ABC 275 のA,B,C,D,E 問題を解くために考えたこと、ACできるPython3(PyPy3)コードを紹介します。
また今回、直接問題とは関係のない部分で筆者がひとりで考えても解決できなかった疑問点を最後に共有しています。わかる方がいらっしゃればぜひ教えてください。→ 筆者の疑問
この記事は @u2dayo さんの記事を参考にしています。見たことのない方はそちらもご覧ください。とても勉強になります。
また、問題の難易度を表す指標を Atcoder Problems から引用しています。このサイトは勉強した問題を管理するのにとてもオススメです。
質問やご指摘はこちらまで
Twitter : Waaa1471
作者プロフィール
Atcoder :緑 855
20221212 現在
目次
はじめに
A.Find Takahashi
B.ABC-DEF
C.Counting Squares
D.Yet Another Recursive Function
E.Sugoroku 4
はじめに
特にC問題以降になると、競技プログラミングに典型的な前提知識、少し難しい数学的考察が必要になり始めます。
しかし、公式解説ではこの部分の解説があっさりしすぎていて競技プログラミング(Atcoder)を始めたばかりの人にはわかりにくい、難しいと感じるのではないでしょうか。
またC++がわからないと、コードの書き方を勉強することが難しいです。一応、参加者全員のコードを見ること自体は可能ですが、提出コードは必ずしも教育的ではありません(ここで紹介する記事も本番で提出したものとは全く異なります)。そんなものから初学者が解説もなしになにか得ることはとても難しいと思います。実際適当に何人かのコードをみたものの、意味がわからずに終わった経験があるのではないでしょうか。
この記事がそんな方々の勉強の助けになればよいなと思っています。
A.Find Takahashi
灰色 14
考察
基本に忠実に ! 前から探索 !
橋の高さリストの最大値を max() 関数で調べて、その値を用いて index() 関数で目的の位置を求めても構いません。(別解参照)
しかし、ここでは前から一つ一つ橋の高さを調べて、その都度最大値とそのindex番号を保存していく処理で実装したいと思います。
また、橋の番号は 1 始まりであるのに対して、python のindex番号は 0 始まりです。この部分の調整のために、あらかじめ 0 本目に高さ 0 の橋を追加する ことにします。
コード
pypy3
N=int(input())
H=[0]+[int(h) for h in input().split()]
ans=0
Hmax=0
for i in range(1,N+1):
if H[i]>Hmax:
# 最大値を保存
Hmax=H[i]
# index番号を保存
ans=i
print(ans)
別解
N=int(input())
H=[0]+[int(h) for h in input().split()]
print(H.index(max(H)))
補足
- 全探索
このように前から一つ一つ調べていくことは 「全探索」といい、競技プログラミング(Atcoder) の一番基本的な問題解決手段です。
B.ABC-DEF
灰色 147
考察
素直に掛け算する
python3 の int 型は他の言語(特に C++ ) と違って、無限長の整数を扱うことができるため、オーバーフローを気にせず演算を行うことができます。
したがって、素直に $ (A×B×C)−(D×E×F) $ の計算を実行して最後に 998244353 で割った余りを求めることができます。
ただし、巨大数を扱う場合には単純な演算であっても計算量を考慮する必要があります。今回は高々 18 桁程度の整数の四則演算を何回か行うだけなので十分高速です。
コード
pypy3
A,B,C,D,E,F=[int(z) for z in input().split()]
MOD=998244353
print((A*B*C-D*E*F)%MOD)
補足
-
mod 計算
X mod(Y) = Z は X を Y で割ったときの余りが Z であることを示します。
筆者も高校で出会ったとき、なかなか理解するのに苦労した記憶があります。この動画で勉強しましょう。これは令和のスタンダードですが、数学でわからないことがあれば、まずヨビノリで調べてください。 -
四則演算計算量
N桁の整数の足し算・引き算は O(N)、掛け算・割り算は O(N^2) のようです。
計算量オーダーの求め方を総整理! 〜 どこから log が出て来るか 〜 -
計算量
そもそも計算量って何 ? という方は、こちらの A問題の補足でまとめたのでご覧ください。
C.Counting Squares
茶色 760
考察
「 正方形の個数を数えるために正方形の判定方法を考えよう 」とするより前に、まず一番初めに、対象を数えるためにどういう手段をとるべきか考えましょう。
例えば全く同じ設定で「二次元平面のポーンの数」を問われていた場合、A問題が解けたあなたは、なにも難しく感じることなく全探索してACできるはずです。
問題が複雑になっても基本は同じです。なにか数えたいのならまずは全探索できるか考える、そこから考察は始まります。
基本に忠実に ! 全探索 !
