PythonでOCR(Optical Character Recognition)をやってみる!!😜
おはようございます。Tomixです。今日PythonのOCRハンズオンをやった時につまづいたところをまとめようと思います。Macでしたので、Windowsの方は対応できるかわかりませんが、一応まとめさせていただきます。
OCRとは!??
OCRとはOptical Character Recognitionの略で、何ができるかというと、画像から文字起こしができるってやつです。Google翻訳などでカメラで写真撮ったら翻訳される、みたいなことができるやつですよね。すごそう。ワクワク😋
ではやっていきましょう!!!
参考にした記事📕
今回私はAnacondaを使いませんでした。Anacondaが怖いからです。なんか環境ぐちゃぐちゃになりそうだったからやめときました。@anzanshiさんはAnacondaありの記事を書かれているので、私はAnacondaなしでやってみた記事を出しますね笑
この記事をする上で前もって必要なもの🐶
- Pythonのインストール
- Homebrewのインストール
- pip3を使える環境
くらいですかね
Python3のインストール
Homebrewのインストール(途中でXcodeもダウンロードします)
今回やっていく中でinstallするもの
- tesseract
- pyocr
の2点です!!
1.まずはpyocrのインストール
ターミナル.appを開きます。

pip3 install pyocr
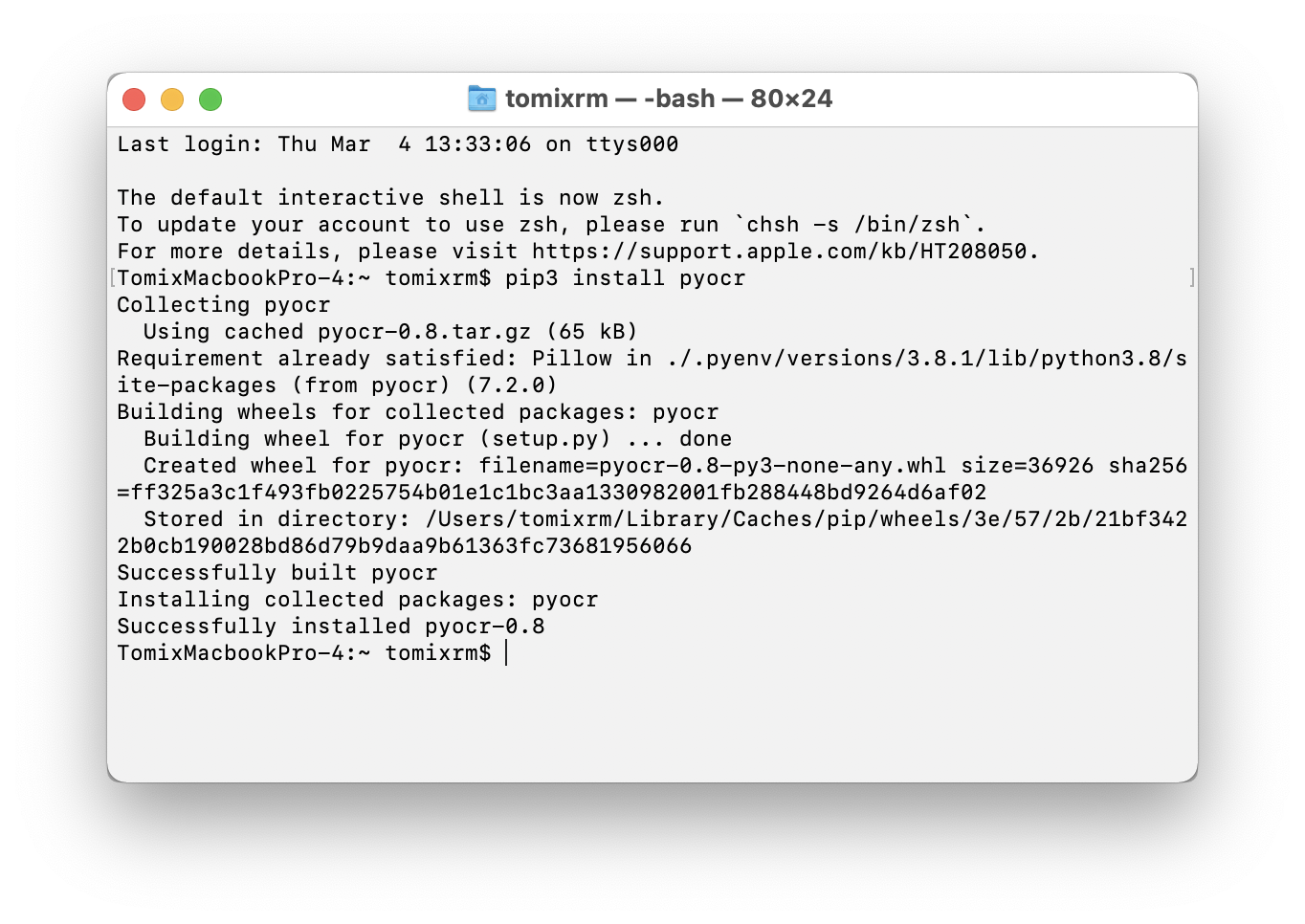
と入力してreturnキー(Enterキー)を押します。するとpip経由でインストールされるはずです。
2.tesseractのインストール

tesseractのインストールはpipを使いません。一応pipでもできるっぽいですが、pipでゲットできる最新バージョンが0.1.3だったので1にすらなっていないしやばそうだということでやめましょう。
Homebrewでインストールすると私の場合4.1.1がゲットできました。今回はHomebrewを使います。
Homebrewを使う時にXcodeが必要なので、容量をかなり食うと思います。(とはいえ大体のエンジニアであればMacにXcodeくらいは入っていると思うし、入れておいてもいいと思います。あと単純にbrewが便利なので入れておいて損はないと思います。)
ちなみにAnacondaでインストールするときはconda-forgeという団体が有志で提供してくれているライブラリを使うことができるので、色々いいことあるそうです...が私は今回Anacondaに逆らっていくのでなしで😜
