1. はじめに:CNNの中身ってどうなってるの?
こんにちは。現在転職活動中の近藤です
今回は特徴量がどのように変化していくのかを画像で可視化し
各レイヤーで行われている数値処理の内容をやさしく解説していきます。
出来るだけやさしく説明しているので数学が苦手な方も読んでみていただけると幸いです。
想定読者
本記事は、以下のような方を想定して書いています:
- CNNのソースコードを見たことがある
→とりあえず動かしたことはある が、仕組みの説明には自信がない - 各レイヤー(Conv・Pool・Denseなど)の処理内容の理解がフワッとしている
→ 処理の意味を見て納得したい・表面的でない理解を身につけたい -
CNNのチューニング沼にハマっている が、分析方法が分からない
→学習がうまくいったかどうか、見た目や精度だけに頼っている
→学習の「良し悪し」の判断をlossやaccuracy以外の指標を持っていない
ではさっそくいってみましょう💨!
2. プロジェクトの概要
本プロジェクトでは、CNNの各レイヤーが出力する特徴マップの変化を観察し、
その背後にある数値処理の仕組みを理解することを目的としています。
今回のプロジェクトのソースコードやデータはこちらにアップしています👇
🔧 tech-kondo/cnn-insight-visualization
🛠 実施したこと(手順)
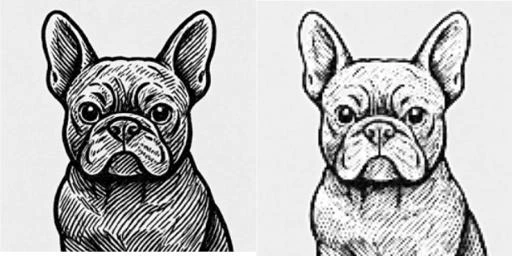
犬のイラスト画像1枚を入力し、各レイヤーで出力される特徴マップを可視化
1. Conv層の処理前後の可視化
→自作カーネルとTensorFlow自動生成カーネルでの畳み込み後の特徴マップを比較
2. Pool層の処理前後の可視化
3. Flatten層、Dense層の数値をグラフで可視化(1次元のため)
学習前後の特徴マップの違いを可視化・差分比較
1. 2クラス(フレブル・ダックスフント)分類モデルを自作し、教師あり学習を実施
2. 1の学習済みモデルの重みを用いて、学習前後の特徴マップの変化をヒートマップで比較
💡 なぜこの流れにしたのか?
• 「CNNの出力が学習でどう変わるのか」を、段階ごとに視覚+構造で理解したい
• 学習によって特徴量がどのように変化するのか自作CNNで可視化して重みがどのような意味を持つのか知りたい
🔍 各レイヤーで出力される特徴マップを可視化
2.5 CNNの中間出力「特徴マップ」とは何か?
特徴マップとは、入力データから抽出された特徴を可視化したもの。
フィーチャーマップ(Feature Map)とも呼ばれる。
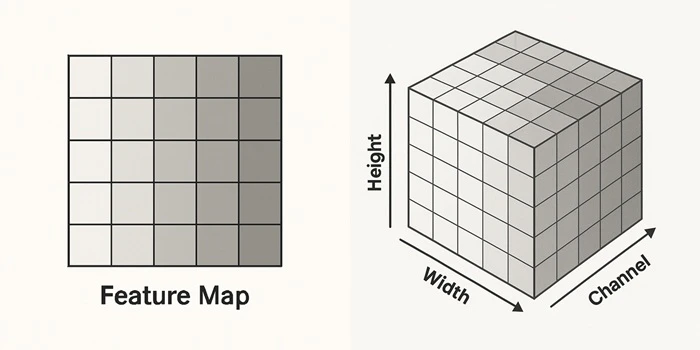
- CNNでは、画像がレイヤーを通過するたびに「何らかの特徴(エッジや模様など)」が数値として抽出されていく
- 出力は 「高さ × 幅 × チャネル数」の3次元配列 (チャネル数=フィルタの枚数)
- 各要素の数値は、「その特徴がどれだけ強く表れているか」を意味する
→ 数値が大きいほど特徴が強いということ - 可視化時には cmap='gray' や cmap='viridis' を使用して色で数値の強弱を表示する
→cmap='gray'は白い色が強い、cmap='viridis'は明るい色が強い