ある4頂点が正方形をなすかを考えるために、4頂点を全探索します。また、同じ正方形を数えても仕方がないので、その組み合わせを数えます。
探索後の判定処理をO(1)で実行できると仮定した場合、全体の計算量は O(4頂点の組み合わせの総数) になります。今回、二次元平面のマス目は 81なので、4頂点の組み合わせの数は最高でも 高々 $ 81C4 \ < 81^4 \ ≓ \ 3.6×10^7$ なので、十分高速に全探索できることがわかりました。
pythonでは itertools ライブラリの combinations 関数を使うことで、組み合わせのイテラブルが作成できます。
import itertools
S=[input() for _ in range(9)]
# ポーンのある位置のみを調べる
porn=[]
for i in range(9):
for j in range(9):
if S[i][j]=="#":
porn.append([i,j])
ans=0
# 4頂点の組み合わせを全探索
for (r1,c1),(r2,c2),(r3,c3),(r4,c4) in itertools.combinations(porn, 4):
正方形を判定する処理
あとは、4頂点のなす四角形が正方形なのかを判定して数え上げれば、この問題を解くことができる ! ところまで来ました。
四角形の正方形判定
ユーザー解説 で詳しく解説されていますが、
➀ 辺の長さが全て等しい
➁ 対角線の長さが等しく、その長さは辺の $√2 \ $倍
この2つの条件を満たす四角形を正方形と判定すればよいです。
ただし、2頂点を結ぶ線分が 辺 なのか 対角線 なのかは頂点の情報だけでは判別できません。そこで、考えられる全ての線分 (4C2本)を調べ、それらの大小関係を比較することで条件を満たすか判定することにします。もし、四角形が正方形ならば、線分を昇順で並び替えると (辺、辺、辺、辺、対角線、対角線) となることを利用する、ということです。
対角線のなす角が 90°の条件では ひしがた を正方形とみなしてしまうことに注意です。
正方形との定義は「4つの辺の長さが全て等しく、かつ、4つの角の角度が全て等しい四角形」です。
条件➁ はこの定義を満たす四角形の 対角線 と 辺 とがなす三角形に注目して、三平方の定理から「$√2×$辺の長さ = 対角線の長さ」が成り立つことを利用したものです。
コード
pypy3
4頂点全探索
import itertools
S=[input() for _ in range(9)]
# ポーンのある位置のみを調べる
porn=[]
for i in range(9):
for j in range(9):
if S[i][j]=="#":
porn.append([i,j])
ans=0
for (r1,c1),(r2,c2),(r3,c3),(r4,c4) in itertools.combinations(porn, 4):
rc=[[r1,c1],[r2,c2],[r3,c3],[r4,c4]]
# この四角形の任意の2頂点を結ぶ線分(辺および対角線)の長さを全て求めておく
L=[]
for (ri,ci),(rj,cj) in itertools.combinations(rc,2):
L.append((ri-rj)**2+(ci-cj)**2)
# 正方形判定
L=sorted(L)
flag=False
for i in range(1,4):
if L[i-1]!=L[i]:
flag=True
if flag:
continue
if L[-2]!=L[-1]:
continue
if 2*L[0]!=L[-1]:
continue
ans+=1
print(ans)
+α
4頂点の組み合わせを全探索できない場合
もしこの問題に 「 必ず200個以上ポーンがあるという」条件があった場合を考えましょう。このとき、4頂点の組み合わせの総数は $200C4 > 10^8$ より4頂点の組み合わせを全探索することはできません。
ではどうすればよいでしょうか。
より少ない頂点の組み合わせを全探索
実は、4頂点の組み合わせを調べることは非常に効率が悪いです。
下の図のように全頂点をわざわざ探索しなくても、3頂点がわかっていれば四角形が正方形をなすための残りの頂点の位置は一意に定まるからです。
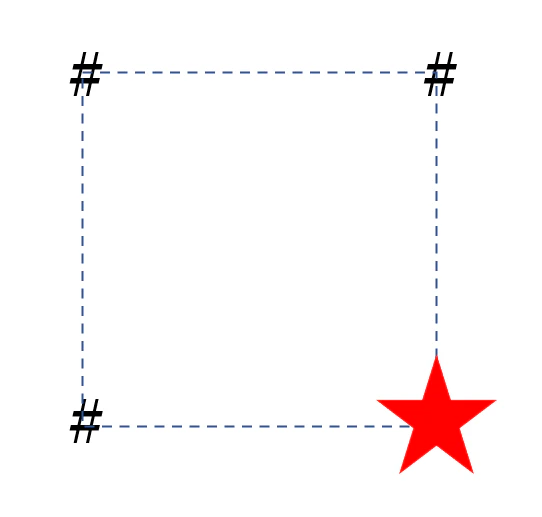
これによって、計算量は O( $200C3$ ) に改善され、この場合でも十分高速に実行できるようになりました。
ただし、この解法には大きな注意点が存在します
重複を回避
4頂点の組み合わせは必ず異なる四角形を成しましたが、3頂点の組み合わせは同じ四角形を成すことがあります。
