概要
みんな大好きBatch normalization(BN)は、どういう原理でうまく行ってるのか、実はあまり良くわかっていない。2015年から使われ始めているから、そこにいて当然って感じだけど、別の手法で置き換えると精度が上がるとか、計算が簡単とか、何か良いことあるかもしれない。あと、この頃流行りの分散学習をBNつきでやると、一つずつのGPUに十分大きいサイズのサブバッチがないと精度が上がらないと知られている。ただ、バッチサイズが増えるとメモリの観点できついから、小さいバッチサイズでも上手くいくNormalizationないかな? ということで、探してみた。
原理がわかると、それに合わせて違うのを作れそうって、ことで、原理について調べている論文をまず見る。とはいえ、原理は置いといて、とりあえずやってみてうまく行けば良いので、山のようにある実験論文も少しあさってみる。
想定読者: Batch Normalizationは知ってるよっていう画像認識屋さん
Normalizationは自然言語だろうとGANだろうと何だろうと基本中の基本だけど、自分は画像認識くらいしかわからないので、画像認識向け。
原理とかどうでも、良いからオチは? って人におススメのNormalization
- ミニバッチ数1でOK: Group Normalization(GN) + Weight Standardization(WS)
- ミニバッチ数1でOKでActivation関数もいじる: Filter Response Normalization(FRN)
- 量子化のために計算の条件を上げたい場合は、$L_2$ Normじゃなくて、$L_1$ normを使う
詳しく見る論文リスト
元々BNが有効な理由と言われていたInternal Covariate Shift(ICS)を実験的に違いそうと示し、Loss landscapeが良くなっているのがBNのすごさじゃないかと、実験と理論的な証明で主張する論文。
How Does Batch Normalization Help Optimization? (MIT、2019年/4月)
BNはRegularizerなので、L2 Regularization(Weight Norm)との関係は、どうなんだろう? というところから、安定した計算をするため$L_2$ Normの代わりに$L_1$ normを使うことを主張する論文。
Norm matters: efficient and accurate normalization schemes in deep networks
(Technion, Intel, 2019年2月)
BNのRegularizerとSGDのRegularizerの関係を調べ、BNの有効性はLoss landscapeが良くなることによるのではないかと、実験と理論的な証明で主張する論文。
Understanding Batch Normalization (Cornell大学、2018年11月)
Loss landscapeを良くするという観点で、WeightをNormalizeしてActivationのNormalizerと組み合わせるWeight Standardization(WS)を考案した論文。
Micro-Batch Training with Batch-Channel Normalization and Weight Standardization
(Johns Hopkins大学、2020年8月)
ActivationのNormalize手法で、Normalizeするスペースを変更するという実験論文。
Local Context Normalization: Revisiting Local Normalization(テキサス大学 El Paso校、Microsoft、Georgia Tech、2020年5月)
Normalizationだけでなく、Activation関数も一緒に学習させることで、ミニバッチ数を減らしても学習できるようにした論文。
Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks(Google Research, 2020年4月)
人間が一々探すんじゃなくて、AutoMLでNormalizationとActivationの組み合わせを見つけちゃえば良いんじゃないの? っていう、金にモノを言わせた論文。
Evolving Normalization-Activation Layers(Google, 2020年7月)
How Does Batch Normalization Help Optimization? を読んでみる
BNを最初に言い出した論文では、BNはInternal Covariate Shift(ICS)が良くなるからだと主張している。ICSっていうのは、簡単に言うと、全層に対して入力のDistributionが変わってしまう現象のことを指す。
ところが、2018年のNeurIPSに
How Does Batch Normalization Help Optimization?
