はじめに
こちらの記事は【ディープラーニング】初心者が競艇予想ツールを作成するために学んだディープラーニングについて_知識編の続編となります。
実装編ではKerasを用いて作成したニューラルネットワークについて説明します。
また、実装編は長くなりそうなので①前編と②後編の豪華?二本立てでお送りいたします!
--2019/9/9追記--
実装編の②も投稿いたしました!
・【ディープラーニング】初心者が競艇予想ツールを作成するために学んだディープラーニングについて_実装編②
アジェンダ
・作成するモデルについて
・ニューラルネットワークが抱える課題について
・単勝予想モデルの作成について
・まとめ
作成するモデルについて
今回作成するモデルは以下の2つです。
・競艇の単勝予想のモデル
・競艇の3連単予想のモデル
これらをKerasを使用して作成していきます。
モデルの作り方については「知識編」でざっくりと説明しましたが、
今回はそれに加えてニューラルネットワークが抱える課題についても
Kerasで対応いたしました。
①ではニューラルネットワークの課題と単勝予想のモデル作成について
ご説明いたします。
ニューラルネットワークが抱える課題について
ニューラルネットワークでは様々なデータを元に学習し、
未知のデータに対して予想を行うことを目的としています。
ですが、この学習を行うにあたり、様々な問題が発生します。
以下は代表的な問題です。
・局所最適解に陥りやすい
・勾配消失問題
・過学習
ここからは各代表的な問題の説明とKerasでの解決方法をご説明いたします。
・局所最適解に陥りやすい
「知識編」にて「ニューラルネットワークは出力値と正解との誤差を算出し、
それを出力層から入力層に逆伝播し、各ユニットの重み・バイアスを更新する」
と説明いたしました。
誤差を元に各ユニットの重み・バイアスの更新を行う際、その更新量は
勾配降下法で算出します。
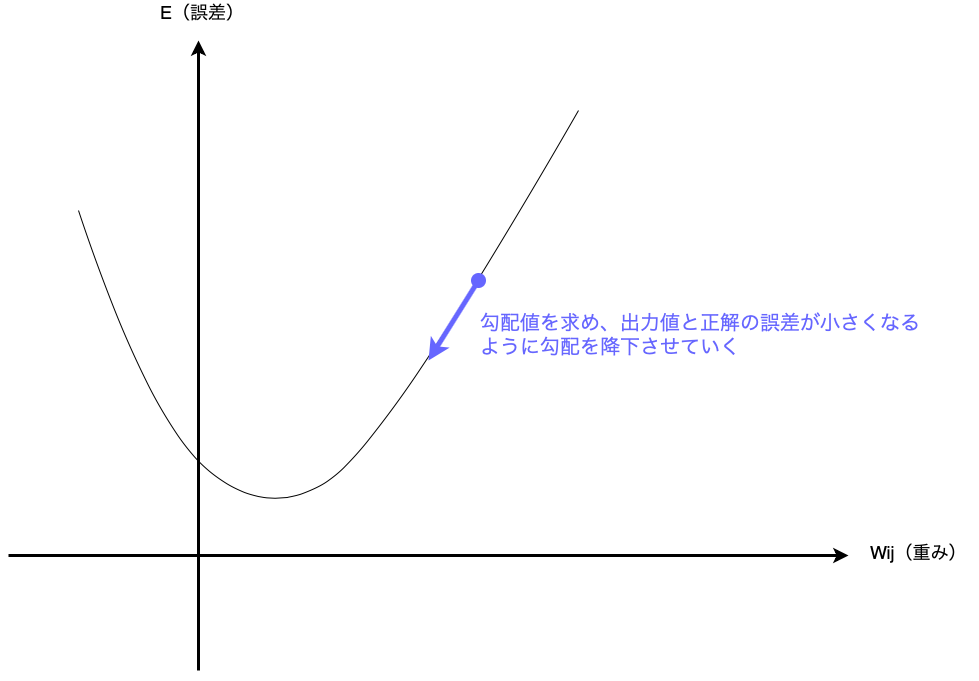
勾配とはあるパラメータXnの変化量に対する関数Yの変化量の割合です。
こちらは以下の式で求められます。
勾配=\frac{\delta Y}{\delta X_n}
勾配降下法は勾配を元にYの最小値に向かって降下するように
パラメータXnを変化させる手法です。
勾配降下法により重さWjkと誤差Eから重さの勾配を算出し、
誤差Eが最小値となるように重さWjkを更新できます!