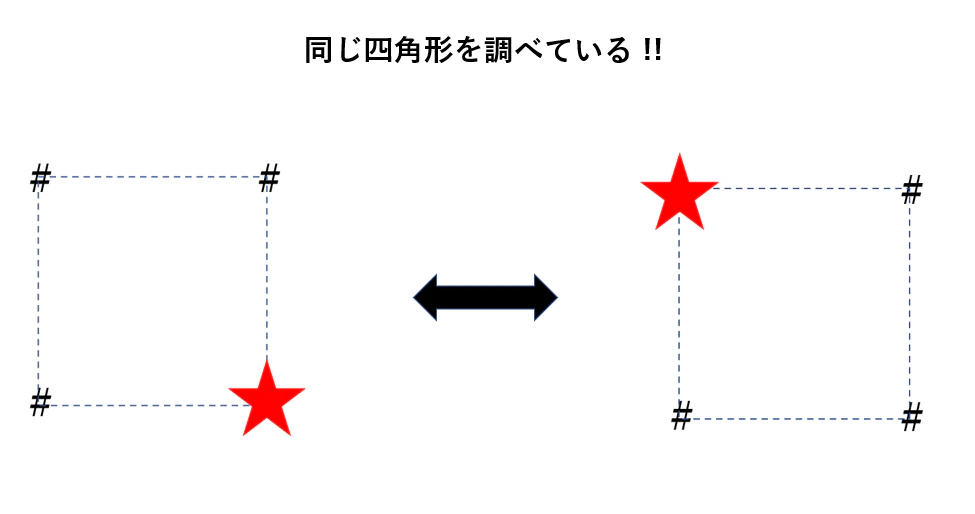
したがって、同じ正方形を重複してカウントしない ような処理を追加で施す必要があります。
ここでは、正方形をなす頂点の組み合わせを集合で管理する ことで、一度調べた正方形の再調査を防ぐことにします。
また、頂点の組を昇順に並べ替える ことで、頂点の登場順に依存しない管理を行います。
この管理方法について、abc276 ~ 280 までの A~D問題のどれかに類題があります。大きなネタバレになるので、まず解いてみたうえで参考にしてみてください。また、その際はこちらをご覧ください。
コード
pypy3
3頂点を全探索
import itertools
S=[input() for _ in range(9)]
ans=0
# 同じ正方形をカウントしないために、正方形を集合で管理する
sq=set()
# ポーンのある位置のみを調べる
porn=[]
for i in range(9):
for j in range(9):
if S[i][j]=="#":
porn.append([i,j])
for (r1,c1),(r2,c2),(r3,c3) in itertools.combinations(porn,3):
RC=[[r1,c1],[r2,c2],[r3,c3]]
# この3頂点を結ぶ線分を四角形の辺と仮定する
for m in range(3):
a1,b1=RC[m][0],RC[m][1]
a2,b2=RC[(m+1)%3][0],RC[(m+1)%3][1]
a3,b3=RC[(m+2)%3][0],RC[(m+2)%3][1]
dist1=(a2-a1)**2+(b2-b1)**2
dist2=(a3-a1)**2+(b3-b1)**2
# 正方形の条件➀ : 辺の長さは全て等しい
if dist1!=dist2:
continue
# 残りの頂点は一意に定まる
a4,b4=a2+(a3-a1),b2+(b3-b1)
if not (0<=a4<9 and 0<=b4<9):
continue
if S[a4][b4]==".":
continue
tmp=tuple(sorted(((a1,b1),(a2,b2),(a3,b3),(a4,b4))))
# 過去に同じ正方形を調べていればスキップ
if (tmp) in sq:
continue
dist3=(a4-a1)**2+(b4-b1)**2
dist4=(a3-a2)**2+(b3-b2)**2
# 正方形の条件➁:2つの対角線の長さは等しく、辺の√2倍
if dist3==dist4 and dist3==2*dist1:
ans+=1
# 正方形を成す辺の組を集合で管理
# 辺の組は昇順に並べ替える
sq.add(tuple(tmp))
print(ans)
さらに厳しく
3頂点の組み合わせの全探索すらできない制約の場合には、2頂点の組み合わせを全探索することになります。
この場合も当然重複回避のために工夫が必要です。気になる方は、ユーザー解説をご覧ください。めちゃくちゃわかりやすく解説されています。
このように、効率的な探索には重複回避、工夫した探索方法の実施が必要になるため問題が複雑化してしまいます。
どんな人間もミスが生じることがあり、考慮すべきことが増えれば増えるほどその確率はあがります。したがって、制約が許すなら何も考えずできる全探索をすることが一番です。最も粗い全探索が圧倒的に最強ということです。
補足
-
組み合わせ
Pythonで階乗、順列・組み合わせを計算、生成
itertools は他にも便利な関数がたくさんあるので、出てくるたびに覚えましょう -
正方形定義 (再掲載)
wiki -
関連問題 (制限あり全探索)
abc179C A x B + C
abc227c ABC conjecture -
効率的な管理方法 類題 (本文そのまま抜粋)
この管理方法について、abc276 ~ 280 までの A~D問題のどれかに類題があります。大きなネタバレになるので、まず解いてみたうえで参考にしてみてください。また、その際はこちらをご覧ください。
D.Yet Another Recursive Function
茶色 606
考察
ちょうど良いのでサンプル2 で実験すると図のようになります
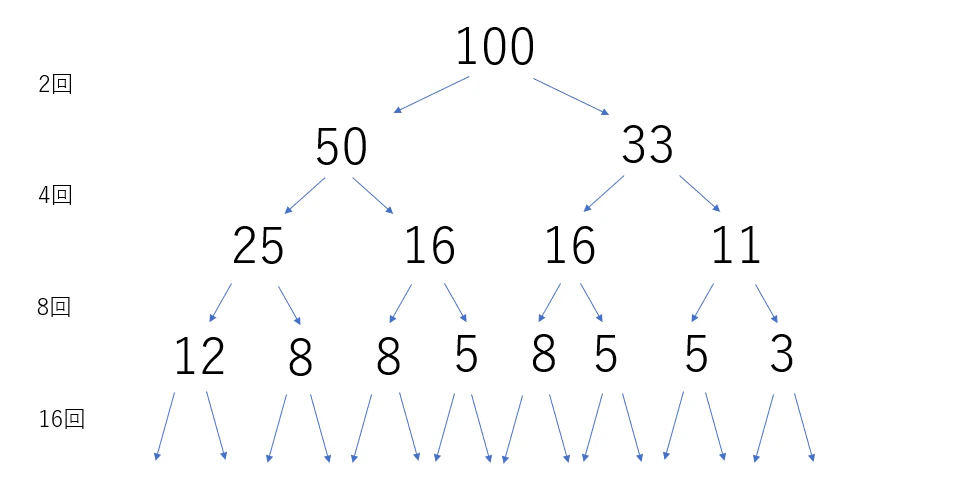
割算の必要回数は指数関数的に増えるので、$\ N=10^{18}\ $ であった場合、感覚的に間に合いません。
実際、$ 10^{18} = 2^{60} $ より、N を2で割り続けられる回数は 60回程度なので、$\ 2^{60}$ 回の計算が必要になる可能性があることが分かります。
なにか工夫して、計算量を改善できないでしょうか?