というのが出て、ICS仮説には、大きな疑問符が付いた。
この論文では、BNの後に毎回違うランダムな値を放り込んで、ICSをわざと悪くしてみて、それでもBNがない時よりも精度が良いという実証をしている。また、Lossの勾配から、ICSを計測する手法を考案し、計測したところBNがあってもなくても変わらない結果になった。
そこで、ICSは置いといて、BNは、Loss関数がsmoothになる(Weightがちょっと変わったら、Lossもちょっとしか変わらない。かっこ良く言うと、Loss関数のLipschitznessが良い)から、うまく行くのではないかと仮定して、Loss、Lossの勾配、Smoothnessを比較してみると、すべてにおいて、BNがある方がsmooth。実験の他に、この論文では、いろんな条件をつけて、BNを入れることによるLoss関数のSmoothnessについて、証明している。
新しいNormalization手法を探索する身として面白いのは、BNの効能を調べるために、BNの分散で割る部分をただの$L_p$ノルムに変更した実験。書き下すと、普通のBN
$$\hat{y} = \gamma \frac{y-\hat{\mu}}{C} + \beta$$
は、分散$C$の計算を以下のようにするが、
\hat{\mu} = \frac{1}{B} \, \sum^B_{i=1} y_i\\
C = \frac{1}{B} \, ||y-\hat{\mu} ||_2
この$C$を単なるLpに変更する。
C = ||y||_p = \Bigl(\frac{1}{B} \, \sum^B_{i = 1} |y_i|^p\Bigr)^{1/p}
実際、$L_1$, $L_2$, $L_\infty$を試してみたところ、
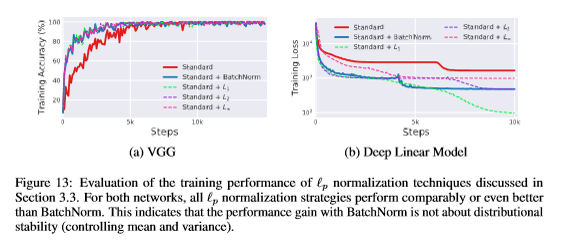
$L_p$ノルムに変えても同じ結果、なんなら良いぐらいな結果になっている。特に$L_1$が良い。
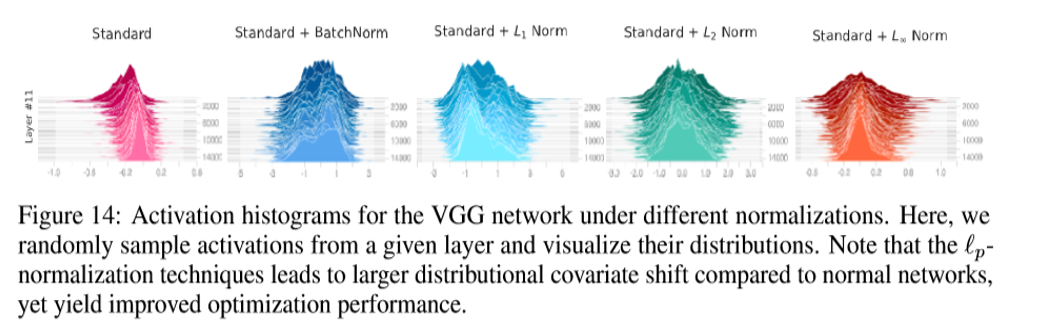
ただし、分散で割っているわけではないので、Activationの形はバラバラになり、ICS仮定はなんか変。Smoothnessの方は、BNと同じような結果になっている。
一応、メモとして書いておくと、この論文は、BNの仕組みを調べるために、ResNetのようなスキップコネクション(BNと同じような機能がある)は使っていない。
そもそも、Smooth loss landscapeで何がうれしいんだよ? とかそういうのは、難しくてよくわからないので、興味がある人は、何故かやったら詳しいWikipesiaへゴー。
Norm matters: efficient and accurate normalization schemes in deep networks を読んでみる
