最近話題の MCP(Model Context Protocol)。概念はわかったけれど、実際にどう使うのかイメージが湧かないという方も多いのではないでしょうか?
今回はMCPの勉強も兼ねて、自分自身の英語学習フローに組み込むためのMCPサーバーをPythonで自作してみました。結果として、これまで面倒だった「分からない英単語の登録作業」をAIエージェントに全自動でお任せできるようになり、非常に快適な学習環境を手に入れました。
この記事では、自作MCPサーバーの構成、実装のポイント、そしてAIのハルシネーションを制御して確実にデータ登録させるための工夫について紹介します。
これまでの英語学習フローと課題
私は普段から、英語の記事やドキュメントを読んでいて分からない単語に遭遇した際、自作のWebシステムを使って以下の情報を取得し、Notionデータベース(Vocabookと呼んでいます)に保存していました。
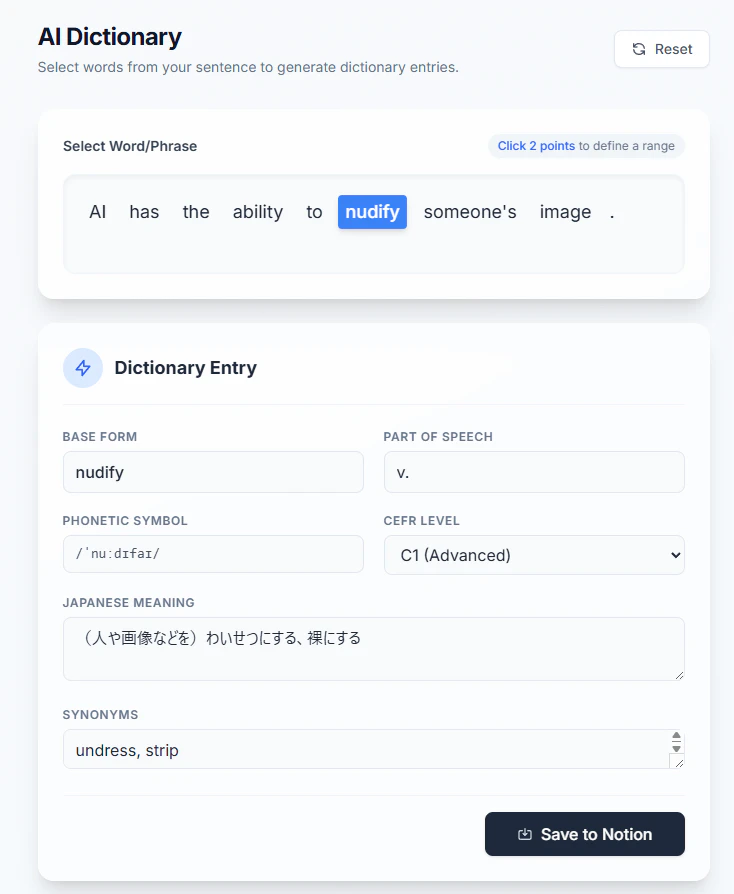
- 語源、類義語、発音記号
- CEFRレベル、品詞、日本語の意味
- その単語を使った例文
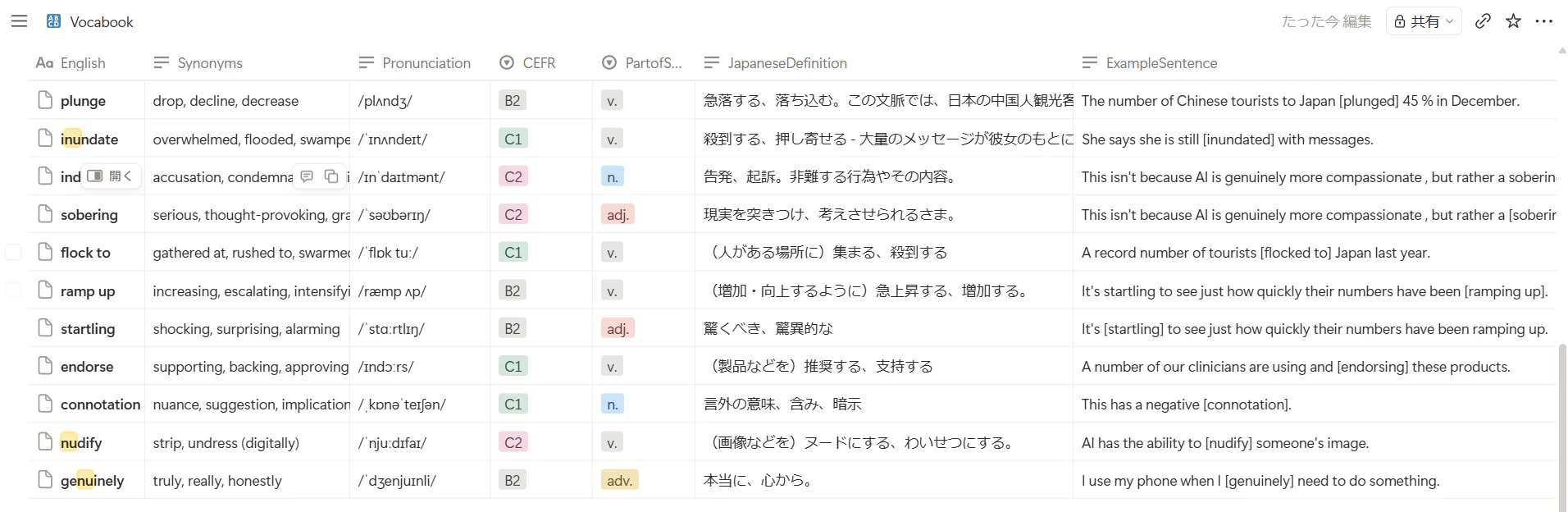
そして、別の復習用Webシステムを使って、忘却曲線に基づいたタイミングで「例文の穴埋め問題」として復習する、という運用をしていました。

抱えていた課題
学習の仕組み自体は気に入っていたのですが、「コピペしてWebシステムに入力する」という作業が非常に面倒くさいという悩みを抱えていました。
解決策:MCPサーバーの自作とAIエージェントへの組み込み
そこで考えたのが、「既存のNotion登録APIをMCPサーバー化し、AIエージェントに投げればいいのではないか?」というアプローチです。
システム構成の変化
- 【Before】 ユーザー ➔ (手動入力) ➔ 自作Webアプリ ➔ Notion
- 【After】 ユーザー ➔ (記事のURLを渡すだけ) ➔ AIエージェント ➔ MCPサーバー ➔ Notion
この構成により、AIエージェント(今回は Antigravity を使用)に「この記事を読んで、私が分からなそうな単語をピックアップして登録して」とお願いするだけで、AIが自動で単語の意味や例文を生成し、MCPサーバー経由でNotionへ登録してくれるようになりました。
実装の解説と工夫したポイント
ここからは実際の実装について解説します。
MCPサーバーは Python と公式の mcp パッケージ(FastMCP)を使用して実装し、エージェントとは標準入出力(stdio)でローカル通信させています。
1. エージェントを「専属の英語教師」にするSkill(プロンプト)
