1. はじめに
今回、「Clean Architecture 達人に学ぶソフトウェアの構造と設計」を読み、ハンズオンから漫然と手探りで実装していたクリーンアーキテクチャーの理論的な背景を知れたので、忘備録も兼ねてまとめておこうと思います。
この記事では、クリーンアーキテクチャーそれ自体の具体的な実装は踏み込みません。また今度別の記事でまとめるかもしれませんが、今回は要旨をまとめていこうと思います。
これは個人の感想になっており、理解が不正確な部分も含まれる可能性もあります。ご質問いただいても構いませんが、気になった方は書籍を購入されることをお勧めいたします。
目次
2. Clean Architecture
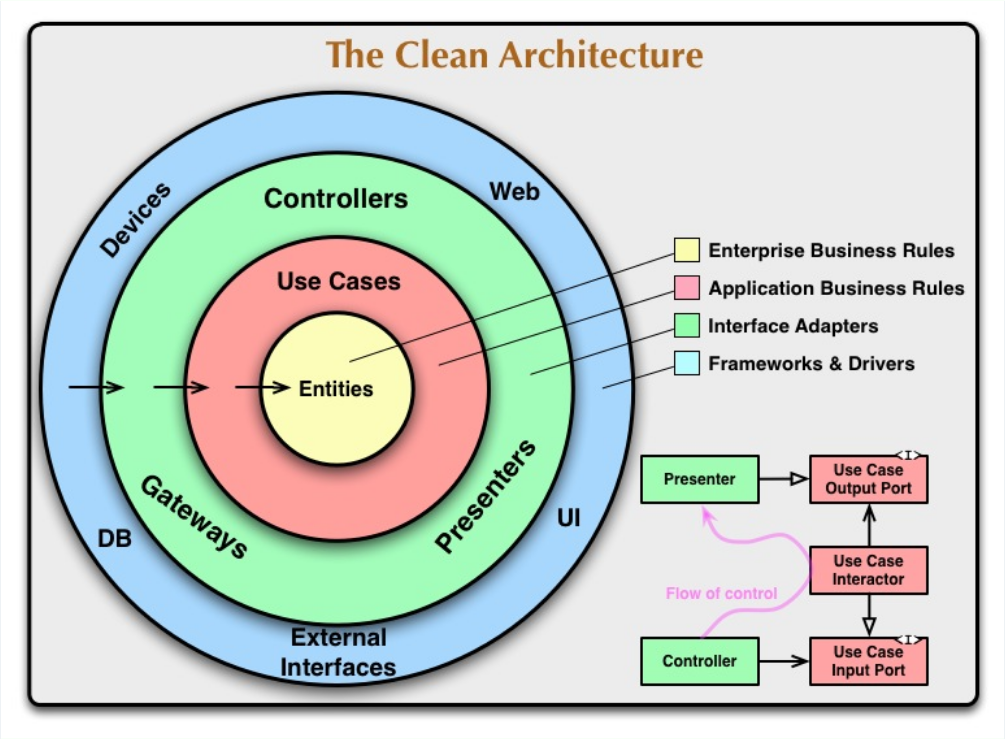
「クリーンアーキテクチャーといえば」でよく出てきますし、この分野の情報をあさり始めたことがあるなら一度は目にしたことがあると思います。
クリーンアーキテクチャーを理解する時におさえるべきポイントは二つです。
- 抽象度に応じてレイヤーを分けること
- 外側の変化しやすいコンポーネントはより内側の安定したコンポーネントに依存すること
クリーンアーキテクチャーの勘所を一言で説明するとすれば、「より抽象的で安定的なものに依存(より内側のものに依存)して、外側を差し替え可能にする」ことだと思います。
これを配置的に言い換えると「最も抽象的で安定させるべきentity(ドメインロジック)を中心において、インターフェースやデータベースなどの具体的で変化しやすい詳細を周縁に置き、ドメインロジックに定められたとおりに処理の記述をユースケース層に集中させる」ということになります。
おそらく、インターフェースが具体的な詳細部分で変化しやすいというのは感じたことがあるかなと思います。例えば、メールアドレスを使ったサインアップメソッドを実装しようとするとき、具体的なレイアウトやインプット要素の配置などは頻繁に変えたり調整したりすると思いますが、最初に決めた入力事項やそのデータ型を変えることは早々ないかなと思います。
また、依存の方向が外側から内側に行くため、より内側の層は外側の層の変更から守られることになります。
これは同時に、変更の影響範囲の予測を容易にします。
具体的な詳細部分の変更はそれより内側の層に変更の影響が及ぶことはないですが、逆に内側のより抽象的で安定的だった層を変更するならば広範な影響が出ることが予測されます。その点で、特にドメイン層の設計は最も慎重になるべきでしょう。
先程の例でいえば、Webインターフェースの変更はサインアップ処理の本体には影響を与えませんが、例えばemail, password, usernameの他にsecond emailのようなものの入力まで求めるようになるならば、当然UIも変えなければならないことは明白でしょう。
クリーンアーキテクチャーを実装するにあたって、三つのメリットがあります。
-
実装の差し替えが容易になる
例:認証プロバイダーをA社→B社に変える、DBをMySQL→PostgreSQLに変える、UIをWeb→モバイルアプリに変える、などが「内側」に影響しない。 -
テスト容易性が増す
インターフェースをモックすれば、外部依存を切り離してドメインやユースケースを単体で検証できる。 -
システムの寿命を延ばせる
ドメイン層(最も抽象的・安定的な部分)を守ることで、外の流行技術が変わっても中心は生き残る。
まずは、「domainを中心においてUIやDBといった詳細を周辺に配置し、周辺から中心にのみ依存するようにする」というクリーンアーキテクチャーの構造を所与のものとして置いたうえで、依存を内側に向かわせるにはどうしたらよいか?と言うところから議論を始めたいと思います。
3. 依存性
そもそも、クラスの関係において「依存」とは何かというところから始めます。
クラスA、クラスBがあり、クラスAがクラスBを参照している(importしている/インスタンス化している)とき、クラスAはクラスBに依存していると言います。