ここで、一度、元の論文に立ち返ると、BNはRegularizerになっていると言っている。ということで、ちょっとこっちからも見てみる。
まずは、復習
Generalization(汎化) Error
supervised learningにおいて、学習用サンプルから学習したい未知のサンプルを予測することによっておきるError
Regularization(正則化)
generalizeabilityを良くする手法。特にサンプルにノイズがのっている時に、Overfittingしやすくなるのをふせぐ
DNNにはRegularize手法がいろいろ入っているけど、それとBNの関係はどうなっているのだろう? というのは、気になるところ。
まず、その名もずばりL2 Regularization、またの名をWeight Decayについて。
Weightにあるスケールをかけた場合、BNがあると平均引いて、分散で割ることになるので、スケールは消えてしまう。まあ、BNに限ったことでもなく、Normalizationってのはそういうもんだってのはある。これを用いて、
L2 Regularization versus Batch and Weight Normalization(Radboud 大学、2017年6月)
で、Loss関数にL2 Regularizationがあると、weightの実際のLearning RateとWeightのスケールに相関がある
$$\Delta W_t \propto \frac{\alpha}{||W_t||^2_2}$$
と、示された。$\alpha$がLearning Rateで$\Delta W_t$がWeight $W$の、ミニバッチ$t$でのアップデート。Learning Rateが同じであっても、Weightのスケールが大きいと、実際のアップデートは小さくなる。これにより、exploding/vanishing gradientを抑えることができる。
これを拡張した論文が
Norm matters: efficient and accurate normalization schemes in deep networks
ここでは、細かい証明と実験を行っている。
また、Weightのスケールが変わらないことに着目し、同じようにスケール不変のNormalizationを考えてみる。特に、分散の計算をするにあたり2乗と平方根があるため、計算が不安定になるのを止めたい。そこでさっきのBNにある分散$C$を、以下の$L_p$ノルムに変更する$L_p$ BNを提案。
$$C = C_{Lp} \frac{1}{B}||y - \hat{\mu}||_p$$
