はじめに
前回まで、Natural Language Classifier(NLC)、Retrieve&Rank(RR)、DocumentConversion(DC)について解説してきた。APIは組み合わせてナンボ。これでようやく本題に入れるというわけである。
ここまでの記事を見逃している人はこちらからぜひチェックして欲しい。
質問応答システムとは?
ここで言う「質問応答システム」とは、ユーザーが質問を入力するとシステムが最適な答えを探して回答してくれるシステムのことである。IBM WatsonはJeopardy!でクイズ王に勝ったことで有名だが、あれも質問応答システムのひとつの形だと思う。あの技術から今のWatsonのコグニティブなAPIが作られている(らしい)。ということで、Watson APIを組み合わせて質問応答システムを作ってみようと思う。
ぼくのかんがえたさいきょうのしつもんおうとうしすてむ
ユーザーというのは気まぐれだ。何を話すかわからない。だからコンピューターは、ユーザーの話題がいったい何であるかを把握する必要がある。といっても、完全にフリーな会話だとキツいので、今回はスマホの話に絞らせてもらう。ユーザーはiPhoneかAndroidの質問をするというのが前提だ。
質問を受け付けたら、まずはNLCにかけてiPhoneの質問かAndroidの質問か分類する。その際に、**自信(Confidence、確信度)**が低い場合には、もう少し情報をもらうために「それはiPhoneの質問ですか?Androidの質問ですか?」とユーザーに追加質問し、自信を持って分類できるようにするとよさそうだ。(この記事執筆時は「わかりません」と返して終わりにしている)
分類されたら**そのクラスに該当するRRのランカーを使って質問に対する回答を探す。**回答が見つからなかった場合は、仕方ないので「回答がみつかりませんでした」と返すことにする。
これを図にしたのが以下である。
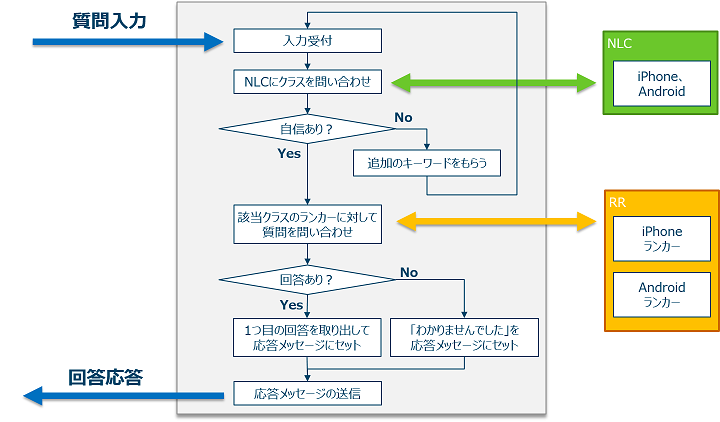
ここで必要なのは、iPhoneとAndroidを分類できるNLCと、iPhoneの質問に答えられるRR、Androidの質問に答えられるRRである。なお、RRはSolrクラスターは1つでコレクションおよびランカーを分離すればよい。
RRとNLCの構成
構成方法は以前の記事を見て欲しい。ポイントとなるのは質問と答えを集めるところになる。今回はソフトバンクのFAQをiPhone、Androidでそれぞれ検索し、出てきた結果からよさげなものをピックアップしてFAQ.csvを作成した。それをツールにかけて、iPhone-Doc.json、iPhone-GT.csv、iPhone-NLC.csv、Android-Doc.json、Android-GT.csv、Android-NLC.csvを生成した。さらに、iPhone-NLC.csvとAndroid-NLC.csvを1つにまとめて、Smartphone-NLC.csvとした。(作ったデータも紹介したいところだが、著作権とか微妙なので添付はしないでおく。)
データ生成のイメージは以下を見て欲しい。iPhoneとAndroidで似ているけど別々の質問をそれぞれのFAQとして用意する。もちろん別々の答えが定義されている。これをツールにかけると以下のようなイメージでNLC用のCSVファイル、RR用のjsonファイルとCSVファイルが生成される。

質問応答システム
このNLCとRRを使って質問に対して回答するサンプルアプリケーションengage.jsを作ってみた。前提として、RRのコレクション名は「iPhone-collection」「Android-collection」であるとする。また、NLCやRRの視覚情報、クラスターID、ランカーIDなどを美しくないがハードコーディングしている。本当はCloudantなどを使うときれいにできるのだろうが、とりあえず動くの優先ということで。
node.jsで書いているので、node engage <質問文>で実行できる。
// Watson Developer Cloud
var watson = require('watson-developer-cloud');
var rr = watson.retrieve_and_rank({
username: '<RRのユーザーID>',
password: '<RRのパスワード>',
version: 'v1'
});
var nlc = watson.natural_language_classifier({
username: '<NLCのユーザーID>',
password: '<NLCのパスワード>',
version: 'v1'
});
var init = function(){
// 引数チェック
if (process.argv.length != 3){
console.log("USAGE: node engage <question>");
return 1;
}
var que = process.argv[2];
classifier(que);
}
var classifier = function(que) {
// NLCによるクラス分け
nlc.classify(
{
text: que,
classifier_id: '3AE103x13-nlc-918'
},
function(err, response) {
if (err) {
console.log('error:', err);
return 1;
} else {
// Confidenceの評価
if (response.classes[0].confidence < 0.95) {
console.log("すみません、質問がよくわかりません。");
} else {
console.log(">>> 認識されたクラス = " + response.classes[0].class_name);
ranker(response.classes[0].class_name, que);
}
}
}
);
}
// RRによる応答
var ranker = function(cl, que){
cid = "<RRのクラスターID>";
colname = cl+"-collection";
// ランカーID
if (cl == "iPhone") {
rid = "<iPhoneのランカーID>";
} else {
rid = "<AndroidのランカーID>";
}
// 設定確認
// console.log(">>> クラスターID : " + cid);
// console.log(">>> コレクション名 : " + colname);
// console.log(">>> ランカーID : " + rid);
console.log(">>> 質問 : " + que);
// パラメーター設定
var params = {
cluster_id: cid,
collection_name: colname
};
// Use a querystring parser to encode output.
