ABC279 のA,B,C,D問題を解くために考えたこと、ACできるPython3(PyPy3)コードを紹介します。
この記事は @u2dayo さんの記事を参考にしています。見たことのない方はそちらもご覧ください。とても勉強になります。
また、diffは問題の難易度を表す指標です。Atcoder Problems から引用しています。このサイトは勉強した問題を管理するのにとてもオススメです。
質問やご指摘はこちらまで
Twitter : Waaa1471
作者プロフィール
Atcoder :緑 829
22/1207 現在
目次
はじめに
A.wwwvvvvvv
B.LOOKUP
C.RANDOM
D.Freefall
はじめに
特にC問題以降になると、競技プログラミングに典型的な前提知識、少し難しい数学的考察が必要になり始めます。
しかし、公式解説ではこの部分の解説があっさりしすぎていて競技プログラミング(Atcoder)を始めたばかりの人にはわかりにくい、難しいと感じるのではないでしょうか。
またC++がわからないと、コードの書き方を勉強することが難しいです。一応、参加者全員のコードを見ること自体は可能ですが、提出コードは必ずしも教育的ではありません(ここで紹介する記事も本番で提出したものとは全く異なります)。そんなものから初学者が解説もなしになにか得ることはとても難しいと思います。実際適当に何人かのコードをみたものの、意味がわからずに終わった経験があるのではないでしょうか。
この記事がそんな方々の勉強の助けになればよいなと思っています。
A.wwwvvvvvv
灰色 diff 7
考察
前から順に調べよう
V= 1 , W= 2 と読み替えたときの文字列の総和を求めればよいです。
ここでは基本に忠実に、文字列を前から順に調べていくことにします。
コード
pypy3
S=input()
ans=0
for s in S:
if s=="v":
ans+=1
else:
ans+=2
print(ans)
補足
なし
B.LOOKUP
問題
灰色 diff 39
考察
文字列検索
Python3.8 (PyPy3(7.3.0)) では文字列の包含関係を in で簡単に調べることができます。
コード
pypy3
S=input()
T=input()
if T in S:
print("Yes")
else:
print("No")
補足
過去にも A,B 問題で同じような問題が登場しているので、ここで覚えておきましょう
C.RANDOM
問題
灰色 diff 272
考察
" # " と" . " からなる H 行 W 列の S,T について、列を並び替えると一致するのか問われています。
素直に考えると、S の各列について T に同じ列が存在するか判定する処理を繰り返せば良さそうです。
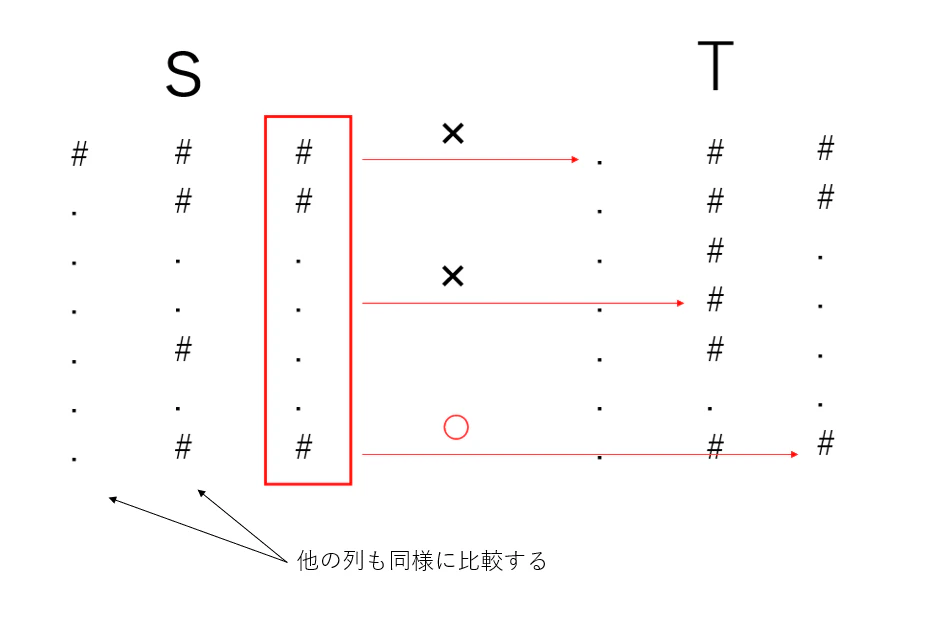
計算量は S,T それぞれの列を全て比較することを考えると O(HW^2)になります。(W^2 回 O(H) の比較処理を行うため)
ここで 1 < H,W < 4*10^5 より、この処理では制限時間に間に合いません。悔しいですが別の方針をたてる必要があります。
遅さの理由を考える
全く新しい方針をゼロから考える前に、まず先ほどの処理がなぜ遅いのか? ボトルネックを見つけて計算量を削減できないか? 考えてみましょう。
ここで注目するのは T の調べ方です。何度も何度も同じ列を調べていますが、これは必要なのでしょうか?