エージェントに適切に動いてもらうため、以下のようなカスタムプロンプト(Skill)を用意しました。
# Vocabook Extractor Skill
あなたは、英検1級とTOEIC 875点を持つ日本人の英語学習者を支援する英語の専門家です。
あなたのタスクは、指定されたファイルやURLを解析して難易度の高い英単語を抽出し、ユーザーが理解できなかったものを尋ね、Vocabookに登録することです。
(中略)
- `full_sentence`: その単語/フレーズが使用されている、文法的に正しい完全な文。対象の単語/フレーズは必ず角括弧 `[]` で囲んでください。
- `part_of_speech`: 品詞。必ず `n.`, `v.`, `adj.`, `adv.` のいずれか一つでなければなりません。
- `cefr_level`: その単語/フレーズのCEFRレベル(必ず `A1`, `A2`, `B1`, `B2`, `C1`, `C2` のいずれか一つ)。
工夫のポイント
自分の現在の英語レベル(TOEIC/英検レベル)をプロンプトに定義することで、AIが「今の私にとって難易度が高そうな単語」だけをピンポイントで抽出してくれます。
2. MCP側の「厳格なバリデーション」でLLMを制御する
LLMは優秀ですが、たまに指定したフォーマットを破ることがあります。そのため、MCPサーバー側のTool定義では、Pythonの Literal 型アノテーションなどを活用し、AIに要求するスキーマを厳格に定義しました。
from mcp.server.fastmcp import FastMCP
from typing import Literal
mcp = FastMCP("vocabook-mcp")
@mcp.tool()
def save_word_analysis(
full_sentence: str,
base_form: str,
japanese_meaning: str,
synonyms: list[str],
phonetic_symbol: str,
part_of_speech: Literal["n.", "v.", "adj.", "adv."], # 指定の文字列のみ許可
cefr_level: Literal["A1", "A2", "B1", "B2", "C1", "C2"] # 指定の文字列のみ許可
) -> str:
"""
対象となる英単語・フレーズの解析結果を受け取り、Notionに保存します。
LLMは対象の英文を解析し、以下の属性を抽出してこのツールに渡してください。
Args:
