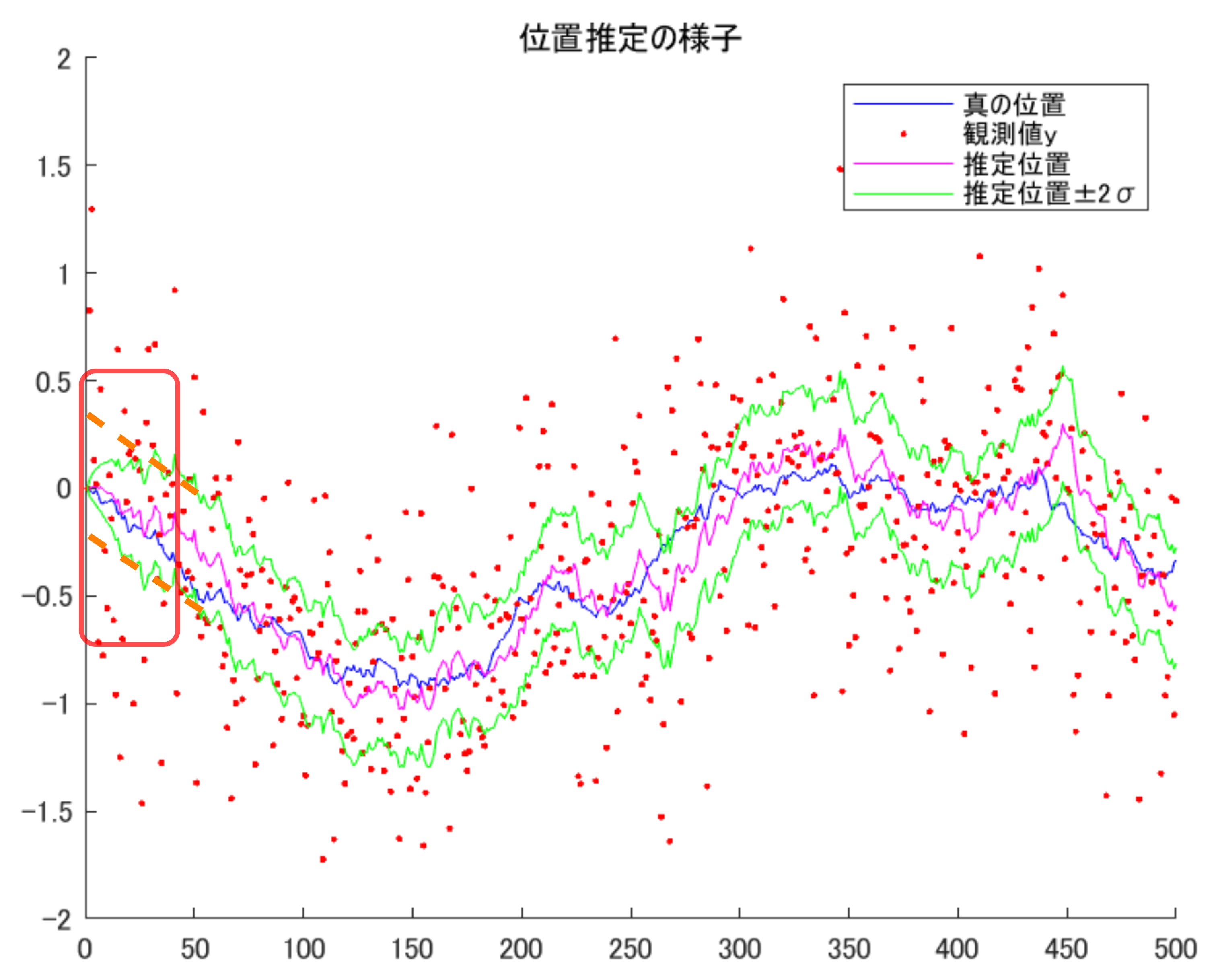
推定結果は下図です。横軸はステップ数であり、縦軸とともにラベルを省略してます。赤点が観測データ、青が真値、マゼンタが推定値です。
赤点はかなり観測ノイズで汚れていますが、その割には真値に近い値を推定できていると言えそうです。速度に関しても、ノイズの影響下にしてはある程度特徴をとらえて推定できていると言えそうです。緑線は、事後誤差共分散行列の対角要素のルートからとった、位置推定の誤差の標準偏差(の2倍)、速度推定の誤差の標準偏差(の2倍)を表します。
この緑線ですが、解釈が一クセあります。「誤差の標準偏差の2倍」を表現しているのですが、
- 観測値から求めているわけではなく、状態方程式の係数行列やノイズの分散の見積もり値から求まる線である(オフライン計算でも同じ値となる)。その意味で「推定値」というより「予測値」である
- いわゆる正規分布の±2σをプロットしていて、定性的にいうならおよそ95%の割合で真値がこの幅の範囲に入る。(が、厳密さを重視するならこうした議論は慎重にするべき)
特に後者は、いわゆる「信頼区間」とは微妙に異なる概念になっています。本記事では (統計警察が怖いので) あまり深入りしないことにします。