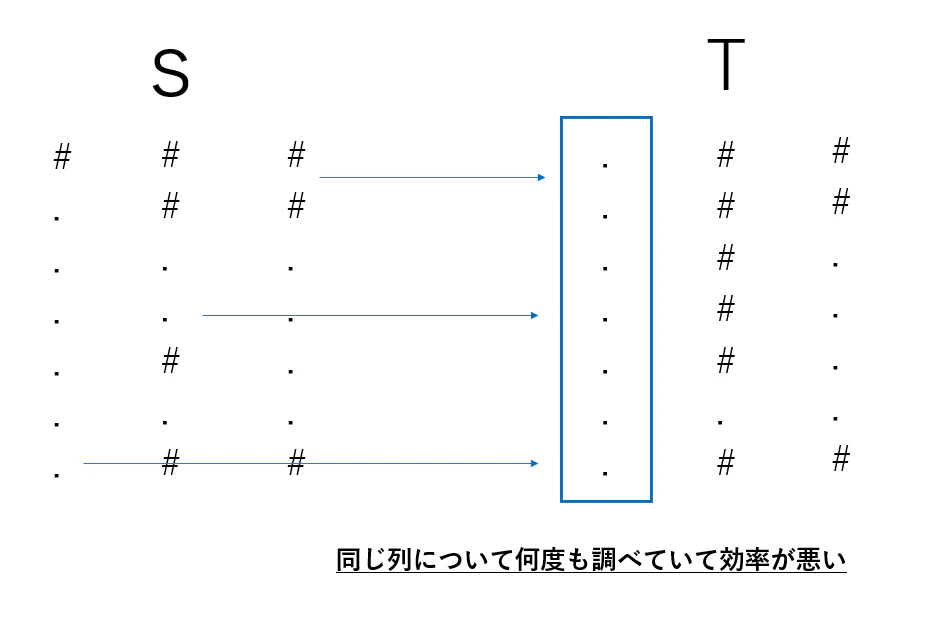
この処理を改善してみましょう
一致した列を二度と調べない
一度一致した列を何度も調べる必要はないので、一致した T の列を flag かなにかで管理してスキップする処理を実行するのはどうでしょうか?