注目すべきは同じ数字です。同じ数字はまとめることができそうです。
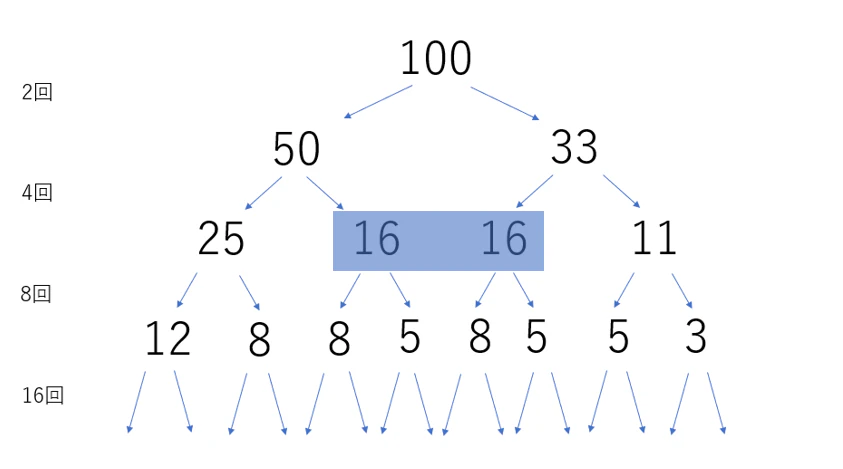
16 、さらにその下流の 5 と 8 もまとめることができます。割算回数を表す矢印の数が少なくなっているのが分かります。
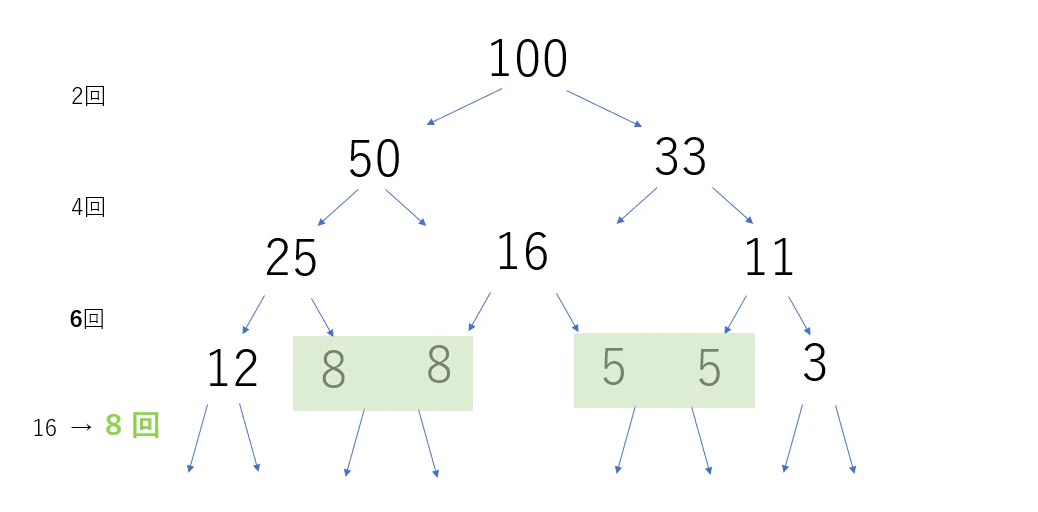
実験例に表した上流工程で数が削減できると、ドミノ倒しの要領で計算量は削減されていきます。
具体的には以下のような考察で十分高速だと判断できそうです。
計算量は登場する整数の種類に比例する。また、N を1層目と考え、割算を行うことで2層、3層と深くなっていくと定める。i層目の Xi個の整数に対して、$2^0 × 3^{Xi} , 2^1 × 3^{Xi-1} , 2^2 × 3^{Xi-2} , ..... , 2^{Xi} × 3^0$ で割ることで新しい整数が $Xi+1$ 個生まれることになる。
したがって、Nは最高でも 2で 60回しか割れないことを考えると整数の種類は $1+2+3+...60 \ ≓ \ 1800 $ 程度である。
以上より計算量は $O(2.0×10^3)$ となって十分高速と判断できる。
実装
必要な情報は以下2つです。
➀ 登場した整数の種類
➁ その個数
個数は Counter で管理するとして、整数をリストに格納して操作を行うことは次のようなイメージになります
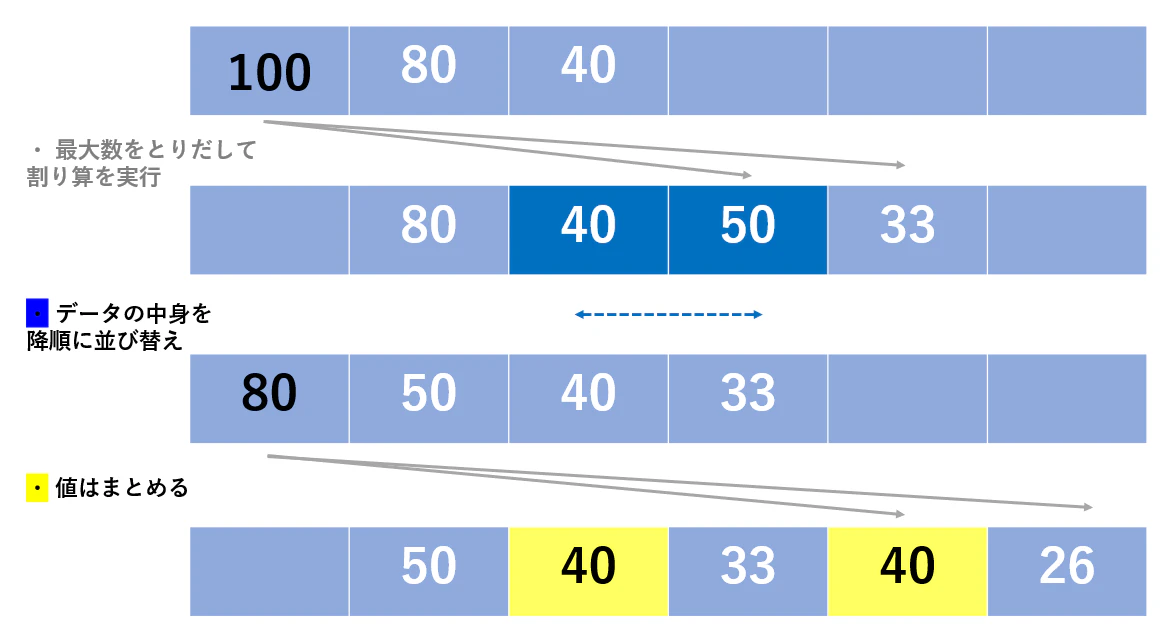
現時点で持っている最大値をとりだして、割算を行って値をまとめていくことを考えると、整数は降順に並んでいることが望ましいです。リストの中身が空になるまで先頭の値をとりだして割算 → リストを並び替え → 先頭の値をとりだして割算 → リストを並び替え ... を繰り返します。
しかし操作毎にリストを並び替える場合、その時点の要素数をX個とすると、$O(XlogX)$ の計算量が必要になってしまいます。
そこで、その時点での最大値さえわかれば、その他の順番はどうでも良いことに注目して、「 優先度付きキュー(ヒープ) 」で整数を管理することにします。ヒープからの最大値の取り出し、値の追加は $O(logX)$ で行えるので、十分高速です。
ただしヒープは最小値の管理しかできないので、ヒープには整数を -1 倍した値を追加し、最大値の取り出し時に、-1倍してもとに戻す 処理を施しています。
常に負の数で整数を扱ってしまうと、今度は切り捨て演算に影響を及ぼす 可能性があることに注意が必要です。
コード
pypy3
from collections import Counter
from heapq import heapify,heappop,heappush