特徴マップの変化を一枚のフィルタを例として最初にお見せします。
【元画像】→【畳み込み後】→【プーリング後(圧縮されてpx数は1/2)】

元画像の中にある縁や線の情報が強調されていることが視覚的に分かります。
このような処理が、CNNの中で層を重ねながら段階的に行われていくのです。
改めて今回の可視化に使用する元画像はこちらです。

本記事では、レイヤー別に見る 「変化」と「処理構造」 を順に解説していきます!
3. Conv層:畳み込み処理とは何か?
📷カーネルについて
まず最初に畳み込み処理を理解するのに必要なカーネルについて説明をします。
カーネルとは 数字が並んだ小さな二次元配列です。
この小さな配列は 画像全体を変化させるフィルターのような役割を果たします。
画像の上でカーネルを重ねてスライドさせながら畳み込み処理をすることで、暗い部分だけを明るくしたり輪郭を強調したりすることが出来ます。
どのように特徴を強弱させるかはカーネルの数値によって決められます。
では畳み込み処理はなぜ行われるのか?
畳み込み処理は画像の特徴を抽出するために行います。
具体的にいえば、ある特定のエッジを強弱させるための処理です。
🎨 Before/After:Conv層の出力特徴マップを画像として比較 ✅
自作カーネルとTensorFlowの自動生成カーネルでの
畳み込み後の特徴マップを可視化してみました。
🔸 自作カーネルを用いた畳み込み処理の可視化
右方向のエッジを強調するカーネルの生成
"Vertical_Edge": np.array([[ -1, 0, 1],
[ -2, 0, 2],
[ -1, 0, 1]])
上記3×3pxのカーネルを100倍に拡大し可視化したカーネル


畳み込み処理後のBefore/After


下方向のエッジを強調するカーネルの生成
"Horizontal_Edge": np.array([[ -1, -2, -1],
[ 0, 0, 0],
[ 1, 2, 1]])
上記3×3pxのカーネルを100倍に拡大し可視化したカーネル

畳み込み処理後のBefore/After


右上方向のエッジを強調するカーネルの生成
"Diagonal_Edge": np.array([[ 0, 1, 2],
[-1, 0, 1],
[-2, -1, 0]])
上記3×3pxのカーネルを100倍に拡大し可視化したカーネル


畳み込み処理後のBefore/After


🔸 TensorFlow自動生成カーネルを用いた畳み込み処理の可視化
カーネルの生成と畳み込み処理の実装
conv_layer = tf.keras.layers.Conv2D(
filters=4,
kernel_size=3,
padding='same',
use_bias=False
)
- filters=4 : 4個のカーネルを使用。出力のチャネル(フィルター数)が4になる
- kernel_size=3 : カーネルのサイズを自作カーネルと同じ3×3に設定
- padding='same' : 画像のまわりを0で囲って出力のサイズを入力と同じ大きさに保つ
- use_bias=False : 畳み込みのあとにバイアスを使用せずカーネルによる変換だけにする
畳み込み処理後のBefore/After
下のカーネルで畳み込みした結果が上の画像(特徴マップ)です。


Tensor Flowの自動生成カーネル凄い!!
複雑なカーネルで様々な特徴をうまくコントロールしている!!!!
比較用に自作カーネルの結果をこちらにも貼ります


畳み込み処理ではどのように計算してこのような結果を得ているのでしょうか?
次のセクションでは、数値をどう変化させているか処理内容を紐解いていきます。
🔢 配列ベースの計算解説:リスト同士の畳み込みをやさしく図で解説🔍
畳み込みとは?
まず一言で言うと:
畳み込みは、カーネルを反転させてずらしながら重なった数字を掛けて足し算する作業です。
どういうことか、シンプルな一次元配列を用いて計算してみます。
a = np.array([2, 0, -1]) b = np.array([1, 3, 5])

この二つの配列を畳み込みします。
Step 1:カーネルを反転する
bをカーネルだと仮定してbを反転します。

Step 2:ずらしながら計算
先ほど反転したカーネルを左端に移動して重なり合う数値を掛けて足していきます。
1つ目の要素= 2×1 = 2

こちらも重なり合う要素を掛けてそれぞれ足していきます。
2つ目の要素= 2×3 + 0×1 = 6

3つ目の要素= 2×5 + 0×3 + -1×1 = 9
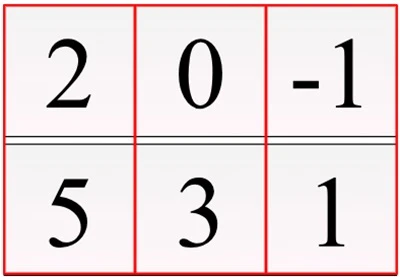
4つ目の要素= 0×5 + -1×3 = -3

