この記事はデータエンジニアのためのSaaS「trocco(トロッコ)」のアドベントカレンダー 2021
17日目の記事になります。
はじめに
本記事ではtroccoをベースに、データを蓄積・加工し可視化することを目的とした基盤を検討してみます。
そして、そこから簡易にMLのフローまで一緒に管理してしまいたいという欲望目線からの考察を展開していきます。
1. 全体の概要図を考えてみる
まずはデータの転送からETL/ELT処理までを trocco で考えてみます。
特に構築のゴールがデータの可視化であり、 対応済みのコネクタ であれば高速に可視化まで持っていけると思います。
手軽に可視化を行うなら、Google Dataportal を使用するのもよさそうです。
また、troccoでは転送元/転送先という観点でサービスを選択できるので、リバースETL ※1 的な要素でも是非使いたいところです。
特に下図のようにセールスフォース(SF)のデータをリバースし、Tableauで可視化、SF側にダッシュボードとして埋め込むなどユースケース的にはシンプルにまとまる可能性も高そうです。
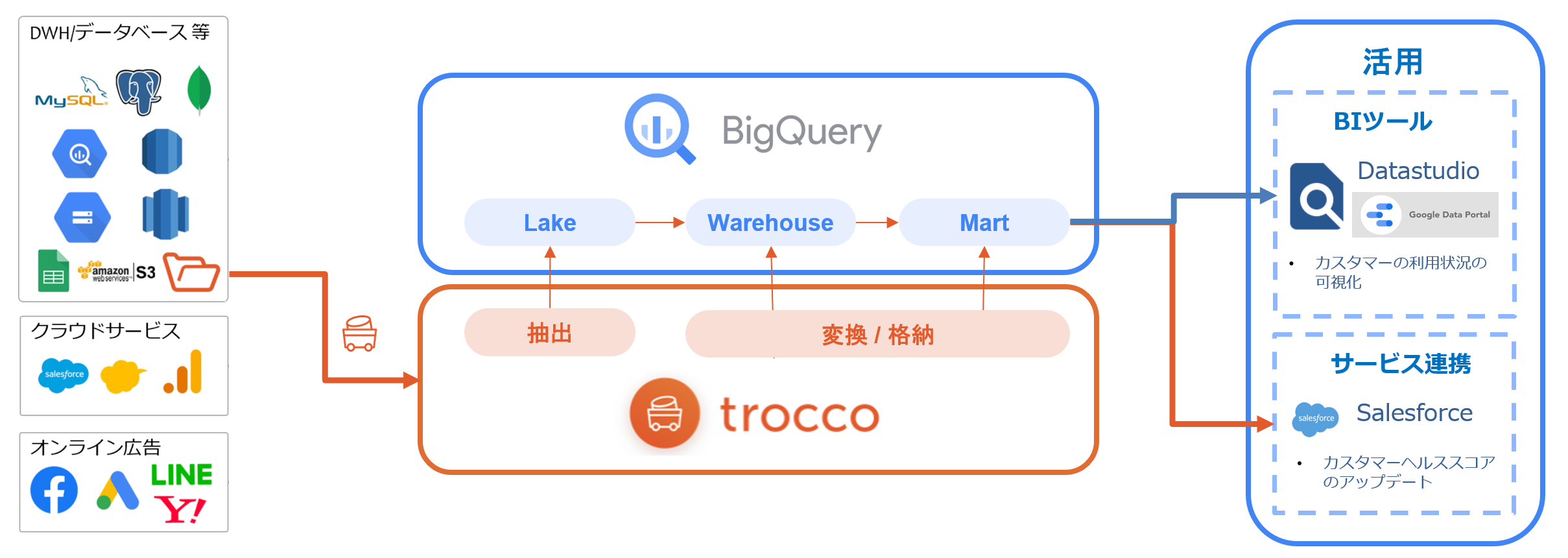
このようにDWH(今回はBigQuery)をハブにして、極力データの遷移を少なくすると簡易なアーキテクチャでは使い勝手がよさそうです。
