Introduction 🚀
One challenge with large language models (LLMs) today is that fine-tuning often feels wasteful.
Teams run dozens of experiments, but only one or two models ever make it to production.
The rest consume compute, time, and energy — then end up forgotten.
Model merging is an emerging technique that flips this problem into an opportunity.
Instead of discarding fine-tuned models, we can combine their weights into a single model —
a process that is:
- 🧩 Modular → mix-and-match capabilities from different models,
- ⚡ Efficient → no extra GPU training required,
- 📈 Effective → surprisingly competitive, powering many state-of-the-art models on the Open LLM Leaderboard.

In 2025, with the release of GPT-OSS and other open-weight LLMs, experimentation has exploded.
Rather than training one model to rule them all, merging lets us blend domain-specialized models—
e.g., summarization + reasoning → a “smart explainer assistant”.
Revisiting Model Customization 🛠️
To understand merging, let’s revisit how fine-tuning works:
- LLMs store knowledge in weight matrices.
- Fine-tuning updates specific regions depending on the task.
- Imagine two fine-tunes as regions on a sports field—one updates the 10–30 yard lines (summarization), another the 70–80 yard lines (math).
When these task regions don’t overlap, we can merge both specializations into one model seamlessly.
Why Model Merging Works
Model merging doesn’t just save resources—it often improves performance.
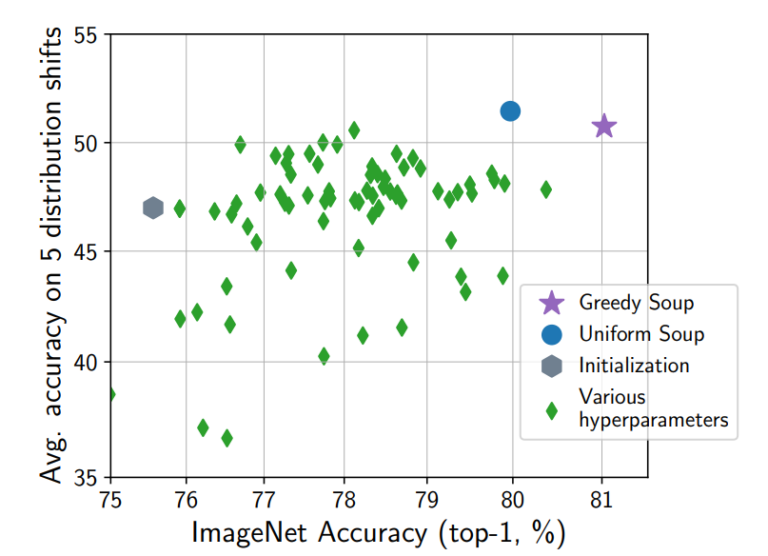
Take a look at this chart from NVIDIA’s technical blog: merged models often outperform their individual parents, especially when using methods like Model Soup.
What’s Next
Now that we’ve laid the foundation—explained why merges matter, what they are, and how powerful they can be—let’s move to the technical side.
In the next section, we'll dive into four popular merging algorithms: Model Soup, SLERP, TIES, and DARE.
Merge Algorithms 🧩
Model merging isn’t a single recipe — it’s a whole toolbox of techniques.
Some are simple averages, others smooth weight transitions, and some attempt to resolve conflicts between specialized models.
In practice, the community has found a few methods especially effective, so we’ll start with those.
Afterwards, I’ll list out all other methods available in mergekit.
Model Soup (Linear Merge)
Concept:
Model Soup is the simplest form of merging — you take the weights of multiple fine-tuned models and average them.
It was first tested in computer vision (ResNet soups), but it works surprisingly well for LLMs too.
Why it matters:
- Lets you recycle “failed” fine-tunes instead of throwing them away.
- Useful for multiple checkpoints from the same training run.
- Very low compute cost (just arithmetic averaging).
Variants:
- Naive Soup → merge all models sequentially, regardless of result.
- Greedy Soup → merge models only if accuracy improves on eval set.