クラスAは内部的に、クラスBの実装を前提として処理を組み立てているので、クラスBがなければ処理が破綻(undefined errorなど)してしまいます。この点で、「依存している」と表現します。
これに対して、クラスBは己がどう扱われるかということに関して関知していません。その去就はユーザーに任されています。
よくクラス図で描かれるときは、AからBへと矢印が向きます。
個人的に、どうしても矢印の向きがわからなくなるのですが、「参照された/呼び出された/importされた」受け身の側が、矢印の先にある、というように考えるといいかもしれません。
3-1. 依存性逆転
クリーンアーキテクチャーにおいては、「より抽象的で安定的なものに依存する」形にしなければなりません。これが、依存関係を表す矢印が内側に向いている理由です。
ただし、実装にあたっては必ずしも依存関係を逆転させなければならないわけではありません。
外側のレイヤーのクラスなどが内側のレイヤーのクラスを呼び出しているとき、素直にimport文を書けばよいだけなので、特にケアすることはありません。内側のレイヤーにあるクラスは、自分がどう扱われるかには関知しないので、確かに依存性は内側に向かっています。
例えば、インターフェース層はコントロール層からクラスをimport(Interface -> Control)し、コントロール層はユースケース層からimport(Control -> Usecase)するといったとき、特に深く考えなくても依存方向は内側へと向かっています。
ただし、時に依存の方向を逆転させる必要があります。
これはつまり、そのままでは内側の層が外側の層からオブジェクトやクラスを呼び出す(依存する)ところを、それを逆にしなければなりません。ただ普通にやろうとしても参照を逆にすることはできません。
多くのオブジェクト指向言語ではAbstract Factoryパターンを使って依存性の逆転を実現します。
このパターンは具体的には、クラスAがクラスBに依存しているとき、クラスAが存在する層でクラスBのインターフェース(抽象/このように振る舞いをしろとあらかじめ定めた条件)を定義し、クラスBがそれを継承する形で依存関係を反転させることを指します。
例えばUserUsecaseがDatabaseAdapterに依存しているとき、UserUsecaseの層でUserRepository(インタフェース)を提供し、DatabaseAdaptarがそれを呼び出して継承することで、依存関係が逆転することになります。
具体的に見ていきましょう。
まず、UserUsecaseがDatabaseAdapterを直接呼び出していて、依存関係が外に向かってしまっている場合です。
# ユースケース層
class UserUsecase:
def __init__(self):
self.db_adapter = DatabaseAdapter()
def register(self, user: User):
self.db_adapter.save(user)
def get_by_id(self, id: str) -> User:
return self.db_adapter.get_by_id(id)
class DatabaseAdapter:
def __init__(self, session):
self.session = session
def save(self, user: User):
self.session.add(user)
self.session.commit()
def get_by_id(self, id: str) -> User:
return self.session.query(User).filter_by(id=id).first()

次が、Usecaseがインターフェースを定義し、依存関係を逆転させた例です。
# ユースケース層(内側が定義する抽象)
class UserRepository(ABC):
@abstractmethod
def save(self, user: User) -> None:
raise NotImplementedError
@abstractmethod
