はじめに
「ニューラルネットワークは数字を認識できる」と言われても、中で何が起きているのか実感がわかない。
そこで、指やマウスで数字を描くと、CNN(畳み込みニューラルネットワーク — 画像認識に特化したAIの一種)が認識する過程をリアルタイムで可視化するツールを作りました。
デモはこちら(ブラウザだけで動きます。インストール不要)
GitHub
https://github.com/Tomoiura/digit_recognizer
これは何か
手書き数字認識の裏側で、ニューラルネットワークがどう判断しているかを目の前で見られるツールです。
3つの可視化
-
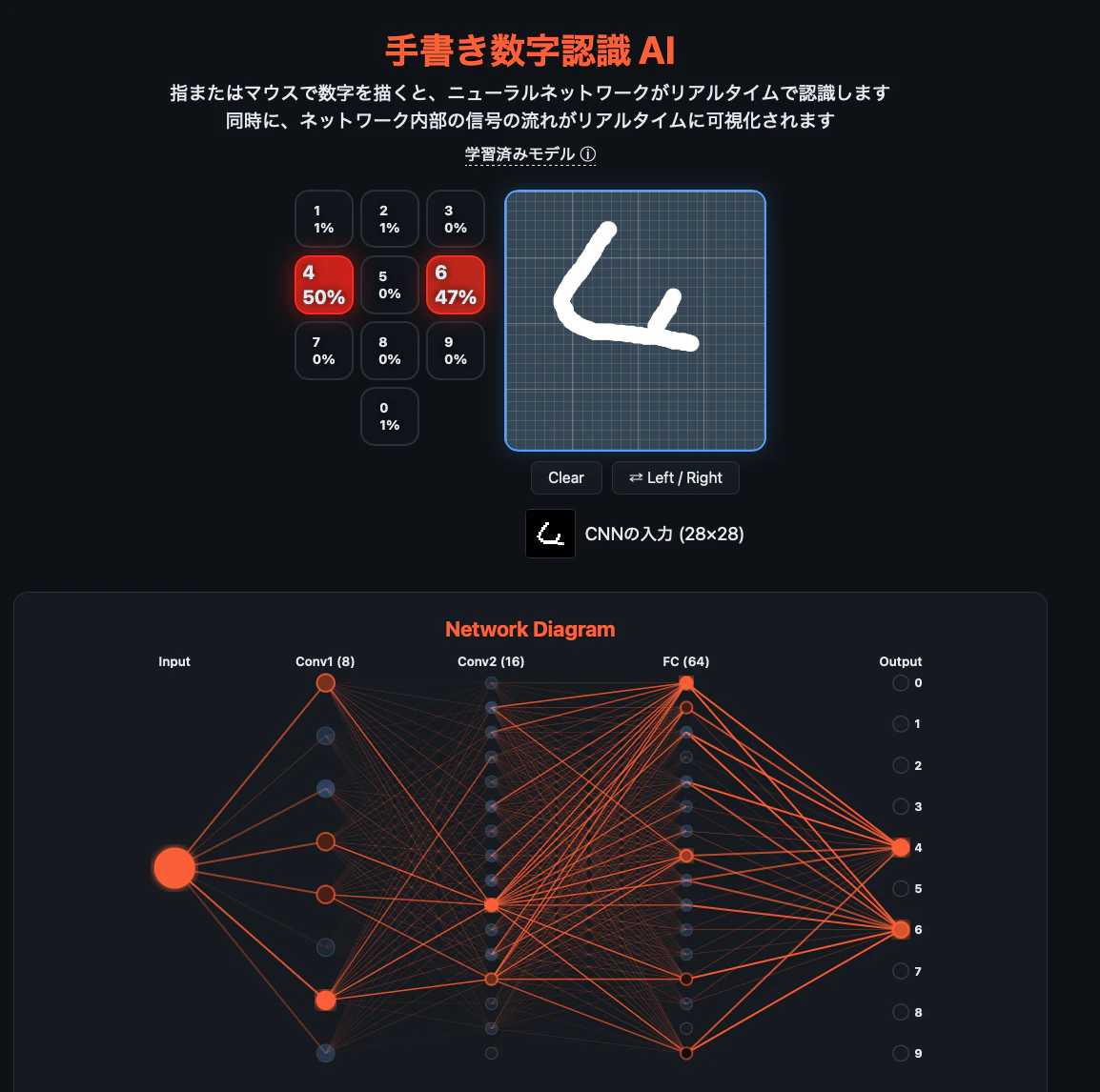
ダイヤル型ヒートマップ — スマホのダイヤルのように0〜9を並べ、確信度が色の濃さでリアルタイムに変化します。描いている途中で「今は8に見えてる」「あ、3に変わった」という判断の揺れが見えます。
-
ネットワーク図 — Input → Conv1 → Conv2 → FC → Output のノードとリンクが、信号の強さに応じてオレンジに光ります。どの経路を通って答えに辿り着いたかが一目でわかります。
-
CNNの入力プレビュー — あなたが描いた文字が28×28ピクセルにどう縮小されるかを表示。「ネットワークにはこう見えている」がわかります。
エミュレーションではなく本物
これはシミュレーションや再現ではありません。27,690個のパラメータを持つ本物のCNNがブラウザ上で動いています。描くたびに実際に畳み込み、ReLU、プーリング、全結合の演算が走り、その途中の値をそのまま可視化しています。
なぜ作ったか
前作の Transformer Emulator では、Transformerの内部動作を可視化しました。ただし、あちらは事前に計算した結果を再生する「眺める」体験でした。
今回は**「触れる」体験**にしたかった。自分で数字を描いて、その瞬間にネットワークが反応する。描いている途中で確率が揺れ動く。「3を描いてるつもりなのに途中まで8に見える」という体験は、教科書では得られません。
描画中に起きていること
数字を描いている間、pointermoveイベントのたびに以下が実行されます:
- Canvas → 28×28に縮小 — 描画内容のバウンディングボックスを検出し、重心で中央揃え。MNISTと同じ前処理です。
- CNN推論(JavaScript) — 畳み込み → ReLU → MaxPool → 畳み込み → ReLU → MaxPool → 全結合 → Softmax。純粋な行列演算をJavaScriptで実行。
- 可視化更新 — 各層の中間出力(活性化)を取得し、ダイヤルの色とネットワーク図のノード・リンクの輝度に反映。
28×28の入力に対するこのサイズのCNNなら、推論は数ミリ秒で完了するため、描画のフレームレートを落とさずリアルタイムに可視化できます。
使ってみて気付いたこと
1. CNNは「迷う」
「3」を描く過程で、確率の推移を見ると:
| 描画段階 | 予測 |
|---|---|
| 縦線を引いた | 1: 30%, 7: 25% |
| 上の丸を閉じた | 8: 55%, 9: 20% |
| 下を開けた | 3: 60%, 8: 22% |
| 描き終わり | 3: 92% |
途中経過は確かに8に見える。CNNの「迷い」は人間の直感と一致していて、合理的に判断していることがわかります。
2. 前処理が精度を左右する