【ユニットの重みと誤差による勾配降下のイメージ】
バイアスも同様に勾配降下法を使用して更新量を求めます!
しかし、勾配降下法を行う際は「重さ・バイアスによる誤差の変化」
つまりは上記のような曲線の形はわかりません。
ですので、例えば以下のような曲線の形をしている場合もあります。
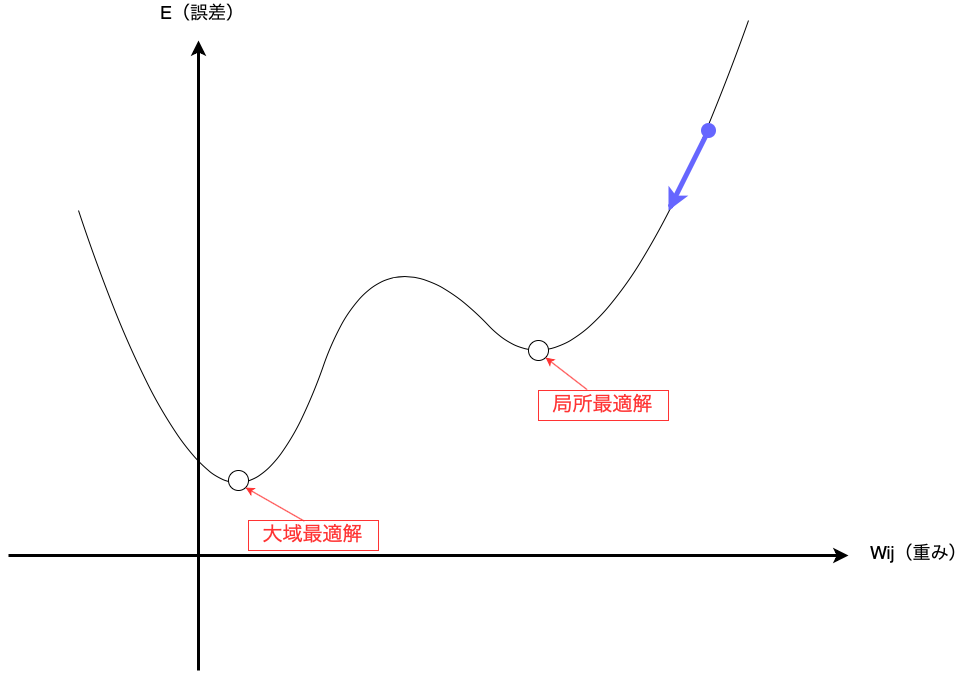
この場合は勾配を降下していくと局所的な最小の誤差Eにたどり着いてしまいます。
この値を局所最適解と言います。
また、真の最適解のことを大域最適解と言います。
局所最適解を避けて大域最適解にたどり着くためには
最適化アルゴリズムの選択が重要となります。
最適化アルゴリズムも複数種あります。
どれが最も効果があるかはニューラルネットワークごとに異なります。
以下は最適化アルゴリズムの簡単な説明とKerasでの実装方法をご紹介します。
なお、最適化アルゴリズムの設定はmodel.compileメソッドで行います。
・確立的勾配降下法(SGD)
確立的勾配降下法は学習時にパラメータを更新するたびに、訓練データを切り替えます。
こうすることで局所最適解に陥りにくくなります。
実装は以下の通りです。
# 確立的勾配降下法(SGD)のインポート
from keras.optimizers import SGD
# 最適化アルゴリズムとして確立的勾配降下法(SGD)を設定する
model.compile(optimizer=SGD)
・Adagrad
Adagradは各パラメータごとに学習率を変化させることで、より効率的に最適化を行います。
ただし、学習の初期に勾配が大きいとすぐに更新量が小さくなってしまい、
学習がストップしてしまうという欠点があります。
実装は以下の通りです。
# Adagradのインポート
from keras.optimizers import Adagrad
# 最適化アルゴリズムとしてAdagradを設定する
model.compile(optimizer=Adagrad)
・RMSprop
RMSpropはAdagradを改良したものです。
過去の更新量を一定の確率で忘却することにより、Adagradの
「すぐに更新量が小さくなってしまい、学習がストップしてしまう」
という欠点を克服しています。
実装は以下の通りです。
# RMSpropのインポート
from keras.optimizers import RMSprop
# 最適化アルゴリズムとしてRMSpropを設定する
model.compile(optimizer=RMSprop)
・Adam
Adamは2014年に提唱された比較的新しい最適化アルゴリズムです。
他の最適化アルゴリズムの良い点を併せ持っているため、
高い性能を発揮することが多いです。
実装は以下の通りです。
# Adamのインポート
from keras.optimizers import Adam
# 最適化アルゴリズムとしてAdamを設定する
model.compile(optimizer=Adam)