5つ目の要素= -1×5 = -5
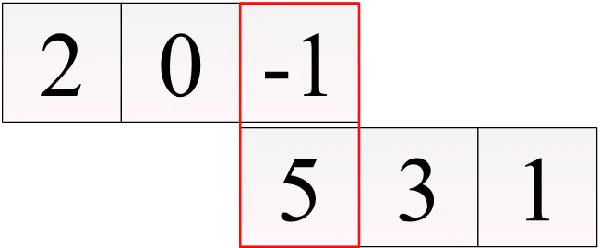
このように計算して、
[2, 0, -1]と[1, 3, 5]の畳み込み結果は[2, 6, 9, -3, -5]となります。
以下のように実装すると解が分かります。
import numpy as np
a = np.array([2, 0, -1]) # 入力信号
b = np.array([1, 3, 5]) # カーネル
# 畳み込みを実行
result = np.convolve(a, b)
print(result)
[ 2 6 9 -3 -5]
画像の畳み込みも上記の処理が二次元配列ベースで行われています。
畳み込みを数式で表すとこのような式になります。
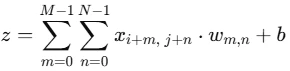
-
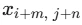 :入力画像(特徴マップ)の値
:入力画像(特徴マップ)の値 -
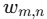 :畳み込みカーネル(フィルタ)の重み
:畳み込みカーネル(フィルタ)の重み -
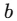 :バイアス
:バイアス -
 :カーネルのサイズ(例:3×3)
:カーネルのサイズ(例:3×3) -
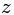 :出力特徴マップ上の1つの位置に対応する値
:出力特徴マップ上の1つの位置に対応する値
🔊ただし注意点!!
実際のディープラーニングではカーネルの反転がない「相互相関処理」が用いられていることが多いです。
関数名だけを見れば畳み込みが行われていると思いきや
| 関数 / API | 反転 | 名前のわりに… |
|---|---|---|
np.convolve() |
✅ あり | 名実ともに「畳み込み」 |
cv2.filter2D() |
✅ あり | 名実ともに「畳み込み」 |
tf.keras.layers.Conv2D() |
❌ なし | 実は「相関」 |
tf.nn.conv2d |
❌ なし | 同じく「相関」 |
torch.nn.Conv2d() |
❌ なし | 実は「相関」 |
公式ドキュメント
tf.nn.convolution:https://www.tensorflow.org/api_docs/python/tf/nn/convolution
torch.nn.Conv2d:https://docs.pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
今回のTensorFlow自動生成カーネルも裏では畳み込みでなく相関が行われていたというわけですね。カーネルが複雑なので反転なんてしなくてもうまく特徴が抽出されるんですね。
4. Pooling層:情報をどう「まとめる」のか
プーリング層を一言で表すと情報の圧縮です。
どのように画像が変化するのかまずはご覧ください。
🎨 Before/After:Pooling層の出力を比較し、どのように情報が圧縮されているかを視覚的に確認 ✅
プーリング処理の実装
pool_layer = tf.keras.layers.MaxPooling2D(
pool_size=2,
strides=2,
padding='same'
)
- pool_size=2 : 処理対象の領域サイズ。「カーネル」/「ウィンドウ」のサイズとも呼ばれる
- strides=2 : 処理対象の領域を2pxずつスライドさせる。この値が大きくなるほど情報の「間引き」が起こり、圧縮率が高くなる。
- padding='same' : 画像のまわりを0で囲う
プーリング処理後のBefore/After
画像のサイズは256px→128pxへと半分に圧縮されています。



