Transformerの学習・推論過程をブラウザ上でアニメーション付きで観察できるツールを作った
ブラウザで試せます(インストール不要)
https://tomoiura.github.io/transformer-emulator/
GitHub
https://github.com/Tomoiura/transformer-emulator
これは何か
Transformer の学習過程と推論過程を、ブラウザ上でアニメーション付きで段階的に観察できるインタラクティブなツールです。
小規模な Transformer Decoder モデル(約14,000パラメータ、GPT-2 の約1万分の1)を対象に、学習中の内部状態の変化や、推論時にレイヤーを通じて表現がどう変換されていくかを可視化しています。
Transformer の基本的な構成要素(Attention、Embedding、FFN など)を一通り学んだ方を主な対象としています。「概念は分かったけど、中で何が起きているのか実感がない」という段階の方に特に向いていると思います。
なぜ作ったか
数式、概念図、実装コード――Transformer を理解するための説明材料はいろいろあります。
ただ、それらを読んでも、学習や推論の途中で内部表現がどう変わっていくのかは、なかなか実感を持って理解できませんでした。
例えば次のような疑問です。
- 学習が進むと何が変化するのか
- 推論時に各レイヤーがどのように表現を変換しているのか
- Attention がどのように振る舞うのか
- Embedding / Positional Encoding / FFN / 出力確率がどうつながるのか
もともとは自分自身のために、内部の変化を可視化しながら理解したいという動機から作り始めました。その後、教育用の副教材としても活用できるよう構成を整理しています。
可視化している内容
学習タブと推論タブの2つの画面で内部状態を可視化しています。
学習タブ
モデルがランダムな状態から徐々に予測可能な状態へ近づいていく過程を追えます。
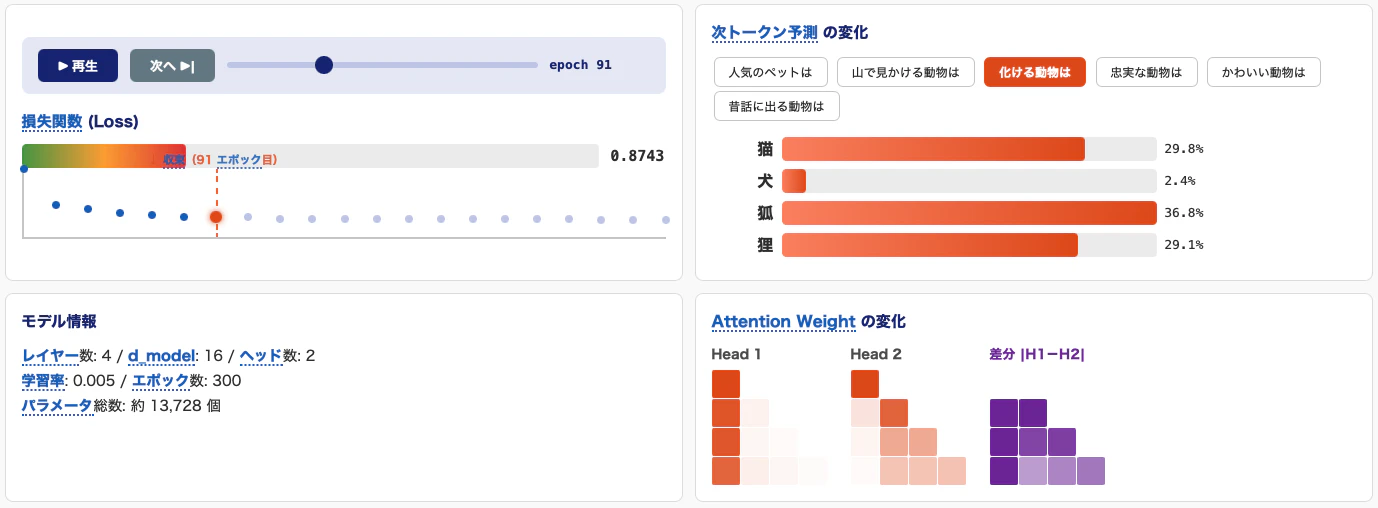
- Loss curve ― 予測のズレが、学習とともにどのように小さくなっていくかを確認できます。
- Attention Weights ― 次の予測をするときに、各トークンが文脈のどこを手がかりにしているかを観察できます。
- Head 間の差分 ― 複数ヘッドの注意分布を比較することで、文脈を複数の見方で捉えている様子を観察できます。
- 任意エポックの確認 ― スライダーにより、学習途中の任意の段階を観察できます。
最終結果だけでなく、**「途中で何が起きているか」**を見せることを重視しています。
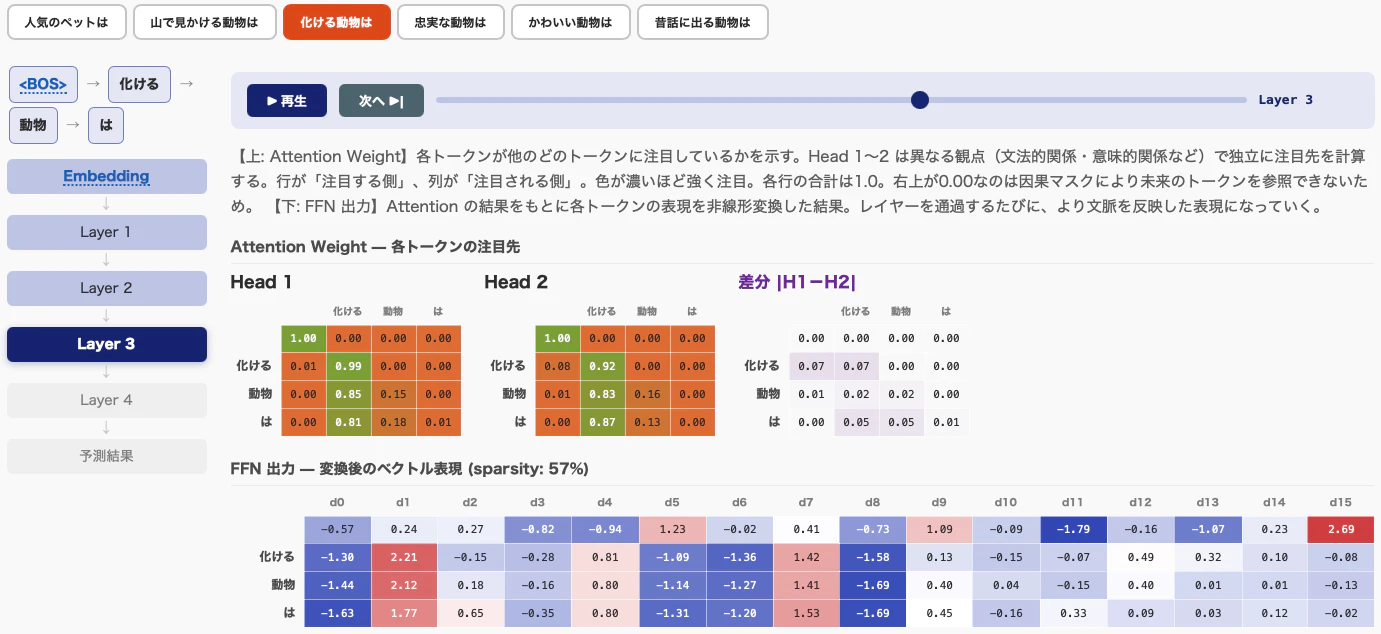
推論タブ