最初のバージョンでは「4」を描くと「7」と判定されました。原因は前処理の欠如でした。MNISTのデータは重心で中央揃えされているのに、単純にCanvasを28×28に縮小しただけだったのです。MNIST準拠の前処理(バウンディングボックス検出 → 中央揃え → 20×20領域に収める)を入れたところ、正しく認識されるようになりました。
3. 27,690パラメータで98%
GPT-4が約1.8兆パラメータと言われる中、このCNNはその6,500万分の1のサイズです。それでもテスト精度98.04%。「適切な構造(畳み込み)を選べば、少ないパラメータで高い精度が出せる」というCNNの本質が体感できます。
技術構成
| 要素 | 技術 | 理由 |
|---|---|---|
| 学習 | Python / 純NumPy | PyTorch等を使わず、backpropagation含め全て自前実装。教育目的 |
| 推論 | Vanilla JavaScript | ブラウザだけで完結させるため。外部ライブラリ不使用 |
| 可視化 | SVG + Canvas + CSS | ネットワーク図はSVG、描画とプレビューはCanvas |
| 出力 | 単一HTMLファイル(約620KB) | 学習済み重みをJSONとして埋め込み。配布が容易 |
モデル構成
Conv(5x5, 8ch) → ReLU → MaxPool(2) # 画像から8種類の特徴を検出
Conv(3x3, 16ch) → ReLU → MaxPool(2) # 特徴を組み合わせて16種類の高次特徴へ
Flatten(400) → FC(64) → ReLU # 全特徴を総合して判断
FC(10) → Softmax # 0〜9の確率を出力
ネットワーク図の実装
SVGで各層のノードを配置し、層間のリンクを<line>要素で描画しています。推論時に各ノードの活性化値を取得し、リンクのstroke-opacityとノードのfillを更新することで、信号の流れを可視化しています。
リンク数は全体で552本ですが、大半はopacity: 0に近いため、視覚的には活性の高い経路だけが浮かび上がります。
多言語対応
タイトル横の切替ボタンで日本語/英語を切り替えられます。ブラウザの言語設定で初期言語を自動判定し、URLパラメータ(?lang=en)でも指定可能です。
テキスト要素が少ないため、JS内に言語辞書を持ち、ボタンクリックで全テキストを書き換える方式を採用しました。描画中でも推論中でも、いつでも瞬時に切り替わります。
実行方法
デモを試す
https://tomoiura.github.io/digit_recognizer/
ブラウザで開くだけで動きます。
ソースから再生成する場合
git clone https://github.com/Tomoiura/digit_recognizer.git
cd digit_recognizer
pip install numpy
python main.py
初回はMNISTデータのダウンロード + 学習(数分)が実行されます。2回目以降はキャッシュされた重みを使うため数秒で完了します。
おわりに
前作の Transformer Emulator が「AIの学習過程を眺める」ツールだったのに対し、今回は「自分の手で描いて、AIの反応をリアルタイムで感じる」ツールになりました。
「ニューラルネットワークは何をしているのか」という問いに対して、数式や図解ではなく、触って、見て、感じることで答えを得られる。そういう体験を目指しました。
技術的な誤りや改善点があれば、GitHub の Issue や Pull Request を歓迎します。