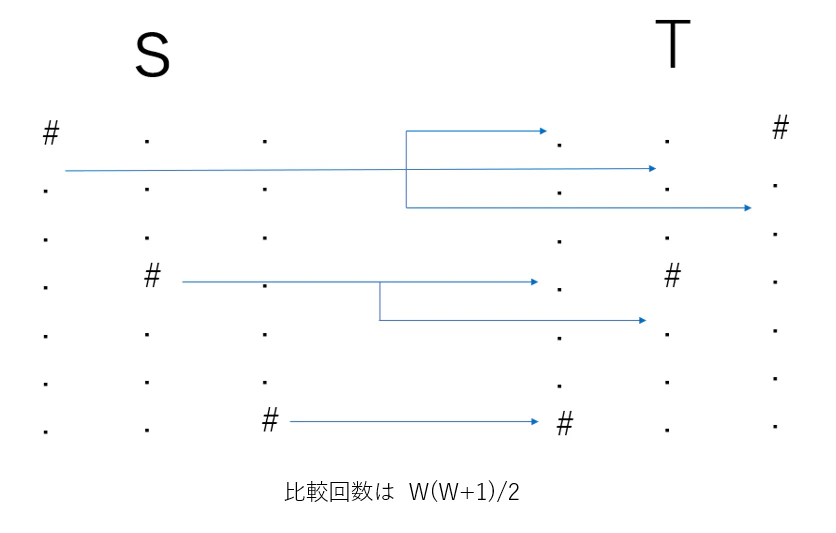
この場合、上図のように S,T が鏡合わせになっている場合に最も計算回数を削減できません。
このとき、W + W-1 + ... 2 + 1 = W(W+1) 回 比較しなければならないので、まだ間に合わないままです。
この工夫のイマイチなところは、何度も調べる T の列を結局なくすことができていない (部分的に減らしているだけに過ぎない)ところです
では、どうすればこの課題を解決できるでしょうか。
こういうときは少し発想を変えて、そもそも列の再調査が発生しない調べ方とはどのようなものか考えます。
例えば、S のどの列と T どの列を比較すべきか、もしあらかじめ決まっていれば不必要な列同士の比較を行わずに済みます。計算量はO(HW)に改善されて十分高速になりました。
つまり、前から順に適当に比較していくのではなく、都合が良い順番で比較するのが効率的であるということになります。
これは、身近なひらがなの文字列を例にして考えてみると分かりやすいです。ばらばらな文字列でも、一度「あいうえお」順に並び替えることで効率的な比較を実現できるようになります。

つまり、S,T をそれぞれ sort して列を前から順に比較すればよいということがわかりました。
計算量は O(HWlogHW) に増えますがこれでも十分高速です。
列の比較 < 行の比較
さて、ここまで無視してきましたが、実は列の比較処理はとても面倒くさいです。2次元リストを行方向に探索し、その行の一次元リストを比較することは簡単にできても、列方向に探索することはできないからです。
そこで、二次元の行と列を入れ替えることにします。これにはnumpy が便利なので利用しています。なお、numpyはpypyで扱えないのでPython3での実装になります。
計算量はnumpy の計算量の詳細がわからないのですが、転置処理のコストは配列の要素数に比例する O(HW) だと考えられます。したがって、ソートがボトルネックになり O(HWlogHW)で、これならば Pythonでも通りそうです。
コード
Python3
import numpy as np
H,W=[int(hw) for hw in input().split()]
S1=[]
for _ in range(H):
s=list(input())
S1.append(s)
# ndarryに変換して転置を行う
S1=np.array(S1)
S1=S1.T
# 二次元リストへ戻す
S1=S1.tolist()
# ソート
S1=sorted(S1)
S2=[]
for _ in range(H):
t=list(input())
S2.append(t)
S2=np.array(S2)
S2=S2.T
S2=S2.tolist()
S2=sorted(S2)
for h in range(W):
if S1[h]!=S2[h]:
print("No")
exit()
print("Yes")
補足
-
二次元リストのソート
リストが行方向に昇順で並び変ります。各一次元リストの中身はsortされません。
Pythonで2次元配列(リストのリスト)をソート -
numpy
機械学習では頻出のベクトル、行列計算のためのライブラリです。筆者はAtcoderではほとんど利用していません。特別な行列処理のほかに複数の要素を一度に二分探索したいときなどに利用することとがたまにある程度です。
参考
numpy を用いた転置 : numpyを利用しない転置の方法も記載されています。
