1つ前の投稿で、Cloud Functionsで天気情報を取得、蓄積する方法を紹介しました。小規模な処理であればCloud Functionsで十分なのですが、処理が複雑になると以下のような問題点があります。
- 処理の進捗状況が把握しずらい
- 再実行オペレーションが行き当たりばったりになりがち(そもそもやりにくい)
これらを解決してくれるのがワークフローであり、Google CloudではCloud Composerが提供されています。Cloud Composerは、Apache Airflowで構築された、フルマネージドのワークフローサービスでなので、ユーザはワークフロー開発に専念することができます。
この投稿の実装範囲
今回はCloud Composerを利用して、以下のことを実装したいと思います。
- GCSバケットに特定のファイルが存在することを検知
- BigQueryへのデータ読込
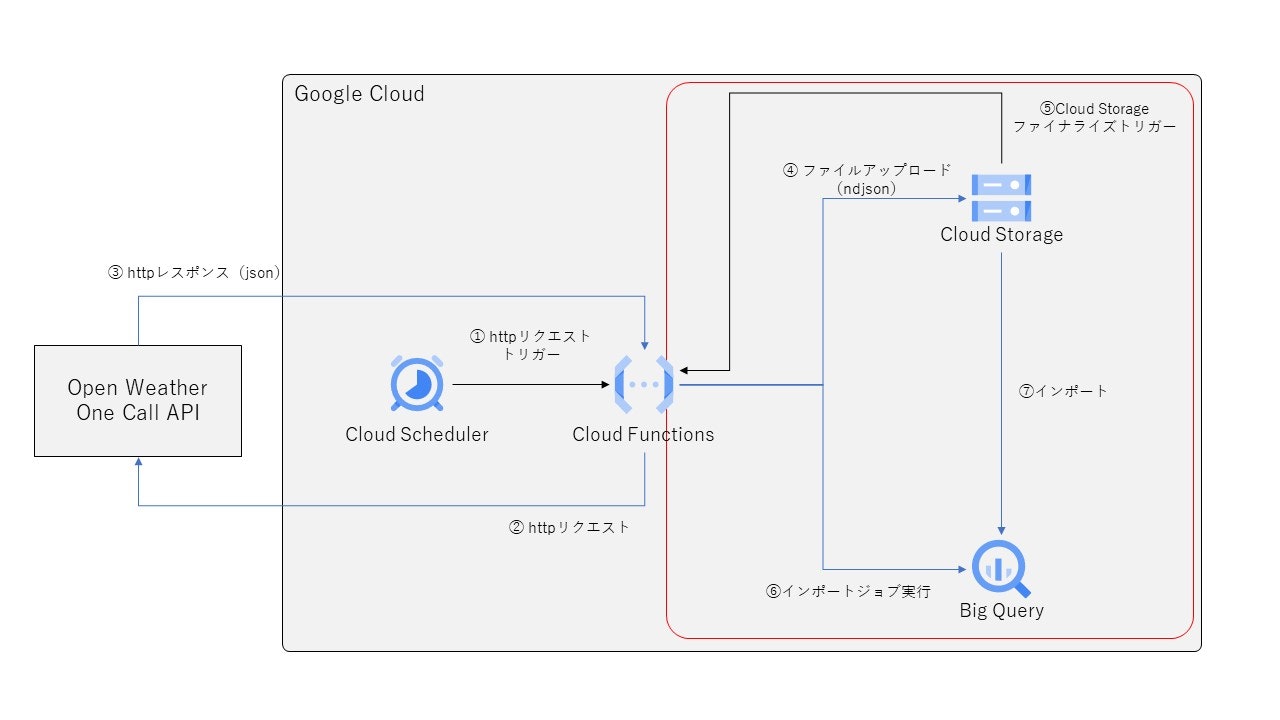
前回は、Cloud Functionsで提供されているGCS上でファイル作成のイベントを検知する仕組みを利用しましたが、ここら辺もCloud Composerで実装していきます。下の処理概要の図の赤枠部分をComposerで実行制御します。
Cloud Composerの環境設定
この投稿では、Cloud Composerの環境構築の詳細部分については説明を割愛しますが、Googleが環境構築のドキュメントを作成してくれているので、それに従えばOKです。私は以下のような感じで環境を作成しました。
- ロケーション:asia-east2
- ノード数:3
- マシンタイプ:n1-standard-1
- イメージバージョン:composer-1.18.6-airflow-2.2.3
- Python:3
作成完了までおおよそ20分程度かかります。
Apache Airflowについて
Apache Airflowは、PythonでDAG(有向非巡回グラフ)を定義します。ざっくりですが、以下の順序でプログラムを書き起こしていきます。
- DAGの設定
- 各タスクの設定
- タスク間の前後関係の設定
Airflowのチュートリアル見てもらえばなんとなく分かるのですが、作成したコードをみながら順番に確認していきましょう。
ソースコード
私が作成したPythonのソースコードは、以下の通りです。
from datetime import datetime, timedelta
import json
import pendulum
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.contrib.operators.gcs_to_bq import GoogleCloudStorageToBigQueryOperator
from airflow.contrib.sensors.gcs_sensor import GoogleCloudStoragePrefixSensor
from airflow.operators.dummy import DummyOperator
bucket = "対象のバケット名をここに記載してください"
with DAG(
'importBigQuery_WeatherData',
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=10),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'sla_miss_callback': yet_another_function,
# 'trigger_rule': 'all_success'
},
description='import Weather Data to BigQuery',
start_date=datetime(2021, 4, 1, tzinfo=pendulum.timezone('Asia/Tokyo')),
