K近傍法(K nearest neighbors)について調べたことを書いていきますが、そもそもどんなアルゴリズムの分類器なのかという話は他の記事で詳しく書かれているので、
- どんな特徴があるのか
- メリット・デメリット
- いつ使うのか
に絞って書きます。
どんな特徴があるのか
K近傍法は、下記の二つが特徴的なアルゴリズムと言えます。
- ノンパラメトリック
- 怠惰学習
ノンパラメトリック
機械学習とはとどのつまりy=f(x)の関数を求めることですが、その中でも、関数の形があらかじめ想定されているものをパラメトリック、そうでないものをノンパラメトリックと言います。
例えば、パラメトリックな手法である線形回帰によるモデルの訓練を行う場合、
w_0 + w_1x_1 + w_2x_2 = 0
のような線形の式を想定した上で、訓練データを与え、w0、w1、w2を求めるというプロセスになります。
この場合、どんなに訓練データの数を増やそうが、式の形が変わることはありません。
逆に、ノンパラメトリックな手法のアルゴリズムでは、f(x)の具体的な形が決まっているわけではありません。(というかK近傍法に関しては怠惰学習ゆえに式の形もなにも、というところなのですが)
そのため、モデルがどんなパラメーターを持つものになるのかは、学習をさせてみないとわかりません。超単純なモデルかもしれないし、めちゃめちゃ次元の高い複雑なモデルになるかもしれないということです。
K近傍法以外、決定木、サポートベクターマシンなどがこのカテゴリに属するアルゴリズムです。
-
メリット
- 柔軟にモデルを作れるので、パラメトリックよりパフォーマンスに優れる
-
デメリット
- データの量が少ないと効果を発揮しにくい
- パラメーターの数が多くなりがちなので訓練に時間がかかる(K近傍法はその限りではない)
- 過学習(overfitting)しやすい
怠惰学習(lazy learner)
怠惰学習とは、教師データから何かしらの新しい方程式を作り出す(= eager learner)のではなく、単純に教師データを丸暗記する(= lazy learner)タイプの学習アルゴリズムを指します。
例えば、ロジスティック回帰による訓練というのは、つまるところ「新規データを分類するためのパラメーター(重み)の算出」ということになりますが、K近傍法のような怠惰学習の場合は、訓練フェーズでは評価式のパラメータを求めるのではなく、「評価の際に参照するための教師データを取り込む作業」ということになります。
もう一度言います。
怠惰学習では、計算しないでデータを取り込むだけです。
怠惰学習であるK近傍法では、訓練フェーズは実質計算が行われないのでかなり早いのですが、その代わり、評価フェーズでは毎回データを参照して結果を算出しなければならないので、取り込んだ訓練データ数が多ければ多いほど時間がかかります。
また、モデルが学習データそのものになるので、その分モデル用のメモリが必要になるのもデメリットです。
メリット・デメリット
メリットデメリットに関しては、細かいところを挙げればもっとありますが、大きなところでいくと下記のようなものがあります。
| メリット | デメリット |
|---|---|
| モデルが単純で、大体どんなデータにもいける | Kの値によって予測のラベルが変わることがある |
| 訓練フェーズが高速 | 訓練データが多ければ多いほど評価フェーズに時間がかかる |