var qs = require('qs');
// Get a Solr client for indexing and searching documents.
// See https://github.com/watson-developer-cloud/nodejs-wrapper/tree/master/services/rr.
solrClient = rr.createSolrClient(params);
var ranker_id = rid;
var question = 'q=' + que;
var query = qs.stringify({q: question, ranker_id: ranker_id, fl: 'id,title,body'});
solrClient.get('fcselect', query, function(err, searchResponse) {
if(err) {
console.log('Error searching for documents: ' + err);
} else {
// 回答の有無を確認
if(searchResponse.response.numFound == 0) {
console.log("回答が見つかりませんでした");
return 1;
} else {
// 1つ目の回答を返す
console.log(">>> 回答 : " + searchResponse.response.docs[0].body);
}
}
});
}
// 実行
init();
これを実行したときの実行例はこちら。質問をするとNLCによってクラスが識別され、クラスごとに設定されているRR(のランカー)を使って回答を返しているのがわかる。
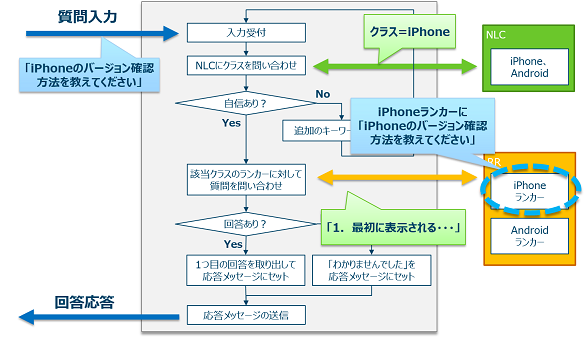
$ node engage "iPhoneのバージョンの確認方法を教えてください"
>>> 認識されたクラス = iPhone
>>> 質問 : iPhoneのバージョンの確認方法は?
>>> 回答 : 1.最初に表示されるホーム画面で「設定」を選択 2.「一般」を選択 3.「情報」を選択 4.「バージョン」項目の数字で現在のiOSバージョンを確認できます
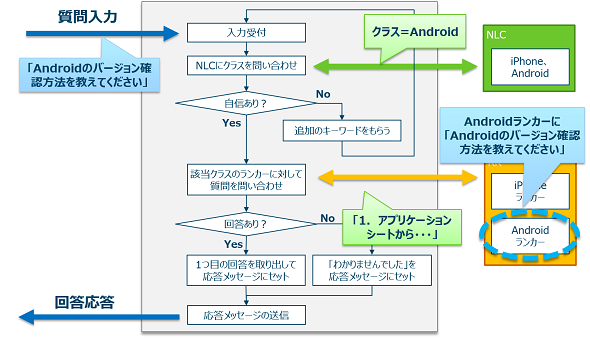
$ node engage "Androidのバージョンの確認方法を教えてください"
>>> 認識されたクラス = Android
>>> 質問 : Androidのバージョンの確認方法は?
>>> 回答 : 1.アプリケーションシートから設定を選択、2.「端末情報」を選択、3.「Androidバージョン」項目で確認できます
$ node engage "こんにちは"
すみません、質問がよくわかりません。
これの動きを図示するとこんな感じになる。NLCによって判別されたクラスに従ってRRのランカーを選択して使うところがポイントである。
iPhoneの場合
Androidの場合
おわりに
今回はNLC部分ではiPhoneかAndroidかしか分類していないが、ここはもっと改善していけるだろう。あいさつなどに対してどう対応するか、どのタイミングであいさつであることを判別するのか、どうやって応答を返すのか、など考え出すと止まらない。また、RRによって得られた回答の検証を行ってより精度を高めるというアプローチもあるだろう。
まだまだ色々できそうだけど、もう時間が無いので今日はここまで。