この論文が出た頃は、ActivationはGaussian Distributionであるべきだと思われていたので、$C_{Lp}$は、それに合わせたちょうど良いDistributionになるよう選ばれていて、$C_{Lp}$の値は学習速度の観点で重要だと実験で示されている。とはいえ、初期値をGaussian Distributionにあわせて設定しているから、当然な気もする。
ResNet-18とResNet-50でImageNetを学習する(下図左)と$L_1$ BNは、元のBN($L_2$ BN)と同じ精度になり、$L_\infty$ BNでは、計算は速くなるけど、Noiseに弱くて精度が悪い。
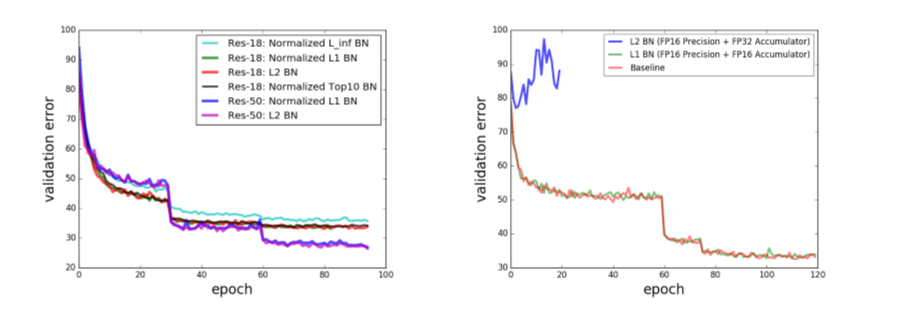
ここで、面白いのは、実際に$L_1$ BNの安定性を見せるために、ResNet-18の量子化をImageNetで学習している実験(上図右)で、$L_2$ BNでは、FP16で学習ができないが、$L_1$ BNでは、問題なく出来ている。大きい値のみ$k$個だけ使うTop(k)手法の方が計算面では安定していて、上図左にあるように、k=10で$L_2$ BN程度に精度は戻っている。
ちなみに、$L_2$ BNの計算が不安定なのは知られている問題で、$L_1$ BNで安定化させるという実験論文は前に出ている。
さて、BNに関しての実験でうまく行ったので、これをWeight Normalization(WN)にも拡張する。WNは、Weight $W$のスケール $g$ と向きを分けて学習する下記の手法で、ActivationではなくWeightをNormalizeする。
$$\hat{W} = g , \frac{W}{||W||}$$
BNほどの人気はないし、精度もそこまで良くないけど、Normalizationと言えば必ず出てくる手法。似たのにCentered Weight Normalization(CWN)っていうのもある。これも、NormalizationをWeightに対して、平均を引いた後にするけど、スケールはActivationに対して学習する。
$$\hat{y} = \gamma , \frac{W-\bar{W}}{||W-\bar{W}||} x + \beta$$
話を元に戻して、Weightのスケールを変えたくないので、WNの$g$を固定する。これにより、元のWNよりも精度が上がった。
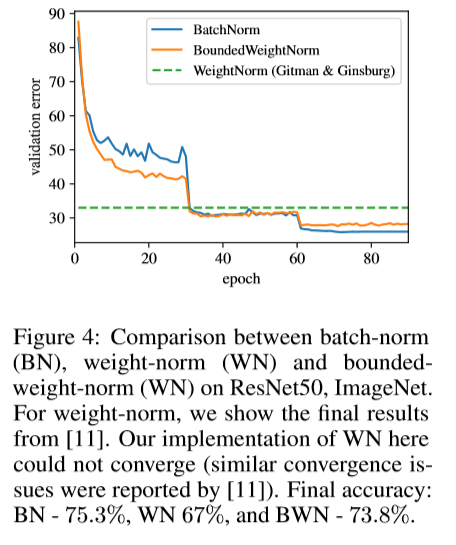
また、$L_2$ Normを$L_1$と$L_\infty$ Normに置き換えると$L_1$は$L_2$の代わりになるが、$L_\infty$は大幅に精度が下がった。
Understanding Batch Normalizationを読んでみる