・勾配消失問題
勾配消失問題とは、出力層から入力層への逆伝播を行う中で、重さ・バイアスの更新量である
勾配が0となってしまうことで、学習が進まなくなってしまうという問題です。
こちらは活性化関数にシグモイド関数を指定した際に発生することが多いです。
対策としては活性化関数をシグモイド関数からReLUに変更することです。
・過学習
過学習とはモデルを学習する際に使用した訓練データに対してのみ最適化が進み、
実際に予測したい未知のデータに対して正しく推測できなくなってしまうことです。
通常、ニューラルネットワークのモデルを作成・学習する際は学習用の訓練データと
モデルの性能を測るためのテストデータを用意します。
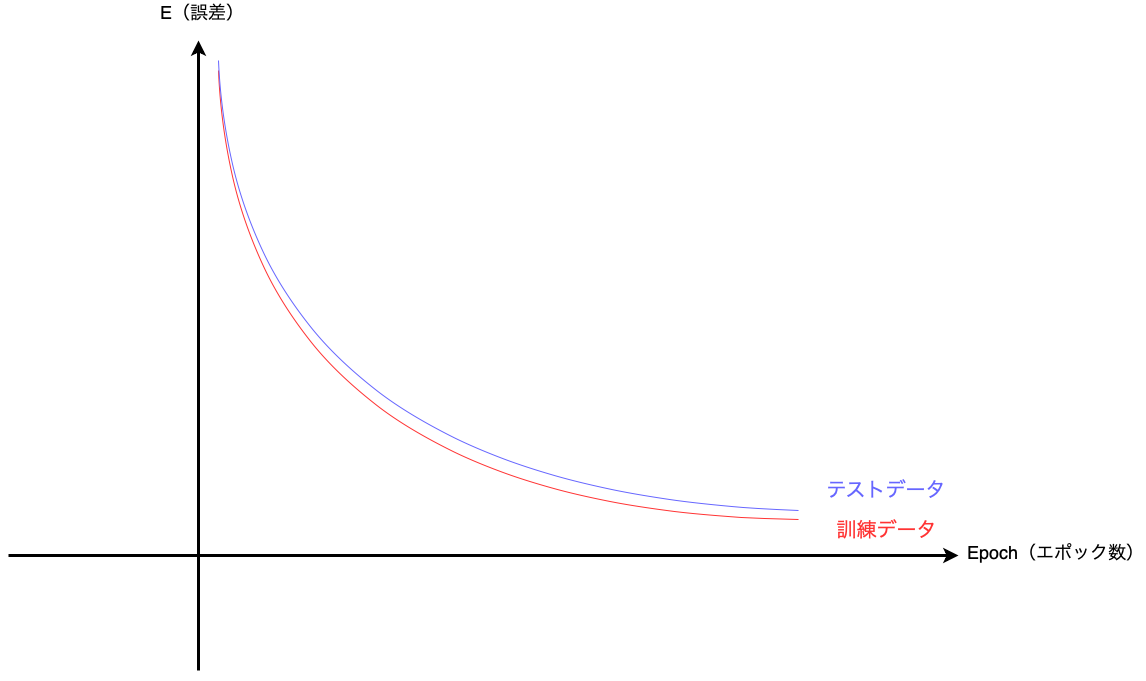
モデルの学習がうまくいき、過学習を起こしていない場合は
訓練データ・テストデータ共に予測の精度が同じように向上していきます。
【学習がうまくいった場合】
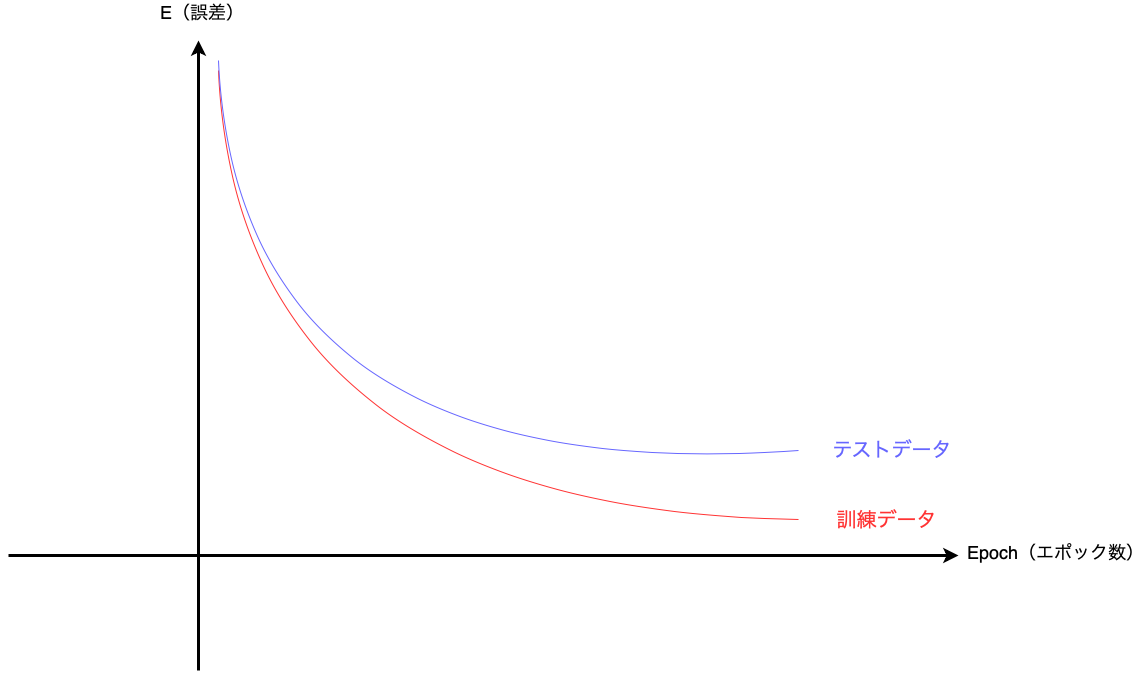
しかし、過学習が発生した場合は訓練データは順調に誤差が減少し、精度が上昇しますが
テストデータの誤差の減少・精度の上昇は途中で終了してしまいます。
【過学習が発生した場合】
過学習を防ぐ方法としては以下の手法などがあります。
・ドロップアウト層を追加する
・正則化を行う
・早期終了を行う
・ドロップアウト層を追加する
ドロップアウトは出力層以外のユニットをある一定の確率で消去する仕組みです。
ユニットを削除することで、ネットワークの規模を小さくすることができます。
こうすることで過学習を抑制できると考えられています。
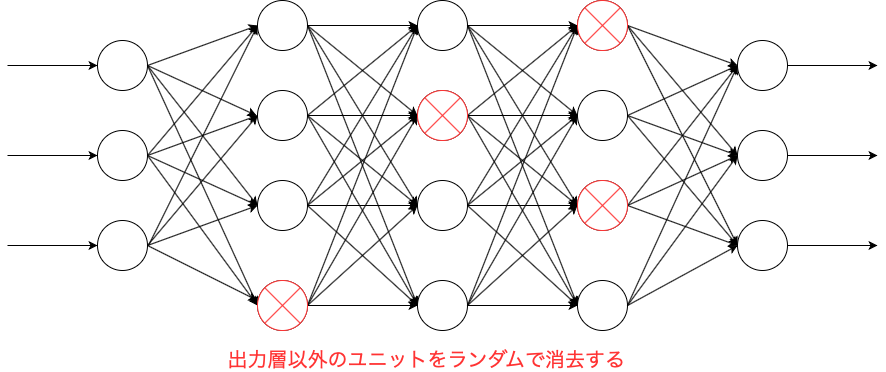
ドロップアウトはモデルにドロップアウト率を設定することで実現できます。
実装は以下の通りです。
# ドロップアウトのインポート
from keras.layers import Dropout
# ドロップアウト率を設定する
model.add(Dropout(0.36))
・正則化を行う。
正則化は重みに制限を加え、重みが極端な値を設定し局所最適解を導かないようにします。
Kerasでは以下の2種類の正則化が行えます。
・L1正則化:不要なパラメータを削除する際に使用
・L2正則化:過学習を抑えたい際に使用
実装は以下の通りです。
# 正則化クラスのインポート
from keras import regularizers
# Dense層を追加する際にL1正則化を設定する
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l1(0.01))
# Dense層を追加する際にL2正則化を設定する
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01))
・早期終了を行う。
早期終了とは学習を途中で打ち切ることです。