では、次にDWH前後でのデータ加工はどの程度までカバーできそうか確認していきます。
2. ETL / ELT
まずtroccoでガリっとETLを行うのであれば、PyhtonとRubyを使った加工が可能です。
(別途 GUI上での設定 も簡易に行える)
ライブラリの追加も検討しながら、一般的なデータ加工の設定はスムーズに行えそうです。処理はレコード単位での反映であるため、スクリプト上で他のAPIを呼び出してバッチ的に前処理を行うことも可能そうです。ただし加工するにあたって、事前に情報をもたなければならないもの(例えば、人名の名寄せや辞書を使って変換など)はELTに処理譲ったほうがよさそうです。
ELTは現状大きく2つモードがあり、下記のような形です。
- データ転送モード: SQLで抽出できた情報から新しく新規のテーブルを作成する、新しい断面をどんどん作成する用途
- 自由記述モード: 抽出ではなく、DMLが書ける。主に操作としてDML文が実行可能、MERGE文など用途が広がる
データ転送モードの場合、新しいテーブルを構築しますが、その際パーティションの付与などもちろん可能です。(もちろん前段の転送処理時にも設定可能でした)
DataportalなどBIで可視化することも踏まえて、このあたりが画面上で考慮できるのは良さそうです。そういう意味でもデータマートとしてシンプルにデータを小分けにしていく運用が十分回りそうな気がします。