次に、SGDのRegularizationについてみてみるために、NeurIPS2018で発表された
Understanding Batch Normalization
をみてみる。
まず、BNを使うと大きなLearning Rateが取れることに着目し、小さなLearning RateのままでBNを使って学習したらどうなるか調べてみた。
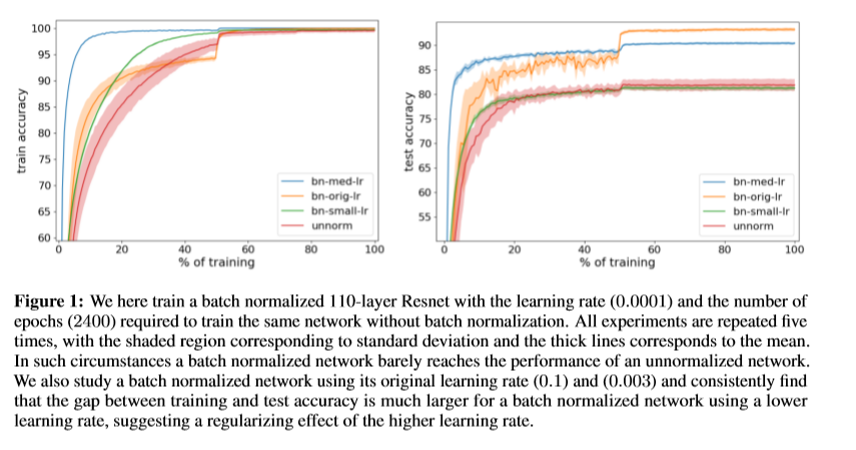
これは、なかなかびっくりな結果で、BNがあってもLerning Rateが小さいと学習できていない。これを説明するために、SGDによるErrorに注目してみる。SGDは、学習データを全部使わず、ミニバッチを使うため、全部のデータを使う場合と比べてErrorが出る。このErrorがRegularizerだと言われているので、これをBoundしてみると、
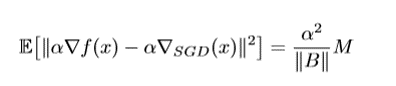
$M$はconstant,$\alpha$はLearning rate,$||B||$はミニバッチ数。$||B||$が大きくなりすぎるとSGDのErrorが小さくなりGeneralizationが悪くなる。これは、この頃、分散学習の人たちがミニバッチ数が大きすぎると精度が悪くなると言っているのと合致する。このBoundにより、Learning Rateを大きくすると大きなSGDエラーが取れるので、Generalizeしやすいと考えられる。
では、BNがあると、何故Learning Rateを大きく出来るのか? という話になり、これまたloss landscapeをlossの勾配方向に調べてみた。
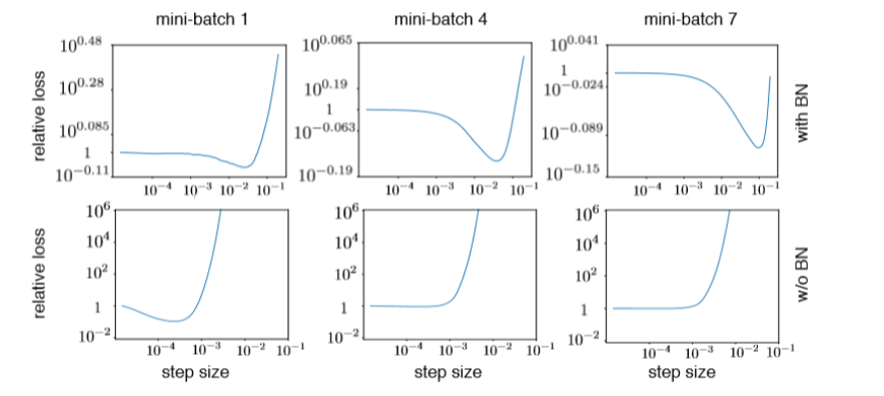
ここで言う、relative lossというのは、ちょっとWeightを動かした時のLossを元のLossで割ったもの。明らかにBNがないとLossはすぐに発散してしまう。ただ、初期値で発散しないようにセットしているわけで、何で発散するんよ? ということになるので、Theoreticalに確認すると、初期値だけでは条件が弱すぎると主張している。
とは言え、初期を頑張ればBNもスキップコネクションもいらなくなるとMean field theory系の人たちは言っているんで、いろんなものが絡み合っているんだと思われる。
Micro-Batch Training with Batch-Channel Normalization and Weight Standardization を読んでみる。
そんなわけで、BNはLoss landscapeを良くしているらしいということが分かって来たので、これを使って良いNormalizationを作ろうというのが、これ。
