概要
ちょっと前に「画像認識でもConvolutionの代わりにAttentionが使われ始めたので、論文まとめ」という記事を書いたわりに、すでにAttentionでもなくてConvでもないけどImageNetでSOTA取ったぜっていう、新しい構造探索系の論文がICLRに出た。この頃、ちょっとバズっているので、概要をまとめてみたいと思う。
Lambda層という遠くまで見られるけど、軽いのを考えたよってのが、ポイントらしい。
LambdaNetworks: Modeling long-range Interactions without Attention
追記:reviewが終了し、ずいぶんと書き直されて、わかりやすくなりました! 図とPseudo-codeが得にありがたい!
まずは、ImageNetの結果。

速度vs精度グラフは、なかなかすごい。
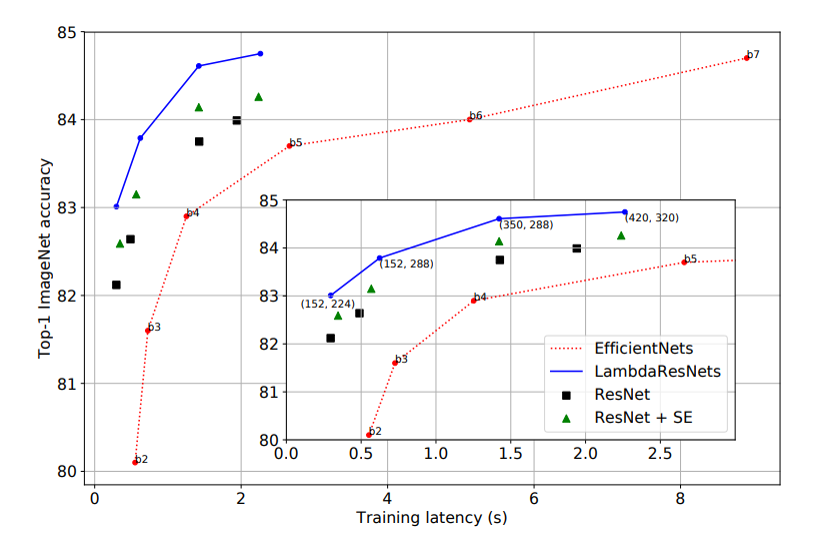
さすがに、この頃流行りのBiTやらViTなんかのマンモスネットワークと比べると精度では負けているけど、あっちは、データも増やしてFine Tuningとかしているので、比較対象としてはどうなんだろう。だいたい、ImageNetはデータの規模が足りなくてタグ付け間違ってるとか言い出しているし、ちょっと違う世界な気がする。
ResNet152が小さいネットワークでImageNetが中規模データセットになる時代がやってくるとは・・・。
手法
まず、Attention構造を、キャッチアップしてないよって人には、以下の記事をどうぞ。
画像認識屋さんのための「初めてのAttention」
今回のLambdaNetworkもAttentionの言葉を使って説明している。
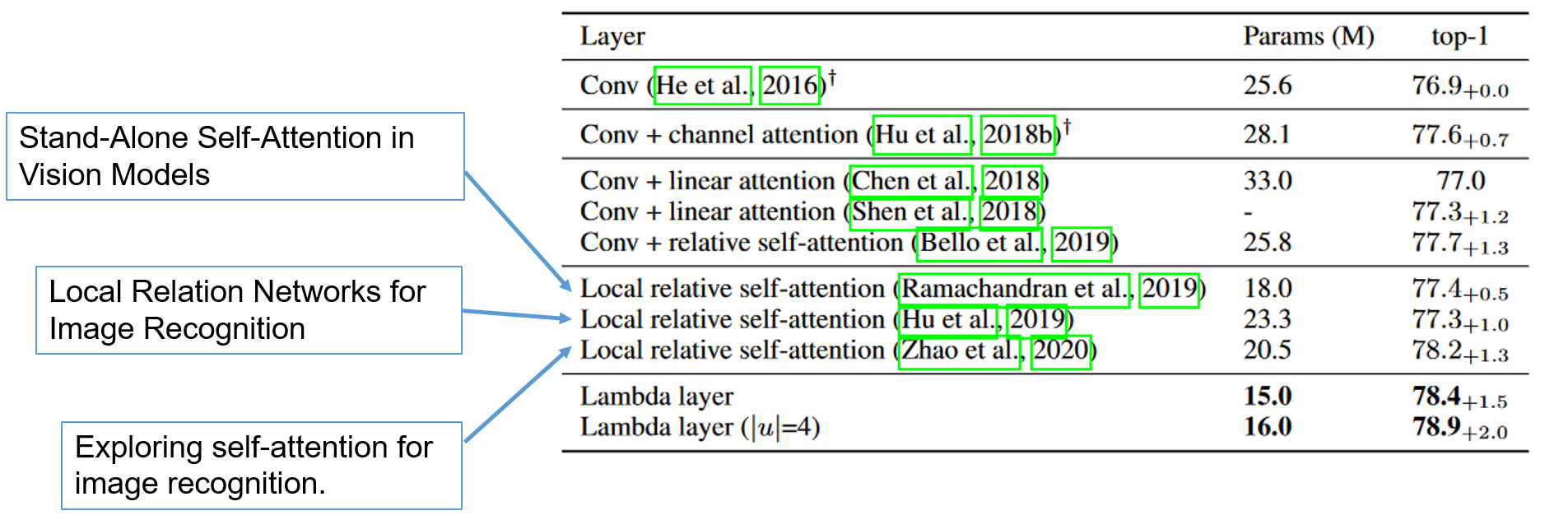
Attentionでは、あるポジション(ピクセル)が回りとどういうふうに関係するかを表すフィルターが入力に依存する。Convolutionのように全てのポジションで同じフィルターを使わず、全てのポジションに対してフィルターを作成するため、計算量とメモリ使用量が大きくなる問題が知られている。当然、これを小さくする方法はいろいろあって、レビュー論文もある。LambdaNetworkはそれらとは、根本的に違うネットワークであると主張。