np.searchsorted : np.soretd(A,V) で二分探索できるのですが、Vに配列を与えるとVの各要素が A のどの位置に挿入位置されるかを表す配列が返ります
Akariさん:numpyを利用している青色の方です。かなりめずらしいのでnumpyを利用している方にとってはとても参考になると思います。 -
計算量 (初学者向け)
こちらの A 問題補足で計算量についてまとめているのでわからない方はご覧ください -
難易度
テストコードがガバガバだったようです。diffにも少しは影響していると思います。おそらくですが、本来は茶色くらいの難易度はあるのではないかと思います。
D.Freefall
茶色 766
考察の前に
このトピックは、この記事が想定している読者でもある、数学がわからない方、苦手な方にむけたものです。Atcoderにおける問題の傾向(Dまで)についても触れていますが、この問題には一切関係ないので、興味のない方は考察まで飛んでください
残念ながらこの問題を解くには、基本的な数学Ⅲの知識が必要です。そのため数学に苦手意識のある方や未学習の方にとっては簡単なものではないと思います。なるべくわかりやすく考察を書きましたが、それでも難しいかもしれません。
ぜひそういった方にこそ、この部分を読んでいただきたいです。この問題を通じてAtcoderの問題の傾向を理解し、自分の目的を効率的に目指しましょう。
わからないままで良いと考える
大真面目に、戦略として十分有効な判断です。なぜなら、D問題までにこういった数学の前提知識が必須な問題は 5 %にも満たないほどのレアケースだからです。(体感です。データはないです。)
例えば、茶色を目指している人にとっては基本的なアルゴリズムを勉強するほうが遥かに有意義です。こんな問題、次いつ出るかわかりません。もしかしたらあなたが辞めるその日まで一度も出てこない可能性すらあると思います。しかし、ほかのアルゴリズムであれば次の回で出題されてもおかしくありません。実際、筆者はちょうど20回本番に参加していますがここまでガッツリ数学が要求されたのは初めてだと感じる一方、BFS,DFS,UnionFindなどのグラフアルゴリズムは幾度となく出題されています。
少し言い過ぎたかもしれませんが問題の傾向を考えると、わざわざ直接的でない数学の勉強を始める、やり直すことはめちゃくちゃ効率が悪いということです。完全網羅は理想ですが、必要に応じて優先順位をつける、取捨選択することは何事においても大切です。
しっかりと問題の傾向を理解したうえで選択を行うことは、決して「逃げ、甘え」ではありません。少なくとも、執筆時の作者のレート上下 +100 までを目指す程度ならもっとほかにやることがあると言えます。
もしあなたが中学生以下の方で、プログラミングを簡単にはじめてみたという場合でも、この問題を解く必要はないかもしれません。高校生になって数学Ⅲを勉強してから改めて解いてみてもいいと思います。
勉強する
問題の難易度が上がるほど、知識も高度なものが要求されるのは当然です。既にある程度のレートであってかつ、より高みを目指すのであればやるしかないです。
幸い時代は令和です。いくらでも勉強する、やり直すチャンスはあります。わざわざ参考書を買わずとも、無料でこういった動画を入り口にすることができます。学校の授業はダメでも、今なら自分に合ったものが見つかるかもしれません。
また、業務でPythonを使えるようになるために勉強としてAtcoderを始めた、という方も勉強すべきかもしれません。なぜなら、Pythonを使うその業務、機械学習につながっているかもしれません。機械学習をするなら数学からはどうやっても逃げられません。いい機会だと思って一緒にがんばりましょう !