入力されたトークン列が Embedding → Attention → FFN → 出力確率 という流れの中で段階的に変換されていく様子を観察できます。
- Token Embedding / Positional Encoding / Combined ― トークンそのものの表現に、位置情報がどのように加わるかを確認できます。
- 各レイヤーの Attention 出力 ― どのトークンを手がかりにしているかを観察できます。
- 各レイヤーの FFN 出力 ― Attention で集めた情報が、各レイヤー内でどのように加工されるかを確認できます。
- 出力確率と次トークン予測 ― 最終的にどの候補が高く評価され、どのトークンが選ばれるかを見られます。
- Greedy / Sampling / Temperature の違い ― 次トークンの選び方を変えると、出力の振る舞いがどう変わるかを比較できます。
モデル構成
教育・学習目的に特化した小規模モデルです。
- 4層、16次元の表現空間、約14,000パラメータ(GPT-2 の約1万分の1)
- 小さなデータセットで学習
そのため、実際の LLM と同等の言語能力を示すものではありません。内部処理を追いやすくすることを優先した構成です。
使ってみて気付いたこと
実際にこのツールで観察してみて、いくつか直感的に理解できたことがあります。
レイヤーを重ねるほどヒートマップが整列していく
Layer 2

Layer 4

推論ページで Layer 1 から Layer 4 まで進めると、ヒートマップが次第に整っていく様子が見えてきます。
ばらばらだった単語の集まりが、次トークン予測に使える文脈表現へと段階的に加工されていることを示しているように見えます。「レイヤーを重ねて表現を洗練する」とよく言われますが、その変化を視覚的に追えるようになりました。
Multi-Head Attention の役割分担が見える
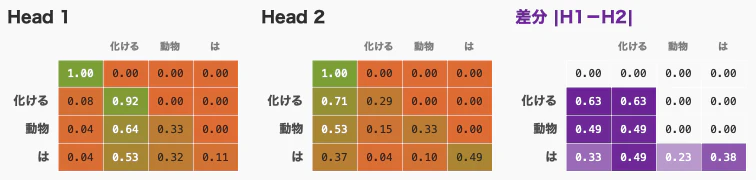
Head 1 と Head 2 の Attention Weight の差分を見ると、同じ入力に対しても異なる注目パターンが現れています。
差分が濃い部分は、複数の Head が異なる注目パターンを持っていることを示しており、Multi-Head Attention が単なる冗長化ではなく、役割分担を持ちうることを直感的に捉えやすくしています。
各次元に単純な意味を与えにくい
d0〜d15 の各次元を見ていると、個々の値に意味を読み取りたくなりますが、学習前はランダムであり、学習を通じて意味は複数次元の組み合わせとして現れます。
特定の1次元だけを見て解釈するよりも、ベクトル全体やレイヤーを通じた変化として捉える方が自然だと感じました。
技術的な工夫
NumPy のみで Transformer を実装
