はじめに
出典先のcode、websiteは、株式会社インテルの社員の方に許可をもらっています。
OpenVinoとは(コンパクトに説明)##
Intelが提供する高性能なコンピューター・ビジョンやディープラーニングを開発可能が可能になるソフトウェアです。
分かりやすく言うと、
AIモデルの作成の仕方を知らない学生・エンジニアも、簡単なAIプログラム、サービスを作成できる!
また、AIエンジニアは自作・自社開発したAIモデルをより手軽に、短時間で商業用のサービスとして開発できる
OpenVINOのしくみ(概略)
1.TensorFlow、MxNet、Caffe、Kaldi、、ONNXフレームワークでトレーニングされたモデルが拡張子が.xmlおよび.binに変換される
(.xmlファイルは最適化されたグラフを表していて、.binファイルには重みが含まれています)
2.これらのファイルを使用し、推論APIが作成される
3.推論APIを使用して、gRPCインターフェースを介して提供されるAIサービスを簡単に作成できる
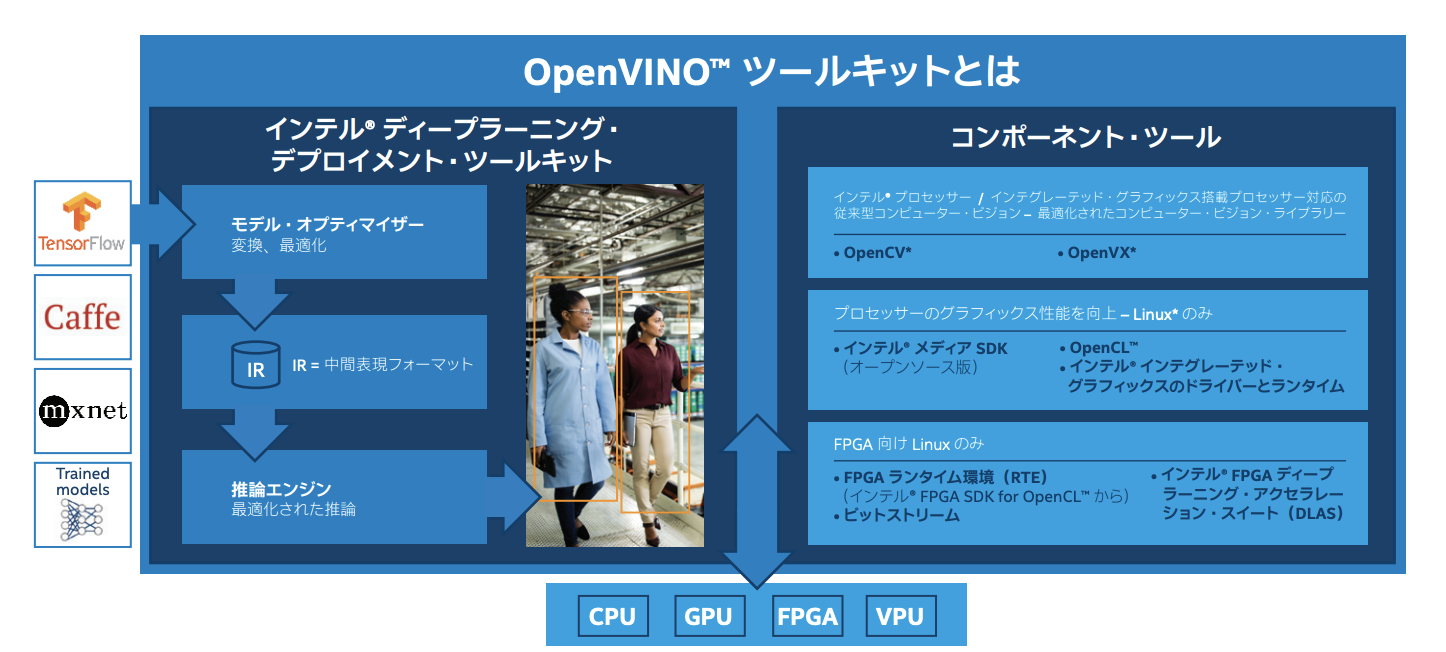
出典:Intel公式website
URL: https://www.intel.co.jp/content/www/jp/ja/internet-of-things/solution-briefs/openvino-toolkit-product-brief.html
OpenVINOモデルサーバーとは
OpenVinoモデルサーバーとは、gRPCまたはREST APIを介して推論サービスを提供してくれるdockerイメージです。
簡単なコマンドで、AIモデルの推論を返すportを作ることができます。
OpenVINOモデルサーバーの使用方法
1.モデルオプティマイザー(学習モデルをIRにするやつです)を使用して、TensorFlow保存モデル表現からIRモデル形式を生成する
以下の例のようなコマンドを使用できます
mo_tf.py --saved_model_dir /tf_models/resnet_v1_50 --output_dir /ir_models/resnet_v1_50/ --model_name resnet_v1_50
mo_tf.pyは、OpenVinoToolKitをインストールすると,PC(MacOSの場合)に以下のようなpathにあります
また、他のモデルは、/opt/intel/openvino/deployment_tools/open_model_zoo以下にあります。(ない場合は、モデルオプティマイザーを使用せずに、Intelの公式リポジトリから.xml、.binファイルをダウンロードして、手順2にskipしてください)
|USER_NAME|:model_optimizer |USER_NAME|$ ls
extensions mo_mxnet.py requirements_mxnet.txt
install_prerequisites mo_onnx.py requirements_onnx.txt
mo mo_tf.py requirements_tf.txt
