こちらの投稿は2025 Japan AWS Jr.Championsの有志メンバーで作成した『30日間で主要AWSサービスを構築できるようになる』をテーマにした初学者向けのハンズオン問題集のDAY16になります!
問題集の趣旨や作成に至るまでの経緯は以下の記事をご覧いただければと思います。
https://qiita.com/satosato_kozakana/items/446971c2deca7e27d0aa
📝 概要
| 項目 | 内容 |
|---|---|
| 所要時間 | 30分-1時間 |
| メインサービス | AWS Glue, Amazon Athena |
| 学べること | S3に置いたデータを AWS Glue crawlerとAthenaを使ってクエリで検索できるようになる流れ |
| 想定費用 | 約20円(※データサイズや実行回数により変動します |
⚠️ 参考:リソースの課金体系については以下を参照ください。
🎯 課題内容
Amazon S3 に配置した約11万件のcsv(カンマ区切り)形式のレビューデータを、AWS Glue を使ってデータ構造を自動で認識させ、Amazon Athena から標準的なSQLでクエリできるようにします。
この一連の流れは、サーバーレスでデータ分析基盤を構築する際の基本的なステップとなります。
📊 アーキテクチャ図
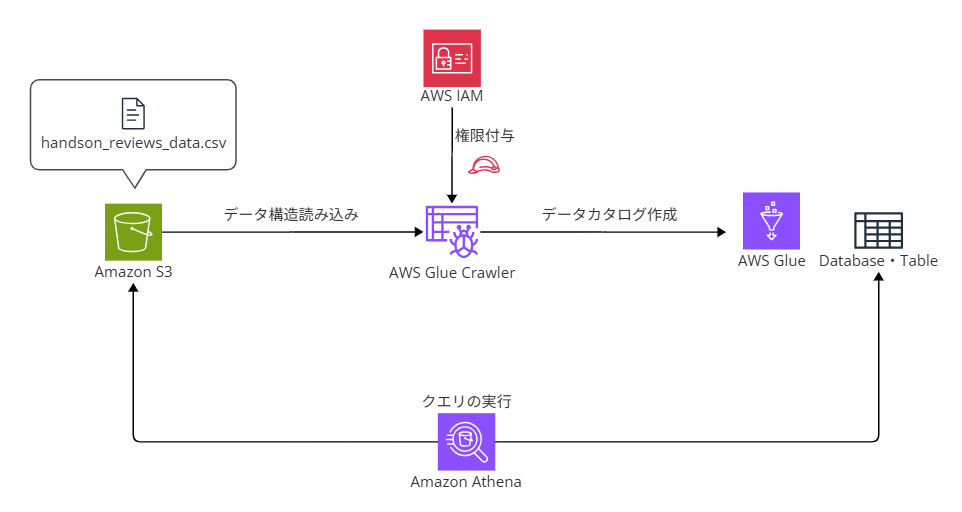
🔧 実装機能
- S3バケットにサンプルデータ(csvファイル)をアップロードする。
- AWS Glue のCrawlerを実行し、S3上データのスキーマを自動で検出・登録してデータカタログのメタデータテーブルを作成する。
- Amazon Athena のクエリエディタから、登録されたデータに対してSQLクエリを実行する。
💡 実装のヒント
Glue Crawlerについて
S3に置いたデータをSQLでクエリできるようになるためには、まずAWS Glue側でそのデータ構造(何の項目があるのか、その項目のデータ型は何なのかなど)を把握してもらう必要があります。AWS Glueはそのメタデータをカタログ化してもっておくことが出来ます。