N=int(input())
L=[-N]
# リストをヒープ化
heapify(L)
# 同じ整数の個数を管理
X=Counter()
X[N]+=1
ans=0
while L:
# 一番でかい整数をとりだす。
now=-heappop(L)
if now==0:
ans+=1*X[now]
nex1=now//2
# 既に同じ整数がある場合はヒープに追加しない
if not X[nex1]:
# 負数にして追加
heappush(L,-nex1)
# 個数を追加
X[nex1]+=X[now]
# 3で割る場合も同様
nex2=now//3
if not X[nex2]:
heappush(L,-nex2)
X[nex2]+=X[now]
print(ans)
ちなみに
最大値をとりださなくても、整数の並びが降順になっていなくても計算量は $O(10^3)$ より少し効率が悪い程度です。
そのため整数を登場順に取り出しても十分高速です。ただし、先頭から値をとりだすために、リストではなく deque を使います。
pypy3
from collections import deque,Counter
N=int(input())
que=deque()
que.append(N)
X=Counter()
X[N]+=1
ans=0
while que:
now=que.popleft()
if now==0:
ans+=1*X[now]
X[now]=0
continue
if not X[now//2]:
que.append(now//2)
X[now//2]+=X[now]
if not X[now//3]:
que.append(now//3)
X[now//3]+=X[now]
X[now]=0
print(ans)
ちなみにちなみに
公式解説ではメモ再帰をとても簡潔に実装しています。
@ lru_cache(maxsize=None) デコレータを関数の頭につけるだけで、その関数が再び同じ引数で呼び出された場合に、$O(1)$ で返り値を出力することができるという仕組みです。なお(maxsize=None)はメモ化上限を設定しないことを示しています。default では128個以上記録してしまうと古い方から忘れてしまうので注意が必要です。
補足
-
Counter
collectionsライブラリをインポートすることで利用できます。
個数管理は頻出ですので必ず使いこなしましょう。
参考 : PythonのCounterでリストの各要素の出現個数をカウント -
優先度付きキュー(ヒープ)
基本的な概念の理解にはこちらが役立ちます
優先度付き待ち行列 - アルゴリズムとデータ構造 - 未確認飛行 C