def get_by_id(self, id: str) -> User:
raise NotImplementedError
# ユースケース層
class UserUsecase:
def __init__(self, repo: UserRepository):
self.repo = repo
def register(self, user: User):
self.repo.save(user)
def get_by_id(self, id: str) -> User:
return self.repo.get_by_id(id)
# インフラ層(外側が実装する具体的な処理)
class DatabaseAdapter(UserRepository):
def __init__(self, session):
self.session = session
def save(self, user: User):
self.session.add(user)
self.session.commit()
def get_by_id(self, id: str) -> User:
return self.session.query(User).filter_by(id=id).first()
UserUsecaseはなお、UserRepositoryを参照しているので、参照は外に向かっているようにみえますが、大事なのはこのようなインタフェースはUsecaseのレイヤーの内側にあるとみなされることです。UserRepositoryをDatabaseAdapterが継承しているため、依存関係はインフラ層からユースケース層へと向かっています。

私はてっきり、依存関係を内側に向けるためにすべての場合においてこのように依存性逆転の法則を使わないといけないと思っていたので、そこらへんの混乱が解消できてよかったです。
ただ、このような依存性逆転の原則を用いない場合においても、よく内側の層はインターフェースを提供し、外側の層は実態としてのクラスではなくインターフェースを参照するように規定することが多いです。これは、「抽象への依存」と言われます。
3-2. 抽象への依存
抽象に依存する利便性を説明するために、認証システムのお話をしましょう。
最近、認証の手段はかなり多くなってきました。
伝統的なemail, passwordから、ワンタイムパスワードやワンタイムメールを用いた認証、指紋や顔、静脈を使った生体認証、スマホアプリを使った二段階認証ナドナド
あるサービスは自前で認証システムを準備するのが面倒になったので、ある認証プロバイダーにすべて丸投げすることにしました(API経由で利用することを想定)。
ただ、この認証プロバイダーは多様な認証方法を備えているとします。このため、もし一々サービスの側から指紋認証やワンタイムパスワードやらの認証方法を指定しなければならないのだとしたら、実に面倒ですし、認証プロバイダーが新しい認証方法を実装するたびにアップデートしなければなりません。もしこれを何も疑問に思わずに実装しているのだとしたら、仕事を増やすことに長けた日本の労働慣行に毒されています。
しかし実のところサービス側はただ、以下の二点だけをできるようになれば、とても便利になるはずです。
- 認証プロバイダーの画面に遷移させる
- 認証されたかどうかの結果を知る
例えば、ユーザーのアクションに基づいてRedirectし、向こうで認証した結果だけを受け取れば、その具体的な実装の中身を知る必要はありません。
認証プロバイダーがそのようなインターフェースを呼び出してくれれば、それに従うだけで大丈夫です。
このように、抽象に依存することができれば、認証プロバイダー側の認証システムの詳細に依存することなく、何を与えるべきで何が返されるのかを把握しておくだけで使い続けることができるのです。
これをクリーンアーキテクチャーに組み込むとすれば、外側のレイヤーから呼び出される内側のレイヤーのクラスは、常にインターフェース(抽象)であるように設計するべきです。
ただ、そのとき、詳細を記述したクラスはどこで呼ばれるのでしょうか?