また、Crawlerを使えばデータソースを自動で読み取り、自動である程度のスキーマ情報を検出・Glueに保持してくれます。
Glue Crawlerを使わない方法
実は、Glue Crawlerを使わないで、自分でクエリを書いてメタデータを設定する方法もあります。今回の問題のテーマとは少しずれますが、厳密にスキーマが決まっている場合、データ形式(特にIDなど)が勝手に想定外のものに変わるなどを避けたい場合はそちらを使うのも選択肢です。
SQL文自体の種類(DML、DDL、DCLなど)も調べると勉強になります。
SQL・Athenaについて
SQLは、データベースを操作するための言語である「構造化問い合わせ言語(Structured Query Language)」の略称です。データベースに保存されたデータを検索、追加、更新、削除するなどの指示を出すために使用されます。Glueのカタログ化されたデータは、Amazon Athena、Amazon EMR、Amazon Redshift SpectrumなどのサービスからSQLで検索・クエリ(問い合わせ)できます。
この中で最も気軽に使えるのが、サーバレスで課金体系がスキャンされたデータ量に応じており、「使った分だけ課金」のAmazon Athenaです。
Athena のクエリ結果保存場所
Amazon Athena は、実行したクエリの結果を S3 バケットに保存します。初めて Athena を使う際には、この結果保存用のS3バケットを指定する必要があります。データソース用のバケットとは別に、結果保存用のバケットやフォルダを事前に作成しておくとスムーズです。
ちなみに「ワークグループ」というものを設定することで、このクエリ結果の保存場所やクエリのデータ量制限をチームごとに分けることもできます。チーム開発や複数のシステムを1アカウントで扱う際などに便利なので、余裕があれば試してみてくださいね。(参考)
✅ 完成後のチェックポイント
- サンプルデータ(CSVファイル)がS3バケットにアップロードされている
- AWS Glue Crawlerの実行が成功し、データテーブルの中にデータスキーマが確認できる
