python seleniumで取得したデータのlist分割について
リストの中の要素を分割したいと考えていますが、うまくいきません
.str.split("\n")などを試しました。
names = driver.find_elements(By.CLASS_NAME, "card__name")
prices = driver.find_elements(By.CLASS_NAME, "price_text")
numbers = driver.find_elements(By.CLASS_NAME, "card__number")
names = [name.text for name in names]
prices = [price.text for price in prices]
numbers = [number.text for number in numbers]
data = list(zip(namees, pricees, numberes))
col = ["name", "price", "ID"]
df = pd.DataFrame(data)
df.columns = col
print(df)
出力の結果は、このような感じになります。
出力結果.py
name price ID
0 白山辰\nDragon Car 100000 #721154
1 白山子年\nRat 29888 #11797262
2 七面様\nSeven Faces 2200 #3860464145
3 巫女乃花弁\nMiko petals 1500 #272957709
4 白山巳鳥\nSerpent Bird 500 #2283077892
... ... ... ...
4793 日本武尊\nYamato Takeru 980 #10760946689
4794 金宇賀様\nGolden Uga 980 #11888034823
4795 聖夜祭\nChristmas 980 #10815013896
4796 日本武尊\nYamato Takeru 980 #13590987777
4797 聖夜祭\nChristmas 980 #18433311752
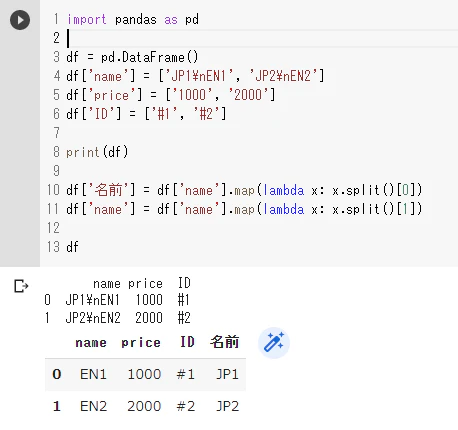
この中の"name"の部分を分割したいと考えているのですが、何かいい方法はありませんか?
具体的には、
name 名前 name
白山辰\nDragon Car ⇒ 白山辰 Dragon Car
白山子年\nRat ⇒ 白山子年 Rat
こんな感じに1つのカラムを2つに切りたいです。
良い方法を教えてください。
0 likes