schedule_interval="30 9 * * *",
catchup=False,
tags=['WeatherData'],
) as dag:
with open('/home/airflow/gcs/dags/target_city.json', "r") as f:
f_json = json.load(f)
end_tasks=dict()
for city_json in f_json:
city_name = city_json["city_name"]
current_sensor = GoogleCloudStoragePrefixSensor(
task_id = "sensor-current-" + city_name,
bucket=bucket,
prefix="current_" + city_name + "_{{ next_execution_date | ds_nodash }}"
)
current_import = GoogleCloudStorageToBigQueryOperator(
task_id = "import-current-" + city_name,
bucket=bucket,
source_objects=["current_" + city_name + "_{{ next_execution_date | ds_nodash }}.json"],
source_format="NEWLINE_DELIMITED_JSON",
destination_project_dataset_table='sandbox.current_' + city_name + "_{{ next_execution_date | ds_nodash }}",
write_disposition='WRITE_TRUNCATE',
)
end_tasks["import-"+city_name] = current_import
current_sensor >> current_import
all_success = DummyOperator(
task_id = "All-Success"
)
for end_tasks_key in end_tasks.keys():
end_tasks[end_tasks_key] >> all_success
DAGの設定
DAGの設定部分は以下の箇所です。
with DAG(
'importBigQuery_WeatherData',
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=10),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'sla_miss_callback': yet_another_function,
# 'trigger_rule': 'all_success'
},
description='import Weather Data to BigQuery',
start_date=datetime(2021, 4, 1, tzinfo=pendulum.timezone('Asia/Tokyo')),
schedule_interval="30 9 * * *",
catchup=False,
tags=['WeatherData'],
) as dag:
ここには実行するDAGの以下のような設定を定義します。
- DAGの名称
- 処理失敗時の挙動
- リトライ実行回数
- リトライまでの時間間隔
- タイムアウト時間
- 実行開始日
- 実行スケジュール
など色々あります。ここら辺は別の機会に個々の項目について、丁寧にまとめて行こうと思います。
各タスクの設定
各タスクの定義は2箇所で行っています。1つ目は、「GoogleCloudStoragePrefixSensor」と「GoogleCloudStorageToBiQueryOperator」を利用して、GCP上のファイルの存在確認処理、JSONファイルのインポート処理を定義しています。