メリット
-
モデルが単純で、大体どんなデータにもいける
与えられたデータからKの距離の訓練データを見て、多数決で分類を行うだけのモデルなので、アルゴリズムがブラックボックス化しません。また、その単純さゆえに大体どんな分類モデルでも汎用的に適用することができます。 -
訓練フェーズが高速
これは怠惰学習の項目でも説明した通りですが、訓練フェーズではほぼ計算が行われないことになるので、高速にモデルを構築することができます。
デメリット
-
Kの値によって予測のラベルが変わることがある
訓練されたモデルは汎化された方程式を持つわけではないので、Kの値によって予測の結果が変わることがあります。Kの値を適切にしないと、同じ訓練データを使っても予測ラベルが一致しないということが起きてしまいます。
適切なKの選択は結構難しいようで、インスタンスの平方根をとるという手法もありますが、必ずしもそれが最良とは限りません。
ちなみにKの値が小さいと外れ値に弱くなり(=過学習)、大きいとモデルの精度が下がります。 -
訓練データが多ければ多いほど評価フェーズに時間がかかる
これも怠惰学習ゆえの特徴で、訓練フェーズが高速であることとのトレードオフになります。
で、いつ使うのか
メリットの部分でも触れましたが、分類系の問題には大体適用できます。
- ユーザーの購買行動予測
- おすすめ映画予測
- クレジットカードの不正利用検知
- 手書き文字認識
などなど。
いつものやつを見てみると、
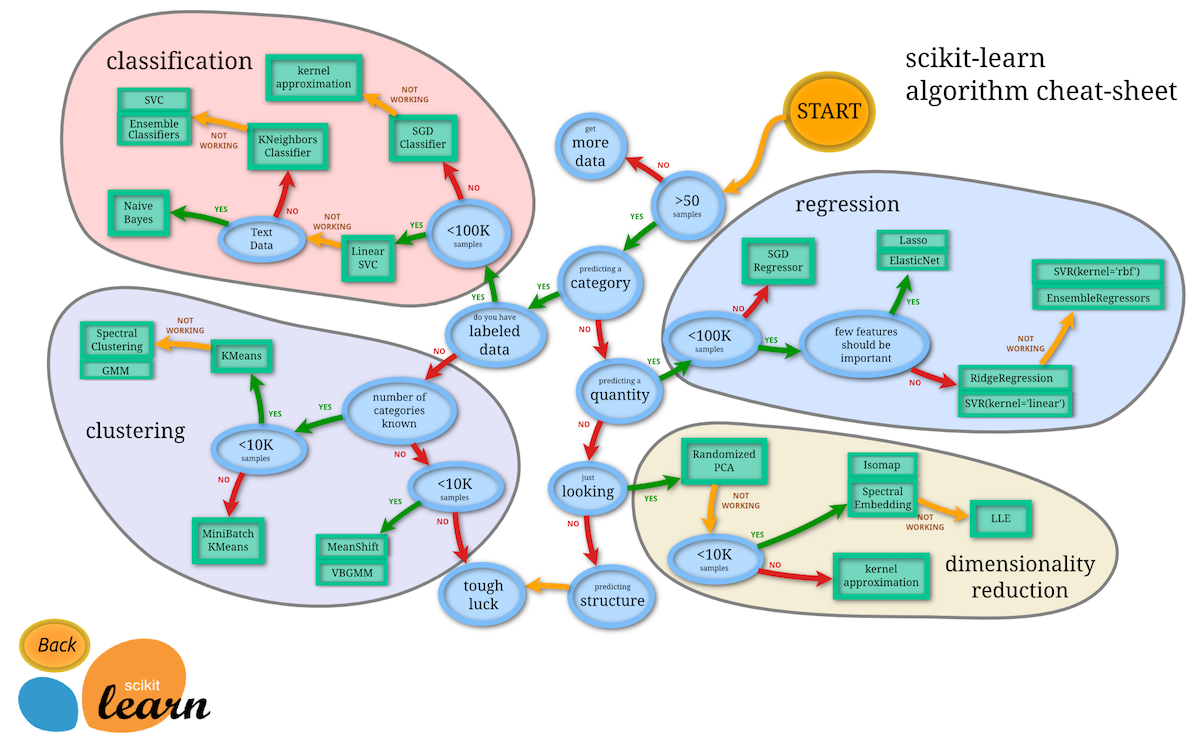
教師あり学習かつ分類問題の中でも、
- <100K samples(サンプルデータ数が100,000未満である): YES
- linear SVC : NOT WORKING
- Text Data(対象が文章データである): NO
の場合に使えとのことです。
サンプル数が多ければ多いほど評価フェーズの時間も長くなることは説明した通りですが、それに従って100,000以上のデータがある場合は適しません。
linear SVCはscikit-learnのSVCモデルではデフォルトカーネルになりますが、単純そうな分類問題はとりあえずこれで試してみて、次にK近傍法を使って精度が上がるかどうか見てみるようなイメージでしょうか。
K近傍法のシミュレーションは下記のサイトで行えます。
http://vision.stanford.edu/teaching/cs231n-demos/knn/
参考
ノンパラメトリックについて
https://machinelearningmastery.com/parametric-and-nonparametric-machine-learning-algorithms/
怠惰学習について
https://sebastianraschka.com/faq/docs/lazy-knn.html
その他
https://www.dummies.com/programming/big-data/data-science/solving-real-world-problems-with-nearest-neighbor-algorithms/
https://medium.com/@adi.bronshtein/a-quick-introduction-to-k-nearest-neighbors-algorithm-62214cea29c7