Community Example:
NVIDIA showed soups improving generalization across distribution shifts (ImageNet → ImageNet-V2, etc.), and LLM merges have shown similar boosts.
🔗 NVIDIA Blog – An Introduction to Model Merging for LLMs
SLERP (Spherical Linear Interpolation)
Concept:
Instead of averaging on a flat line (linear merge), SLERP interpolates weights along a curve on a hypersphere.
This preserves the magnitude (norm) of weights and creates smoother transitions.
Why it matters:
- Prevents performance degradation common in linear averaging.
- Produces “intermediate” models between two endpoints.
- Hugely popular in community merges.
Limitations:
- Works only with 2 models at a time.
- Can be chained hierarchically for >2 models.
Community Example:
- Marcoro14-7B-slerp became the best-performing 7B model on the Open LLM Leaderboard in 2024.
- Still one of the go-to methods for 2025 merges.
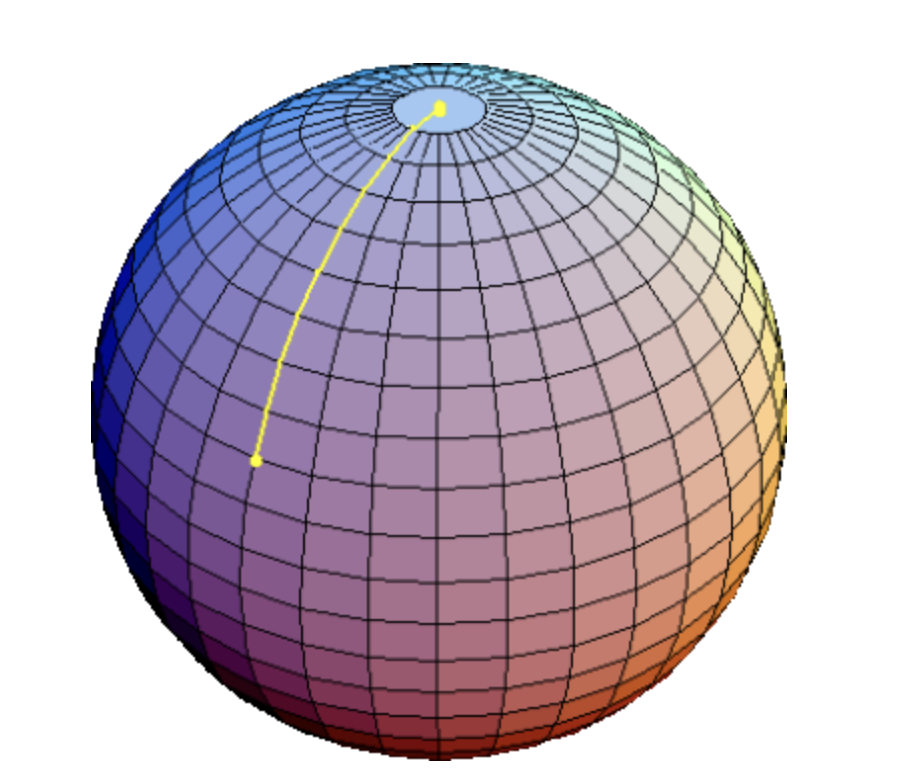
📊 Visual: Depicts how the SLERP model gives the shortest trajectory on the sphere between two points. Source: Statistical Analysis of Orientation Trajectories via Quaternions with Applications to Human Motion
🔗 Wikipedia: SLERP
TIES-Merging
Concept:
TIES stands for Trim → Elect Sign → Merge.
It builds on Task Arithmetic (merging deltas from fine-tunes) but adds rules to resolve conflicting updates.
How it works:
- Trim: Keep only the most important parameter updates (sparsify).
- Elect Sign: Resolve conflicts by choosing the most “dominant” direction of change.
- Merge: Average only the aligned updates.
Why it matters:
- Reduces task interference when combining multiple specializations.
- Creates more stable, multitask models.
Community Example:
Many NeuralHermes merges on Hugging Face use TIES to combine reasoning, coding, and alignment models effectively.