with open('/home/airflow/gcs/dags/target_city.json', "r") as f:
f_json = json.load(f)
end_tasks=dict()
for city_json in f_json:
city_name = city_json["city_name"]
current_sensor = GoogleCloudStoragePrefixSensor(
task_id = "sensor-current-" + city_name,
bucket=bucket,
prefix="current_" + city_name + "_{{ next_execution_date | ds_nodash }}"
)
current_import = GoogleCloudStorageToBigQueryOperator(
task_id = "import-current-" + city_name,
bucket=bucket,
source_objects=["current_" + city_name + "_{{ next_execution_date | ds_nodash }}.json"],
source_format="NEWLINE_DELIMITED_JSON",
destination_project_dataset_table='sandbox.current_' + city_name + "_{{ next_execution_date | ds_nodash }}",
write_disposition='WRITE_TRUNCATE',
)
end_tasks["import-"+city_name] = current_import
2つ目は、「DummyOpererator」を利用して、すべてのインポート処理が終わった後にDAG内のタスクがすべて終了したことを確認するためのダミータスクを定義しました。これくらいの小規模DAGであればよいですが、大規模になってくると確認が面倒になってくるので。
それと、プログラムの中で登場する{{ }}で囲まれた部分は、airflow上で特別な意味を持ちます。実行日を制御するはexecution_dateなどよく利用するのですが、結構仕様がややこしいのでこちらも別途DAGの設定と合わせて詳細なお話をまとめようと思います。ここら辺の話はAirflowのドキュメントにもまとまっているので、参照してみるといいかもです。
タスク間の前後関係の設定
最後にタスクの前後関係を定義を見ていきます。これも2箇所で行っています。タスクの依存関係は「>>」を使います。1つ目は、ファイルの存在検知とインポート処理の前後関係を定義しています。
current_sensor >> current_import
2つ目はインポート処理とダミータスクの前後関係を定義しています。
for end_tasks_key in end_tasks.keys():
end_tasks[end_tasks_key] >> all_success
都市名の定義ファイル
[
{
"city_name":"fukuoka"
},
{
"city_name":"tokyo"
}
]
Web管理画面について
Composer環境の作成が完了すると、Cloud Consoleの画面は以下のようになっています。

赤枠部分のリンクをクリックすると、以下のようなApache Airflowの管理画面が表示されます。
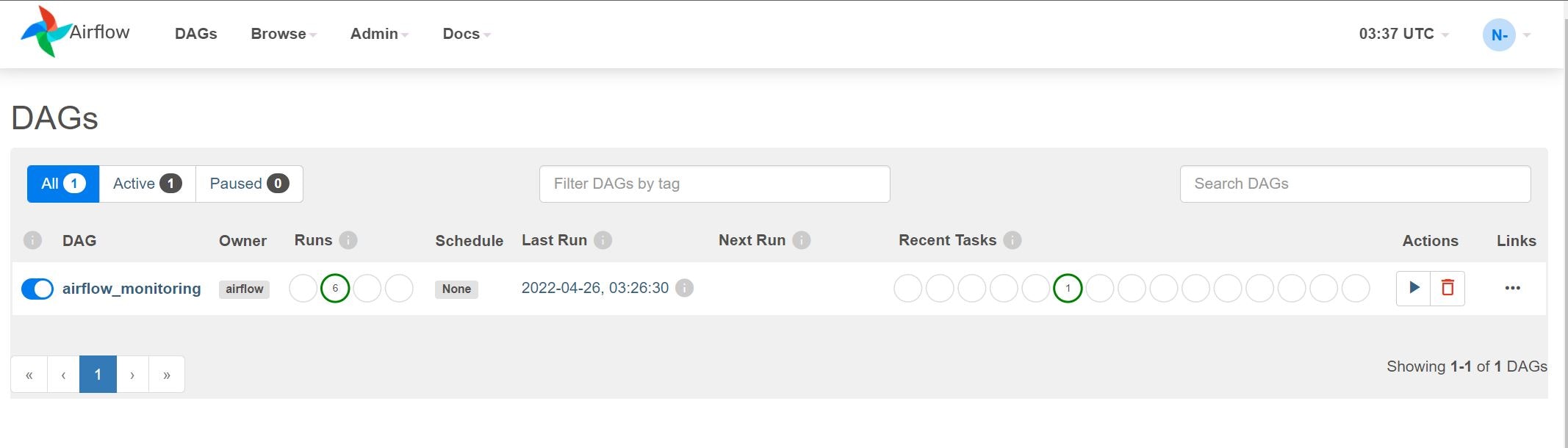
airflow_monitoringというDAGすでに登録されていますが、これは状態監視を行うために稼働しているものとなります。このままにしているとずっと動き続けるので、邪魔だなと思ったらスケジュールを止めちゃうこともできます。止め方は簡単です。上の赤枠部分をクリックするとスケジュールが停止します。
クリックして色が変わればOKです。
これでスケジュールを停止させることができました!
