はじめに
こちらの記事は【ディープラーニング】初心者が競艇予想ツールを作成するために学んだディープラーニングについて_実装編①の続きでございます。
前回の予告通り、この記事では競艇の3連単予想とハイパーパラメータのチューニングについて説明いたします。
2019/09/13追記
前回の予告では3連単予想とハイパーパラメータのチューニングについて
説明すると記載いたしましたが、記事が長くなりますので
記事を分割し、今回はハイパーパラメータのチューニングについて触れていきます。
3連単予想についてはまた別記事を投稿する予定です。
前回の記事では単勝予想の的中率(accuracy)が約7割であると説明いたしました。
では3連単予想の的中率はどれくらいになるでしょうか?
その答えは以下の通りです。
Test loss: 3.852140003836793
Test accuracy: 0.10230849948315905
まぁ〜低いですねww
頑張ってモデル作成したので、もう少しでも良いので伸びて欲しいですね..
ということで、的中率を改善するためにハイパーパラメータのチューニングを
実施してみました。
アジェンダ
・ハイパーパラメータについて
・Hyperasについて
・まとめ
・ハイパーパラメータについて
ニューラルネットワークにはユニット数や層(レイヤー)数、ドロップアウト率などの
ハイパーパラメータがあります。
これらの値はモデルを定義する際に設定します。
また、ハイパーパラメータではありませんが
活性化関数や最適化アルゴリズムもモデル作成時に設定します。
ハイパーパラメータはモデルの性能に影響するため、
モデルの正解率を向上させるためにはハイパーパラメータの最適化も重要となります。
しかし、ハイパーパラメータの最適化には以下のような難点があります。
・ハイパーパラメータは作成するモデルごとに最適な値は異なる。
・ユニット数やモデル数のロールモデルは存在しない。
ですので、最適化を実現するためには
これらのハイパーパラメータのチューニング作業が必要となります。
しかし、このハイパーパラメータのチューニング作業はとても時間がかかる&しんどい作業です...
(例えるなら某少年漫画のように大海原で秘宝を探すようなものです。)
できることなら自動でハイパーパラメータの最適化を行ってくれる仕組みがあれば楽なんですが...
・Hyperasについて
「自動でハイパーパラメータの最適化を行ってくれる仕組みがあればな~」
と言いましたが、Hyperesが全て解決してくれました!!
Hyperasについては以下のサイトで詳細に説明されております
・Kerasだってハイパーパラメータチューニングできるもん。【hyperas】
・Kerasでハイパーパラメータを自動調整したいならHyperas
・Keras Hyperparameter Tuning in Google Colab using Hyperas
こちらを使用すれば、最もモデルの性能が良くなるハイパーパラメータの組み合わせを自動で探索し、最適化された
モデルを自動で保存することができます!!
実際に私が作成した3連単予想モデルのハイパーパラメータチューニングを
Hyperasでやってみます。
また、Google ColaboratoryでHyperasを使用する場合はGPUを使用することをお勧めします。
GPUの使用方法は簡単です。
以下の通りに実行すればOKです。
・ノードブックを開き、「ランタイム」タブの「ランタイムのタイプを変更」をクリック
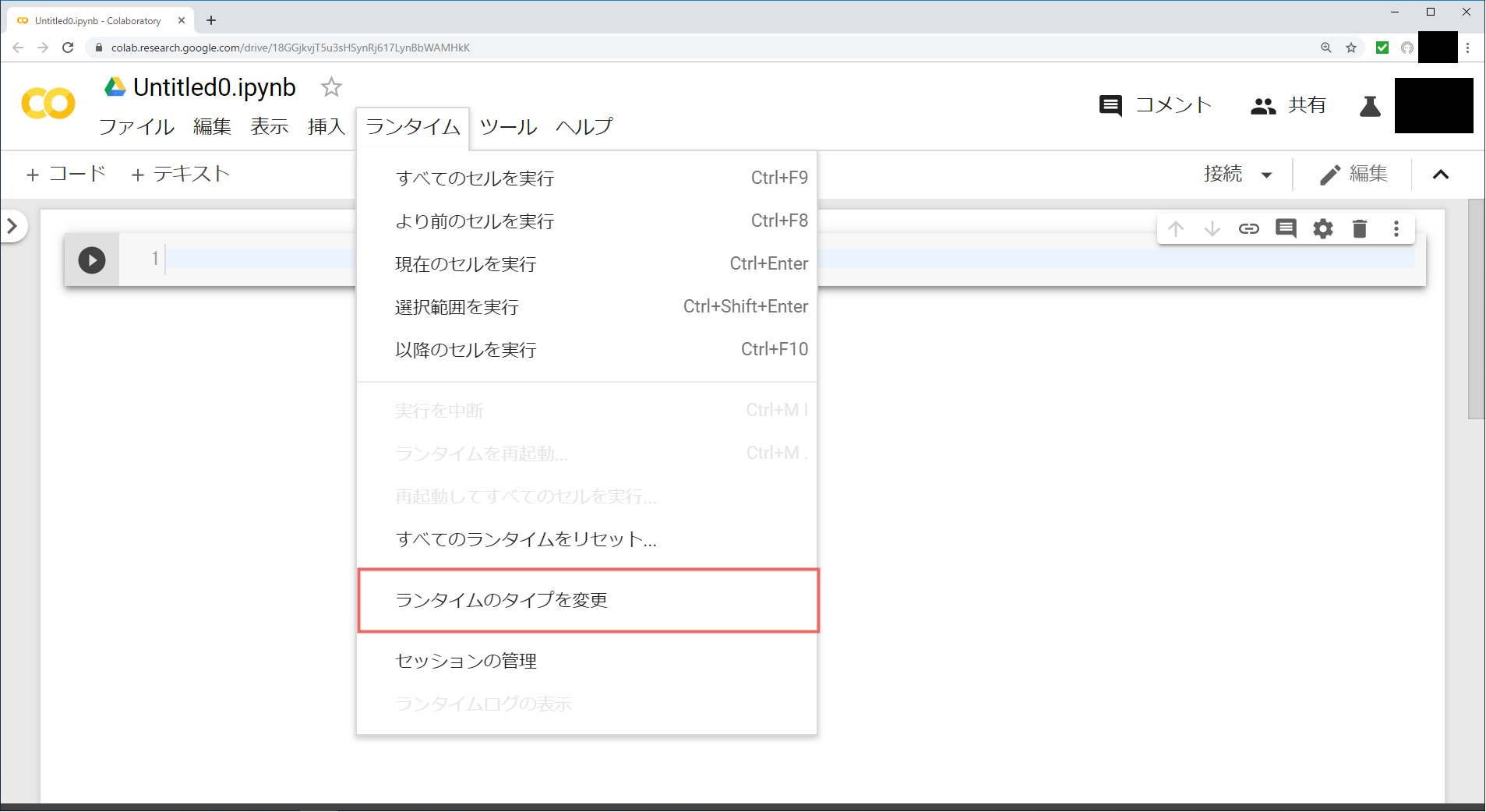
・「ハードウェア アクセラレータ」のプルダウンから「GPU」を選択し、保存する
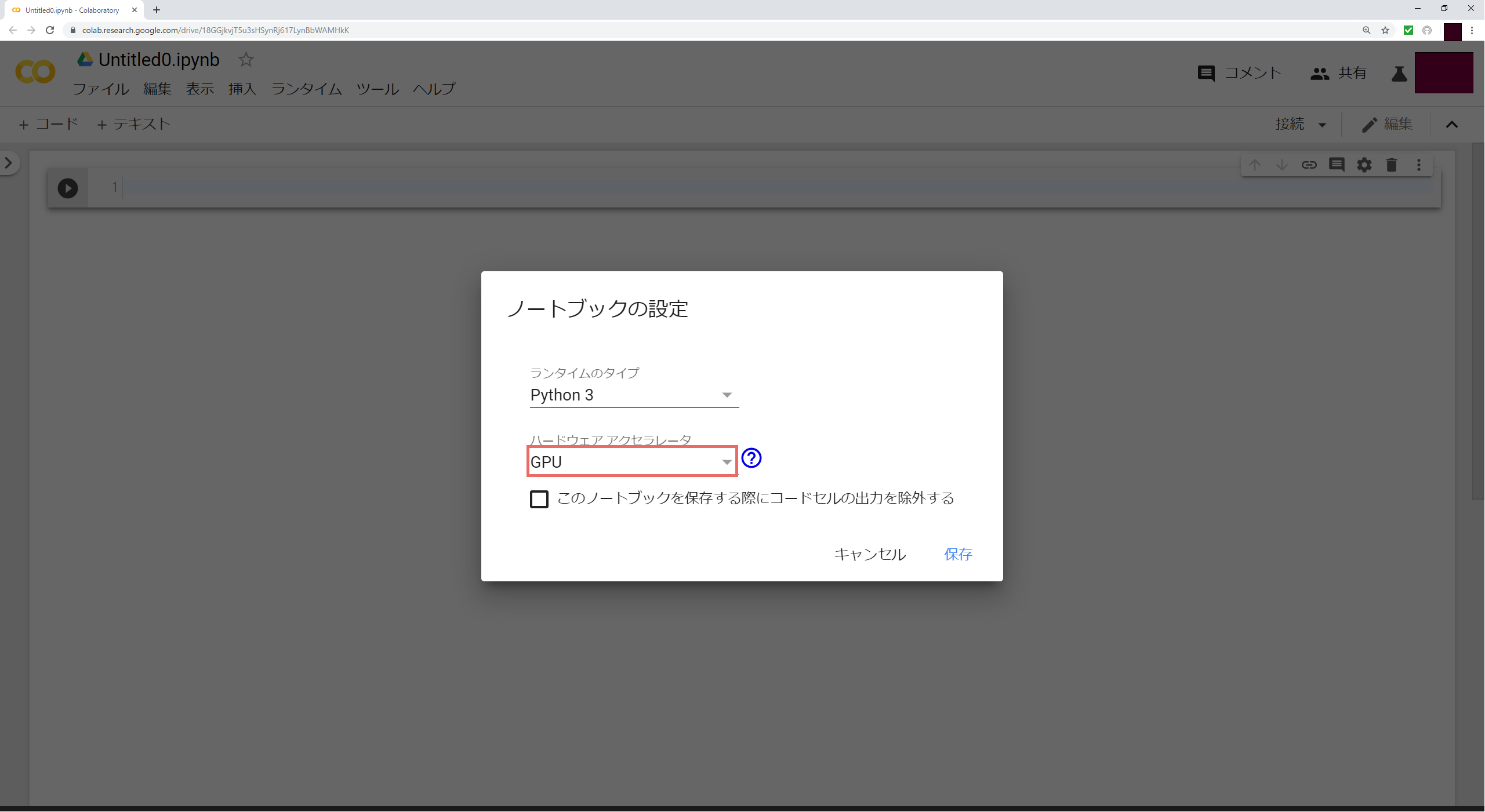
これでGPUが使用できるようになりました!
Google Colaboratoryで使用できるGPUについては以下の記事をご参考にしてください。
・【秒速で無料GPUを使う】TensorFow(Keras)/PyTorch/Chainer環境構築 on Colaboratory
それではHyperasの実装を行っていきましょう!
# Hyperasやその他諸々の必要なライブラリをインポート
!pip install hyperas
!pip install hyperopt
