1. はじめに
NTTテクノクロスの上原です。弊社アドベントカレンダーの8日目の記事を書きます。
簡単に自己紹介ですが、自分は現在PostgreSQL 5年生で、弊社ではPostgreSQL関連の業務(設計コンサル、トラブルシュート等のサポートやDBの移行支援等)を担当しております。
最近では、オンプレ環境だけでなく、AWS上の移行案件についての対応も増えてきております。
今回は今更ではありますが、syncdbというツールをDB移行に利用するケースを想定した際の性能についてお話させていただきます。
What is syncdb?
syncdbとは、PostgreSQL、Oracleを対象に任意のテーブルを同期する機能を提供するOSS製品です。
同じDBはもちろん、異種DB間であっても任意のテーブルを同期することができるという画期的な機能を提供します。
同期機能は「全体リフレッシュ」、「差分リフレッシュ」の2つが提供されています。
- 全体リフレッシュ
- 初回同期時や更新量が多い場合に選択される同期方式で同期対象のテーブルをTRUNCATEしテーブルを全体のINSERTを行う。
- 差分リフレッシュ
- 更新量がすくない場合に選択される同期方式でsyncdbのメイン機能。
- 記録された差分ログ情報に基づき、同期先のテーブルを操作する。
syncdbの用途としては、テーブルの冗長化、異種DB間の連携やDB移行に利用することができます。
大雑把にですが、こんなイメージです。
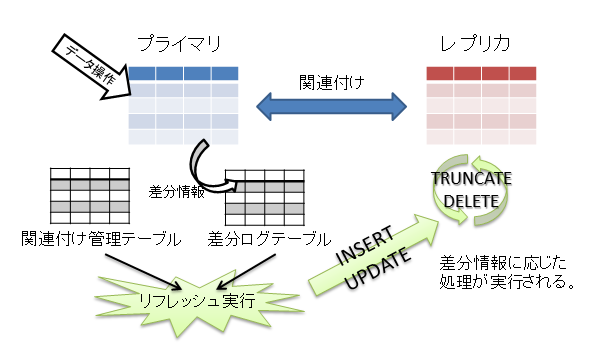
※処理の詳細はマニュアルに記載されているので、詳しくはコチラを御覧ください。
なぜ、syncdbの性能を確認したいの?
ツールをご存知の方は何を今更と思うでしょう。
実はこのツールは約10年前に公開されており、PostgreSQLでいうと「8.4」あたりの時代作られたものです。(ちなみに自分は今回初めてsyncdbを触りました汗)
最初に紹介させていただいたとおり、自分はDBの移行支援の業務を行っているのですが、移行の方式検討に対して「syncdbって検討してみた?」というコメントを内部で指摘され、もしかしたらハマるパターンがあるような気がして、モヤモヤを抱えておりました。
そんな中、アドベントカレンダーの時期がやってきたので、良い機会なのでこのモヤモヤを晴らそうと本テーマを選びました!
前置きが長くなってしまいましたが、ここから本題です!