Micro-Batch Training with Batch-Channel Normalization and Weight Standardization
その前にちょっと復習。
BNは、ActivationをNormalizeするので、この時にNormalizeするスペースを変えようっていうのは前からある。この話をする時、必ず出てくるGroup Normalization(GN)の論文に出てくる図がわかりやすい。
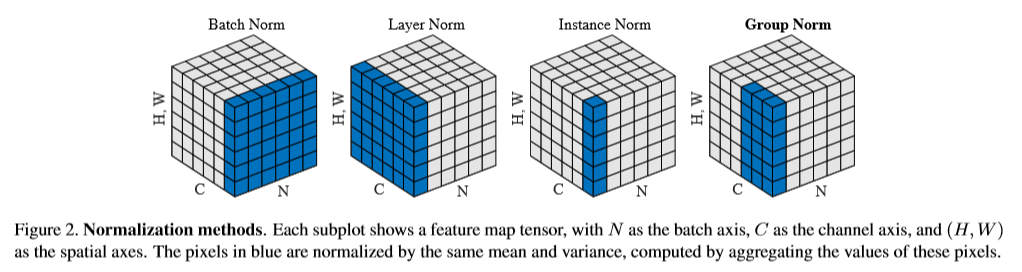
チャンネルがC、バッチサイズがN、絵がHxWとして、どこを集めてNormalizeしてあるかが図示されている。自然言語なんかの順番が重要な情報でバッチが使えない場合はLayer Normalizationを使うらしい。画像では、絵の中の情報が場所によって違う意味を持つため、まとめるとうまく行かないので、Instance NormalizationやGroup Normalization(GN)を使う。バッチサイズを減らしたい時は、GNを使うのが、普通だが大きいサイズのBNに精度では劣っている。また、いろいろあるNormalizationを学習で選んで使うSwitchable normalization(SN)というのもある。この論文の図もわかりやすい。
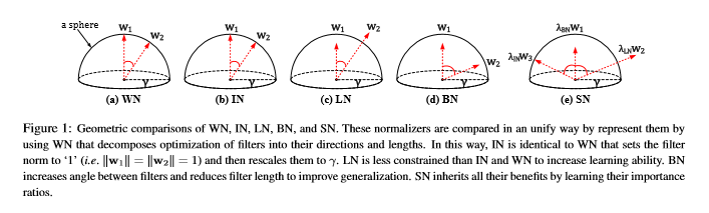
さっき説明したWeight Normalization(WN)は、ActivationではなくWeightの方をNormalizeしているので、両者は一緒に使える。
この論文では、これを利用して、WeightをチャンネルごとにNormalizeするWeight Standardization(WS)をActivationのNormalizationと組み合わせて使う。WSでは、スケーリングする前に平均を引き、スケールは固定で1、チャンネルごとにNormalizeする。ちなみに、Centered Weight Normalization(CWN)では、Weight全体をNormalizeする。WSはloss landscapeがsmoothになると証明している。あと、Singularityがなくなるとか、なんとかも言っているけど、これまたDynamicsの話で、難しくて自分にはさっぱり。
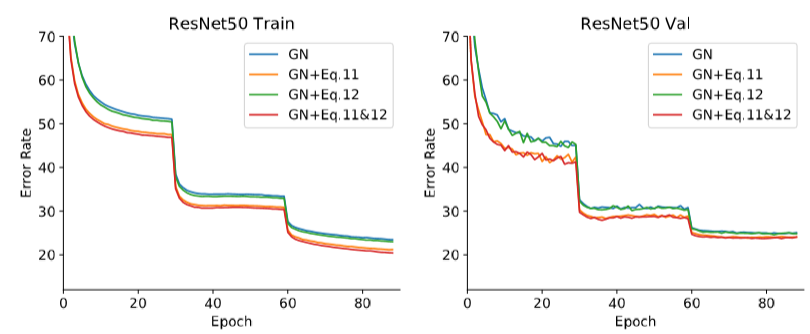
ResNet-50でImageNetを学習する実験(下図)では、GNと組み合わせることで、平均を引く(Eq.11)方が分散で割る(Eq.12)よりも意味がありそう。Inference時は、分散の意味があるのか謎。
このWSをActivationのNormalizationと一緒にやると、精度も上がっている。
