はじめに
今回は、私たちがチーム開発をするにあたって少しだけ困っていたことを、少しだけ自動化した話を共有いたします。
内容
本記事では、次の流れで紹介します。
- なぜコーディングサーバーを採用したのか
- コーディングサーバー運用で顕在化した課題
- CloudWatch、Lambda、Teams を使った自動復旧の構成
- AWS CDK による IaC デプロイと Go 実装の要点
- この取り組みから得られた学び
私たちの開発環境
私たちのチームでは 業務用PCとしてWindowsのPCでWeb システムを開発しています。
ただ、日々の開発では次のような課題がありました。
- 社内ネットワークへ接続するための Proxy 設定が必要
- 新しいメンバーの参加時や、利用言語・ミドルウェアが増えたときに Proxy 設定の追加対応が毎回発生する
- 端末スペック差により、ビルドや依存解決の待ち時間に差が出る
このあたりを個々の端末で吸収し続けるのは非効率だったため、開発環境の共通化を目的としてEC2でコーディングサーバーを導入しました。
コーディングサーバー運用で見えてきた課題
一方で、コーディングサーバーを運用し始めると別の課題が見えてきました。
CPU 使用率が高くなると VS Code から EC2 へ接続しづらくなり、利用者から見ると「自分のネットワークが悪いのか」「サーバーが重いのか」がすぐに判別できません。
また、CPU 高負荷が原因と分かったあとも、CloudWatch を見に行って、必要なら手動でEC2を再起動する運用になっていました。
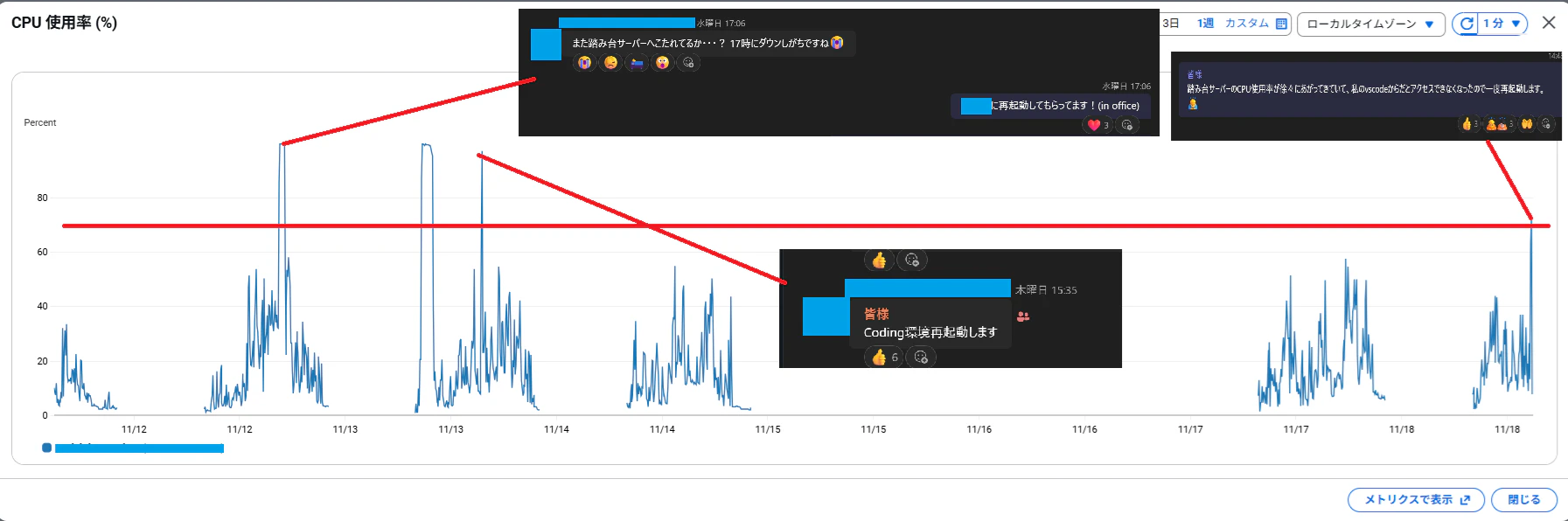
1日に1~2回程度CPU使用率が頭打ちになり、EC2の手動再起動と再起動したことをチャットする運用になっていました。
この記事で扱うこと
そこで今回は、CloudWatch で CPU 高負荷を検知し、Lambda で EC2 を自動再起動しつつ、Teams へ通知する仕組みを作りました。
インフラは AWS CDK でコード化し、通知アプリは Go で実装しています。
この記事では、コーディングサーバー採用の背景から、暫定対策として自動復旧基盤をどう組んだかまでをまとめます。
扱わないこと
TeamsでWebhookを作る方法
観測された事象
コーディングサーバー方式で実際に困ったのは、主に次の 3 点です。
- CPU 使用率が高くなると VS Code から EC2 に接続できなくなることがある
- 接続できない理由がローカルネットワークなのか、EC2 の高負荷なのかを判断するために CloudWatch を見に行く必要がある