- AWS Glue のデータカタログ、および Amazon Athena のテーブル一覧に、S3データに対応するテーブルが表示される
-
Athenaで
SELECT * FROM "データベース名"."テーブル名" LIMIT 10;のような基本的なクエリが成功し、結果が表示される -
Athenaで
GROUP BYやCOUNTなどの集計クエリが正しく実行できる(サンプルデータを使う方は、「製品カテゴリごとの平均スター評価を集計」するクエリに挑戦してみてください)
🧰 使用資材
サンプルデータ(オリジナルで作成しても良いですが、こちらのサンプルを使用しても構いません。)
こちらのリンク先のデータをダウンロード・解答し、handson_reviews_data.csv という名前のcsvファイルをS3にアップロードして使用してください。
※これはカンマ区切りファイル(CSV)です。以下は参考として2件のデータを出していますが、実際にはヘッダーを含め約11万件のデータが含まれています。
marketplace,customer_id,gender,age,review_id,product_id,product_parent,product_title,product_category,star_rating,helpful_votes,total_votes,vine,verified_purchase,review_headline,review_body,review_date
JP,41127453,W,28,R33GT1L31ALWI5,B002TUEW1W,840963902,ソニックワークス 電気ケトル 軽量コンパクト設計,Video DVD,5,12,13,N,N,使いやすさに感動しました,長年愛用していた前のモデルから買い替えました。バッテリー持ちも良く、操作性も向上していて大満足です。特に指紋認証の反応速度が速くなったのが嬉しいポイントです。,2006/3/23
JP,41127453,W,28,RS0KVGYGZC1H9,B001BNIKW0,694858098,エコプラス 炭酸水メーカー 業界最小クラス,Video DVD,5,0,5,N,N,バッテリーが一日中持つ,初期設定がとにかく簡単!シンプルなUIで直感的に操作でき、機械に不慣れな自分でもすぐに使いこなせました。アプリとの連携もスムーズで快適です。,2010/10/14