下図もあまり厳密な内容ではないですが、
- カルマンフィルタによって求まる事後誤差共分散行列の予測値(緑)
- オンライン計算で時々刻々求めた実際の誤差の2乗の期待値(赤)
をプロットしました。「誤差の2乗の期待値」は本来、単一シミュレーション内ではなく複数シミュレーションを走らせて複数試行での平均をとる必要がありそうですが、今回は簡易的に移動平均をとることで模擬しました(そっち方面にいくとアンサンブルカルマンフィルタになってしまいそうですね)。おおよそですが、緑線のカルマンフィルタの予測誤差と、赤線のシミュレーション内での実際の誤差から求めたものは大小関係があってそうです。
実はこの図P(1,1)・P(2,2)の緑線と、上の位置・速度推定の図での緑線の意味合いはほぼ同じです。上の図での緑線は、下図の緑線を標準偏差の2倍に直して、マゼンタの推定値に足し引きしただけ、というわけです。

カルマンゲインが時刻ステップでどう変化したかもプロットしました。上の図での誤差の共分散行列が落ち着くタイミングに合わせて、ゲインが一定値に収束しています。

また、先述の検証項目(3)として、時変のカルマンフィルタと、ゲインを固定化した定常カルマンフィルタの推定誤差についても比較しました。上の図でゲインが一定値になる(つまり誤差の共分散行列が一定値になる)タイミング以降の応答はまったく同じです。