2. 実施概要
今回は、比較的規模の大きいデータベース移行でsyncdbを利用できるかどうか指標となる値を取得する。という観点で測定を行っています。
そのため、今回の測定では 「全体リフレッシュ」についてのみ 測定しています。
syncdbは本来の用途(差分リフレッシュができる)とは異なる使い方なので、結果はあくまで参考情報である点に注意してください。
環境
検証はAWS上で実施しています。
- PostgreSQLのバージョン
| sync元 | sync先 |
|---|---|
| PostgreSQL 8.4 | Aurora PostgreSQL (compatible with PostgreSQL 10.7) |
※移行を想定して、sync元は敢えて古いバージョンのものを利用しています。
-
テーブルサイズ:800MB、4GB
- ある程度傾向が掴めれば良いので、この2点で測定します。
-
syncdbは移行元環境のEC2上で実行します。
測定パターン
以下の4つのパターンで測定を行いました。
| Case | 概要 | sync元(EC2) インスタンスタイプ |
sync先(Amazon Aurora) インスタンスタイプ |
テーブルサイズ |
|---|---|---|---|---|
| 1 | ベースライン取得 | t2.micro | db.r5.large | 800MB1テーブル, 4GB1テーブル (2パターン) |
| 2 | インスタンス強化 | m5.large | db.r5.large | 4GB*1テーブル (1パターン) |
| 3-1 | インスタンス強化 syncdbの並列実行 |
c5.2xlarge | db.r5.large | 800MB*5テーブル (1パターン) |
| 3-2 | インスタンス強化 syncdbの並列実行 DBインスタンス強化 |
c5.2xlarge | db.r5.xlarge | 800MB*5テーブル (1パターン) |
3. 検証結果
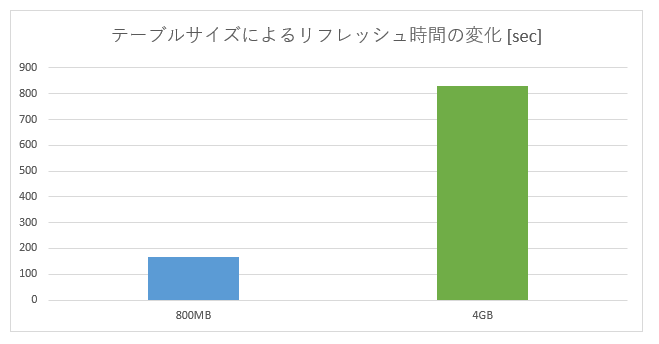
3.1. テーブルサイズと処理時間の傾向
- 結果:1GBあたり約3分
- 処理時間とリフレッシュ対象のテーブルサイズはほぼ完全に比例することを確認した。
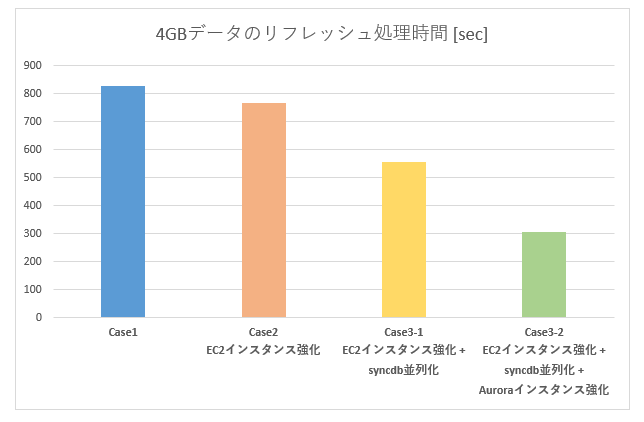
3.2. 条件による処理時間の変化
- 5並列環境において、1GBあたり約1分
- CPUリソースに余裕があれば、複数テーブルを同時に処理させることで処理時間の短縮は見込めるとわかった。
- CPUリソースに余裕がない状態では並列化の効果は薄かった。(Case3-1)
- リソースに合う並列化であれば、単位時間あたりの処理性能を上げることができた。(Case3-2)
4. 検証手順(以下、参考情報です。)
以降は、測定の手順や結果の詳細について記します。興味があれば、読んでみてください。
4.1. 事前準備
初期データ投入
$ createdb sf60
$ createdb sf300
$ pgbench -i -s 60 sf60
syncdb構築
syncdbのマニュアルを参考に以下のコマンドを実行していく。
# syncdb用のモジュールをDBに登録する
$ createlang plpgsql sf60
$ createlang plpgsql sf300
$ psql sf60 -f ~/adventCalendar/syncdb-1.0.3/sql/mlog_postgresql.sql
# sync先のDBにもモジュールを登録する
$ psql -U postgres -h <Aurora Endpoint> -f ~/adventCalendar/syncdb-1.0.3/sql/observer_postgresql.sql rep_sf60
設定ファイルは以下のように定義した
<?xml version="1.0" encoding="UTF-8"?>
<SyncDatabase>
<jdbcResource>
<name>ec2_sf60</name>
<className>org.postgresql.Driver</className>
<url>jdbc:postgresql://localhost:5432/sf60</url>