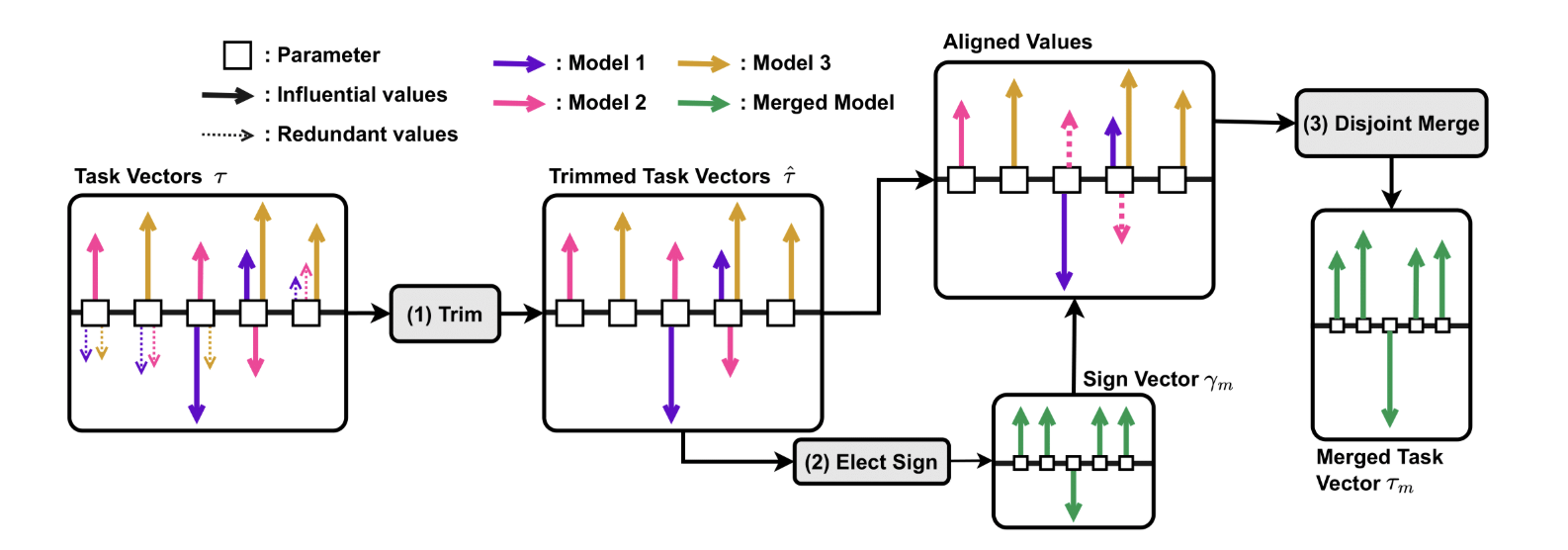
📊 Visual: llustrates the process involved in TIES-MERGING.
🔗 TIES-Merging Paper (arXiv 2306.01708)
DARE (Drop and Rescale)
Concept:
DARE is like TIES but more brutal:
- Randomly drops a large fraction (90–99%) of fine-tuned updates (sets them to zero).
- Rescales the rest so the model remains balanced.
Why it matters:
- Incredibly robust → even after dropping most deltas, merged models retain performance.
- Sometimes outperforms SLERP and TIES.
- Inspired by the idea that many fine-tuned changes are redundant or noisy.
Community Example:
- DAREdevil-7B merges have beaten SLERP merges on multiple benchmarks.
- The paper was nicknamed “Language Models are Super Mario” because models can absorb abilities like power-ups.