🔗 リファレンスリンク
🛠️ 解答・構築手順(クリックで開く)
解答例と構築手順を見る
※本資料作成時からUIが変わることもよくあるので、変更時は読み替えてください✅ ステップ1:S3バケットの作成とデータアップロード
まずはデータの参照元となるストレージまたはデータベースを用意する必要があります。安価なAmazon S3は大規模データ分析基盤のファーストステップとして優れています。
- AWS マネジメントコンソールで「S3」を開きます。
-
「バケットを作成」 をクリックし、一意のバケット名(例:
handson-reviews-data-<アカウントID>-<日付>)を入力してバケットを作成します。バケット名以外はデフォルト設定で構いません。 - バケット一覧から作成したバケットを選択し、「オブジェクト」タブ内の「フォルダの作成」からデータを保存するためのフォルダ(例:
reviews/)を作成します。

- 「🧰 使用資材」のリンクから
handson_reviews_data.csvをダウンロードし、作成したreviews/フォルダ内にアップロードします。(reviews配下に移動 > 「アップロード」 > 「ファイルを追加」 > 選択 > 「アップロード」)

- 同様に、今までAthenaを使ったことがない、または必要だと判断した場合はAthenaのクエリ結果を保存するためのバケットも作成しておきます。(例:
my-athena-results-202510-handson)
✅ ステップ2:AWS Glue Crawlerの作成と実行
S3にデータがあるだけでは、参照もしにくく、クエリで任意の値を検索することもできません。検索基盤を作るうえで、まずはAWS側で「そのS3にどんな形のデータが入っているのか」のメタデータを読み込ませる必要があります。
- AWS マネジメントコンソールで「AWS Glue」を開きます。
- 左側のメニューから 「Data Catalog」配下にある 「Crawlers」 を選択し、「Create crawler」 をクリックします。