また、pythonでの実装のためにはこちらがおすすめです。
優先度付きキュー(ヒープ)とPythonで実装するライブラリ「heapq」について -
切り捨て演算
print(15//2) # 7 print(-15//2) # -8負方向へ切り捨てが行われるので、負の範囲では絶対値が大きくなるような変化が生じます。
int(a/b)で 全ての範囲で 0に近付ける切り捨ては実現できますが、/ 演算では小数計算が生じるので、誤差が生じる可能性があります。お勧めしません。
参考
浮動小数点演算、その問題と制限 -
deque
Pythonのdequeでキュー、スタック、デック(両端キュー)を扱う
deque の使い方を勉強できます。他の問題(尺取り法など)でも使う基本的なデータ構造なので絶対覚えましょう。 -
メモ化再帰
python3.2以降のlru_cacheが素敵すぎて。
使い方はこちら
E.Sugoroku 4
水色 1264
考察
状況を把握するために、すごろくゲームをシミュレーションしてみます。
すると、$k$ 回目にあるマス $X$ に存在する場合、$k+1$ 回目に $X+1\ ~\ X+M$ のマスに等確率で到達できることがわかります。( ただしゴールを超える場合は $N-(X+M-N)$ のマスに到達する)
したがって、
1, 試行回数
2, マス目
3. 到達確率
これら 3つの情報で状態を定義することで、状態の遷移に忠実に全ての状態を更新させることができそうです。
状態の遷移は 動的計画法 (DP) で行うことが頻出です。また、1 ~ 2 の情報で 3 を管理すると考えると、2次元 dpテーブル (リスト) を作成することになりそうです。考えられるすべての状態を管理するためには、テーブルのサイズは $N × K$ である必要があります。各試行で 1 ~ Mマス先のマスに到達する可能性があることを考えると、各状態に対して $O(M)$ の操作が必要になりそうです。したがって、計算量は $O(NMK)$ になりますが、これは十分高速です。
確率の管理
確立は「 条件を満たす場合の数 ÷ 総数 」で表せます。
つまり、総数が同じ状況では確率は場合の数に一致します。よって、例えば次のような状況では、場合の数で状態を管理することができます。
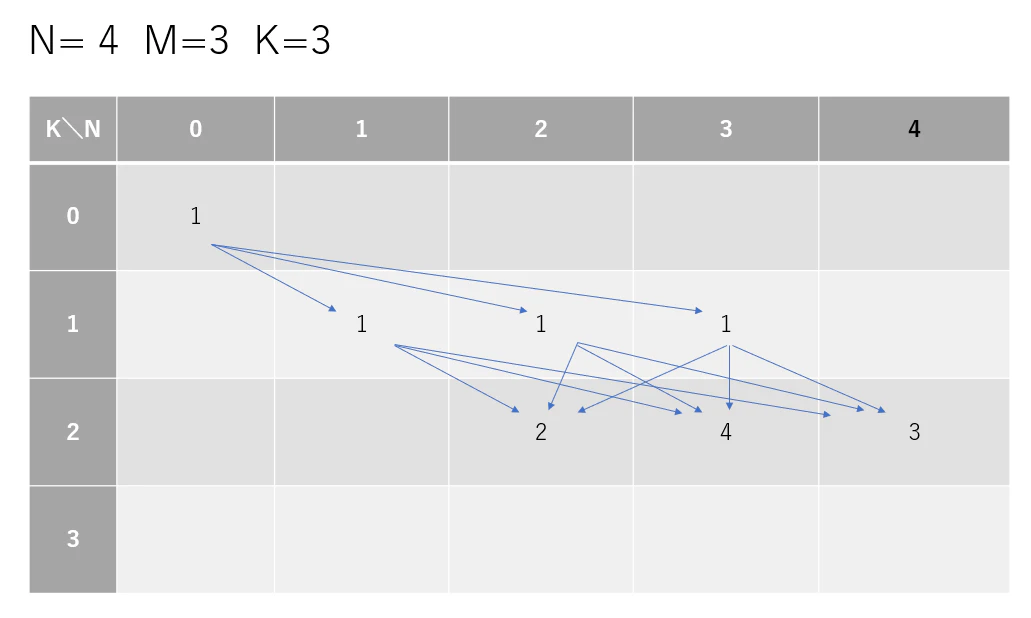
問題になるのは次の試行時です。 K=2 においてゴールした 3回と、次の試行(k=3)でゴールする 6回 の確率は同様に確からしくないので、単純に場合の数を足すことはできません。
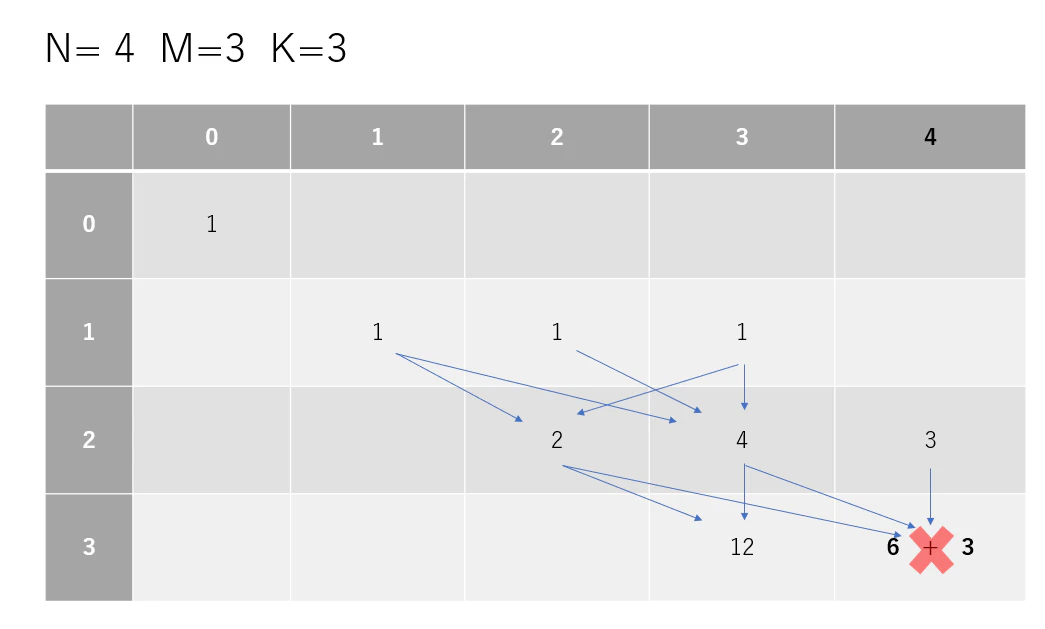
ここで、一旦 mod を無視すると、求める確率 $S$ は以下のように表せます。
