自分のブログの転載記事です。
TL;DR
User-Agentの設定に気をつけないと、Google検索結果のスクレイピングがうまくいかないかもしれません、というお話です。
ついでに、Google検索結果のスクレイピングはグレーっぽいというお話です。
やってみて失敗したこと
Googleの検索結果をスクレイピングするなら、あなたはどのようなコードを書くでしょうか。
私はこんな感じで書きます。
search_url = "https://www.google.co.jp/search?hl=jp&gl=JP&"
query = URI.encode_www_form(q: "日本M&Aセンター")
search_url += query
charset = nil
html = open(search_url) do |f|
charset = f.charset
f.read
end
doc = Nokogiri::HTML.parse(html, nil, charset)
人によって細かい違いはあるかもしれませんが、上記はごく普通のNokogiriでのスクレイピングだと思います。
ここから、最初の検索結果に現れたサイトのURLを取得したいとします。
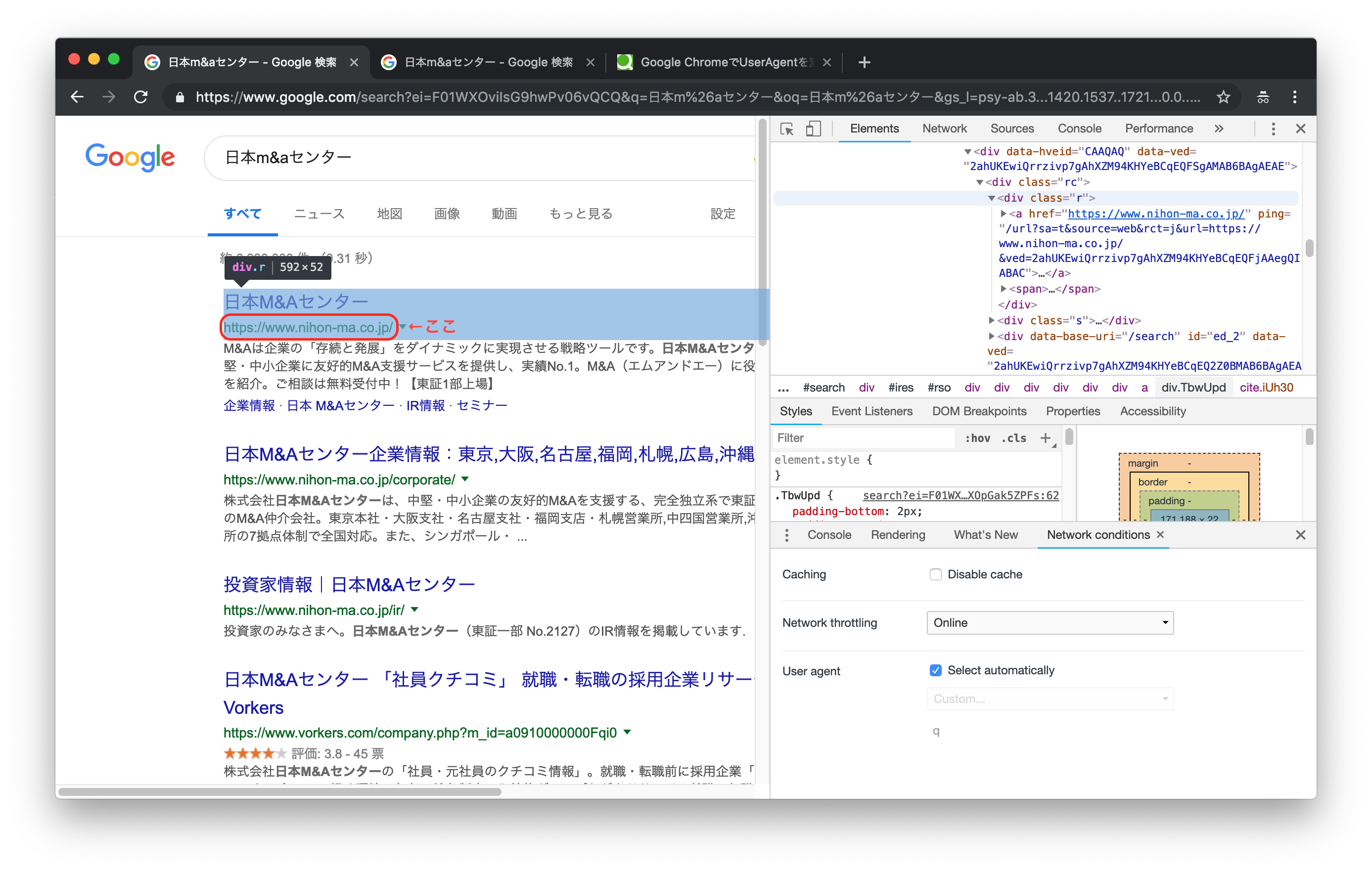
xpathでの指定が簡単そうでしたので、要素のxpathを指定し、そこからリンクテキストをスクレイピングするとします。
link = doc.xpath('//div[@class="r"]/a')
link[0].attribute('href').text