学習を進めていく中で誤差が減少しない・精度が上昇しないといった
傾向が見え始めた際に学習を終了することで、過学習を防止します。
実装は以下の通りです。
# コールバック関数として用意されている早期終了(EarlyStopping)のインポート
from tensorflow.keras.callbacks import EarlyStopping
# 早期終了の定義
early_stopping = EarlyStopping(patience=10, verbose=1)
# モデル学習時にコールバック関数として設定する
model.fit(x_train, y_train, batch_size=50, verbose=0,
epochs=100, validation_split=0.1,
callbacks=[early_stopping])
EarlyStoppingの引数は以下の通り
・patience:正答率がどれくらいのepoch数で改善が見られなかった際に
早期終了するべきかを定義する。
・verbose:早期終了したことをコンソール出力するべきかを定義する。
ここまでがニューラルネットワークが抱える課題とその解決方法についての
説明でした。
ニューラルネットワークの課題やKerasでの解決方法は
以下の書籍を参考にいたしました。
「知識編」でご紹介した本ですが、本当にオススメですので是非ご参照ください。
・はじめてのディープラーニング
・PythonとKerasによるディープラーニング
・モデルの作成について
それでは実際に競艇の予想モデルを作成していきます。
使用したデータは【機械学習】初心者が競艇予想ツール作成して金儲け大作戦と同じです。
ですのでまずはGoogle Drive に格納されているcsvの読み込みから行います。
・csv取得
# Google Driveのマウントを取る
from google.colab import drive
drive.mount('/content/drive')
# OAuth2.0認証を行うために必要なものをインポート
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Google Driveのcsvを使用するためにOAuth2.0認証を行う
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
これらを実行するとどちらも以下のような実行結果が出力されます。



これでGoogle Driveからcsvを取得する準備が整いました。
では取得しましょう。
# csv読み込み
import pandas as pd
downloaded1 = drive.CreateFile({"id":"xxxxxx"})
downloaded1.GetContentFile("race.csv")
なお、取得対象のcsvのIDは以下の手順で取得します。
①Google Driveに接続し、対象のファイルを選択し、右クリック→共有 と選択