- CPU 高負荷と分かった場合でも、最終的に EC2 を手動で再起動する必要がある
本来は「なぜ高負荷になりやすいのか」を根本から詰めるべきですし、実際に原因特定も進めていました。ただ、調査時点では明確な根本原因まで到達できなかったため、まずは暫定対策として MTTR を下げる仕組みを整えることにしました。
各システムの役割
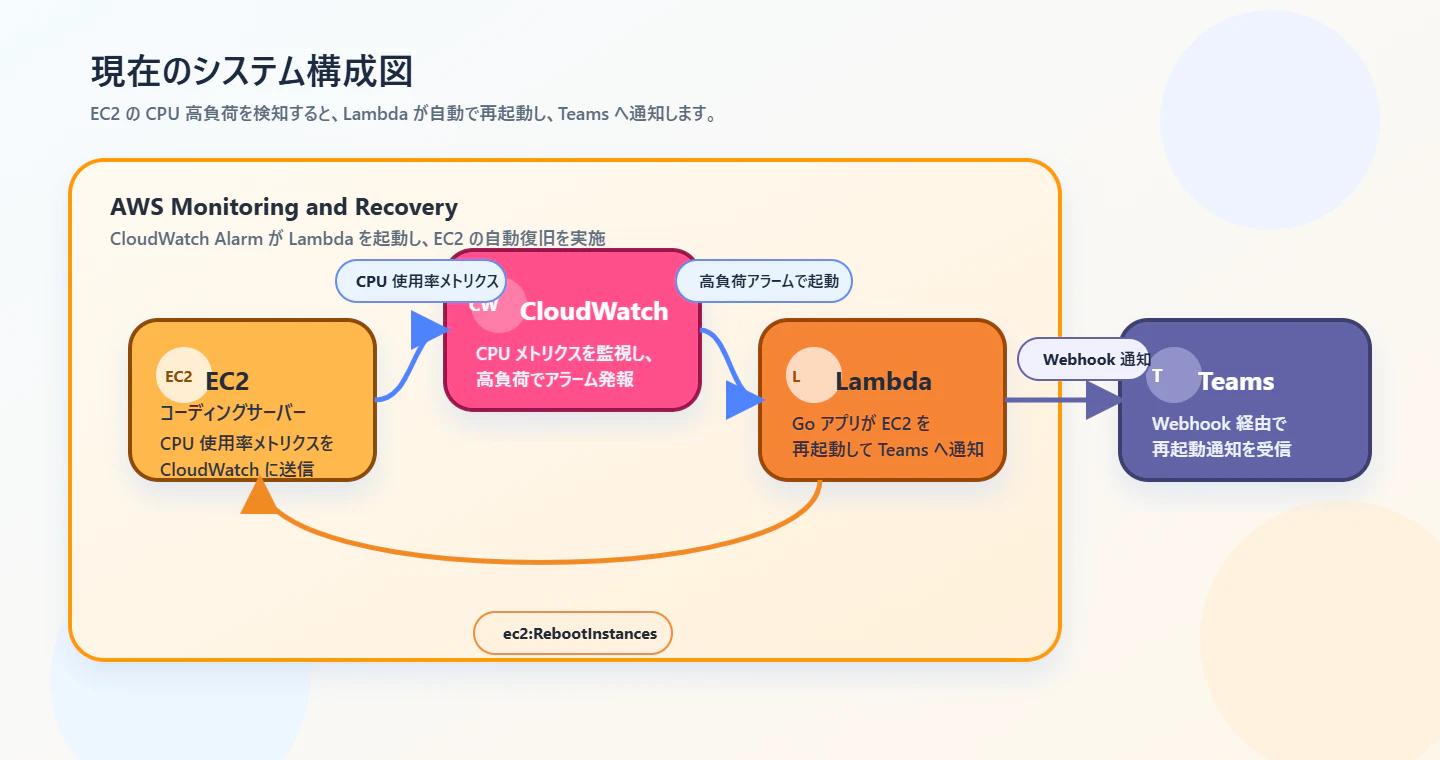
各サービスの役割は下記になります。
- CloudWatch: EC2 の CPU 使用率メトリクスを監視し、しきい値超過時にアラームを発報します
- Lambda: CloudWatch アラームをトリガーに起動し、対象 EC2 の再起動と Teams 通知を実行します
- Teams への投稿: 利用者や運用担当が「EC2 が高負荷で自動再起動された」ことをすぐに把握できるようにします
- AWS CDK: Lambda、IAM 権限、CloudWatch アラームからの呼び出し許可といったインフラ構成をコードで管理し、再現可能な状態でデプロイします
自動復旧と通知のシーケンス
今回の自動化シーケンスは、次のような流れです。
- CloudWatch が EC2 の CPU 高負荷を検知する
- アラームから Lambda を直接起動する
- Lambda が EC2 の Reboot API を実行する
- 同じ Lambda が Teams に通知を送る
IaC 側では、CloudWatch Alarm から Lambda 呼び出しまでを CDK で管理するなら、例えば次のように書けます。対象 EC2 の CPU 使用率が 90% を超えたら Lambda を呼び出すイメージです。
// 1. Go で実装した再起動用 Lambda をデプロイする
const rebootLambda = new lambda.Function(this, "RebootEc2LambdaFunction", {
runtime: lambda.Runtime.PROVIDED_AL2,
handler: "bootstrap",
code: lambda.Code.fromAsset(path.join(__dirname, "../lambda"), {
bundling: {
// Lambda のカスタムランタイム向けに Go バイナリをビルドする
image: lambda.Runtime.PROVIDED_AL2.bundlingImage,
command: [
"bash",
"-c",