LambdaNetworkでも、基本的なAttentionと同じように、フィルターを二つに分けて考える。
- content-based: SEネットのように、全体を見て、そこから、ポジションごとのフィルターを作る。Attentionで全体を見るような感じだけど、全ポジションで同じフィルターになるのが大きく違う。これで、計算量は大きく減る。
- position-based: Attention構造のPosition Encodingの部分にあたる。全てのポジションで、回りとどのように関係するかのFilterを持つ。Convのように、入力とは関係ないが、Convと違って、全てのポジションで同じフィルターを使うわけではない。
この2つを足し合わせたものがLambdaNetworkのAttention Map相当になる。
当然ながら、position-basedの方が計算量も多く、精度への貢献度も高い。また、Convと同じように、フィルターが入力に依存することはないため、バッチの中にある入力全て同じフィルターが使え、バッチのサイズにより学習中のメモリ使用量が増大することはない。
有名なAI解説YouTuberさんの説明を使って、データの流れを説明してみる。
入力画像は、$X \in \mathbb{R}^{n \times d}$。この$n$は$H \times W$の画像であれば、$n = H \times W$、$d$はdepth。カーネルサイズは、$m = k \times k$。ヘッドの数は$h$。
-
content-lambda $\lambda^c$: このcはコンテントを意味していて、添え字ではないのに注意。
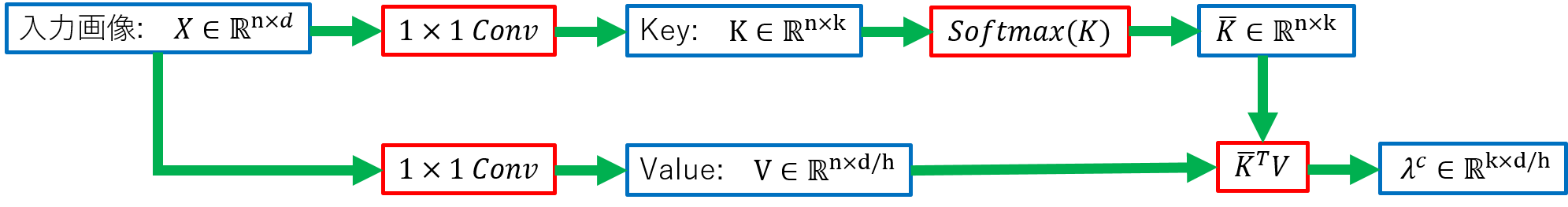
-
potision-lambda $\lambda^p_n$: pはポジションを意味する。nは添え字で、ポジションの位置を表す。