brew install tesseract
と入力し、returnキー(Enterキー)します。
これでTesseractが入ったと思います。途中で(y/n)とか出てきたら、書いてる文章を読んで、yesかnoかをyかnで入力してreturnキーしましょう。
3.では実際に使ってみる!!
動作確認も兼ねてやってみましょう。OCRに挑戦です!💪🔥
こちらの記事を参考にさせていただきました。
https://qiita.com/it__ssei/items/fd804dcb10997566593b
今回私はJupyter Labでテストしてみました。入力して[Shit+return]ですぐに答えが反映されてテストする時に使いやすいのでおすすめです。一行づつテストするのには向いていると思います。
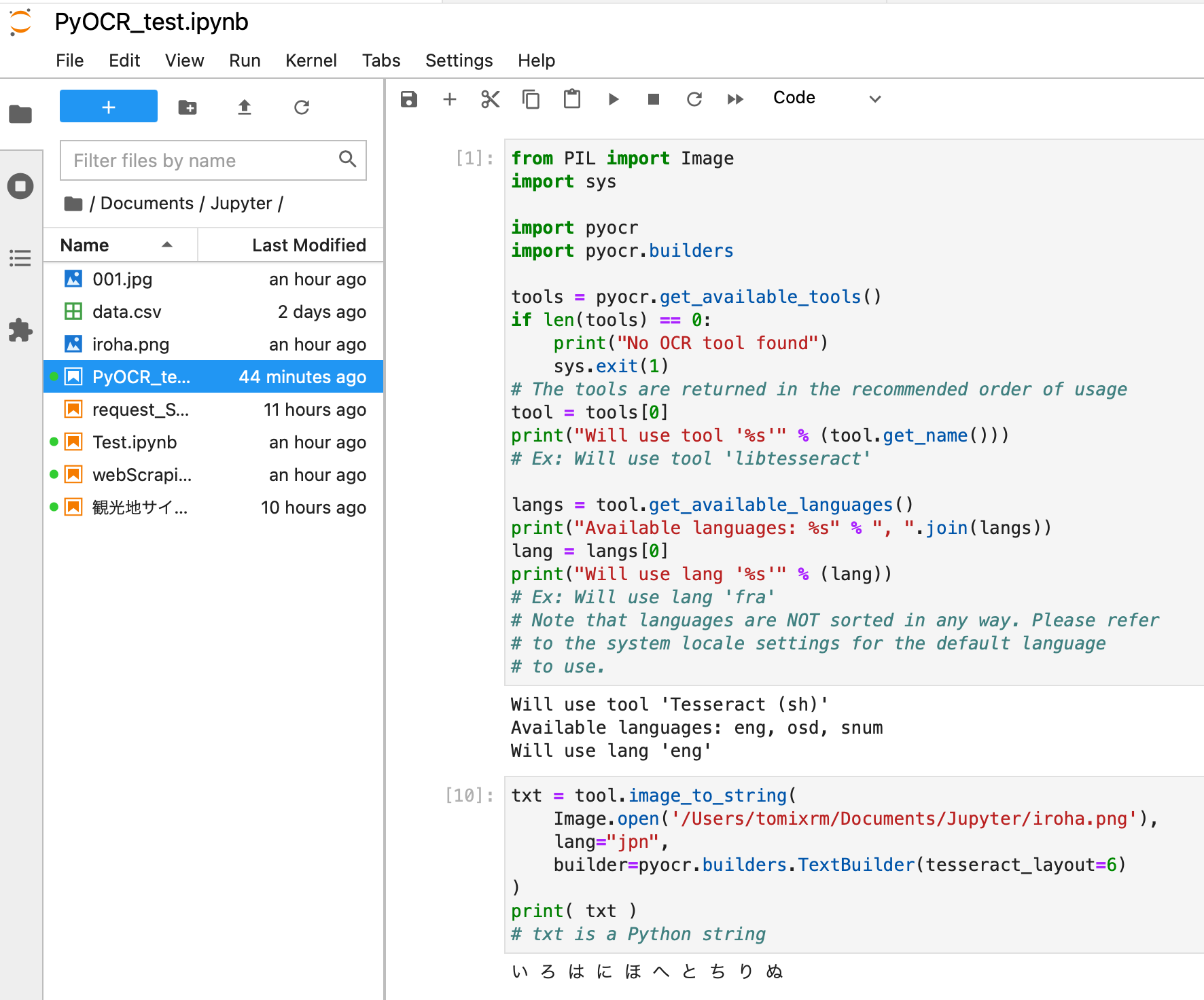
Jupyter Labで試してみたい方はこちらの記事が参考になると思います。
from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
Will use tool 'Tesseract (sh)'