PyTorch や TensorFlow を使わず、NumPy だけで Transformer Decoder を実装しています。Embedding、Multi-Head Attention、FFN、Softmax、Cross Entropy Loss、逆伝播まですべて手書きです。
フレームワークのブラックボックスを排除することで、学習・推論の各ステップで何が計算されているかを完全に制御・記録できるようにしています。
全エポックの内部状態を JSON に記録
学習中の各エポックで、Attention Weight、Loss、各レイヤーの中間表現などをすべて JSON に書き出しています。この JSON を HTML 側で読み込み、スライダーで任意のエポックを再生できる仕組みです。
推論時も同様に、レイヤーごとの中間表現をすべて記録して可視化に使っています。
単一 HTML ファイルで完結
main.py を実行すると、学習・推論の結果をすべて埋め込んだ単一の result.html を生成します。サーバーが不要で、ファイルを開くだけで動くため、配布や共有が簡単です。
学習データのカスタマイズ
学習データや質問内容は JSON で定義しています。デフォルトの「動物に関する質問と回答」から自由に入れ替えることで、独自のテーマでも同じ構成で可視化できます。
たとえば、料理、都市、プログラミング言語、歴史上の人物など。授業や勉強会で使う場合にも、説明したいテーマに合わせてデータを差し替えられます。
補助機能
- 用語解説のマウスオーバー ― 画面内の専門用語にはすべて解説を付けており、その場で意味を確認できます。Transformer の説明では用語が次々に出てくるため、都度確認できることを重視しました。
- 表示内容のコピー ― 画面上の説明や一部の表示内容はコピー可能です。メモへの貼り付けや、勉強会での再利用を想定しています。
- 用語集タブ ― 可視化画面とは別に、関連用語をまとめて参照できるタブを用意しています。用語集も JSON で定義しているため、カスタマイズ可能です。
実行方法
ローカルで生成したい場合は以下で試せます。Python 3.9 以上を推奨します。
git clone https://github.com/Tomoiura/transformer-emulator.git
cd transformer-emulator
pip install -r requirements.txt
python main.py
実行後、output/result.html が生成され、ブラウザで閲覧できます。
おわりに
Transformer は現代 AI の中核技術ですが、その内部は抽象的で、初学者にとって理解しづらい対象でもあります。
本ツールは、学習過程と推論過程を一つの連続した流れとして観察できるようにすることを意識して作成しました。内容や利用に対して改善提案などあれば、ぜひコメントや Issue でフィードバックをいただけると嬉しいです。