考察D
まず問題の雰囲気や制約から、探索的なアプローチをとるよりも数学的に解くのが良さそうだと感じます。
もっと詳細に言うと A や B を全探索した場合、各処理がO(1)であっても間に合わないところ、落下時間の関数が求められるところがそう感じる理由になります。
その落下時間の関数は 飛び降りるまでの時間を $t$ ($t$ は非負整数) とすると $f(t) = Bt + \frac{A}{√(t+1)}$ と表せます。
つまり、「$t$ が 0以上の任意の整数の範囲を動くときに $f(t)$ が最小となる $t$ の値はいくつか 」 問われています。
最小値を求めるためにもまず、この関数がどういった性質を持っているか調べます。どんな調査であっても「可視化」することはとても重要であるので、関数をグラフの形で調べてみることにします。また、簡単なグラフであれば、「増減」に注目すると大まかな形を把握することができます。
グラフの増減を調べる
増減を調べるために $f(t)$ を微分します。また、このとき $√$ の中を単純化する方が簡単なので、 $t' = t+1$ と置き換えることにします。
\\\\[25pt]
f(t')\ = \ B\ (t'- 1)\ +\ A\ (t')^{-\frac{1}{2}} \\
\begin{align}
\frac{df(t')}{dt'}\ &=\ B\ -\frac{1}{2}\ A\ (t')^{-\frac{3}{2}} \\
&=\frac{2B\ (t')^{\frac{3}{2}} -\ A}{2(t)'^{\frac{3}{2}}}\ \\
\end{align}
$t' > 0$ より 分母は必ず正の値を取るので、$f(t')$ の増減は 分子のみに依存します。