Available languages: eng, osd, snum
Will use lang 'eng'
Available languagesにjpn(日本語)がないですねぇ...日本語使えないじゃん。つらぴ
日本語を使いたいので、あとで日本語対応させていきます!!とりあえずはOCRを体験してみましょう!!
文字認識(OCR)をやってみる!
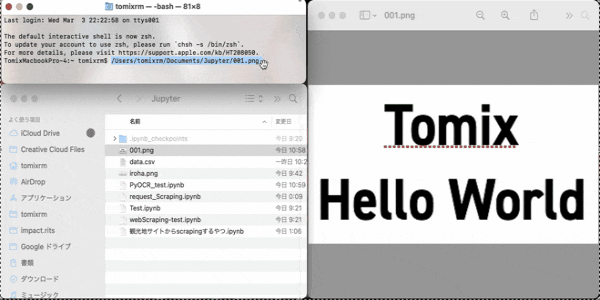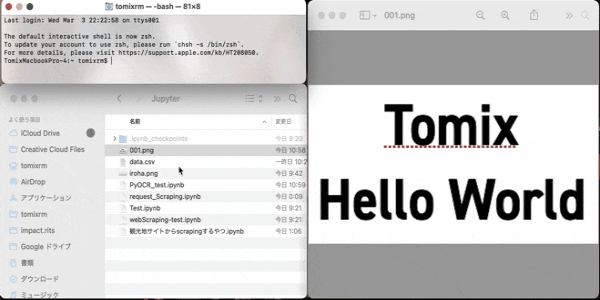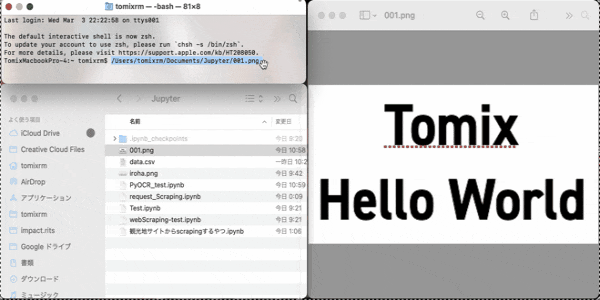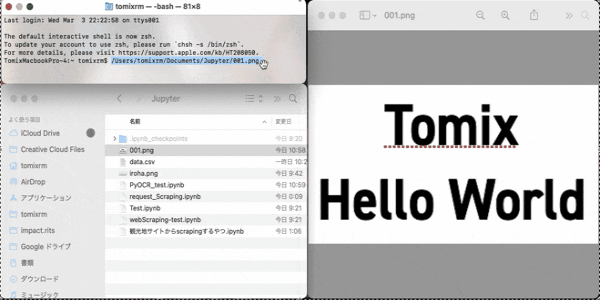
こちらの画像をダウンロードしてください。名前を001.pngにしておきましょう。
これが読み取る画像になります。テストしきましょー

先程のコードに続けて、
txt = tool.image_to_string(
Image.open('/Users/tomixrm/Documents/Jupyter/001.png'),
lang="eng",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print( txt )