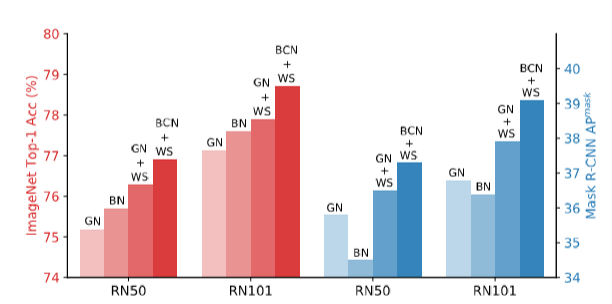
このBCNとは、BNをした後にGNをバッチ方向も含めて行うNormalization。ResNet50のBNとBCN+WSは64/GPUバッチで、ResNet101では、32/GPUバッチ。GNとGN+WSでは1/GPU。GPUは全部で4台。
WSの便利さは流行るんじゃないかと思う。
実際、やたらと大きいネットワークを使うBig Transferでは、BNではなくGN+WSが使われている。
Local Context Normalization: Revisiting Local Normalization を読んでみる
ActivationのNormalizationにおいて、Spacialにある程度Localに見るという手法も提案されている。
Local Context Normalization: Revisiting Local Normalization
この手法は、Layer/Group/Instance Normのように、バッチごとにNormalizationを行うが、SpacialにLocalな部分のみでNormalizeする。下図がわかりやすい。
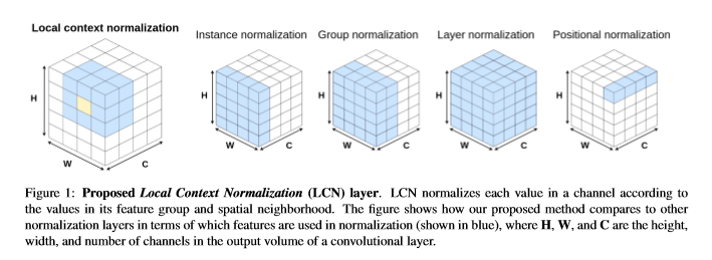
普通に計算をすると大変なので、効率的に計算するためにdilated convなんかを使うらしい。
Localで見ることができるために、CityscapesのSemantic Segmentationや、COCOのObject DetectionとInstance Segmentationでは、精度が向上した。ImageNetは全体を使うタスクのため、GNとほぼ同じ結果になっている。
Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks を読んでみる
NormalizationだけではなくActivation関数も学習させて、この組み合わせで、バッチサイズが少なくとも精度が良いという論文も出てきた。
Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks
この論文では、下図の新しいNormalization FRNとActivation関数 TLUを提案
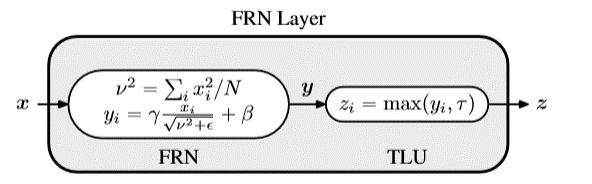
NはSpacialにH x W全部のデータを取るので、チャンネルごと、バッチごと(instance normalizationと同じ)にNormalizeすることになる。TLUは、ReLUの折り返し地点が変わる感じで、
$$max(\vec{y}, \tau) = ReLU(\vec{y}-\tau) + \tau $$