これらから$\lambda_n = \lambda^c + \lambda_n^p$が求まり、通常のAttentionと同じように求めたQueryと掛け合わせることで、$n$における出力が求まる。また、精度を上げるために、KeyとValueの次元を増やし大きくするパラメータ$\mu$がある。LambdaNetworkは、スマートに実装が出来るポイントがいくつかあるため、EfficientNetと比べるとパラメータ削減の規模よりも格段に速くなる。
論文では、今回説明したよりも、少し一般的な表記になっている。(そして、出来立てホヤホヤでわかりにくいので、著者のソースコードを確認した方が細かい点ははっきりすると思われる。)
ResNet-50を元にした、実験結果
Lambda層は、そのままConvの変わりに使えるので、ResNetを基準に、Convを置き換える。
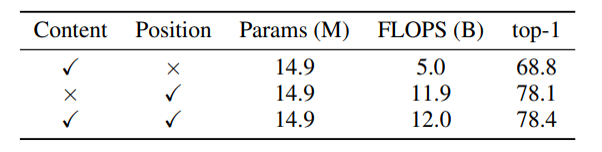
ConvをAttentionに置き換えるとパラメータ数が減り精度があがるとわかっている(細かいことは、こっちの記事を参照)。それと比べてみてもImageNetで良い結果が出ている。
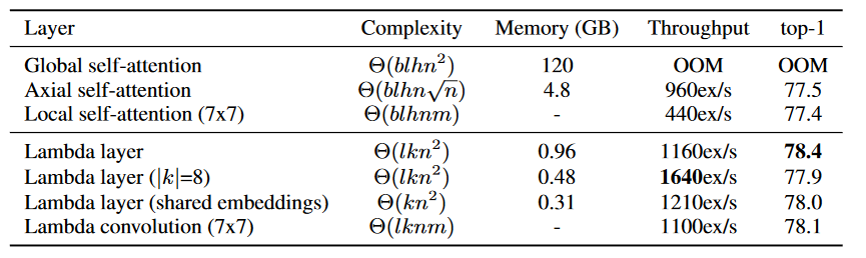
Lambda層は、精度も良いが、学習のThroughputも大幅に改善している。
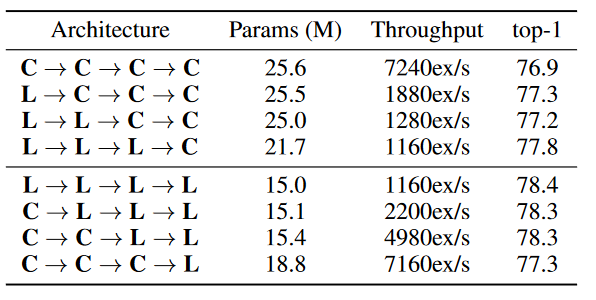
Convの実装は効率が良いので、学習を高速化させる場合は、Conv層を多くしたい。そこで、Lambda層とConv層を混ぜたハイブリッド方式を考える。ResNet50はConvの層をまとめたブロックが4つあるので、このブロックごとに、Conv層をLambda層と交換する。面白いことに、Lambda層を前よりも後の方に入れた方が良く、前の方にConv層があっても精度は変わらない。
まとめ
と、言うことで、またも新しい構造が現れた!
画像系にAttention構造がやってきたと思ったら、次から次へと出てくる。Attention構造の改造論文もいっぱいあるし、いったい、いつ落ち着くのだろう。とは言え、Conv層はやはり優秀なので、なんやかんやで組み合わさって残りそうな雰囲気なのが面白い。