よく使われる手法は依存性注入です。
3-3. 依存性注入
ただし、いくら抽象に依存すると言っても、抽象それ自体には具体的な処理の記述がないわけですから、どこかで具体的なクラス・オブジェクトは呼び出さなければなりません。
その「組み立ての責務」を担いつつ、層同士を疎結合にする役割を負うのが依存性注入です。
# ユースケース層
class UserUsecaseInterface(ABC):
@abstractmethod
def register(self, user:User) -> None:
raise NotImplementedError
def get_by_id(self, id: str) -> User:
raise NotImplementedError
class UserUsecase(UserUsecaseInterface):
def __init__(self, repo: UserRepository):
self.repo = repo
def register(self, user):
self.repo.save(user)
def get_by_id(self, id):
return self.repo.get_by_id(id)
# インターフェース層
def get_repository() -> UserRepository:
return UserRepositoryImpl(session)
def get_usecase(repository: UserRepository = Depends(get_repository)) -> UserUsecaseInterface:
return UserUsecase(repo=repository)
@router.get("/{id}")
def get_user(id: str, usecase: user.UsecaseInterface = Depends(get_usecase)):
return usecase.get_by_id(id)
上の例では、「実体としてはUserRepositoryImplやUserUsecaseという具体的なクラスを取得しているけれども、インターフェースを扱っていることにしている」点に注目してください。
UserUsecaseクラスは、中身でUserRepositoryImplを呼び出さずにインターフェースを受け取るように定義しています。こうすることで、インフラ層とユースケース層を疎結合にできます。(依存性注入)
必ず依存性注入が必要か?
インターフェースと見做して扱うことだけを考えれば、必ずしも依存性注入にする必要があるわけではありません。
例えば以下の例では、初期化のところでUserRepositoryImplを呼び出していますが、その返り値の型をリポジトリと言うインターフェースにしているので、先ほどの例のようにインターフェースのメソッドとして呼び出しています。
class UserUsecase:
def __init__(self, session):
self.repo: UserRepository = UserRepositoryImpl(session)
def register(self, user):
self.repo.save(user)
def get_by_id(self, id):
return self.repo.get_by_id(id)
ただ、この場合テスト容易性が下がります。
テストでは任意のオブジェクトを渡すようにできた方がいいですが、この例では内部でUserRepositoryImplを渡してしまっているので、DBへの依存が固定化されており、それを外すような干渉ができません。即ち単体テストが行えなくなります。
また、UserRepositoryを実装するコードがデータベースを扱うUserRepositoryImplから、InMemoryUserRepositoryImplのようなものに変えるとき、その差し替えにUserUsecaseの中身まで変更しなければなりません。これは、変更の範囲を内側に及ぼさないようにする約束に背きますので、やはり避けた方がよい理由になるでしょう。
このような理由から、依存性注入がよくセットで使われることになります。
4. SOLID原則
以下では、どうしてクリーンアーキテクチャーではそのようなレイヤーの構成になるのか、依存性を内側に向けるべきなのか、ということについて理論的な根拠を探っていきます。
直接的には、コンポーネントに関する諸原則が根拠になっているそうですが、さらにそのコンポーネントの原則を支えているのがクラスに関するSOLID原則です。
Single Responsibility Principle
一つ目の原則は、「単一責任の原則」です。
Robert氏に曰く、「モジュールを変更する理由はたった一つであるべき」原則です。
そのクラス・メソッドが利用されるシーンにおいて、アクターが違うのであればそのクラス・メソッドは分割するべきで、同じアクターであるならば共通化するべき、ということを指しています。
これは「過剰な共通化によってもたらされる悲劇」を避けるために大切です。
利用シーンの異なる処理の中で偶然共通した処理があった時、これを共通化して切り出してしまうと、ある処理の過程で切り出した処理に変更を加えなければならなくなった時、他の処理にも暗黙の裡に影響を及ぼしてしまいます。
まぁ、VSCodeを使っている方であれば、例えばそのメソッドがどこで呼び出されているかを確認するのも簡単なのでそこまで問題にならないと思うかもしれませんが、少なくともそのメソッドの中で利用シーンに基づいた場合分けの処理が必要になり、共通化の恩恵がなくなることは想定しやすいでしょう。