ここで、$g(t') = 2B(t')^{3/2}$ としてこれに注目すると、 $y= g(t')$のグラフは以下の通りです。
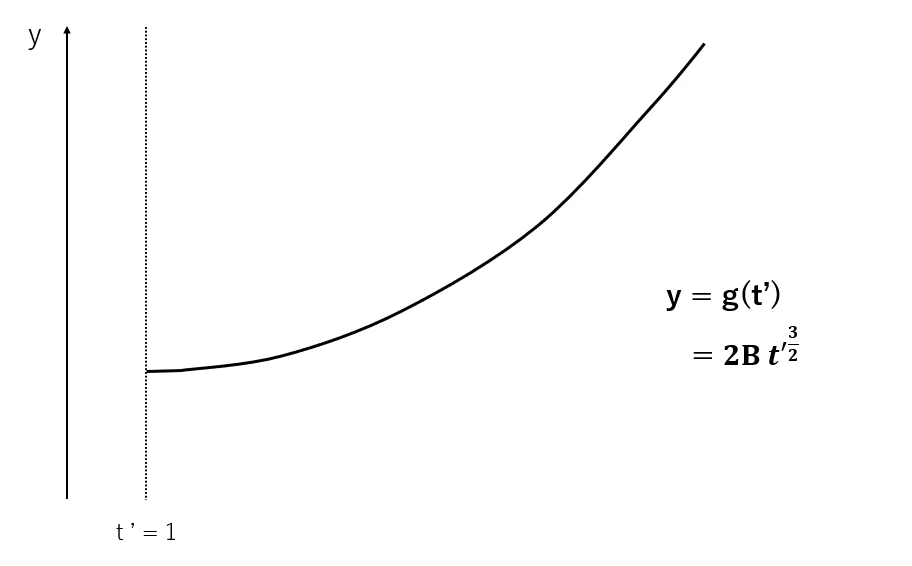
したがって、y = A のグラフの位置次第で $f(t')$ の増減は2通り考えられます。
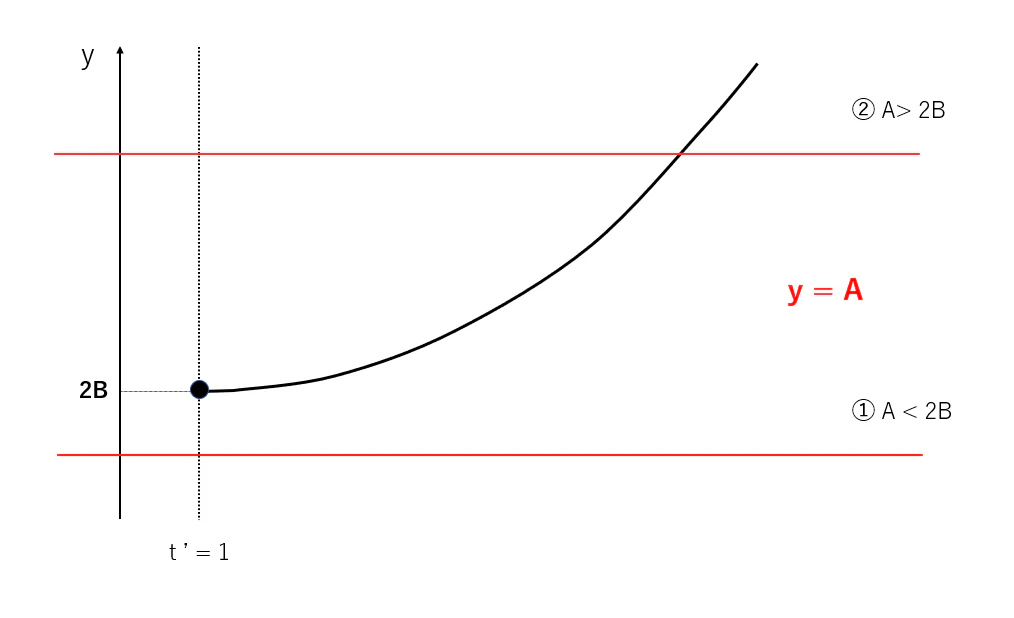
➀ $A < 2B$
このとき、常に $\frac{df(t')}{d(t')} > 0$ が成立します。したがって、$f(t')$ は単調に増加します。
つまり、$f(t')$ は $t'=1 $ で最小値をとることになります。
➁ $A > 2B $
$y= A$ , $y= 2B(t')^{3/2}$ のグラフの交点 $ t' = X $ を境界に $ f(t') $ の増減は負から正へ変化します。
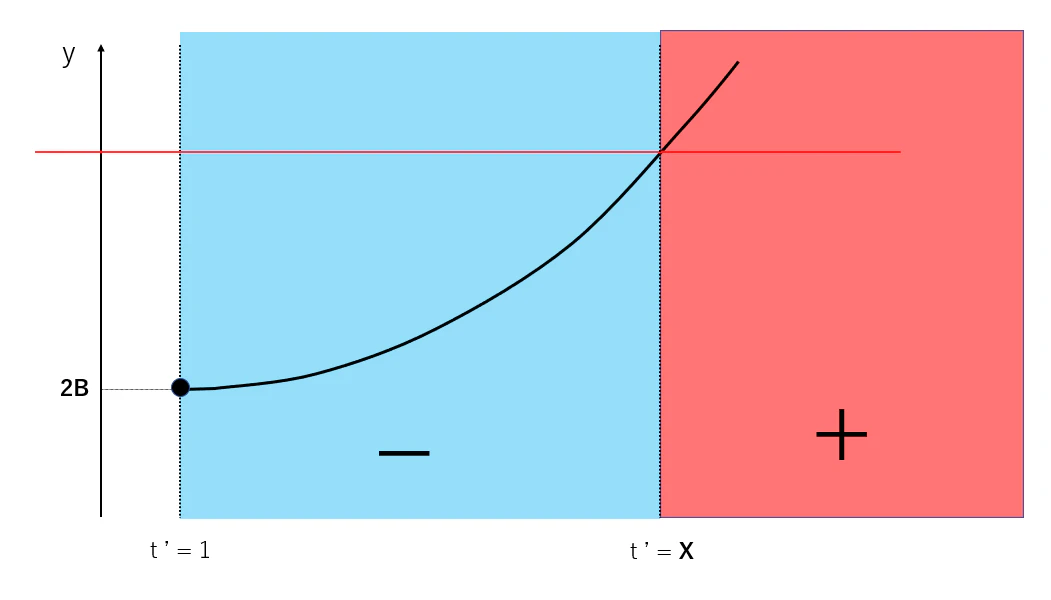
よって、$y=f(t')$ は以下のような形をしていることがわかりました。
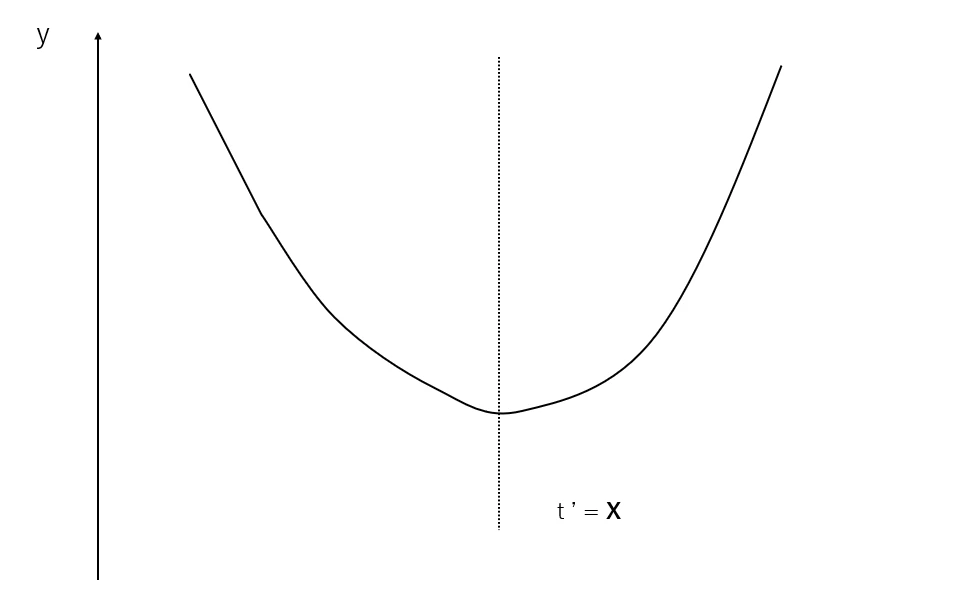
したがって $f(t')$ は $t'= X$ で最小値をとることになります。
ここまでわかったことをまとめると
$A < 2B $ の場合、$ t'=\ 1 $
$A > 2B $ の場合、$ t'=\ X $
したがって、あとはこの $X$ を求めることができればこの問題をとける ! ところまで来たように一見すると思えます。