そうすると、変数linkには何が入っているでしょうか。
puts link
=> nil
何も入っていません。何故でしょう。
結論から言うと、xpathの指定が間違っているからです。
そしてなぜxpathが間違っているのかというと、User-Agentを指定していないからなのです。
User-Agentの検証
実際に検証してみましょう。
まずはUser-Agentの設定を何も変えずに検索してみます。
(User-Agent設定はChromeのdeveloper toolから見られます)
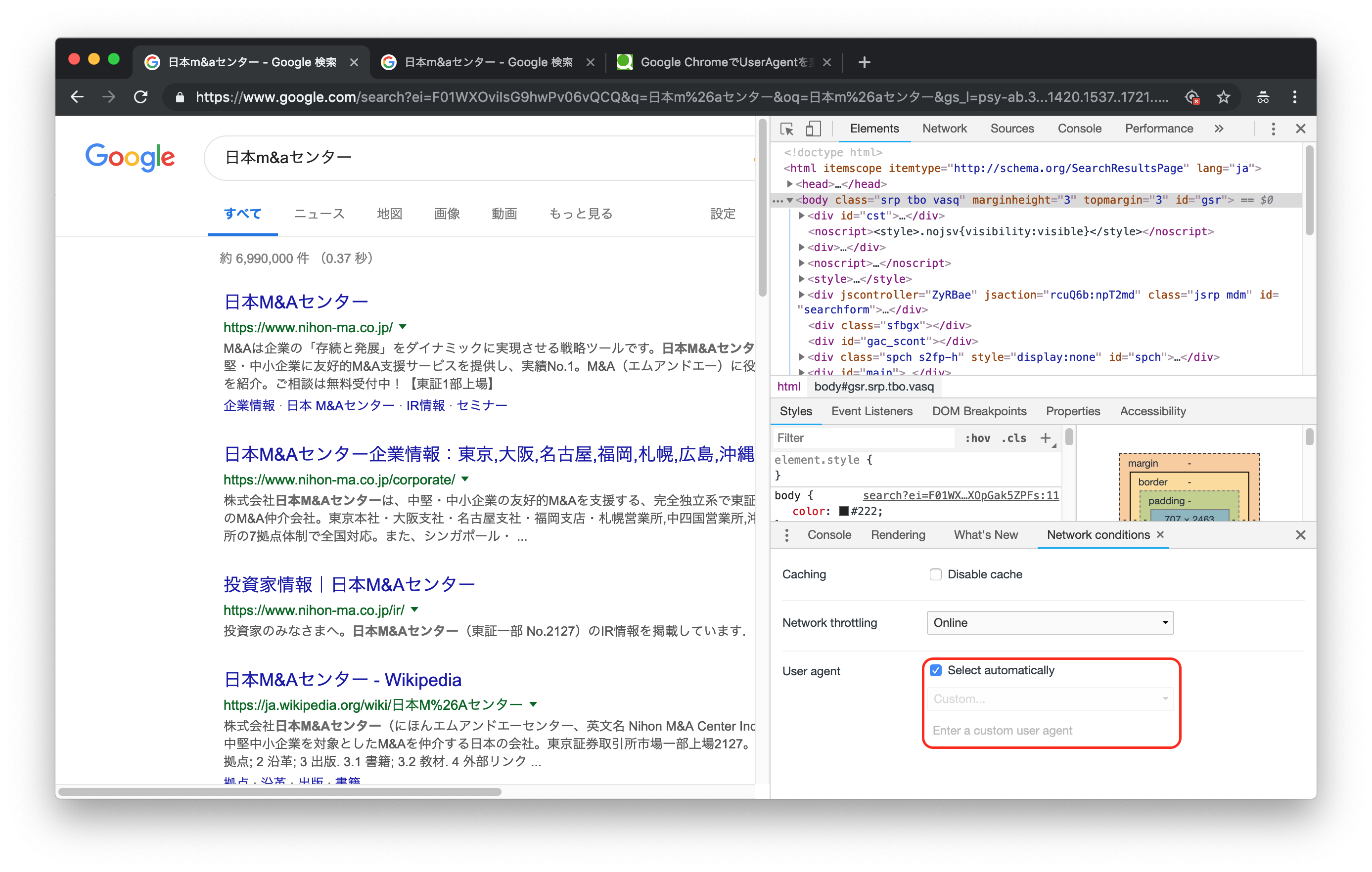
この場合、自分の環境ではUser-Agentは以下のような設定になっています。
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36"
では次にUser-Agentに意味のない文字を設定して、同じ画面を表示してみます。
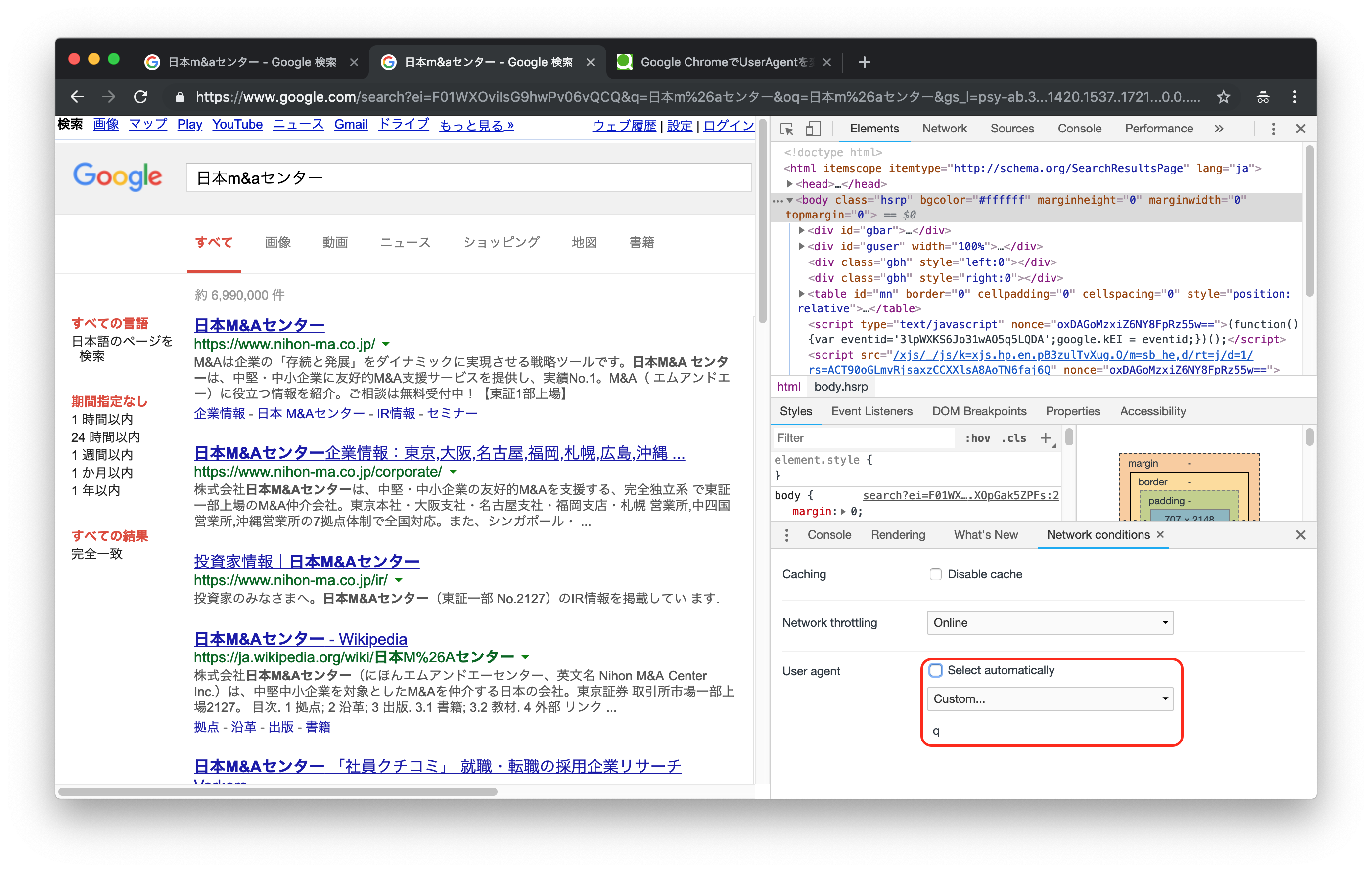
検索結果の画面が変わったことがわかるでしょうか。
表示されている内容が大きく変わったわけではありませんが、レイアウトやスタイルが変更されています。
これがUser-Agentを設定せずにGoogle検索をおこなった場合のレスポンス、というわけです。
この状態でもスクレイピングは可能なのですが、要素のxpathが変わってしまうため、Chromeを見ながらスクレイピングするということがやりにくく、非常に開発がしづらくなってしまいます。
対策
対策としては、User-Agentを明示的に設定してあげればよいです。
というわけで修正したソースコードがこちら。
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36"
search_url = "https://www.google.co.jp/search?hl=jp&gl=JP&"
query = URI.encode_www_form(q: "日本M&Aセンター")
search_url += query
charset = nil
html = open(search_url, 'User-Agent' => user_agent) do |f|
charset = f.charset
f.read
end
doc = Nokogiri::HTML.parse(html, nil, charset)
link = doc.xpath('//div[@class="r"]/a')
link[0].attribute('href').text
これで、自分の使用しているChrome環境と同じレスポンスを取得できるようになります。
スクレイピングのマナーとしてもUser-Agentは設定するべきですので、良いことづくめですね。
余談
ちなみにGoogleの検索結果をスクレイピングするにあたっていろいろ調べたのですが、Googleは検索結果のスクレイピングを認めていないようですね。
robots.txtにも、以下の記載がありますので。
User-agent: *
Disallow: /search
とはいっても、実際はある程度黙認されているようです。
何にせよ、スクレイピングは自己責任で行うべきですね。