# txt is a Python string
を入力して実行します。
↓画像ファイルの場所は人によって違うので、各自設定してください。
/Users/tomixrm/Documents/Jupyter/001.pngは保存した画像のディレクトリ(保存場所)です。
これを正しく記述するには、対象の画像ファイルをターミナル.appにドラッグアンドドロップしたら、ディレクトリが出てくると思います。コピーしてImage.open("ここにペースト")しましょう。
Image.open(画像ファイル),
**lang="eng"**は言語を英語にしています。日本語でやっていきたい場合は"eng"を"jpn"にしたらできると思います。でも私の環境では日本語が対応できていなかったので、日本語対応させていきましょう。
4.日本語対応させる!!
ここからてこずったところです
Tesseract を日本語対応させるときにやること
やることは/usr/local/Cellar/tesseract/4.1.1/share/tessdata を開いて
Githubからjpn.traineddataをダウンロードしてきて、/usr/local/Cellar/tesseract/4.1.1/share/tessdataの中に入れるだけて感じです。
ややこしいと思うので、下記で説明していきます。
1.コマンドライン(ターミナル)でtesseractのフォルダに移動する
コマンドラインを使います。下記を入力します。
コマンドラインわからない人はProgateのこの講座がおすすめです。
https://prog-8.com/languages/commandline
cd
ls /usr/local/Cellar/tesseract
と入力してみます。そうすると、4.1.1とか4.1.0とかのフォルダ名が出てくるはずです。この4.1.1とかの番号を使いますのでメモしてください。
先程の4.1.1などの数値(フォルダ名)を使って以下のようにします。(4.1.1は可変です)
cd
cd /usr/local/Cellar/tesseract/
open 4.1.1
をします。そしたらフォルダが開くはずです。
そしたらこういう感じのフォルダが見えると思います。
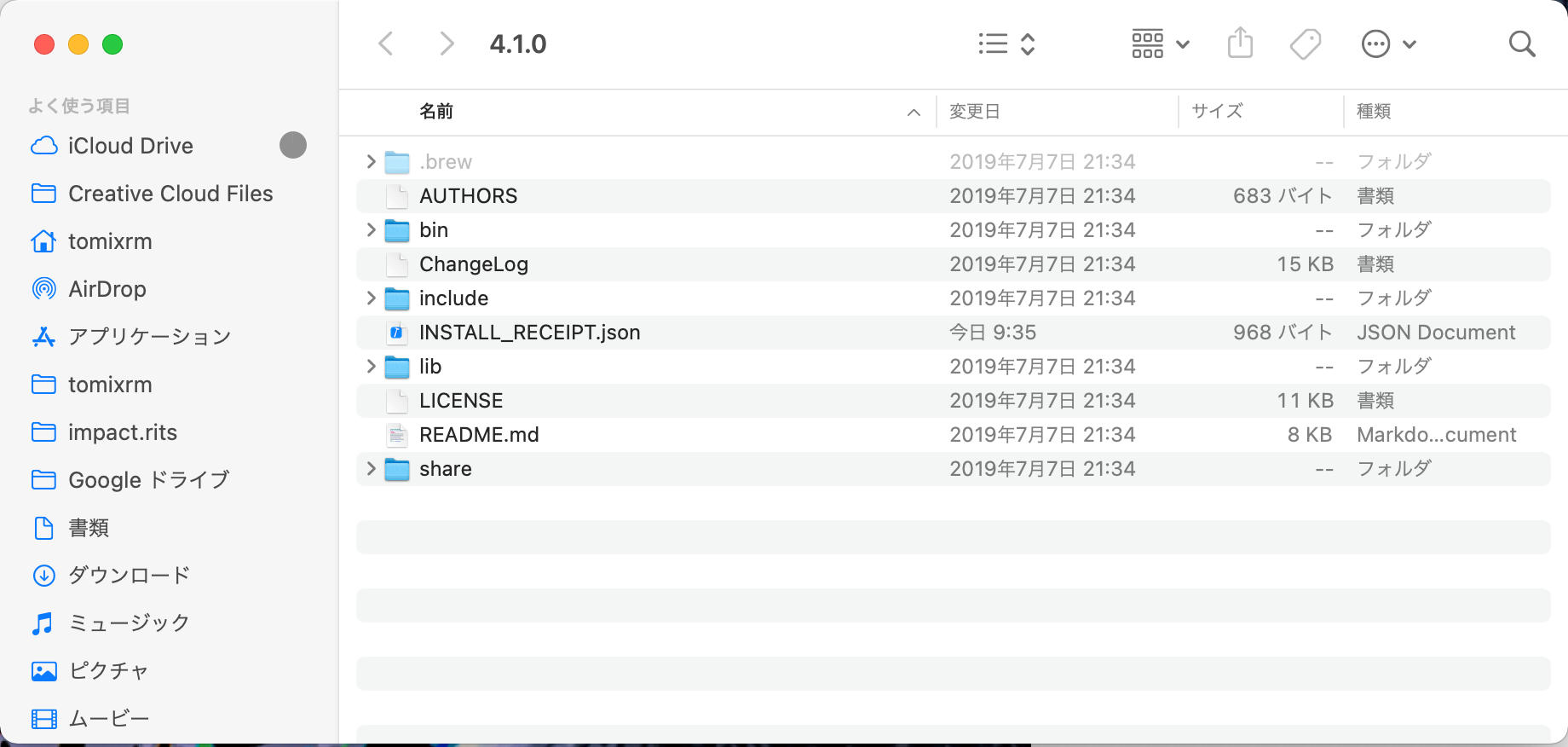
そのあとshare/tessdataを開きます。(shareの中のtessdataフォルダを開く)
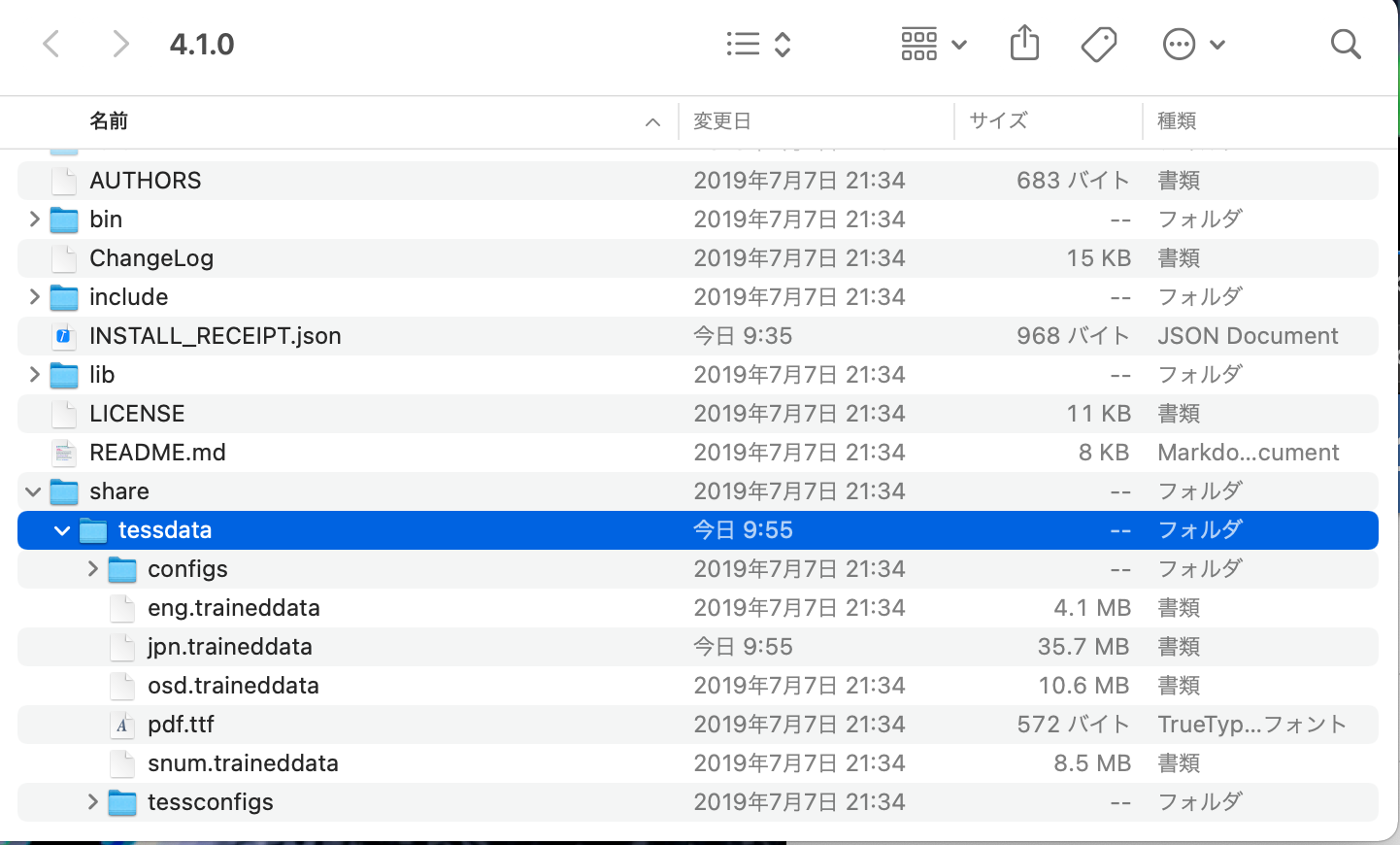
開いたらとりあえずここまでは成功です!!