!pip install h5py
from __future__ import print_function
from hyperopt import Trials, STATUS_OK, tpe
from hyperas import optim
from hyperas.distributions import choice, uniform
import keras
from keras.models import Sequential
from keras.models import model_from_json
from keras.preprocessing.image import load_img, img_to_array
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utils
from keras import optimizers
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.preprocessing import StandardScaler
import itertools
# Google Driveをマウント
from google.colab import drive
drive.mount('/content/drive')
# PyDriveなどをインストール
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
# hyperasを使用するノートブック名(つまりは今実装しているノートブック名)を設定
# これがないとhyperasをどこで使用するのかわからず、エラーが発生するらしい
fid = drive.ListFile({'q':"title='CreateResult3Model_1.ipynb'"}).GetList()[0]['id']
f = drive.CreateFile({'id': fid})
f.GetContentFile('CreateResult3Model_1.ipynb')
# 競艇データのCSVファイルの読み込み
downloaded1 = drive.CreateFile({"id":"xxx"})
downloaded1.GetContentFile("race.csv")
これでライブラリなどのインストールが完了しました。
次のセルからはHyperasの実装となります。
実装の流れは以下の通りです。
① 訓練データ・テストデータを作成するdata()を定義する。
② モデルを作成し、最適なハイパーパラメータを探索するためのcreate_model()を定義する。
③ optim.minimize()を実行し、最適なモデル作成を行う。
① 訓練データ・テストデータを作成するdata()を定義する。
data()では、モデル作成に使用する訓練データ・テストデータを作成します。
こちらでは今までと同様の手順で訓練データ・テストデータを作成していきますので、
特に変わったことはしておりません。
def data():
result3_label = []
winner_predict1_list = []
# 目的変数のラベル(単勝予想)
winner_label = ["1", "2", "3", "4", "5", "6"]
# 目的変数のラベル(3連単予想)を作成する
for v in itertools.permutations(winner_label, 3):
result3 = "".join(v)
result3_label.append(result3)
# JSONファイルからモデルのアーキテクチャを得る
model_arc_str = open("/content/drive/My Drive/model_winner.json").read()
model = model_from_json(model_arc_str)
# モデルの重みを得る
model.load_weights("/content/drive/My Drive/model_winner.h5")
# csv読み込み
race_data = pd.read_csv("race.csv")