<username>uehara</username>
<password></password>
</jdbcResource>
<jdbcResource>
<name>aurora_sf60</name>
<className>org.postgresql.Driver</className>
<url>jdbc:postgresql://<Aurora Endpoint>:5432/rep_sf60</url>
<username>postgres</username>
<password>postgres</password>
</jdbcResource>
</SyncDatabase>
リフレッシュに向けた準備
syncされる側には予めsync元と同じテーブルスキーマが登録されている必要があるので、テーブルを作成しておきます。
$ psql rep_sf60 -Upostgres -h <Aurora Endpoint> -c 'CREATE TABLE pgbench_accounts(aid int, bid int, abalance int, filler char(84), PRIMARY KEY(aid))'
$ syncdb create --master ec2_sf60 --schema public --table pgbench_accounts
$ syncdb attach --master ec2_sf60 --server aurora_sf60 --schema public --table pgbench_accounts
input query : SELECT aid, bid, abalance, filler FROM "public"."pgbench_accounts"<改行>を入力
<ctrl+d>を入力
4.2. 測定結果
Case1:処理時間のベースライン取得
Case1では、DBサイズを800MBと4GBの2パターンでの処理の時間を測定します。
$ date; time syncdb refresh --server aurora_sf60 --schema public --table pgbench_accounts --mode auto; date
検証条件
- EC2:t2.micro
- Amazon Aurora:db.r5.large
- テーブルサイズ
- 800MB*1テーブル
- 4GB*1テーブル
結果
以下のとおりで、800MBで3分弱でした。
Mon Dec 2 02:37:05 UTC 2019
INFO - full refresh (insert:6,000,000)
real 2m46.556s
user 0m42.540s
sys 0m2.239s
Mon Dec 2 02:39:51 UTC 2019
4GBだと、およそ14分という結果でした。
Mon Dec 2 02:47:48 UTC 2019
INFO - full refresh (insert:30,000,000)
real 13m48.802s
user 3m22.874s
sys 0m9.948s
Mon Dec 2 03:01:37 UTC 2019
つまり、データ量を5倍にすると処理時間もきっかり5倍となり、データサイズと処理時間が比例していることが確認できました。
もし、1TBのテーブルを移そうと思うと、、、60時間!?
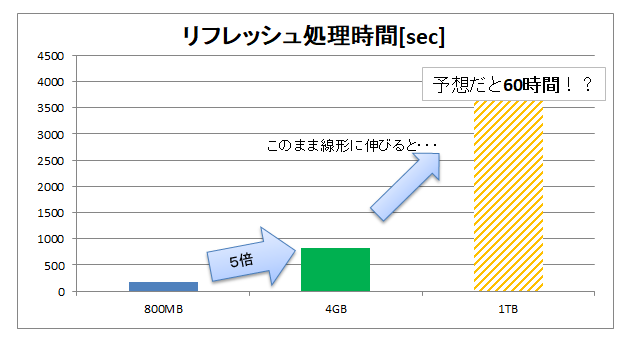
あかんやつだ。。。
Case2:インスタンスタイプ強化
さすがにCase1の結果だと、悲しい結果なので、なんとか早くできる方法がないか試してみようと思います。
AWSのパフォーマンスインサイトの情報を確認する限り、特にDB側がネックになっている様子は見えなかったので、EC2側のインスタンスを強化して再測定を行いました。
検証条件
- EC2:m5.xlarge
- Amazon Aurora:db.r5.large
- テーブルサイズ:4GB*1テーブル
結果
Mon Dec 2 09:48:10 UTC 2019
INFO - full refresh (insert:30,000,000)
real 12m49.120s
user 2m48.374s
sys 0m16.408s
Mon Dec 2 10:00:59 UTC 2019
ほぼ効果なし!