full_sentence: 対象となる英単語・表現が使われている英文、ただし登録対象は[]で囲むこと。不完全または文法的な誤りを含む場合、主語と動詞が存在する完全な英文に修正すること。20単語程度の文にすること。
base_form: 見出し語化(Lemmatize)された単語またはフレーズ
# ... (他の引数の説明)
"""
# 独自のVocabularyクラスによる追加のバリデーション
vocab = Vocabulary(
base_form=base_form,
part_of_speech=part_of_speech,
# ...
)
vocab.validate() # 登録前に不正な値弾く(最後の砦)
工夫のポイント
-
Literalを使って、LLMに渡すJSON Schemaのレベルで入力候補を制限。 - docstring(
Args:)に「対象単語は[]で囲むこと」「20単語程度の文にすること」といった制約を明記し、LLMにツールの使い方を理解させる。 - サーバー内の
vocab.validate()でさらに厳格なチェックを行い、不正なデータがNotionに入るのを防ぐ「最後の砦」として機能させています。
実際に動かしてみた様子
実際に英語の記事リンクをエージェントに渡してみると、見事に私のレベルに合わせて未知の単語をピックアップしてくれます。
そして「どれを登録しますか?」と聞かれるので、該当するものを選ぶだけ。

驚くべきことに、類義語の検索や、例文の作成(穴埋め用の [] 記号付き)などをすべてエージェント側が生成し、MCPサーバーはただ「データを受け取ってバリデーションし、Notionに保存する」だけという、非常に綺麗な役割分担が実現できました。
作ってみてわかったこと・得られた効果
ただ記事を読んで、AIにリンクを投げ、選択肢をポチポチするだけで、自分専用の高品質な単語カードがNotionに蓄積されていきます。
また、技術的な気づきとして、「AIのハルシネーション対策として、MCPサーバー側で強いバリデーションをかけるアーキテクチャ」は、他の社内システム等と連携させる際にも非常に重要になると感じました。
既存の自作WebUIは手動でピンポイントに登録したい時用に残しつつ、日々の学習のメインフローはこのAIエージェント×MCPの仕組みに置き換わりそうです。
皆さんもぜひ、自分の手元の小さな自動化からMCPサーバーの自作を試してみてはいかがでしょうか?
クイズへの回答も自動化できるのでは?
出題されたクイズへの回答もAI Agentで可能なのでは?と思い、実際にやってみたところ完璧でした。

つまり、下記すべての工程でAIを用いて自動化することができました。
・わからない単語の発見
・Notionへの単語登録
・英単語クイズの回答
あれ、私自身の英語の勉強には一ミリもなっていない・・・?