とも書ける。学習するのは、この$\tau$。FRNのバイアス項だけじゃダメっていうのは面白い。
ResNetV2-50でImageNetを学習した結果
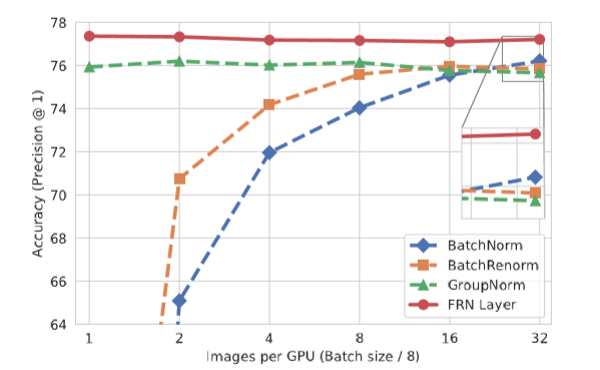
なかなかすごい結果だけど学習がちょっとトリッキー。
まず、Learning Rateのスケジューリングはstep decayは良くなくて、Continuousな方(restartなしのcosine decayとか)が良い。Warm-upはした方が良い。途中のLayerで1x1のActivation mapになる(fully connected layerとかの)場合は、FRNの$\epsilon$を学習する。その際、必ず正にするため$\epsilon = 10^{-6} + |\epsilon_l|$として、$\epsilon_l$を学習する。
Classificationだけでなく、Object Detectionでも良い結果になってるし、ライブラリーに組み込まれれば流行る可能性は十分あるんじゃないかと。
Evolving Normalization-Activation Layers を読んでみる
この頃、AutoMLでネットワーク自体を学習で作ってしまおうというのが増えてきているが、NormalizationとActivation関数だって学習で作れるんじゃないかというのが以下。
Evolving Normalization-Activation Layers
いろんなオペレーションをグラフ構造で組み合わせ、遺伝的アルゴリズムで、ちょうど良いのを作り上げる。出来たものの例が下図。
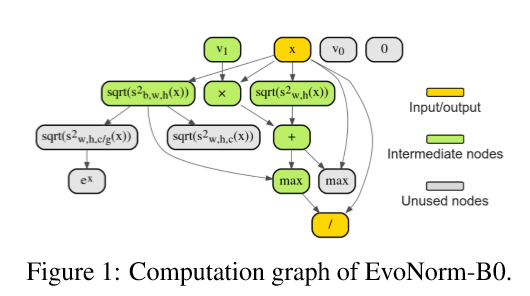
とはいえ、ネットワーク・データごとにこれをやると言うのは、なかなか厳しいんじゃないかと。これで、UniversalなNormalizationが出来たというわけでもないようだし。
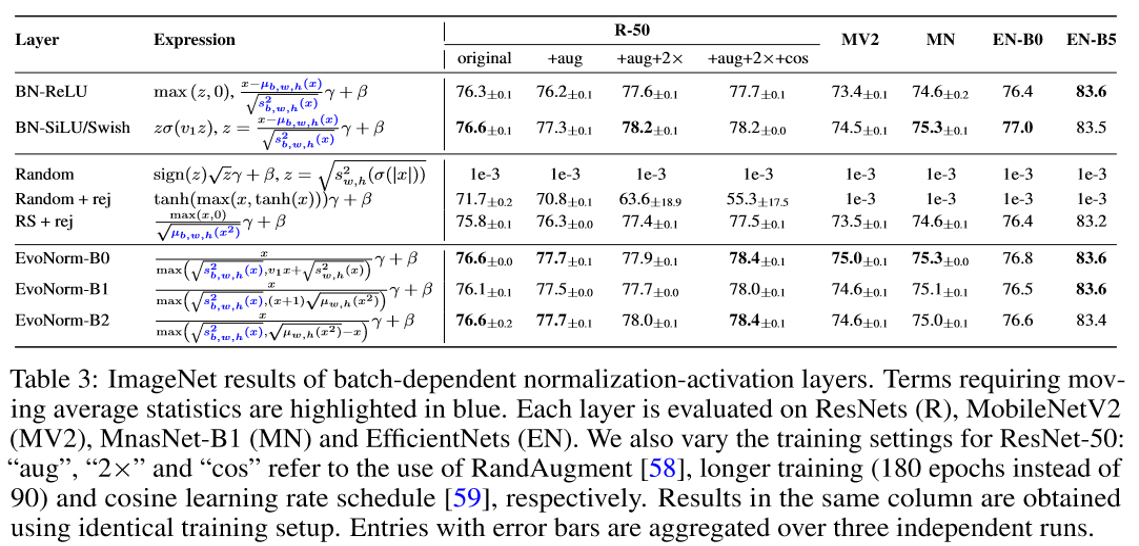
このテーブルのEfficientNet(EN)はBNとAutoMLで見つけたReLUに近いSwishを使って、AutoMLで作られたネットワークで、これだと、新しいNormalizationとActivation関数に代えても精度は上がっていないように見える。
それにしても、この量の実験結果を公開してくれるのはすごい。ここから、新しいNormalizationのヒントが見つかるかもしれない。
まとめ
BNは、便利なので、この頃のネットワークには特に何も考えずに入れてあるものの、ある時シレっと別のに置き換わっているかもしれない。
Normalizationには他にもいろいろ。以下のまとめが参考になる。
Batch Normalizationとその派生の整理