\begin{align}
S\ &= \ \sum_{k=1}^{N} \frac{G_k}{M^{k}} \\
&= \frac{G_1 × M^{K-1} \ + G_2 × M^{K-2} \ + \ ..\ + G_k × M^{K-k} \ + \ ..+ G_K × M^0}{M^{K}}
\end{align}
ここから、k回目にマス Nに到達できる場合の数 $G_k$ に $M^{K-k}$ をかけた $ G' =\ G_k × M^{K-k} $ を 見かけの場合の数 とすれば場合の数で状態を管理できると考えられます。
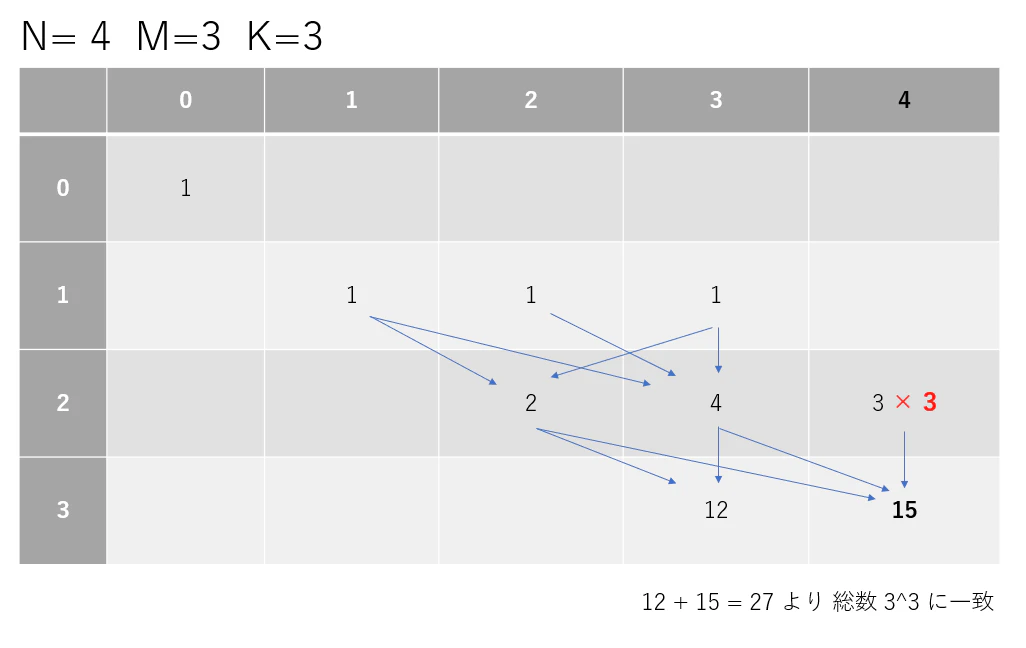
したがって場合の数で状態を更新していくことで、テーブル右下に見かけの場合の総数 $ \sum_{k=1}^{N} G'_k $ が得られます。
あとは $ S= \frac{\sum_{k=1}^{N} G '_k}{M^{K}} \ (modP)$ を求めるだけです。
分数の mod は分母の逆元をフェルマーの小定理から求めることで計算可能です。
コード
pypy3
O(NMK)
N,M,K=[int(nmk) for nmk in input().split()]
MOD=998244353
dp=[[0 for _ in range(N+1)] for _ in range(K+1)]
dp[0][0]=1
ans=0
for k in range(K):
for j in range(N):
if dp[k][j]>0:
for m in range(1,M+1):
if j+m<=N:
dp[k+1][j+m]+=dp[k][j]
# ゴールを超えてしまった場合
else:
dp[k+1][N-(j+m-N)]+=dp[k][j]
# k+1 回目にゴール出来る確立は dp[k+1][-1]*M(K-(k+1))/M^K
if dp[k+1][-1]>0:
ans+=dp[k+1][-1]*(M**(K-(k+1)))%MOD
ans=(ans*pow(M**K,MOD-2,MOD))%MOD
print(ans)
+α
M が大きい場合
今回 $ 1≦ M ≦ 10 $ の制約にかなり救われています。$ M=100$ であればこの処理では間に合いません。
そこで、より高速な解法を紹介します。
imos法
imos法によって状態の更新を O(1)で行うことで計算量を抑えることができます。
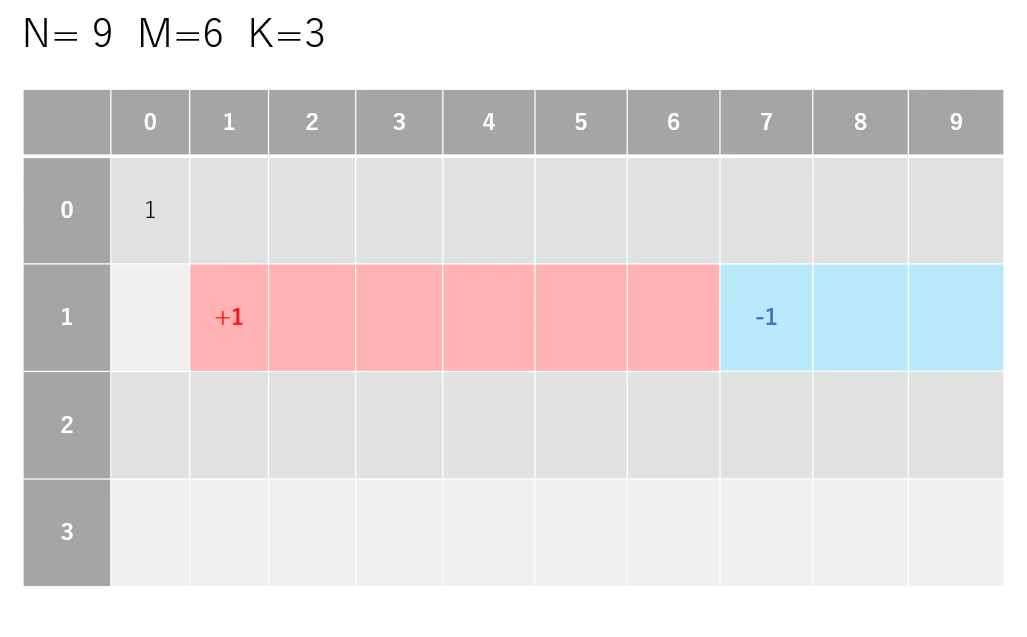
図のように、到達しうるマス目(赤い範囲:1 ~ 6) の先頭(1)と、到達しないマス目 (青い範囲 : 7~9) の先頭(7) のみを更新します。