上記の点を踏まえても、やはり正直「時変ゲインにする必要あるかなあ」という印象です。先に見せた位置推定の図をもう一度載せると下記で、赤で囲った部分の緑線は$P_0$がゼロのため初期値ゼロとなっています。オフライン計算で求めた$P_{k^\ast}$を初めから使うならオレンジ点線のようになるので、そちらの方がもっともらしいのでは…と感じます。
また、線形カルマンフィルタで応答初期の推定精度が求められるのってどんな状況だろう…というのもわかりません。この点は、詳しい方のご指摘をお待ちしたいと思います。
定常カルマンフィルタの周波数特性
さらに時不変の定常カルマンフィルタにすることの大きなメリットとして、周波数特性が調べられる点があります。定常カルマンフィルタの推定式を整理していくと、下記となります。
\begin{align}
\left(
\begin{array}{c}
\hat{p}_{k}\\
\hat{q}_{k}
\end{array}
\right) &= A\left(
\begin{array}{c}
\hat{p}_{k-1}\\
\hat{q}_{k-1}
\end{array}
\right) + K \left(y_k - c^T A \left(
\begin{array}{c}
\hat{p}_{k-1}\\
\hat{q}_{k-1}
\end{array}
\right) \right) \\
&= (I-Kc^T)A\left(
\begin{array}{c}
\hat{p}_{k-1}\\
\hat{q}_{k-1}
\end{array}
\right) + K y_k
\end{align}
シミュレーション条件で設定した係数行列を入れて整理すると、下記になります。$z$は伝達関数のシフトオペレータです。
\begin{align}
\left(
\begin{array}{c}
\hat{p}\\
\hat{q}
\end{array}
\right)
&= \left(I- \left(
\begin{array}{cc}
k_1 & 0 \\
k_2 & 0
\end{array}
\right) \right)\left(
\begin{array}{cc}
1 & T_s \\
0 & 1
\end{array}
\right) \left(
\begin{array}{c}
z^{-1}\hat{p}\\
z^{-1}\hat{q}
\end{array}
\right) + \left(
\begin{array}{c}
k_1 \\
k_2
\end{array}
\right) y \\
\left(
\begin{array}{c}
\hat{p}\\
\hat{q}
\end{array}
\right) &= \left(
\begin{array}{cc}
1-k_1 & (1-k_1)T_s \\
-k_2 & -k_2 T_s+1
\end{array}
\right) \left(
\begin{array}{c}
z^{-1}\hat{p}\\
z^{-1}\hat{q}
\end{array}
\right)
+ \left(
\begin{array}{c}
k_1 \\
k_2
\end{array}
\right) y \\
\left(
\begin{array}{c}
z\hat{p}\\
z\hat{q}
\end{array}
\right) &= \left(
\begin{array}{cc}
1-k_1 & (1-k_1)T_s \\
-k_2 & -k_2 T_s+1
\end{array}
\right) \left(
\begin{array}{c}
\hat{p}\\
\hat{q}
\end{array}
\right)
+ \left(
\begin{array}{c}
k_1 \\
k_2
\end{array}
\right) zy \\
\left(
\begin{array}{cc}
z-1+k_1 & T_s(k_1-1) \\
k_2 & z-1+k_2 T_s
\end{array}
\right)
\left(
\begin{array}{c}
\hat{p}\\
\hat{q}
\end{array}
\right) &= \left(
\begin{array}{c}
k_1 \\
k_2
\end{array}
\right) zy \\
\left(
\begin{array}{c}
\hat{p}\\
\hat{q}
\end{array}
\right) &= \left(
\begin{array}{cc}
z-1+k_1 & T_s(k_1-1) \\
k_2 & z-1+k_2 T_s
\end{array}
\right)^{-1} \left(
\begin{array}{c}
k_1 \\
k_2
\end{array}
\right) zy \\
\end{align}
あとは逆行列を求めるだけなのでSymbolic Math ToolboxやChatGPT等に処理させ、
- 観測値$y$から位置$p$の推定値への伝達関数
- 観測値$y$から速度$q$の推定値への伝達関数
を求めると下記になります。
\begin{align}
\frac{\hat{p}}{y} &= \frac{( k_{1}(z - 1) + k_{2}T_{s}\ )z }{(z - 1)^{2} + (k_{1} + k_{2}T_{s})(z - 1) + k_{2}T_{s}} \\
\frac{\hat{q}}{y} &= \frac{k_{2}(z - 1) z }{(z - 1)^{2} + (k_{1} + k_{2}T_{s})(z - 1) + k_{2}T_{s}}
\end{align}
この伝達関数の応答を確認するコードが下記です。(先のシミュレーションコードの続きです)
%%
% カルマンフィルタの位置推定・速度推定の伝達関数の特性を確認する
k1 = K(1,end);
k2 = K(2,end);
z = tf('z',Ts);
hatp_flt = (k1*(z-1)+k2*Ts) * z / ((z-1)^2 + (k1+k2*Ts)*(z-1) + k2*Ts);
hatq_flt = k2*(z-1)* z / ((z-1)^2 + (k1+k2*Ts)*(z-1) + k2*Ts);
[psim,tsim] = lsim(hatp_flt,y,steps*Ts);
[qsim,~] = lsim(hatq_flt,y,steps*Ts);
% 伝達関数に対する応答としても一致する
figure;
tiledlayout(2,1, 'TileSpacing','compact', 'Padding','compact');
nexttile;
plot(tsim,psim,tsim,hatx_fix(1,:))
nexttile;
plot(tsim,qsim,tsim,hatx_fix(2,:))
max(psim-hatx_fix(1,:)')
max(qsim-hatx_fix(2,:)')
figure;
bode(hatp_flt,hatq_flt)
grid on;
legend({'位置推定フィルタ','速度推定フィルタ'})
時系列データのところは全く同じなので省略して、周波数特性の結果のみ載せると下記です。直感どおり、位置推定フィルタはローパス特性、速度推定フィルタはバンドパス特性を持っていることがわかります。(位置推定フィルタでゲイン0[dB]を超える部分があるのがちょっと不思議ですね)

おわりに
「線形」カルマンフィルタに限って、色々な解釈を紹介しました。間違い、ご指摘等ありましたらお知らせください。読んでいただきありがとうございました。
-
「カルマンフィルタの基礎」, 足立 修一, 丸田 一郎, 東京電機大学出版局, 2012年,https://www.tdupress.jp/book/b349390.html ↩ ↩2 ↩3 ↩4
-
「線形カルマンフィルタの基礎」, 足立 修一 , 計測と制御 第 56 巻 第 9 号 2017 年 9 月号, https://www.jstage.jst.go.jp/article/sicejl/56/9/56_632/_pdf/-char/ja ↩ ↩2 ↩3 ↩4
-
「ガウス過程と機械学習」, 持橋 大地, 大羽 成征, 講談社サイエンティフィク, 2019年, https://www.kspub.co.jp/book/detail/1529267.html ↩