"GOOS=linux GOARCH=amd64 go build -o /asset-output/bootstrap main.go",
],
user: "root",
},
}),
timeout: cdk.Duration.seconds(30),
});
// 2. 対象 EC2 の CPU 使用率が 90% を超えたら ALARM にする
const cpuAlarm = new cloudwatch.CfnAlarm(this, "CodingServerCpuAlarm", {
alarmName: `${instanceId}-cpu-utilization-high`,
alarmDescription: "Notify Lambda when EC2 CPU utilization is over 90%",
namespace: "AWS/EC2",
metricName: "CPUUtilization",
dimensions: [
{
name: "InstanceId",
value: instanceId,
},
],
statistic: "Average",
period: 300, // 5分平均で評価
evaluationPeriods: 1,
threshold: 90, // 90% を超えたらアラーム
comparisonOperator: "GreaterThanThreshold",
treatMissingData: "missing",
// アラーム発報時に Lambda を直接起動する
alarmActions: [rebootLambda.functionArn],
});
// 3. CloudWatch Alarm からこの Lambda を呼び出せるように権限を付ける
rebootLambda.addPermission("AllowCloudWatchAlarmsInvoke", {
principal: new iam.ServicePrincipal("lambda.alarms.cloudwatch.amazonaws.com"),
action: "lambda:InvokeFunction",
sourceAccount: this.account,
sourceArn: cpuAlarm.attrArn,
});
このようにしておくと、EC2 の CPU が 90% を超えた時点で CloudWatch Alarm が Lambda を起動し、その後の再起動処理と Teams 通知へ繋げられます。