- 「Name」欄に任意のCrawler名(例:
handson-reviews-data-crawler)を入力します。「Next」で次へ進みます。 - 「Data source configuration」>「Add a data source」をクリックし、データソースとして、ステップ1でデータをアップロードしたS3パス (
s3://<バケット名>/reviews/) を指定します。なお、もしバケット全体を指定したい場合、s3://<バケット名>ではなくs3://<バケット名>/と入力する必要があります。最後のスラッシュに注意してください。
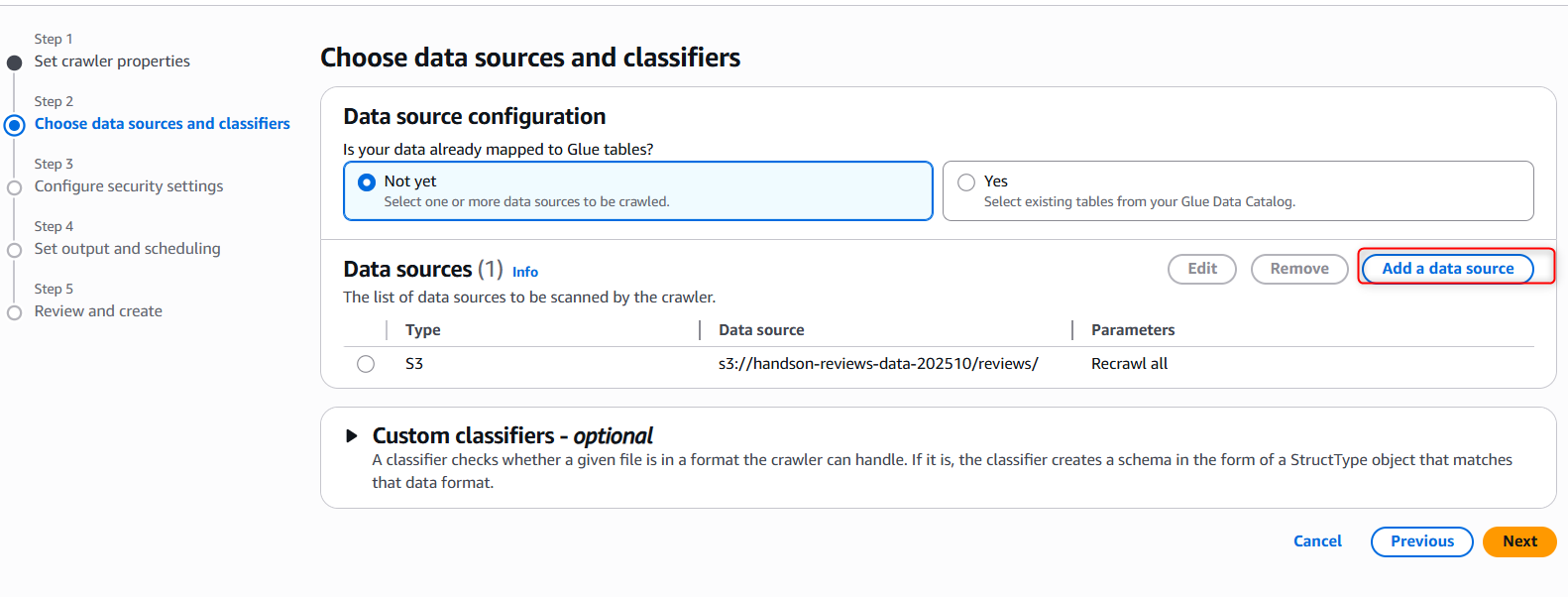

-
IAMロールでは、「Create new IAM role」を選択し、「Enter new IAM role」内に任意のロール名(例:
AWSGlueServiceRole-handson-202510)を指定・「Create」を押下します。これにより、Crawlerが必要なS3アクセス権限を持つようになります。 -
出力先として、Target databaseの欄で「Add Database」をクリックします。新たなタブが立ち上がるので、そこで新しいデータベース(例:
handson-reviews_db)を作成します。Crawler作成タブに戻り、作ったデータベース名を選択して先に進みます。

- 設定内容を確認し、「Create crawler」をクリックします。

- 作成後の画面(または作成したCrawlerを選択して移行する画面)にて、 「Run crawler」 を実行します。
- 実行が完了し、
StateがRunningからReadyになると完了です。「Crawler runs」タブ右上の「View run details」を見てみてください。Tables addedが1になれば成功です。Crawlerは自動的にファイルがcsv形式であることを検出します。
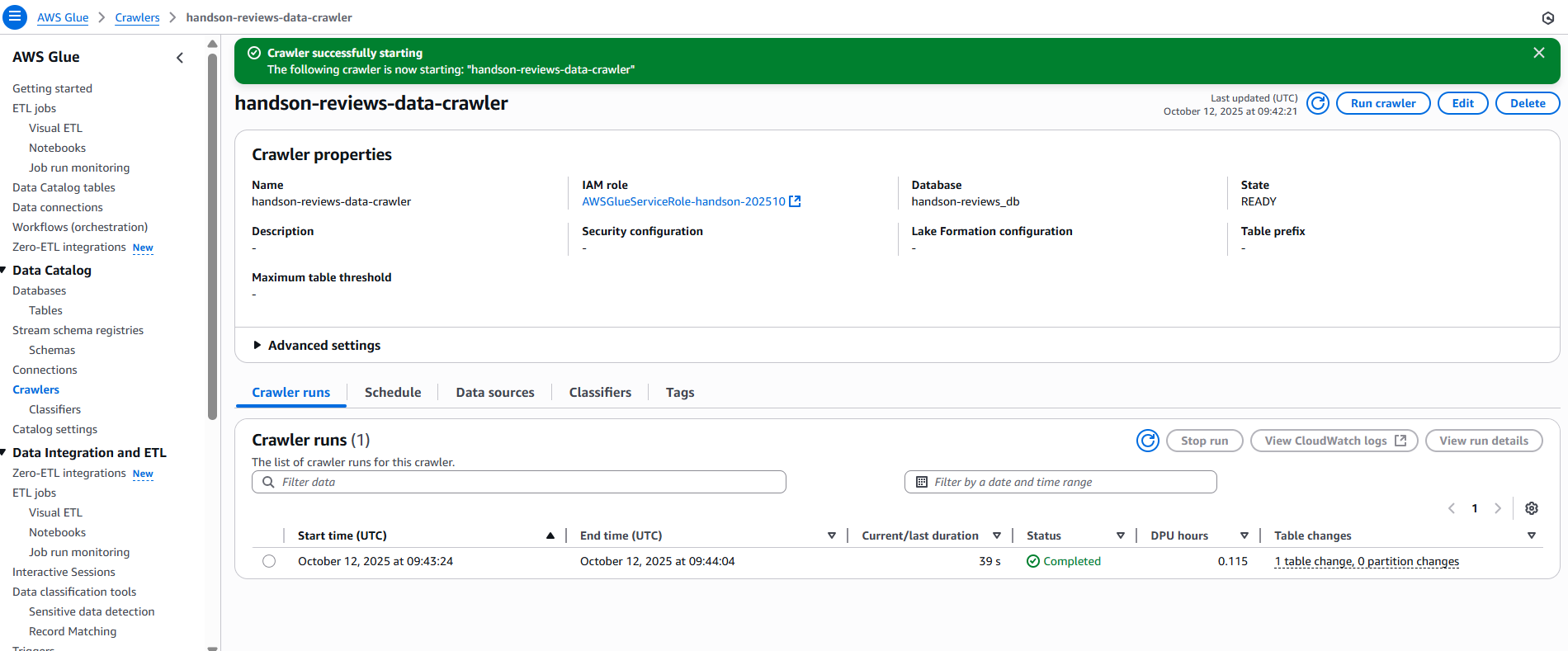