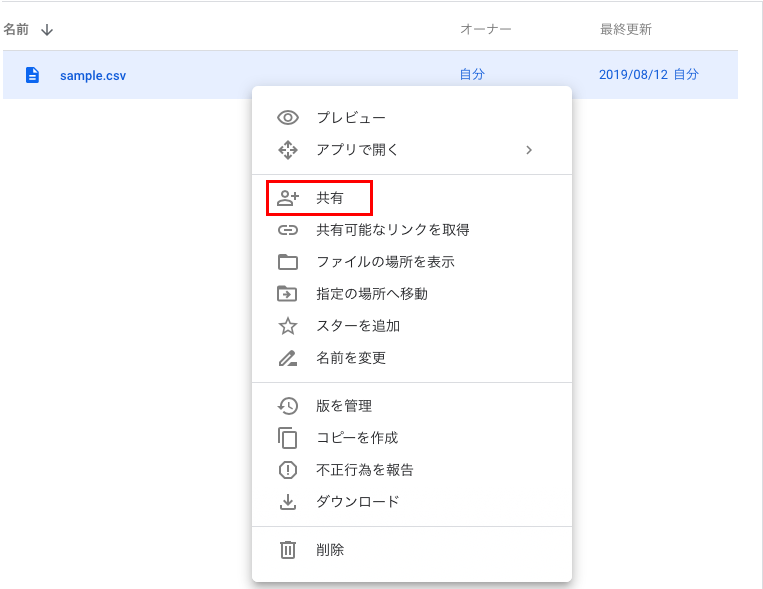
②画像の黒塗り部分がIDとなるため、コピーする
これでcsvの読み込みは完了しましたので、まずは単勝予想のモデルを作成していきます!
・単勝予想モデル作成
それでは必要なライブラリをインポートします。
# Keras、Pandas、Numpyなど必要なライブラリをインポート
from __future__ import print_function
from sklearn.preprocessing import StandardScaler
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
from sklearn.model_selection import train_test_split
import keras
from keras.datasets import fashion_mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
import warnings
warnings.filterwarnings('ignore')
from sklearn import svm
from sklearn.metrics import accuracy_score
import itertools
!pip install h5py
次に取得したcsvを使用して単勝予想用の訓練データとテストデータを作成します。
・訓練データとテストデータの作成
# one-hotエンコーディング関数
def one_hot_encode(y_data,y_label):
results = np.zeros((y_data.shape[0], len(y_label)))
for n in range(y_data.shape[0]):
result = y_data.iat[n,0].astype(str)
index = y_label.index(result)
results[n, index] = 1
return results
# 訓練データとテストデータを正規化する関数
def to_StandardScaler(x_train, x_test):
sc = StandardScaler()
sc.fit(x_train)
x_train_std = sc.transform(x_train)
x_test_std = sc.transform(x_test)
return x_train_std, x_test_std
# csv読み込み
race_data = pd.read_csv("race.csv")
# 訓練データ数
train_row = round(race_data.shape[0] * 0.8)
# 説明変数(単勝予想のために使用するデータ)を設定
x = DataFrame(race_data.drop(["1st-Rank","result2","result3"],axis=1))