アプリケーション側は Go で実装し、EC2 再起動と Teams 通知を 1 つのハンドラーで処理しています。通知文面は、少し遊びを入れて次のようにしました。
Go言語でソースコードを作ったのは完全に趣味です
// 高負荷になった対象 EC2 を再起動する
_, err = ec2Client.RebootInstances(ctx, &ec2.RebootInstancesInput{
InstanceIds: []string{instanceID},
})
// Teams へ送る通知メッセージを組み立てる
payload := map[string]string{
"instance_id": instanceID,
"message": fmt.Sprintf(
"EC2インスタンス %s でCPU高負荷を検知したため、自動で再起動しました。",
instanceID,
),
}
このあと payload を JSON にして Teams の Webhook へ POST しています。つまり Lambda の責務は、「再起動する」と「関係者へ知らせる」をセットで完了させることです。
デプロイは CDK で行います。今回のようにインフラ変更と Lambda 実装変更を同じリポジトリで管理していると、差分の追跡がしやすくなります。
デプロイ後にCPU使用率が高くなると、無事?Lambdaが実行されてEC2再起動とTeamsへの自動通知が実行されるようになりました。
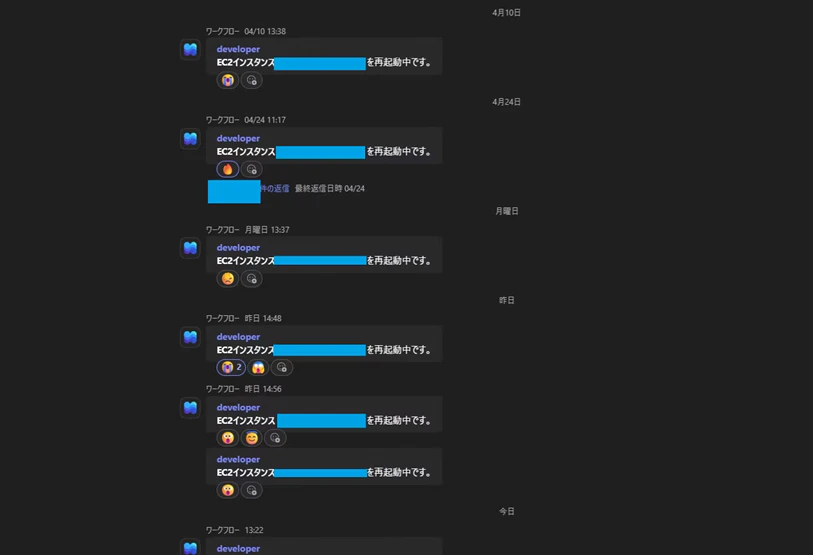
私たちのチームではこの通知が飛んできた際にタグメンションで気づきやすい仕組みになっていることもあり、誰かがスタンプでリアクションをとってくれています。
まとめ
多いときは1日2回、少ないときは週に1回程度発生する課題ではありましたが、チームとしては新規の機能開発を優先していく方針だったため、中々調査含めて放置されていた問題でした。
EC2の再起動作業自体は数分程度で終わりますが、誰かが再起動するだろうの気持ちで放置されてしまうと、数時間以上放置されることもあり、まずはEC2の再起動だけでも自動化することを優先して自動復旧の仕組みを導入しました。
業務時間外でTeamsワークフロー作成やTeamsへの通知はLambda直接かSNS経由どちらがいいかなどを少しずつ調査して、今の構造に落ち着きました。
そろそろ根本原因調査しないとですねぇ
注意事項
本記事に掲載している内容は、あくまで一般的な技術情報と個人の見解に基づくケーススタディであり、特定のサービスの品質を評価・断定するものではありません。また、所属する組織の立場や戦略、意見を代表するものでもありません。