次は畳み込み処理とプーリング処理を一通り行った画像をまとめて出力しました。
Before

After

Before

After

おもしろい結果が出ました。
画像を圧縮しているのに、特定の特徴は強化されていることが見て分かります。
解説してみます。
例えばこの特徴マップは


陰影によりフォルムの凹凸がより分かりやすく表現されているように見えます。
こちらの特徴マップは


背景と被写体をうまく分離できているように見えます。
こちらの特徴マップは


毛並みがくっきり美しく表現されている気がします。
この特徴マップは

表情が強調されているように見えますね。
このように畳み込みとプーリングを組み合わせることにより
特定の特徴が強調されていることが分かりました。
どのように、特徴を残して画像を圧縮するのか次のセクションで解説します。
🔢 配列ベースの計算解説:2×2領域での最大値取得(MaxPooling)の処理を例示🔍
プーリング処理でも、畳み込み処理と同様に特定の領域をスライドしながら処理を行います。
このスライドする範囲は 「カーネル」 または 「ウィンドウ」 と呼ばれます。
ただし、 畳み込みのカーネルと違って数値(重み)を持たず、単に「処理対象の領域」という意味 で使われます。
今回は
- 特徴マップサイズ = 6×6px
- ウィンドウサイズ = 2×2
- ストライド = 2
という設定でMaxプーリング処理を解説します。
こちらが6×6pxの特徴マップです。
特徴マップなので値が大きければ大きいほど特徴が強いという特性を持っています。
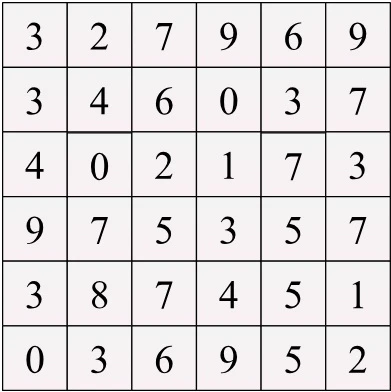
赤い枠内が処理対象の領域、ウィンドウです。
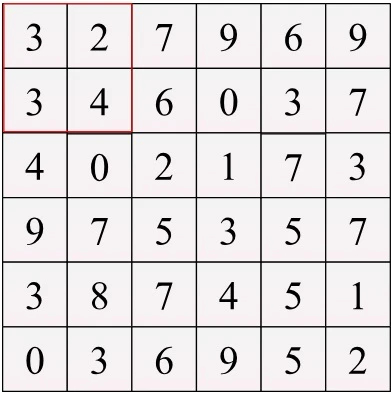
プーリング処理では、このウィンドウ内の一番大きい値を取ります。
[3,2,3,4]なので、4になります。
ストライドが2なのでウィンドウを2pxスライドさせて、また領域内の最大値を取ります。
これを繰り返し行います。

太枠が処理をしたウィンドウの跡です。赤いピクセルが最大値です。

最大値を残して圧縮した結果が以下です。

これが最大値をとるMaxプーリング処理です。
他にも平均値をとるタイプのプーリングもあります。
Maxプーリングの処理を数式で表すとこのような式になります。
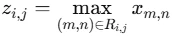
-
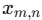 :入力特徴マップの値
:入力特徴マップの値 -
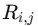 :出力位置
:出力位置 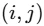 に対応する プーリング対象領域(例:2×2のウィンドウ)
に対応する プーリング対象領域(例:2×2のウィンドウ) -
 :出力特徴マップのの位置に入る値
:出力特徴マップのの位置に入る値
次のセクションではFlatten層とDence層の出力について解説していきます!
5. Flatten → Dense層:大きく形状が変化し意味的な特徴へ
🎨 FlattenとDense層で出力されたベクトルを可視化 ✅
Flatten層では、プーリングによって要約された特徴マップ(3次元:高さ×幅×チャネル)を、1次元の長いベクトルに変換します。
これは、画像的な構造を持っていた情報を「数値の並び」として扱えるように“ペタンと平らにする”操作です。
Flatten処理の実装
tf.keras.layers.Flatten(name='flatten')
...
print("Flatten形状:", flatten_out.shape)
Flatten形状: (1, 131072)
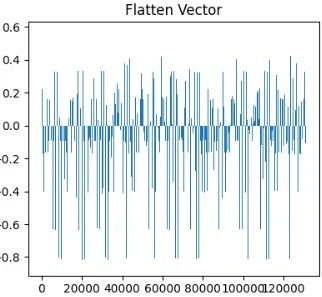
Flattenの出力をグラフで可視化すると、0〜1付近の数値が連なったグラフとなり、各要素が画像中の小さな領域の情報を表していることがわかります。
その後のDense層では、このFlattenされたベクトル全体に対して重みをかけて合成し、さらにReLUなどの活性化関数を通して「重要な特徴」に圧縮・強調された出力が得られます。
Flatten処理の実装
tf.keras.layers.Dense(8, activation='relu', name="dense")
...
print("Dense形状:", dense_out.shape)
Dense形状: (1, 8)