次は日本語バージョンのtessdataをダウンロードしていきます。
日本語対応化ファイルをダウンロードする
Githubからダウンロードしてきます。Cloneでもいいんですけど、あんまりコマンド使うとかわいそうな気がするので、最小限にしときますね。
1. ここからjpn.traineddataをダウンロードしてください。
ダウンロードしたjpn.traineddataを4.1.1の中のshareの中のtessdataに入れましょう。
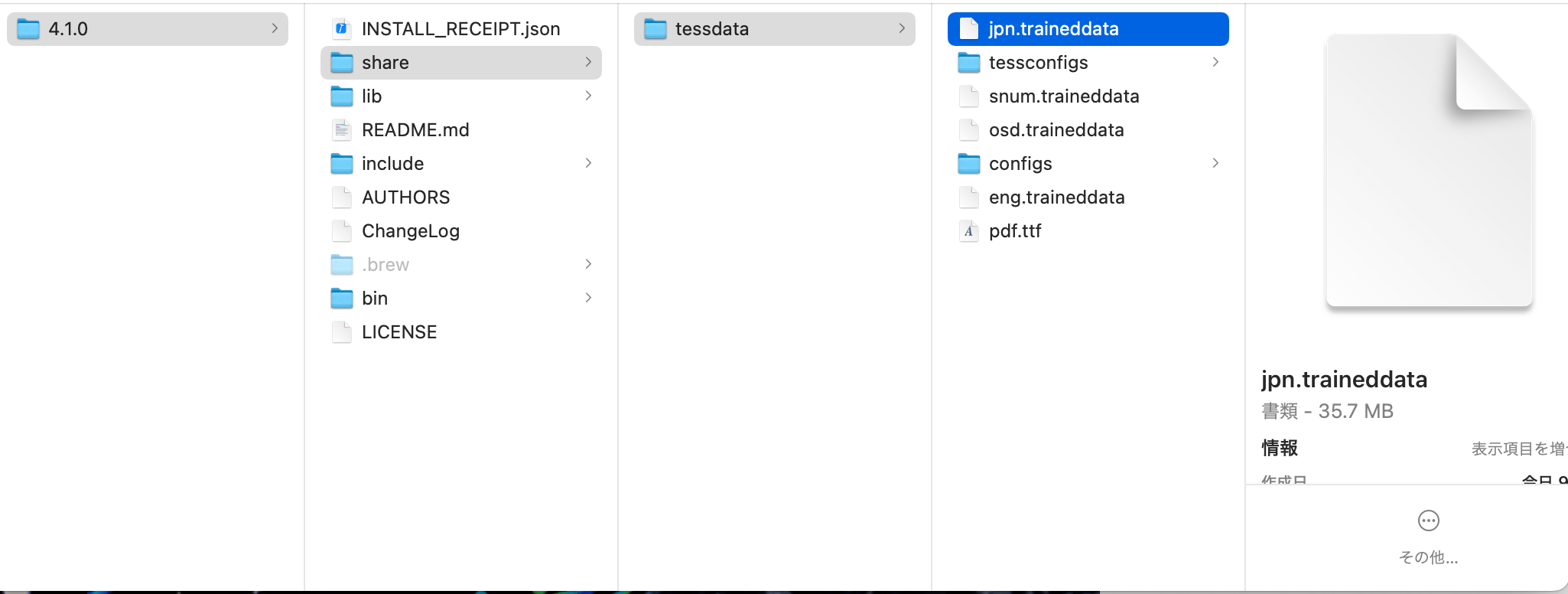
こういう感じのファイル構造になっていると思われます。
これで対応されたはずです!!
日本語対応を試してみる!!
先程のコードをちょっといじって日本語をOCRしてみましょう。
まずはこの画像をダウンロードして001.pngと名前をつけて保存しましょう。

先程と同じディレクトリに画像を置いて、置き換えます。
from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
txt = tool.image_to_string(
Image.open('/Users/tomixrm/Documents/Jupyter/001.png'),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print( txt )