プログラムのリリースについて
同じくCloud ConsoleのComposer画面からDAGフォルダのリンクをクリックします。

するとGCSの画面が新しいタブで開かれます。

ここに必要なファイルをアップロードすれば、リリース完了です。ということで、先ほどの「importBigQuery.py」と「target_city.json」をアップロードします。

AirflowのWeb管理画面に戻ると・・・
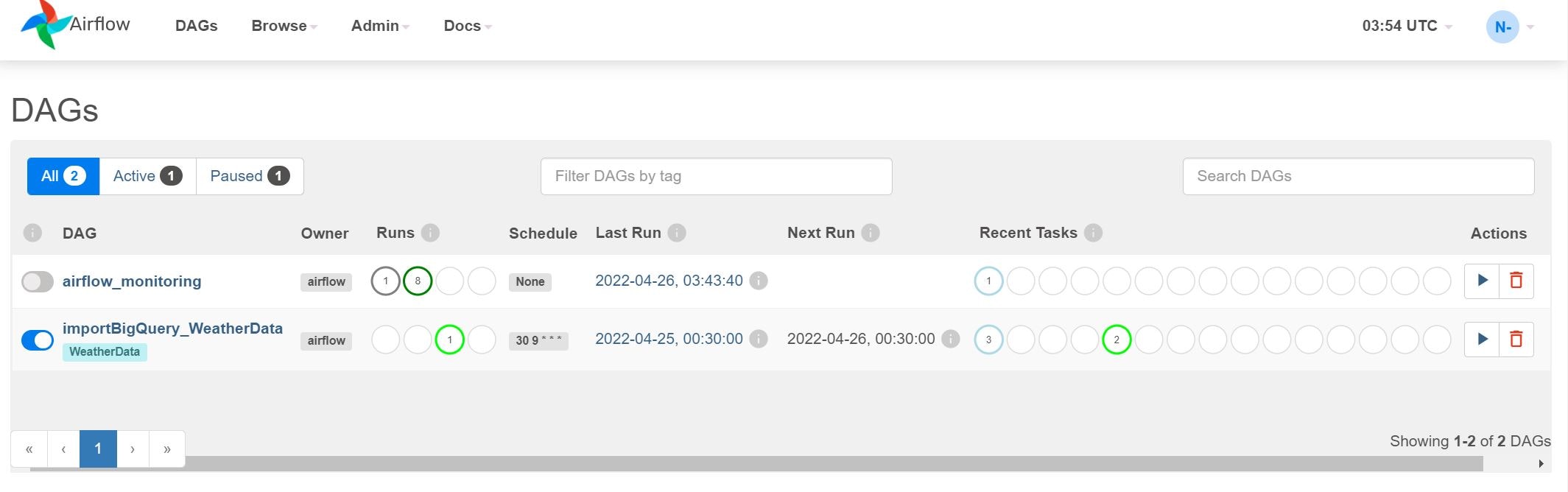
importBigQuery_WeatherDataというDAGが以下されています。表示されない場合は、ブラウザの更新をやってみてください。また、DAG名をクリックすると詳細情報を見ることができます。
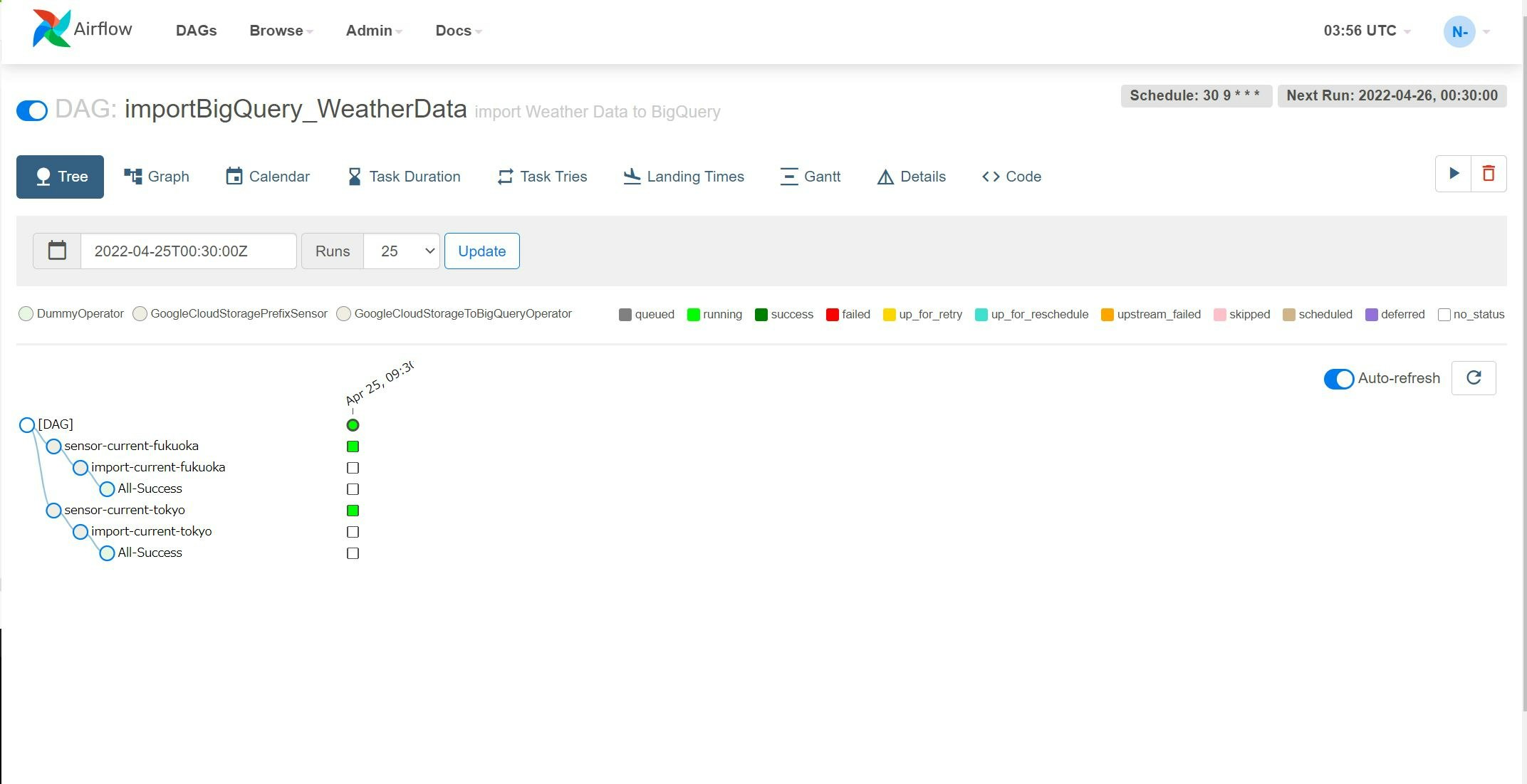