- 余裕があれば、作成したDatabasesの中のTables(例: reviews)を選択肢、中のスキーマを確認してみてください。思っているスキーマと違っていたら、ここで「Edit Schema」から変更可能です。

✅ ステップ3:Amazon Athenaでのクエリ実行
ステップでデータベースとCrawlerによるメタデータ取得ができたので、S3に置いたデータをAthenaでクエリできるようになりました。いよいよ実際にSQLを使ってデータを検索してみましょう。
- AWS マネジメントコンソールで「Amazon Athena」を開きます。
- 初めて使用する場合は、まずクエリ結果の場所を設定します。左ペインから「クエリエディタ」>上のタブで「設定」を選択し、「管理」ボタンからでステップ1で作成した結果保存用のS3バケットを指定して保存を押します。

- 「エディタ」タブに戻ります。
-
「データソース」 と 「データベース」 で、Glue Crawlerが作成したものを選択します (
AwsDataCatalog,handson-reviews_db)。「カタログ」は「なし」のままで大丈夫です。 - 左側の「テーブル」に、Crawlerによって自動作成されたテーブル(例:
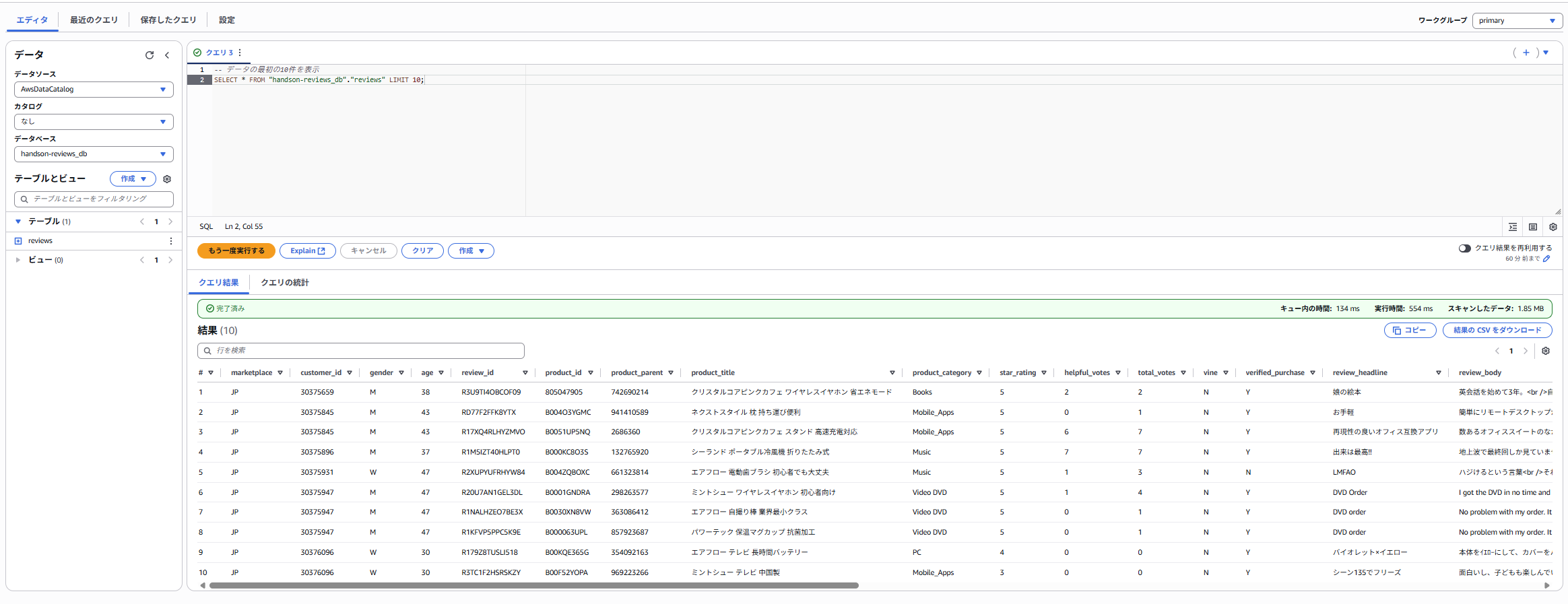
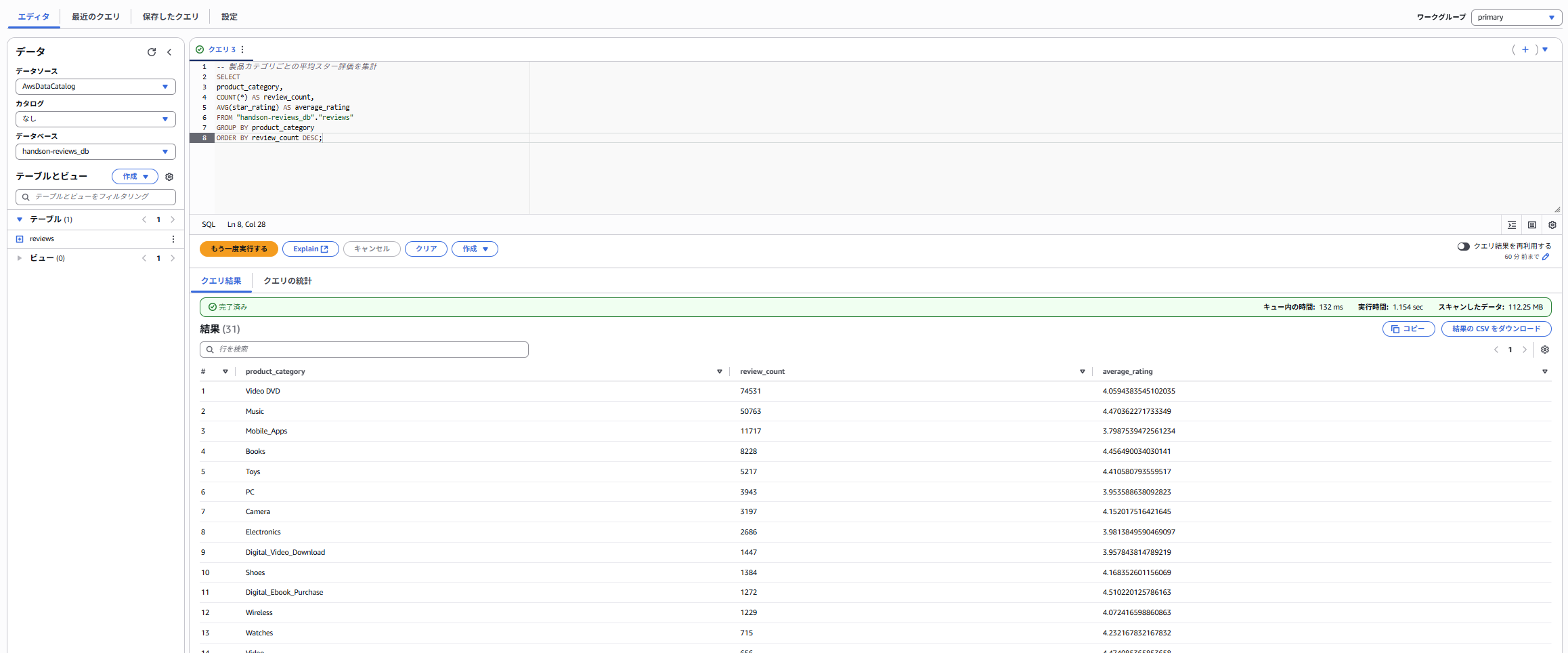
reviews)が表示されるはずです。 - クエリエディタに以下の2つのSQLを入力し、それぞれ**「実行」** をクリックします。
-- データの最初の10件を表示
SELECT * FROM "handson-reviews_db"."reviews" LIMIT 10;
-- 製品カテゴリごとの平均スター評価を集計
SELECT
product_category,
COUNT(*) AS review_count,
AVG(star_rating) AS average_rating
FROM "handson-reviews_db"."reviews"
GROUP BY product_category
ORDER BY review_count DESC;