# 訓練データ数
train_row = round(race_data.shape[0] * 0.8)
# 単勝予想データの作成・標準化
predict_winner_data = DataFrame(race_data
.drop(["1st-Rank","result2","result3"],axis=1))
sc = StandardScaler()
sc.fit(predict_winner_data)
predict_winner_data = sc.transform(predict_winner_data)
# 単勝の1位予想を実施し、確率が最も高いコースを取得する
for n in range(race_data.shape[0]):
data = predict_winner_data[n].reshape(1,-1)
result_winner = model.predict(data, batch_size=50,verbose=0)
winner_predict1 = winner_label[np.argmax(result_winner)]
winner_predict1_list += winner_predict1
winner_predict1_list = [int(s) for s in winner_predict1_list]
# 3連単予想データを作成
race_data = race_data.assign(winner_predict1 = winner_predict1_list)
# 説明変数(順位、クラスなど除く)
x = DataFrame(race_data.drop(["1st-Rank","result2","result3"],axis=1))
# 目的変数(3連単を予想する)
y = DataFrame(race_data["result3"])
# 学習データとテストデータに分ける
x_train = x[:train_row]
x_test = x[train_row:]
y_train = y[:train_row]
y_test = y[train_row:]
# 目的変数をone-hotエンコーディングする
y_train = np.zeros((y_train.shape[0], len(result3_label)))
for n in range(y_train.shape[0]):
result = y_train.iat[n,0].astype(str)
index = result3_label.index(result)
y_train[n, index] = 1
y_test = np.zeros((y_test.shape[0], len(result3_label)))
for n in range(y_test.shape[0]):
result = y_test.iat[n,0].astype(str)
index = result3_label.index(result)
y_test[n, index] = 1
# 3連単予想データの標準化
sc = StandardScaler()
sc.fit(x_train)
x_train = sc.transform(x_train)
x_test = sc.transform(x_test)
return x_train, y_train, x_test, y_test
② モデルを作成し、最適なハイパーパラメータを探索するためのcreate_model()を定義する。
def create_model(x_train, y_train, x_test, y_test):
model = Sequential()
# 層を追加する際にユニット数、初期化方法、ドロップアウト率を選択させる
model.add(Dense({{choice([90, 100, 110, 120, 130, 140, 150, 160])}},
input_shape=(x_train.shape[1],), activation='relu',
kernel_initializer={{choice(['he_normal', 'he_uniform'])}}))
model.add(Dropout({{uniform(0, 1)}}))
model.add(Dense({{choice([120, 150, 200, 250, 300])}},