最初に表示されるのが、Tree画面です。これは、DAGの階層構造および、過去の実行結果を参照することができます。
Graphタブを押すと以下のような画面が表示されます。
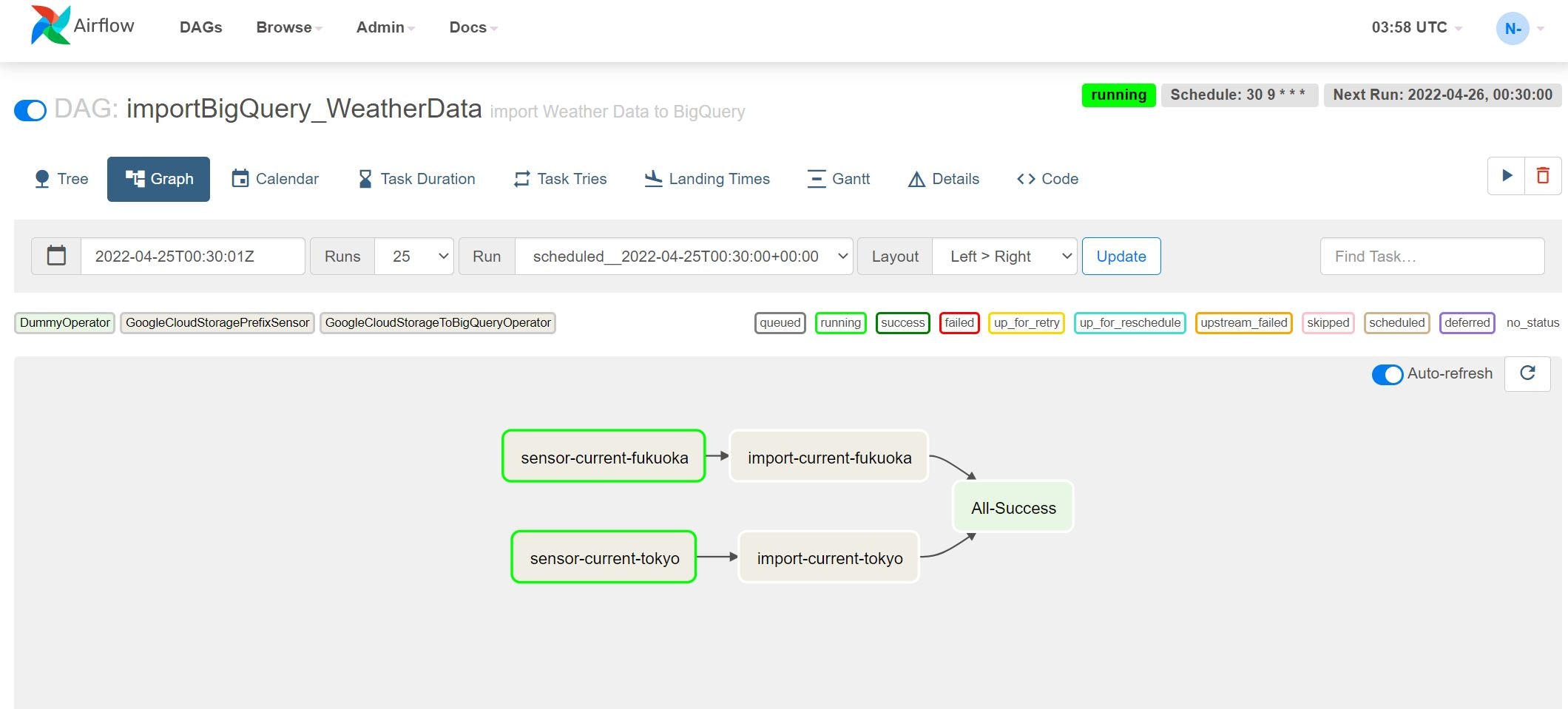
いかにもワークフローのような画面が表示されました。