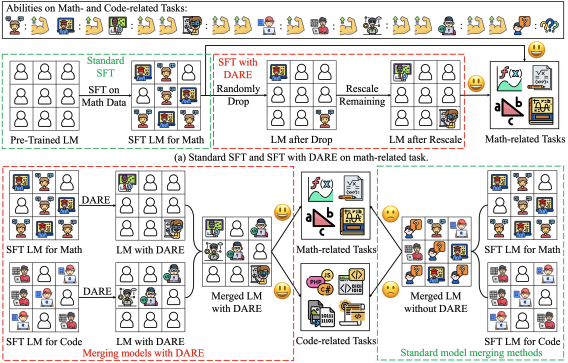
📊 Visual: Illustrations of DARE and merging models with DARE. DARE can achieve comparable performance with standard SFT with 90% or even 99% delta parameters removed. Moreover, DARE tackles the parameter interference issue when merging models and yields consistent improvements. At the top, we mark each icon with one or two muscle logos, indicating its ability for specific tasks. For example, the first or second icon has one muscle logo for math-related tasks, while the thirdor fourth icon can perform better in math with two muscle logos. The rescale operation in DARE multiplies the remainingparameters by 1/(1 − p), which enhances the task-specific abilities and leads to changes in icons after rescaling.
🔗 DARE Paper (arXiv 2311.03099)
Frankenmerges (Passthrough)
Concept:
Instead of averaging or interpolating, Frankenmerges literally stack layers from different models.
Example: Take first 32 layers from Model A + last 8 layers from Model B → 40-layer hybrid.
Why it matters:
- Produces exotic model sizes (e.g., 9B parameters from two 7B models).
- Has created some impressive open-source models (e.g., SOLAR-10.7B, Goliath-120B).
- But it’s highly experimental → can produce unstable or weird results.
Community Example:
Reddit’s “Waifu Research Department” and LocalLLaMA communities frequently experiment with Frankenmerges.
Quick Comparison
| Method | Best For | Limitation |
|---|---|---|
| Model Soup | Recycling many fine-tunes cheaply | May degrade if tasks are too different |
| SLERP | Smoothly combining 2 models | Only 2 at once |
| TIES | Stable multitask merges | Complexity, slower |
| DARE | Robust merges with pruning | Randomness, needs tuning |
| Frankenmerge | Creative hybrid architectures | Very experimental |
Other Merge Methods in MergeKit
In addition to the main ones we discussed above, mergekit also supports many other merging strategies.
Here’s a quick list (without deep dive), in case you want to explore further:
-
NuSLERP (
nuslerp) – faster, flexible SLERP. -
Multi-SLERP (
multislerp) – interpolate across >2 models. -
Karcher Mean (
karcher) – manifold-based average. -
Task Arithmetic (
task_arithmetic) – simple task vector merges. -
DELLA (
della,della_linear) – adaptive pruning based on weight magnitudes. -
Model Breadcrumbs (
breadcrumbs) – prune both smallest & largest updates. -
SCE (
sce) – variance-based selection, calculate, erase. -
Model Stock (
model_stock) – geometry-based interpolation. -
Nearswap (
nearswap) – param-wise selective merge. -
Arcee Fusion (
arcee_fusion) – importance-driven fusion. -
Passthrough (
passthrough) – raw layer stacking (basis of Frankenmerges).
👉 Full documentation here:
🔗 MergeKit Docs: Merge Methods
Hands-On MergeKit🔧
Now that we’ve covered why merging matters and the main algorithms, let’s actually get our hands dirty with MergeKit. This walkthrough shows how to install it, run merges (SLERP, TIES, DARE-TIES), test the results, and push them to the Hugging Face Hub.
Install and Setup
pip install -U mergekit huggingface_hub transformers accelerate sentencepiece datasets
Authenticate with Hugging Face if you need gated models or want to publish your merge:
from huggingface_hub import notebook_login
notebook_login()
SLERP — Spherical Linear Interpolation
When to use: Smoothly blend exactly two models (e.g., reasoning + summarization).
Key parameter: parameters.t controls how much of Model B you mix into Model A.