(処理設定が面倒だと、ドカッと大きなテーブルをBIに渡したくなる)
自由記述モードについては記載の通りです。
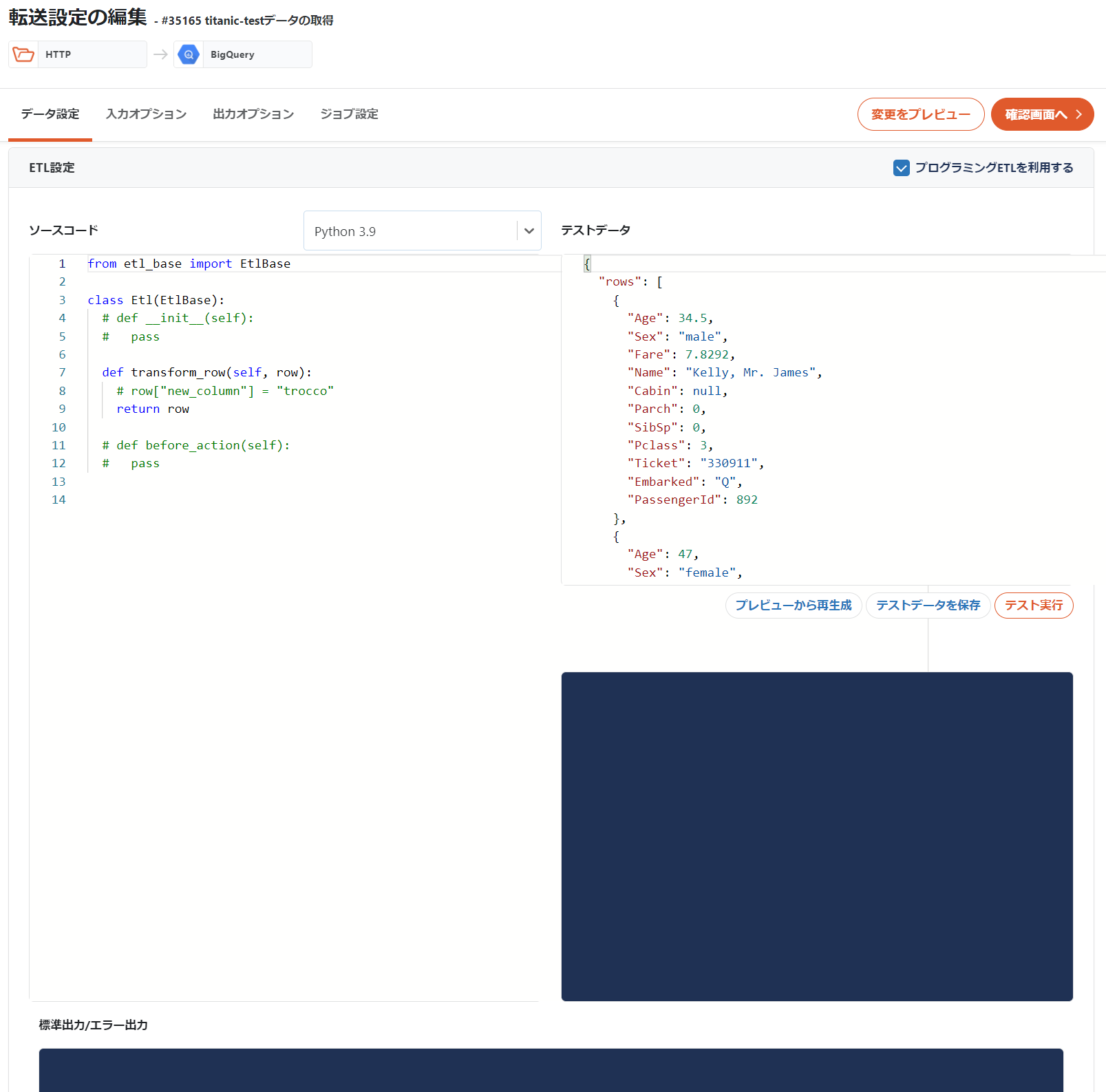
が、SQLが自由に書けるということで、BQMLでモデルを構築することも可能でした。やったね。こちらは後述します。
3. MLのOpsも含んだ形でのワークフロー形成
troccoにはワークフローが存在します。グラフィカルにジョブを配置し、有向グラフとして関係性を示すことができます。
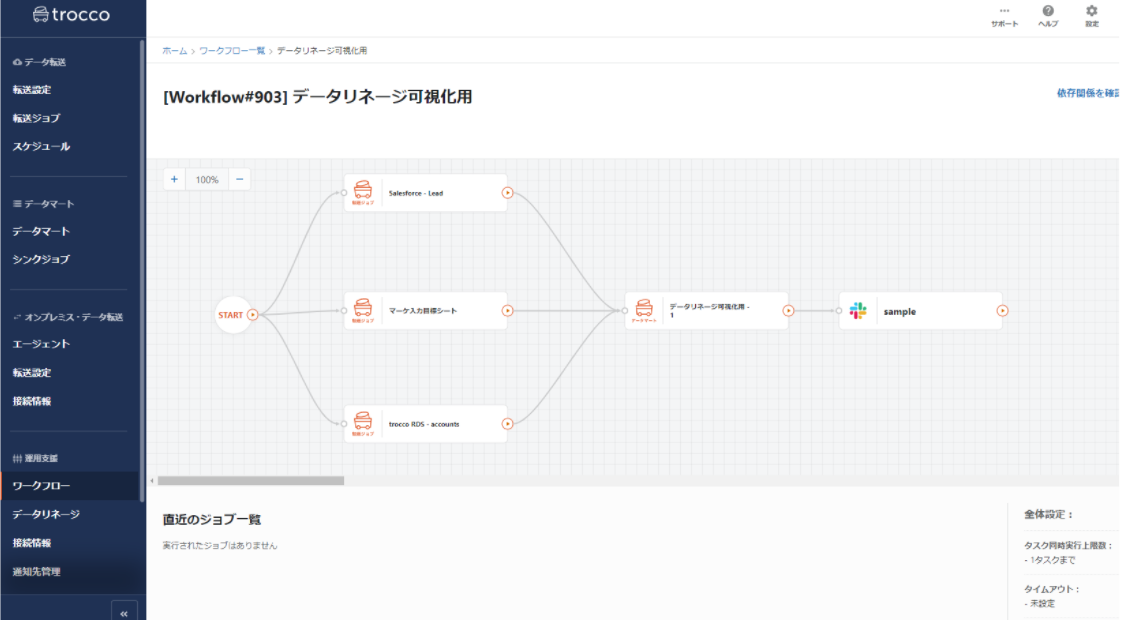
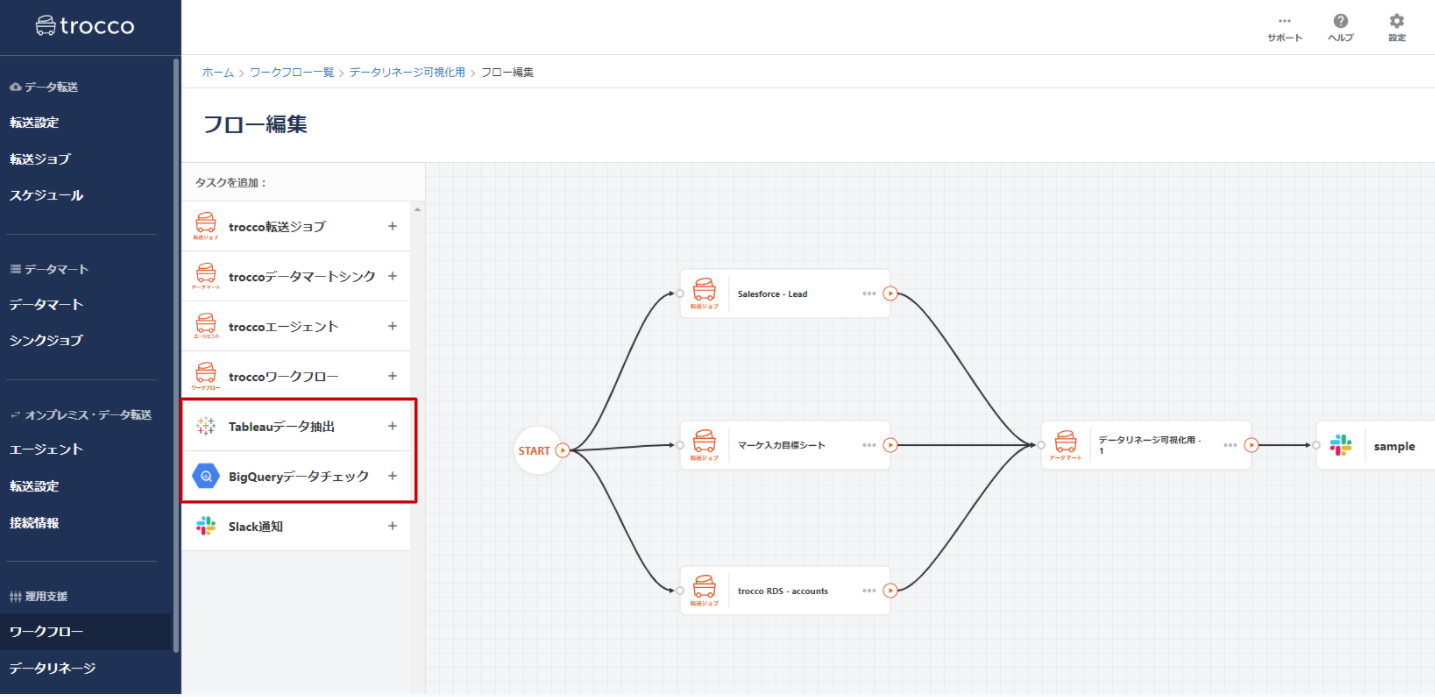
編集画面では、troccoのジョブ(転送・データマート)に加えて、Tableauのデータ抽出をキックするジョブやBQ側のデータ件数をチェックするジョブも追加できます。troccoに管理されたデータソースで作られたTableauのダッシュボードを、Tableau Online上で処理完了ごとに更新したい場合などは良いユースケースとなりそうです。
このような観点から情報を整理し、MLを含んだ形でデータ連携のイメージを起こしてみました。
とりあえず、インプットはユースケースも多いSFDCが対象です。
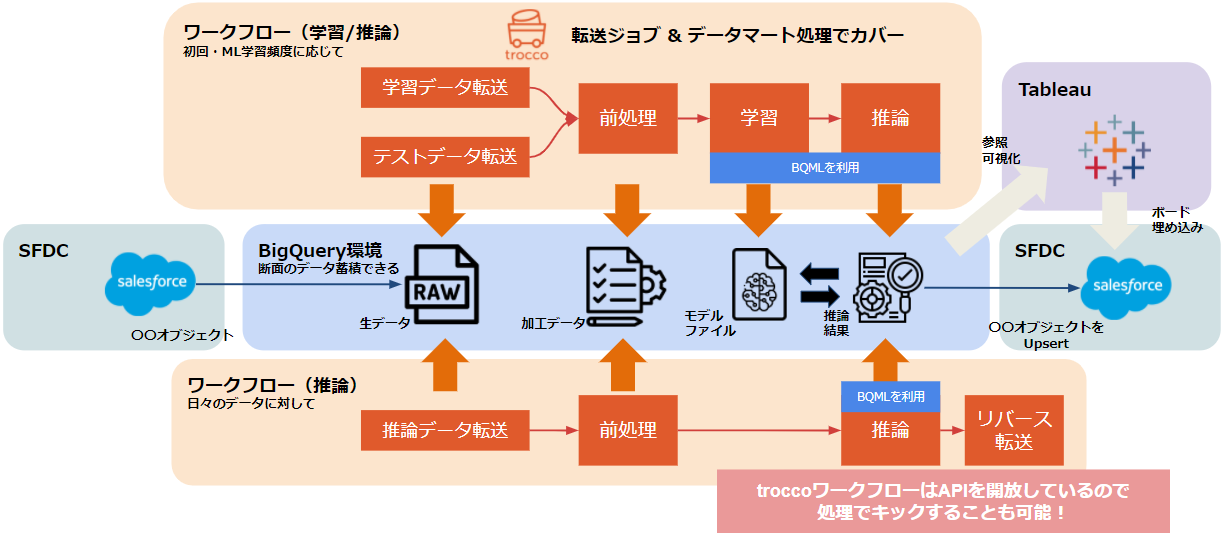