Open Closed Principle
これは、「拡張に対しては開いていて、修正に対しては閉じていなければならない」というものです。
もう少し具体的に言うと、新しい機能を追加する時、より簡単に機能を追加することができるけれども、その時に必要になる既存のコードの修正は少なくて済むように求める原則です。
「新しい機能を追加」するとき、よくできたプロダクトでは既存のコードに対してパラレルに実装できます。
認証システムにおいて、ワンタイムパスワードを送信する手段をSMSから電話やメールアドレスも選べるようにしたいとしましょう。
このとき、認証手段を呼び出す側が「SMSで認証する」という詳細に依存していると、認証を呼び出す側でも「電話で認証するメソッド」や「メールアドレスで認証するメソッド」が必要になってしまいます。しかし、「認証インターフェース」という抽象に依存していれば、「認証メソッド」の呼び出し部分は変わらず、コンポジションのところでなにを認証システムとして提供するかを差し替えるだけで可能です。
また、メールアドレス認証や電話認証の拡張は、SMS認証に関する実装になんら変更を要求しません。
Liskov Substitution Principle
この原則は「スーパータイプ(スーパークラス/基底クラス)はサブタイプ(サブクラス/派生クラス)と置換可能でなければならない」ことを要求しており、特に振る舞いまで同じでなければなりません。
クラスを継承するとき、派生クラスは基底クラスのメソッドなどを上書きすることができますが、その振る舞いを変えた場合そのメソッドを基底クラスのメソッドと同じように動作すると期待して呼び出すことができません。
しかし、派生クラスを参照する先からすればそんなことは知りようがないわけなので、不透明性が高くなるという点で問題です。
Interface Segregation Principle
インターフェース分離の原則は、依存するインターフェースはそれに依存するクラスに対応する程度の粒度であるべきというもので、継承の話から行くとインターフェースを継承するクラスはインターフェースに定義されたメソッドを使うようにするべきで、不必要なメソッドがあるならインタフェースから削除しようということです。
Dependency Inversion Principle
依存性逆転の法則です。これは前に言及しているので説明は省略します。
所感
オブジェクト指向プログラミングの文脈においては、LIDは特に抽象・インターフェースに関する言及になっているように思います。クラスを実装・参照する際の指針になっているとも解釈できるのではないでしょうか。
・DIP:「抽象を介して依存せよ」という“抽象への依存の原則”
・ISP:「適切な粒度で抽象を設計せよ」という“抽象の設計の原則”
・LSP:「抽象の契約を裏切るな」という“抽象の実装の原則”
この三つをまとめて言うならば、
「モジュールを介した参照はインターフェースを通じて行われるべきで、方針が詳細に依存しそうな場合などには逆転させなければならない(DIP)。インターフェースを設計する時はそれを継承するクラスがメソッドを余すことなく使える程度の粒度にするべきであり(ISP)、クラスでインターフェースを実装する時は、期待される振る舞いを逸脱しないように注意しなければならない(LSP)」
と言った感じでしょうか。
これらはクラスの設計に関する指針ですが、コンポーネントの設計に関する指針にも拡張されます。
特に、依存の方向性や抽象への依存という考え方はレイヤーの分け方や依存関係を考えるもとになっており、クリーンアーキテクチャーを構築するうえで最大の根拠となるところであると言えるでしょう。
5. コンポーネントの原則
なぜ、entityが最も中心に位置し、外側から中心に向かって依存するようにクリーンアーキテクチャーを設計しなければならないのでしょうか。それは、コンポーネントの結合に関する原則から導かれることになります。
- 非循環依存関係の原則(ADP):コンポーネントの依存グラフに循環依存があってはならない
- 安定依存の原則(SDP):安定的で変わりにくいものに依存すること
- 安定度・抽象度等価の原則:コンポーネントの抽象度はその安定度と同程度でなければならない
これらの三つを踏まえて考えると、
依存の方向性は一方校に向かうようにしなければならず、より安定的で抽象的なものはより多く依存されるべきであるので、抽象的なものを中心において依存されるようにするべきである、ということです。
これは、この記事のはじめの方で説明したレイヤーと依存の方向についての説明と同じであることに気づいてもらえると思います。
6. おわりに
このクリーンアーキテクチャーを論じた本は、そのアーキテクチャーの話に行くまでにだいぶ長く、また実装の際にテクニックを具体的にどういう風に使えばよいかという実例をあまり出してくれていなかったので、個人的には分かりにくさがありました。
レイヤーごとの配置や内側への依存さえ守れば一応のクリーンアーキテクチャーはできるわけで、クリーンアーキテクチャーの概要とその実装テクニックから説明を始めればとっつきやすかったろうになという思いから、このような構成で記事として整理することになりました。
ただ、ここまで整理してまだ6,7割程度しか十分に理解しきれていない感じがするので、何度か読み直していきたいと思いました。
書籍では前半に集められている諸原則の説明はやや端折り気味だったので、より詳しく知りたい人は一読することをお勧めします。