この例ではsensor-current-fukuokaとsensor-current-tokyoという2タスクが、GCS上のファイル存在有無を確認行っている状態で、現在ファイルが存在しないため実行中(running)のステータスとなっています。それでは、ファイルを配置して処理が動くか確かめていきます。

対象ファイルを配置すると・・・
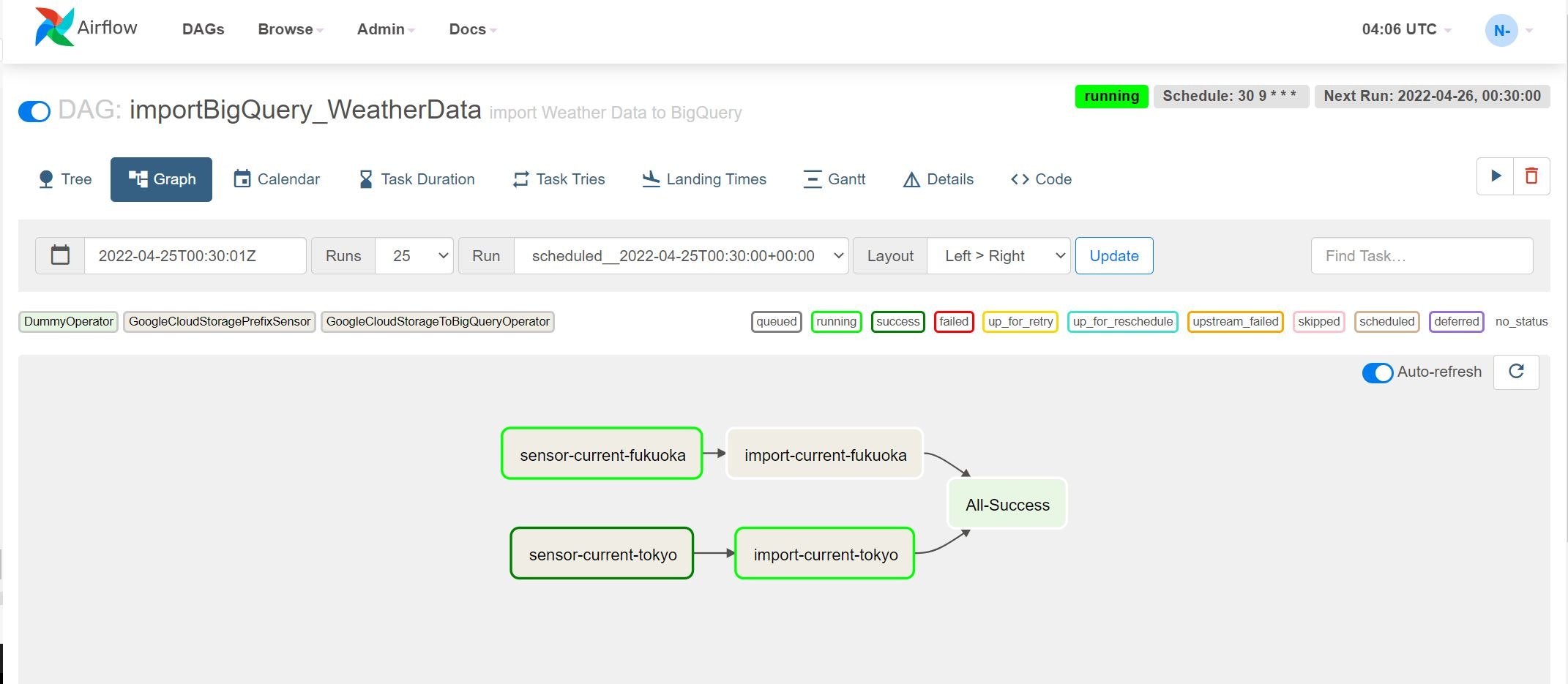