# 目的変数(単勝結果)を設定
y = DataFrame(race_data["1st-Rank"])
# 目的変数のラベル作成
y_label = ["1", "2", "3", "4", "5", "6"]
# 学習データとテストデータに分ける
x_train = x[:train_row]
x_test = x[train_row:]
y_train = y[:train_row]
y_test = y[train_row:]
# 目的変数をone-hotエンコーディングする
y_train = one_hot_encode(y_train, y_label)
y_test = one_hot_encode(y_test, y_label)
# 標準化を行う
x_train_std, x_test_std = to_StandardScaler(x_train, x_test)
処理内容は以下の通りです。
①Google Driveより読み込んだcsvをPandasオブジェクトとして格納する。
②csvの全データから訓練データに使用するレコード数を計算する。
今回は全データの8割を訓練データ、2割をテストデータとする。
③csvのデータを説明変数と目的変数に仕分けする。
説明変数は予測に使用するデータのこと。
(毒キノコ予想を例とすると、説明変数は「キノコの色」や
「キノコのカサの大きさ」など)
目的変数は予測したいデータのこと。
(毒キノコ予想を例とすると、目的変数は「毒の有無」)
④説明変数と目的変数をそれぞれ訓練データ(x_train,y_train)と
テストデータ(x_test,y_test)に仕分けする。
⑤目的変数をone-hot表現に変換する。
one-hot表現とは「目的変数のパターン数」の長さを持ち、
該当するもののみ1が設定され、それ以外の値は0となるベクトルに変換すること。
例えば 毒キノコの判別の場合
・キノコAは有毒
・キノコBは無毒
・キノコCは有毒
とする。
毒キノコの判別では目的変数は「毒の有無」となるため、
以下のようにベクトルで定義することができる。
・有毒=[1,0]
・無毒=[0,1]
この場合、キノコA/B/Cは以下のようにone-hot表現ができる
・キノコAは有毒なので[1,0]
・キノコBは無毒なので[0,1]
・キノコCは有毒なので[1,0]
one-hot表現にすると、出力層のユニット数を「目的変数のパターン数」で設定し、
予測した分類に該当するユニットのみ1を出力し、
それ以外のユニットは0を出力することができる。
⑥説明変数を標準化する。
標準化とはデータの平均を0、標準偏差を1に変換することです。
標準化により説明変数ごとの値の桁のばらつきを統一化できます。
(人間でいうと「身長」と「視力」では値の桁が違うため、
このまま使用すると「身長」の値が大きく影響する可能性がある)
標準化はsklearn.preprocessingのStandardScalerクラスを使用しています。