# txt is a Python string
これ↑がコードになります。
↓変えるべきのところ
Image.open('画像ファイル'),
lang="jpn", #言語
上記のコードを実行した結果がこちら。
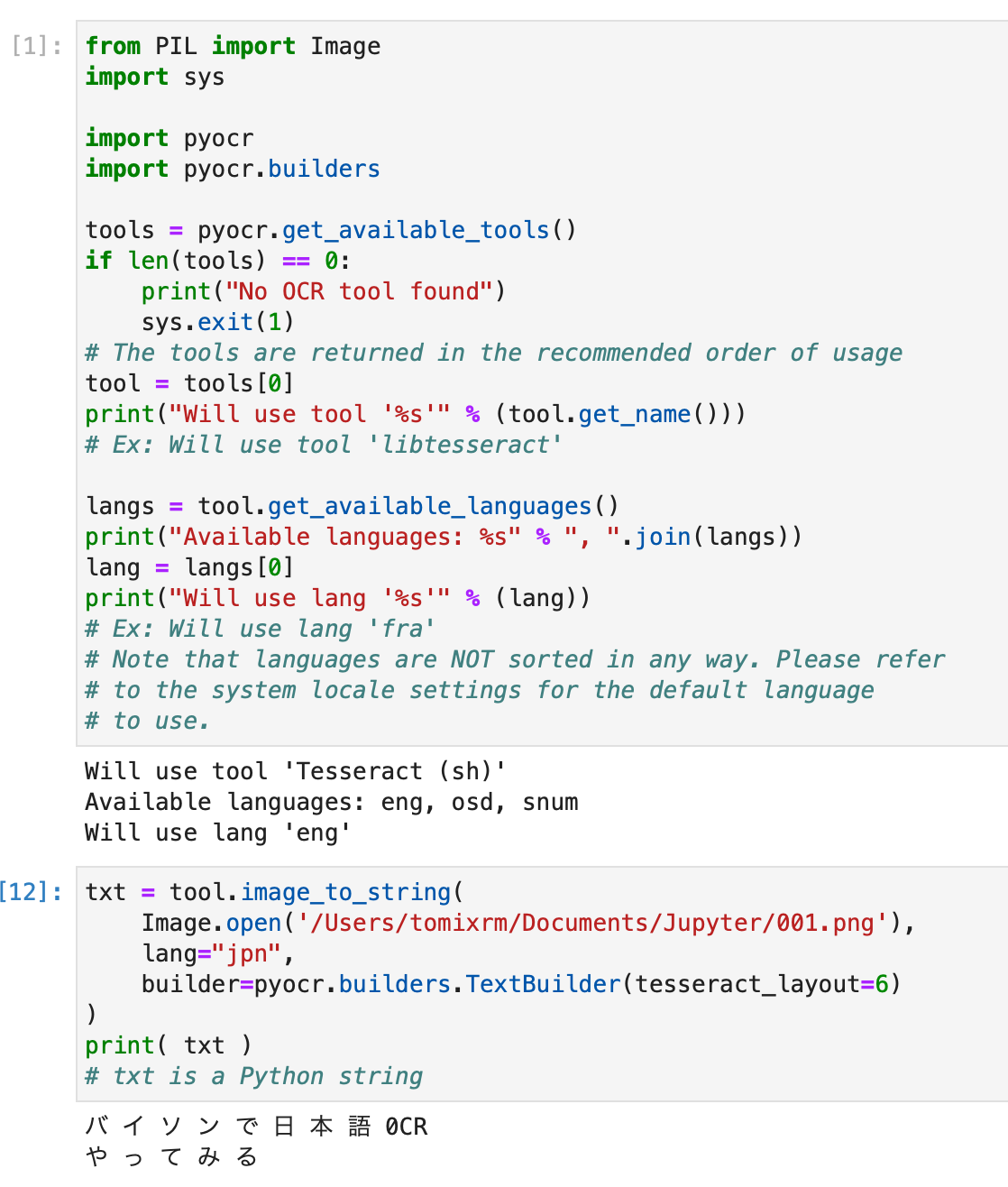
バ イ ソ ン で 日 本 語 0CR
や っ て み る
...そっすか。バイソンは違うだろ...パイソンがバイソンになりました。文字色を黒じゃなくしたところがまずかったのかな???あと文字にスペースが入っていますね。よくないです。あとOと0が勘違いされていますね。あららーーーーー残念だ。
番外編 スペース問題を解決する
そういう時は文字列処理でスペースを消せばいいので、先程のコードに追加で
txt = txt.replace(' ','')
txt = txt.replace('\n','')
print(txt)
とすれば、
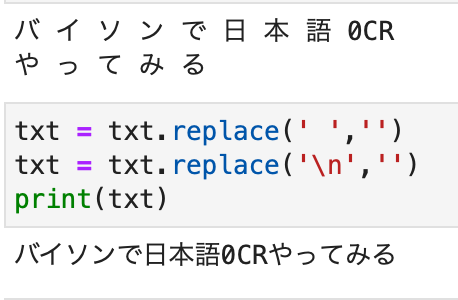
バイソンで日本語0CRやってみるが出ました!!!
終わりに
pipとbrewでインストールして、pythonでOCRをやってみました。
Oと0が間違えられたり、パとバを間違えたりなど、機械も信頼できたものではないですねw
以上です。お疲れ様でした。
参考