Denseの出力は、Flattenと比べて要素数が少なく、情報が圧縮されます。
学習が進むにつれて、Denseの出力は“意味のある特徴”を強調する方向へと最適化されていきます。
🔢Flattenでの次元変換、Dense層での重み×入力の演算の意味を解説🔍
🔸 Flatten層の処理
たとえば、プーリング後の特徴マップが (128, 128, 8) の形だったとします。Flatten層ではこれを単純に「縦に並べる」ことで、(128×128×8 = 131072) の1次元ベクトルに変換します。
計算は一切行われておらず、次元の変換のみが行われています。
この変換によって、画像から抽出された全ピクセル的な特徴が1本のベクトルに展開され、Dense層などの全結合層で扱える形式になります。
🔸 Dense層の処理
Flattenされたベクトルx = [x₁, x₂, ..., xₙ] に対して、以下の計算を行います:
1) z = x₁*w₁ + x₂*w₂ + ... + xₙ*wₙ + b
2) a = ReLU(z)
X = 特徴
W = 重み
b = バイアス
1) これは、入力ベクトル(特徴)の各要素に重みベクトルを掛けて足し合わせた値にバイアスを加えています。
つまり、 入力ベクトルの中身(特徴)を、重みベクトル(どれを重要視するか)でスコア化して、1つの数字(=特徴の合成値)にまとめる ということをしています。
2) 非線形関数で変換する
これらの1)と2)の処理を1セットとして各ユニットが出力されています。
今回は学習していないので、W = 重み と b = バイアス はランダムな値であり、
つまりは何を抽出すべきかをまだ知らない状態です。
学習していくにつれ、Wとbは「どの要素がどれだけ重要か」最適化され意味のある数値になり、少数の次元に圧縮されます。
このような処理により、
Dence層では “画像全体の数値的特徴” を “意味的な特徴” に変換しています。
🧠 モデルで見る学習の影響
6. 学習前後の全体比較
先ほど、学習により重みが最適化され、意味のある特徴が抽出されるようになると述べました。
実際にCNNモデルの学習・構築を行い、学習前後の特徴マップを比較してどのような変化が見られるか。可視化していきます。
📷 学習データの準備
webスクレイピングを用いてダックスフントとフレンチブルドッグの写真を約200枚ずつ収集し、256×256pxにリサイズしたものを学習データに用いました。
-
ダックスフント

-
フレンチブルドッグ

これらの学習データをTensorFlowのKeras APIを用いて、
画像フォルダ構造からtf.data.Datasetを生成
# 訓練・検証用に分割(8:2)
train_ds = tf.keras.utils.image_dataset_from_directory(
dataset_dir,
validation_split=0.2,
subset="training",
seed=42,
image_size=(256, 256),
batch_size=32,
label_mode='int' # クラスは整数(0 or 1)
)
val_ds = tf.keras.utils.image_dataset_from_directory(
dataset_dir,
validation_split=0.2,
subset="validation",
seed=42,
image_size=(256, 256),
batch_size=32,
label_mode='int'
)
🧠 モデルの定義
とてもシンプルなCNNを構築しました。
inputs = Input(shape=input_shape)
# 特徴抽出部(Conv層)
x = layers.Conv2D(16, (3, 3), activation='relu', padding='same', name='conv1')(inputs)
x = layers.MaxPooling2D((2, 2), name='pool1')(x)
x = layers.Conv2D(32, (3, 3), activation='relu', padding='same', name='conv2')(x)
x = layers.MaxPooling2D((2, 2), name='pool2')(x)
# 分類部
x = layers.Flatten()(x)
x = layers.Dense(64, activation='relu')(x)
outputs = layers.Dense(num_classes, activation='softmax')(x)
model = models.Model(inputs=inputs, outputs=outputs, name="SimpleCNN")
Model: "SimpleCNN"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ input_layer_2 (InputLayer) │ (None, 256, 256, 3) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv1 (Conv2D) │ (None, 256, 256, 16) │ 448 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ pool1 (MaxPooling2D) │ (None, 128, 128, 16) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2 (Conv2D) │ (None, 128, 128, 32) │ 4,640 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ pool2 (MaxPooling2D) │ (None, 64, 64, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten_2 (Flatten) │ (None, 131072) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_4 (Dense) │ (None, 64) │ 8,388,672 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_5 (Dense) │ (None, 2) │ 130 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
epoch10で学習
lossはこんな感じ
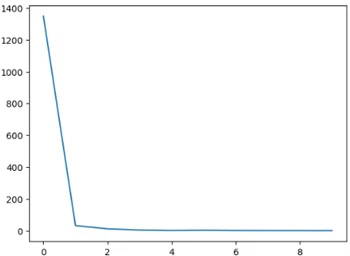
まあ収束してるのでヨシとします
📷 検証データ
今は亡き愛犬の写真を使用します。