しかし、この $X$ は $t'$ の条件である整数になるとは限りません。つまり、単純にグラフの最小値を求めるだけではいけないということです。$t'= 1,2,.....,n,n+1,.... $ ($n$ :正整数) の範囲において $f(t')$ が最小となる $t'$ を求めなければいけません。
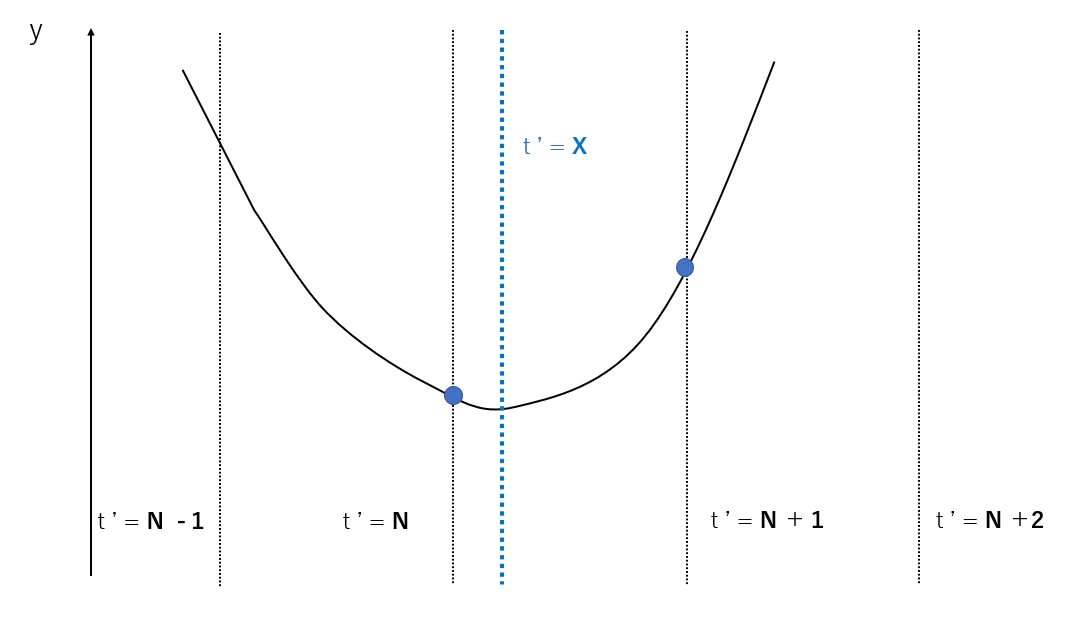
この $t'$ は、境界に最も近い2つの整数のどちらかであって、$f(t')$をより小さくするものです。
境界までの範囲における単調性を利用した二分探索
さて、この 2整数を求めるにはどうすればよいでしょうか。
最も簡単な方法は、整数を 1 から順に境界にたどり着くまで探索することだと思います。
では、どこまでの整数を調べれば必ず境界がみつかるでしょうか。グラフから、B が小さければ小さいほど、A が大きければ大きいほど、境界 $t' = X$ は右にずれていきます。今、$1 < A,B < 10^{18}$ なので、$A= 2B(t')^{3/2}$ を満たす $t'$ は $10^{12}$ 程度となる可能性があります。当然、この範囲を全探索することはできません。
そこで、境界が見つかるまでの関数の単調性に注目し 二分探索で境界を見つけることにします。計算量は O(logA) なので十分高速です。
二分探索が分からないという方はぜひこちらをご覧ください。とても勉強になります。
簡単に処理内容を説明すると、減少領域の端を $t'=1$ , 増加領域の端を $t'= 10^{15}$ に設定し、その中間の $t'=\frac{1+10^{12}}{2}$ はどちらの領域に含まれるのかを調べます。