この後、k=1 の一次元リストの累積和をとることで、状態が正しく更新されることになります。
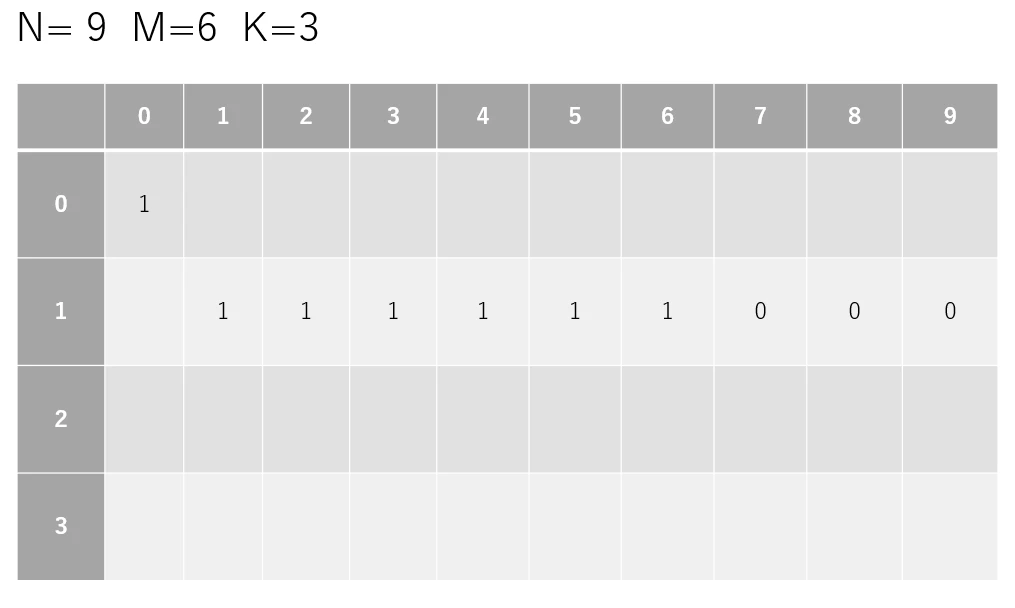
ここでは、ゴール超過処理のために dpテーブルのサイズを $ (N+M)K $ に変更し、超過を無視して状態を更新した後に適切な位置の状態を再更新することにします。
imos 法で実装する場合にはこちらの工夫が効果的です。
計算量は $ O((N+M)K)$ になります
※※ 筆者の疑問 ※※
pypy3
imos 法で高速化
import itertools
N,M,K=[int(nmk) for nmk in input().split()]
MOD=998244353
dp=[[0 for _ in range(N+1+M)] for _ in range(K+1)]
dp[0][0]=1
ans=0
for k in range(K):
for j in range(N):
# imos法で 1~Mだけ進んだ状態を操作
if dp[k][j]>0:
dp[k+1][j+1]+=dp[k][j]
dp[k+1][j+M+1]-=dp[k][j]
# 塁積和をとって状態を更新
dp[k+1]=list(itertools.accumulate(dp[k+1]))
# ゴールを過ぎてしまった場合の数を調整
for m in range(1,M):
dp[k+1][N-m]+=dp[k+1][N+m]
# k+1 回目にゴール出来る確立は dp[k+1][-1]*M(K-(k+1))/M^K
if dp[k+1][N]>0:
ans+=dp[k+1][N]*(M**(K-(k+1)))%MOD
ans=(ans*pow(M**K,MOD-2,MOD))%MOD
補足
-
pow(a,b,M)
a^b (mod M) を より高速に求められる
組み込み関数 -
フェルマーの小定理
フェルマーの小定理の証明と例題
フェルマーの小定理の意味と証明が死ぬほどわかりやすくまとめられています。分からない方は絶対見てください。 -
imos 法
imos法
製作者本人がわかりやすく解説してくれているので、こちらをご覧ください。
筆者の疑問
imos法での実装は計算量 O((N+M)K) なので、N=M=K=1000 であっても十分高速に処理できると思っていました。
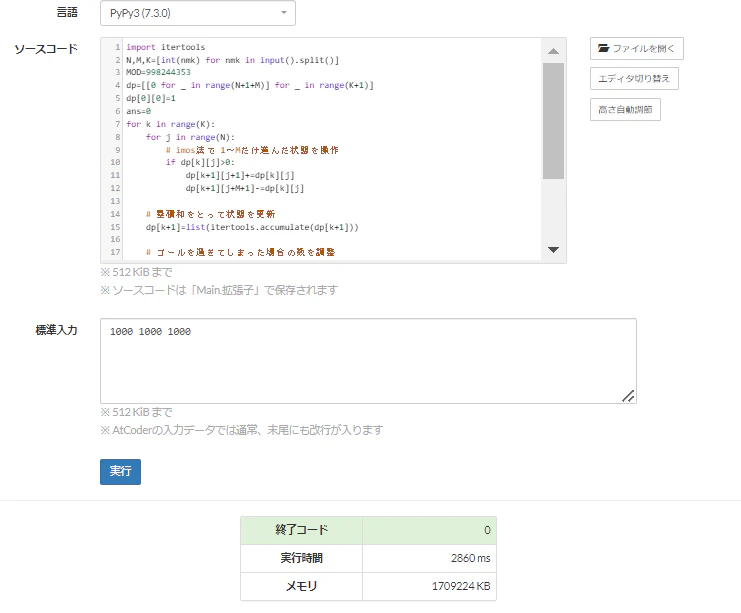
しかし、コードテストで確認してみると 2000 sec を超えてしまいます。
計算量推定のどこかで勘違いしているのかと検討したのですが、わからないままです。わかる方がいらっしゃればぜひ教えてください(; ;)
終わり
過去のコンテストも随時更新していきます。絶対見逃すなよ!!