activation='relu',
kernel_initializer={{choice(['he_normal', 'he_uniform'])}}))
model.add(Dropout({{uniform(0, 1)}}))
# 層(レイヤー)数を選択させる
if {{choice(['three', 'four', 'five'])}} == 'three':
pass
elif {{choice(['three', 'four', 'five'])}} == 'four':
model.add(Dense({{choice([120, 150, 200, 250, 300])}},
activation='relu',
kernel_initializer={{choice(['he_normal', 'he_uniform'])}}))
model.add(Dropout({{uniform(0, 1)}}))
elif {{choice(['three', 'four', 'five'])}} == 'five':
model.add(Dense({{choice([120, 150, 200, 250, 300])}},
activation='relu',
kernel_initializer={{choice(['he_normal', 'he_uniform'])}}))
model.add(Dropout({{uniform(0, 1)}}))
model.add(Dense({{choice([120, 150, 200, 250, 300])}},
activation='relu',
kernel_initializer={{choice(['he_normal', 'he_uniform'])}}))
model.add(Dropout({{uniform(0, 1)}}))
model.add(Dense(120))
model.add(Activation('softmax'))
# 最適化アルゴリズムを選択させる
model.compile(optimizer={{choice(['rmsprop', 'adam', 'sgd'])}},
loss='categorical_crossentropy',
metrics=['accuracy'])
callbacks = [
EarlyStopping(patience=10)
]
model.fit(x_train, y_train, batch_size=50, verbose=0, epochs=100,
validation_split=0.1, callbacks=callbacks)
val_loss, val_acc = model.evaluate(x_test, y_test, verbose=0)
return {'loss': -val_acc, 'status': STATUS_OK, 'model': model}
create_model()ではモデルを定義しますが、その方法は今までとほとんど同じです。
つまりは以下の通りに実装しています。
① Sequentialインスタンス(以下model1)を生成する
② modelに層(レイヤー)を追加する
③ modelをcompileして定義する
④ modelをfitで学習させる
今までと異なる点は②、③で使用しているchoiceとuniformです。
choiceはListで設定したパラメータからいづれかを選択し、設定します。
以下の例ではユニット数を100,200,300のいづれかを選択し、設定します。
model.add(Dense({{choice([100, 200, 300])}}, activation='relu'))
Hyperasではchoiceでいづれかの値を選択し、モデルを作成することを
繰り返すことで、最適なパラメータの設定値を探索します。
また、ifとchoiceを組み合わせることで、層(レイヤー)数の最適な値も探索可能です。
以下の例では層(レイヤー)数を3〜5の中で最も良いものを探索させます。
if {{choice(['three', 'four', 'five'])}} == 'three':
pass