Case2は、一応やってみたけど、実施前にEC2側のSar、Auraraのパフォーマンスインサイトを確認した限り特にボトルネックになっている部分は見られなかったので、これは妥当な結果といえる。(じゃあ、なんでやったんだよ!)
Case3-1:syncdbの並列実行
テーブル単位で並列実行することで処理効率を上げて、総処理時間の短縮を図ることができるか確認します。
ちなみに、並列実行機能はないので、以下のように単にsyncdbコマンドを同じタイミングで複数回実行する形で検証しました。
for i in 01 02 03 04 05
do
syncdb refresh --server aurora_sf60 --schema public --table pgbench_accounts${i} --mode auto & > /dev/null 2>&1
done
検証条件
- EC2:c5.2xlarge
- Amazon Aurora:db.r5.large
- テーブルサイズ:800MB*5テーブル
結果
Mon Dec 2 10:40:43 UTC 2019
INFO - full refresh (insert:6,000,000)
real 9m17.262s
user 0m30.870s
sys 0m1.954s
Mon Dec 2 10:50:01 UTC 2019
思っていたほどの効果はない!
あれ?9分って、これじゃあ、そんなに処理時間が変わらない。。。5並列なのに、25%程度の改善でしかない。
パフォーマンスインサイトを見ると、Aurora側のCPUがカツカツになっていることが見える。まぁ、syncdbを並列実行してAuroraに対する同時接続数が増えているので当然の結果ですね。
Case3-2:syncdbの並列実行(DBインスタンス強化)
テーブル単位で並列実行することで処理効率を上げるため、Aurora側のCPU数を2倍にして、総処理時間の短縮を図ることができるか確認します。
検証条件
- EC2:c5.2xlarge
- Amazon Aurora:db.r5.xlarge
- テーブルサイズ:800MB*5テーブル
結果
Thu Dec 5 02:29:01 UTC 2019
INFO - full refresh (insert:6,000,000)
real 5m6.538s
user 0m31.838s
sys 0m1.555s
Thu Dec 5 02:34:07 UTC 2019
素晴らしい!!
Case3-1では、syncdbの並列数に対してAurora側のCPU数が少ない状態でしたが、この検証でCPU数を倍にしたことでネックがある程度解消され、処理時間を短縮することができました!
とはいえ、syncdb5並列に対して、Auroraは4CPUという条件なので、パフォーマンスインサイトを見るとまだCPUがネックになっているようでした。インスタンスタイプを上げてCPU数を増やせば、改善はできそうですが、感触は掴めたので今回はここまで。
4.3. 検証で実施できていないこと
- 差分リフレッシュの測定
- syncdbの肝の機能なので、本当はこちらについても測定したほうがよいのですが本記事ではここまでとなります。
6. さいごに
モヤモヤはなくなり、すっきりしました。
もともとの検証の動機だった、「対応した案件にハマるかも」という疑問に対しては「条件が合えば可能」というのが結論です。(はっきりしない結論で恐縮です。。。)
- 採用の判断の際、以下の内容には注意する必要がある。
- 例えば、1テーブルでTBオーダのものが存在するようなケースでは難しい。(検証結果からすると60時間コースになってしまう)
- テーブル毎に差分ログテーブルを用意する必要があるので、数百テーブルあるシステムではセットアップのコストが高くなる。(部分的にsyncdbを使うというのは可能)
- 同期対象テーブルの更新量が少ないか?多いと差分リフレッシュはできず全体リフレッシュになってしまう。
移行方式の検討段階で、「移行元のバージョンが古すぎてベンダの提供する移行サービス等を利用できない」といった問題があれば、 syncdb の利用を検討してみてはどうでしょうか?
全テーブルをsyncdbの対象とはせず、一部のテーブルだけはsyncdbを利用するというようなハイブリットな構成であれば、対応できるケースも増えると思います。
明日は戸部さんによるJetpack Composeに関する記事が投稿される予定です。お楽しみに!