- Single value → global blend (e.g.,
0.5 = 50/50) - List of values → per-layer schedule
Config (config_slerp.yaml):
models:
- model: NousResearch/Hermes-2-Pro-Mistral-7B
- model: WizardLM/WizardMath-7B-V1.1
merge_method: slerp
base_model: NousResearch/Hermes-2-Pro-Mistral-7B
dtype: bfloat16
parameters:
t: 0.5
Run merge:
mergekit-yaml config_slerp.yaml ./merge_slerp \
--copy-tokenizer --out-shard-size 1B --lazy-unpickle --allow-crimes
Quick smoke test:
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
tok = AutoTokenizer.from_pretrained("./merge_slerp")
model = AutoModelForCausalLM.from_pretrained("./merge_slerp", device_map="auto")
pipe = pipeline("text-generation", model=model, tokenizer=tok)
print(pipe("Explain model merging in two bullets:", max_new_tokens=60)[0]["generated_text"])
TIES — Interference-Aware Merge
When to use: Merge multiple fine-tunes while handling conflicting updates.
Key parameters:
-
weight: contribution of each model -
density: fraction of deltas retained (sparsify to reduce noise) -
normalize: ensures weights sum to 1
Config (config_ties.yaml):
models:
- model: mistralai/Mistral-7B-v0.1
- model: OpenPipe/mistral-ft-optimized-1218
parameters: {density: 0.5, weight: 0.5}
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
parameters: {density: 0.5, weight: 0.3}
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters: {normalize: true}
dtype: float16
Run merge:
mergekit-yaml config_ties.yaml ./merge_ties \
--copy-tokenizer --out-shard-size 1B --lazy-unpickle
DARE-TIES — Drop-and-Rescale + Sign Consensus
When to use: You want robust merges by pruning deltas aggressively and rescaling the survivors.
Key parameters:
-
density: fraction of deltas kept -
weight: relative strength of each task model -
int8_mask: true: compact pruning masks
Config (config_dare.yaml):
models:
- model: mistralai/Mistral-7B-v0.1
- model: OpenPipe/mistral-ft-optimized-1218
parameters: {density: 0.53, weight: 0.4}
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
parameters: {density: 0.53, weight: 0.3}
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters: {int8_mask: true}
dtype: bfloat16
Run merge:
mergekit-yaml config_dare.yaml ./merge_dare \
--copy-tokenizer --out-shard-size 1B --lazy-unpickle
Pushing to Hugging Face Hub
Embed your YAML config in the model card for reproducibility:
from huggingface_hub import HfApi, ModelCard
import os
yaml_text = open("config_slerp.yaml").read()
card = ModelCard(f"# MyMergedModel\n\nMerged with MergeKit.\n\n```yaml\n{yaml_text}\n```")
card.save("./merge_slerp/README.md")
api = HfApi()
api.create_repo("your-username/MyMergedModel", repo_type="model", exist_ok=True)
api.upload_folder(repo_id="your-username/MyMergedModel", folder_path="./merge_slerp")
print("✅ Pushed to Hugging Face Hub!")
Key Takeaways
- SLERP is great for smooth 2-model blends.
- TIES stabilizes merges across multiple specializations.
- DARE-TIES is robust even with heavy pruning.
- Always use
--copy-tokenizer, and add--out-shard-size 1B+--lazy-unpickleto avoid memory issues.
✨ With just these few configs and commands, you can go from two fine-tunes to a new, merged model ready to test, evaluate, and publish.
Conclusion 
Model merging has quickly evolved from a niche experiment into a practical tool for the open-source LLM community. By combining the strengths of multiple fine-tunes, we can:
- Recycle experiments instead of discarding them
- Blend capabilities (reasoning, summarization, coding, alignment) into a single model
- Cut costs by avoiding expensive re-training from scratch
With libraries like MergeKit, this process has become approachable — whether you’re doing a simple SLERP blend, a more careful TIES merge, or pushing robustness with DARE-TIES. In just a few commands, you can create a new model, test it, and share it on the Hugging Face Hub with a reproducible config.
Merging isn’t a silver bullet — mismatched models can clash, and evaluation is still crucial — but it’s a powerful addition to the modern LLM toolbox. As research continues, expect to see more sophisticated merge methods, better evaluation practices, and community-driven “frankenmerges” that push performance boundaries.
✨ Takeaway: Model merging is no longer just an experimental hack. It’s becoming a cornerstone technique in how we build and share models — fast, cost-effective, and collaborative. If you haven’t tried it yet, now’s the time.