mo.py requirements.txt version.txt
mo_caffe.py requirements_caffe.txt
mo_kaldi.py requirements_kaldi.txt
|USER_NAME|:model_optimizer |USER_NAME|$ pwd
/opt/intel/openvino/deployment_tools/model_optimizer
2.モデルのフォルダー構造設定
モデルを含むフォルダー構造
モデル(.xml,.bin)を使用する前に以下のようなフォルダー構造に配置する必要があります。
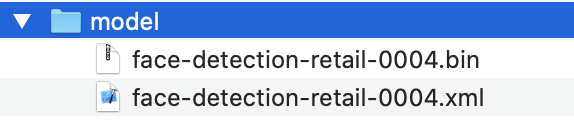
各モデルには、すべてのバージョンが数値名のサブフォルダーに格納される個別のフォルダーが必要です。 このように、OpenVINOモデルサーバーは複数のモデルを処理し、TensorFlow Servingと同様の方法でそれらのバージョンを管理できます。
3.導入プロセス
展開プロセスは次の2つのステップに制限されています。
1.次のコマンドを使用して、Dockerイメージをビルドします
docker build -t openvino-model-server:latest
出典:Intelの社員の方github
URL: https://github.com/openvinotoolkit/model_server
2.次のコマンドを使用して、Dockerコンテナーを開始します
docker run -d -v $(pwd)/model:/models/face-detection/1 -e LOG_LEVEL=DEBUG -p 8000:8000 openvino/ubuntu18_model_server /ie-serving-py/start_server.sh ie_serving model --model_path /models/face-detection --model_name face-detection --port 8000 --shape auto
出典:Intelの社員の方のgithub(前と同じURLです)
(詳しい説明は次回行います)
これらの2つのステップが完了すると、OpenVINOモデルサーバーはDockerコンテナー上で実行されポート8000でgRPCAPIと動きます
4.check
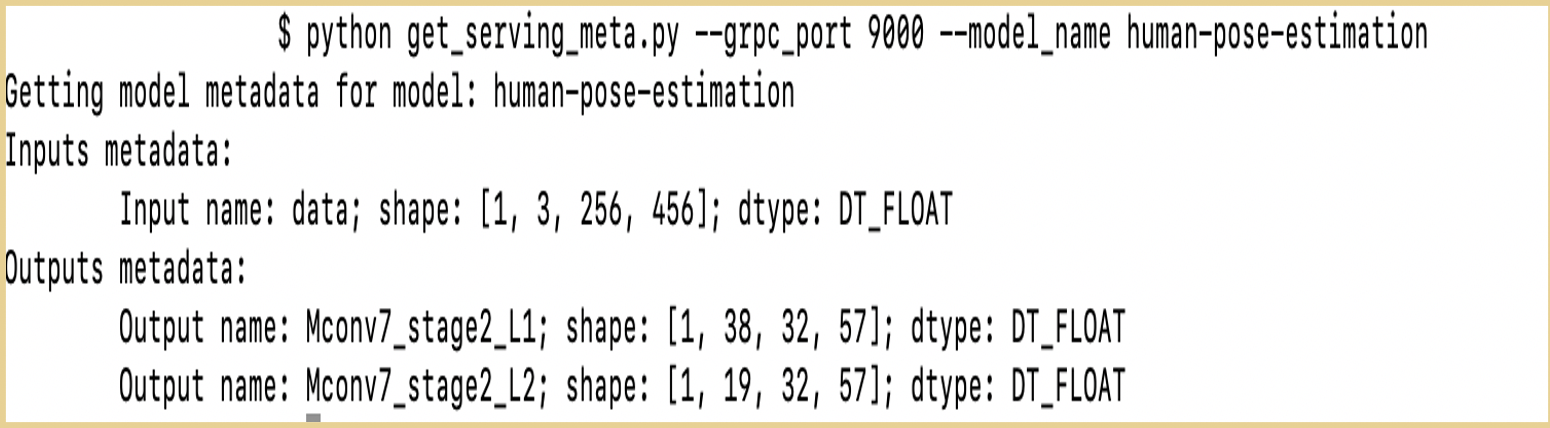
Intelの社員の方のgithub(前と同じURLです)にある、get_serving_meta.pyを使用すると、3でopenしたportが正常に動いているかをcheckできます。
get_serving_meta.pyをRunする時に、以下のコマンドライン引数を打つと、指定したportで推論実行できるAIモデルのInput metadataとOutput metadataがでます。
python get_serving_meta.py --grpc_port DOCKER_PORT_NUMBER --model_name AI_MODEL_NAME
下の例は、他のAIモデル、port番号のcheck成功例です。