7.クエリが成功し、「結果」ペインにデータが表示されることを確認します。もし余裕があれば、他のクエリも自由に試してみてください。
🧹 片付け(リソース削除)
- Amazon S3:作成した2つのバケット(データ用、Athena結果用)の中身を空にしてから、バケット自体を削除します。
-
AWS Glue:
- 作成したCrawlerを削除します。(AWS Glue > 左ペインData Catalog > Crawlers > 該当Crawlerを選択し、Actionから「Delete crawler」)
-
作成したデータベース (
handson-reviews_db) を削除します。(AWS Glue > 左ペインData Catalog > Databases > 該当データベースを選択して「Delete」)
- IAM:Glue Crawler用に作成したIAMロールを削除します。
※Amazon Athenaコンソールのクエリエディタ上のタブはバツマークを押して消してしまっても、残しておいても問題ないです。
上記手順でクエリログを補完するAmazon S3を削除しているので、料金はかかりません。行ったエディタ上のログは45日間で消えます。
Athena では、クエリ履歴が 45 日間保持されます。クエリ履歴を表示するには、Athena API、コンソール、および AWS CLI を使用できます。クエリを 45 日より長い期間保持するには、それらを保存してください。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/security-data-protection.html
🏁 おつかれさまでした!
S3に置いたデータをサーバーレスで分析する基本的な流れの理解の手助けになれば幸いです。
応用していくと、AWS CloudTrailのようなAWS内のログを分析する基盤を作ったり、膨大なログデータやIoTデバイスからのデータを蓄積し、ビジネスインサイトを得るための強力なデータ分析基盤を作るのに役に立つ技術です。
Athenaのクエリの書き方やS3上のデータの持ち方でパフォーマンスが変わるので、なかなか奥が深い分野です。
ぜひ、色々挑戦してみてください。