動き出しました!濃い緑色が正常終了です。もう少し待つと・・・
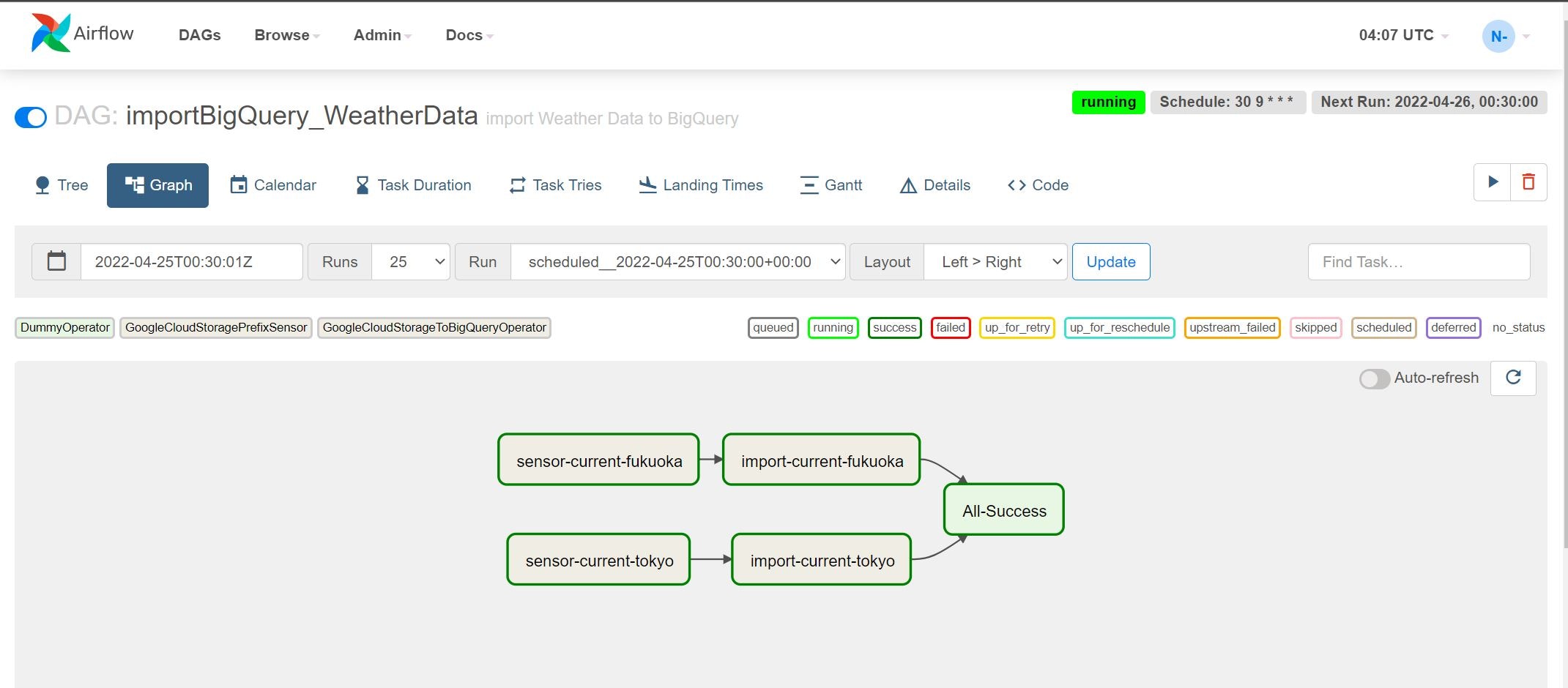
無事すべて正常終了しました。
BigQueryの確認
念のためデータがインポートされているか確認します。
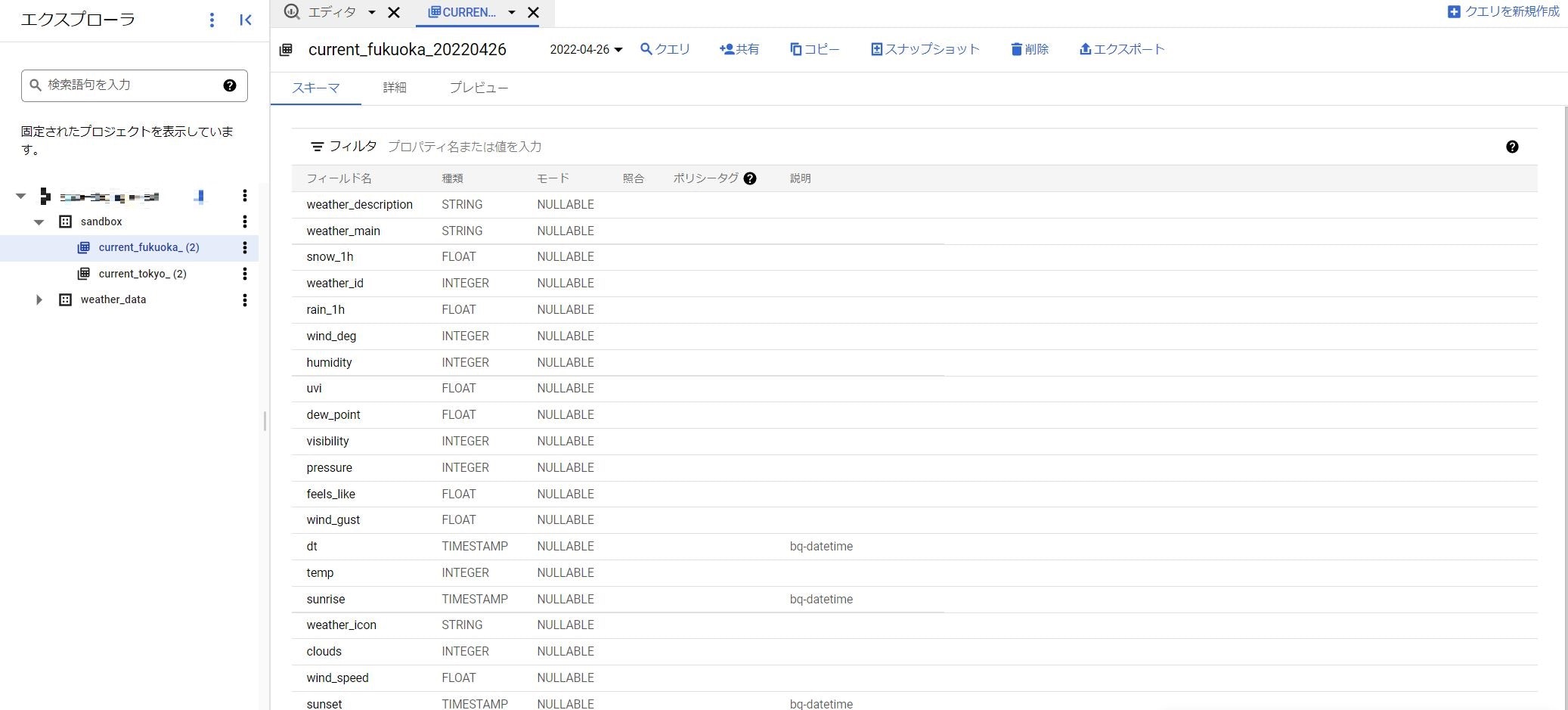
インポートされてました!