特徴マップの比較
上段=学習前の特徴マップ
中段=学習後の特徴マップ
下段=差分比較ヒートマップ
赤色=特徴量が強くなった箇所、青色=特徴量が弱くなった箇所
📚 conv1
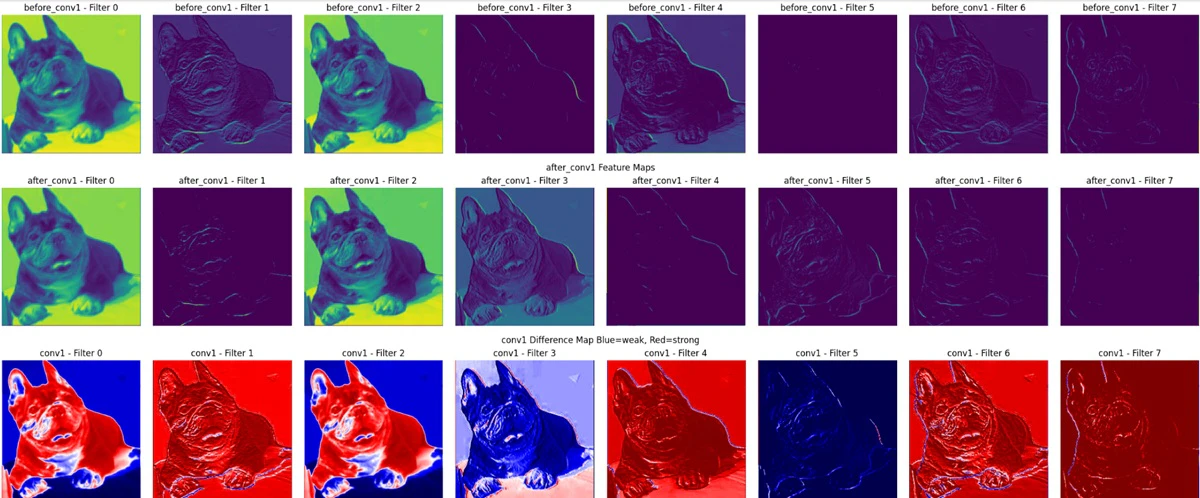
おお...?犬の領域が赤くなってる=特徴量が強くなってる!
より深いレイヤーも見てみましょう
📚 pool1

変化なし。プーリング処理しかしていないからか
📚 conv2

おお!!!!!


きたー!お見事ー!!!!!🤩🙌
- 2クラス分類
- 学習データ1クラスあたり200枚
- シンプルCNN
- epoch=10
上記条件で学習したモデルが犬の特徴を認識出来ました。
他にも背景が複雑/別の犬種/複数の犬などのバリエーションでも試したいところですが、
比較検証した結果、意味のある特徴量の変化が確認できたのでここで検証は終了します!
7. ✍️ おわりに:可視化と分析で開けるCNNの中身
今回の可視化プロジェクトでは、Conv層・Pooling層・Dense層を通じて出力されるデータを可視化し、各レイヤーがどのような数値処理を行い、出力がどう変化するのかをひとつずつ紐解いてきました。
ただ結果を見るだけではなく、手順を追って可視化し、それを数値処理ベースで理解することでCNNの処理が抽象的なものではなく構造的なものとして腑に落ちてくる感覚がありました。
また、今回の取り組みを通じて可視化することの重要性を感じました。
チームメンバーに説明する場面や、クライアントに成果を伝える場面では、今回のように可視化して視覚的に伝えるということが非常に重要な工程だと実感しました。
可視化力=人に伝える技術のひとつでもありますね。
他にもモデルの精度向上作業の業務でも、モデルの設計においても、どれだけ内部の処理やデータを可視化できるかが分析の深さや意思決定の質につながるのではないかと気づかされました。
ここまで読んでくださりありがとうございました。
参考になった方は、いいね・ストック・フォローしてもらえると嬉しいです!