例えば、もし減少領域に含まれているのであれば、$ 1<=\ t' <=\ \frac{1+10^{12}}{2}$ の範囲は全て減少領域に含まれることになります。なぜなら境界線をまたがない限り単調性が約束されているからです。
この次は 減少領域の端を $t'=\frac{1+10^{12}}{2}$ に変更して同じ処理を繰り返していきます。これによって、単純に全探索するよりもはるかに少ない回数で境界の位置を調べることができます。
誤差
他の多くの問題と異なり、相対誤差でも正誤判定が行われます。
コード
pypy3
A,B=[int(ab) for ab in input().split()]
# f(t')の増減が常に正である場合
if 2*B-A>=0:
ans=A
# 境界を二分探索で求める
else:
minus=1
# 大きめに範囲を取っておく
plus=10**15
while plus-minus!=1:
mid=(minus+plus)//2
if 2*B*mid**1.5-A<=0:
minus=mid
else:
plus=mid
# もっとも境界に近い2整数は minus,plusであるので両者を比較し、より小さい方を採用
# t'= t+1 であることに注意
ans=min(B*(minus-1)+A/(minus)**0.5,B*(plus-1)+A/(plus)**0.5)
print(ans)
補足
-
二分探索
二分探索アルゴリズムを一般化 〜 めぐる式二分探索法のススメ 〜:二分探索を勉強するのにとても参考になります (再掲載)
練習:アルゴ式に例題がいくつかあります -
三部探索
公式解説をみると三部探索というアルゴリズムでもこの問題をとけるそうです
終わり
1 時間 E問題を考え続けました。。。手も足も出ませんでした。。。