elif {{choice(['three', 'four', 'five'])}} == 'four':
model.add(Dense({{choice([120, 150, 200, 250, 300])}},
activation='relu',
kernel_initializer={{choice(['he_normal', 'he_uniform'])}}))
model.add(Dropout({{uniform(0, 1)}}))
elif {{choice(['three', 'four', 'five'])}} == 'five':
model.add(Dense({{choice([120, 150, 200, 250, 300])}},
activation='relu',
kernel_initializer={{choice(['he_normal', 'he_uniform'])}}))
model.add(Dropout({{uniform(0, 1)}}))
model.add(Dense({{choice([120, 150, 200, 250, 300])}},
activation='relu',
kernel_initializer={{choice(['he_normal', 'he_uniform'])}}))
model.add(Dropout({{uniform(0, 1)}}))
uniformは指定された数値間で最適な値を探索します。
以下の例では最適なドロップアウト率を探索します。
model.add(Dropout({{uniform(0, 1)}}))
ですので、Hyperasでは最適なパラメータを探索させる場合は
choiceとuniformを使用します。
ここまで来れば、9割は実装が完了しました。
あとは探索方法を定義し、自動でパラメータ調整を行うだけです!!
③ optim.minimize()を実行し、最適なモデル作成を行う。
# 最適なモデル作成を行う
best_run, best_model = optim.minimize(
model=create_model,
data=data,
algo=tpe.suggest,
max_evals=200,
notebook_name='CreateResult3Model_1',
trials=Trials())
# 学習モデルの保存
model_json = best_model.to_json()
with open('/content/drive/My Drive/model_result3_1.json', 'w') as f_model:
f_model.write(model_json)
best_model.save_weights('/content/drive/My Drive/model_result3_1.h5')
# 作成した最適なモデルによるテスト結果を表示
_, _, x_test, y_test = data()
val_loss, val_acc = best_model.evaluate(x_test, y_test)
print("val_loss: ", val_loss)
print("val_acc: ", val_acc)
最後に最適なモデルを作成するためのoptim.minimize()を実装します。
基本的に引数はデフォルトで使用しています。
変更しているのは以下のものです。
・max_evals:choiceやuniformで選択したパラメータの組み合わせを何通り検証するか
・notebook_name:Hyperasを実行するノートブック名(拡張子不要)
これでHyperasによる最適なモデル作成は以上となります。
Hyperasでチューニングした結果ですが的中率は**約12%**まで改善しました!!
そんなに大きくは改善されませんでしたが、効果はありました。
・まとめ
今回はハイパーパラメータのチューニングについて説明いたしました。
最初は手動でパラメータを変更し、何度もモデルを作成していましたが、
1時間経過しても改善されないことがザラにありました。
ご紹介したHyperasを使用すれば、そんな苦労を大幅に軽減できます!
次は今回作成したモデルを使用し、回収率100%を超えるのかを検証し、
ディープラーニングでお金儲けができるのかを追求する予定です!