ここまでやれば訓練データとテストデータが作れていますので、
次からは単勝モデルを作成します。
・単勝予想モデルの作成・学習・保存
# モデル作成
model = Sequential()
model.add(Dense(132, input_shape=(x_train_std.shape[1],), activation='relu'))
model.add(Dropout(0.36))
model.add(Dense(200, activation='relu'))
model.add(Dropout(0.49))
model.add(Dense(200, activation='relu'))
model.add(Dropout(0.49))
model.add(Dense(y_train.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# モデル学習
early_stopping = EarlyStopping(patience=10, verbose=1)
model.fit(x_train_std, y_train, batch_size=50, verbose=0, epochs=100, validation_split=0.1, callbacks=[early_stopping])
# モデルの保存
model_json = model.to_json()
with open('/content/drive/My Drive/model_winner.json', 'w') as f_model:
f_model.write(model_json)
best_model.save_weights('/content/drive/My Drive/model_winner.h5')
これでモデルが作成できました!!
各層のユニット数や活性化関数・最適化アルゴリズムについてはとりあえず
お試しで設定しています。
最後に作ったモデルの正答率なども確認してみましょう!
# モデル評価
score = model.evaluate(x_test_std, y_test, verbose=1)
print("\n")
print("Test loss:",score[0])
print("Test accuracy:",score[1])
出力結果は以下の通りです。
Test loss: 1.0314583373094781
Test accuracy: 0.6951731377108274
単勝の正答率は約7割でした。
私の友人曰く「競艇の単勝予想の正答率7割は普通」とのことでしたので、
まだこのニューラルネットワークは人並みのようです。
今回はユニット数などは調整していないので、これらのハイパーパラメータをチューニング
すれば伸びるかもしれません。
まとめ
今回はニューラルネットワークが抱える課題と競艇の単勝予想モデルの作成について
説明いたしました。
②では3連単予想モデルの作成とハイパーパラメータのチューニングについて説明する予定です。