上記におけるポイントを箇条書きで記載します。
- MLの学習と推論にはBQML(BigQueryML)を使用します
- SQLでMLモデルを構築できるため、trocco上で管理が可能です
- MLモデルを構築できれば、バッチ的な一括推論がSQLでシンプルに書けるのもメリットかと思います
- troccoのワークフローは主に学習用と推論用にわける
- ワークフロー内にワークフローを配置することも可能なので、力技で処理の分岐を設けることも可能ですが、見栄えと管理がしづらくなるので見送ります。
- シンプルに学習と推論の頻度も違うので、ワークフロー自体は分けるほうが良さそうです。APIとして個別にリクエストできるのもよいですかね
- データの取得から推論まで一連の流れを管理するので、転送ジョブにおけるデータのリストアやジョブエラー時における発生個所からの再実行など、ML用のため自分で作るにはちょっと面倒な部分も一手に引き受けくれた感があります
- データマート作成でデータを加工し、推論する
- これはメリデメありそうですが、とりあえず何かしらデータを加工すればBQ上に新規でテーブルが作成される形となります
- あとはデータのエイリアスや必要に応じてバックアップ(テーブルコピー)を行っていれば十分な運用フローになりそうです
- 一旦各ジョブをつなげることができれば、運用が回る想定
- 実際のデータ遷移は様々な環境をまたがっていますが、trocco上に処理を寄せることができるのでワークフローで繋ぐことができれば、Opsとして動かすことができます(もちろんデータにゴミが混ざると駄目だけど、そこはSQLだとハンドリングしやすい場合も多いと思う)
- ソース管理(Github)もできる
- trocco側の機能で各設定ファイルをyaml形式で、GIthub管理することができます。また、Github管理せずとも、troccoの画面上で設定情報の差分がみれたり、リビジョンバックもできるので、この点についてはかなりリッチな印象です。
- 推論結果をリバースETLする
- BQ側に一括で推論結果が格納されるので、それを参照したいサービス側で直接見るのも良いと思います。が、troccoで一括管理する利点として、直接サービス側に転送する(Update or Upsert)のもやはり良さそうです。
4. 実際に動かしてみた
上記のSFDCベースで想定して実施できればよかったのですが、あいにく良さげなデータセットが手元になかった😢ので
サンプルとしてkaggleのタイタニック問題のデータの取得から推論までを含めて実施してみます。
タイタニック問題は検索すれば、内容がたくさん出ると思うので割愛しますが、1行で書くと
「タイタニック号に乗車していた人間の属性項目を使って、DEAD or ALIVEを判定する2値分類問題」という内容です。
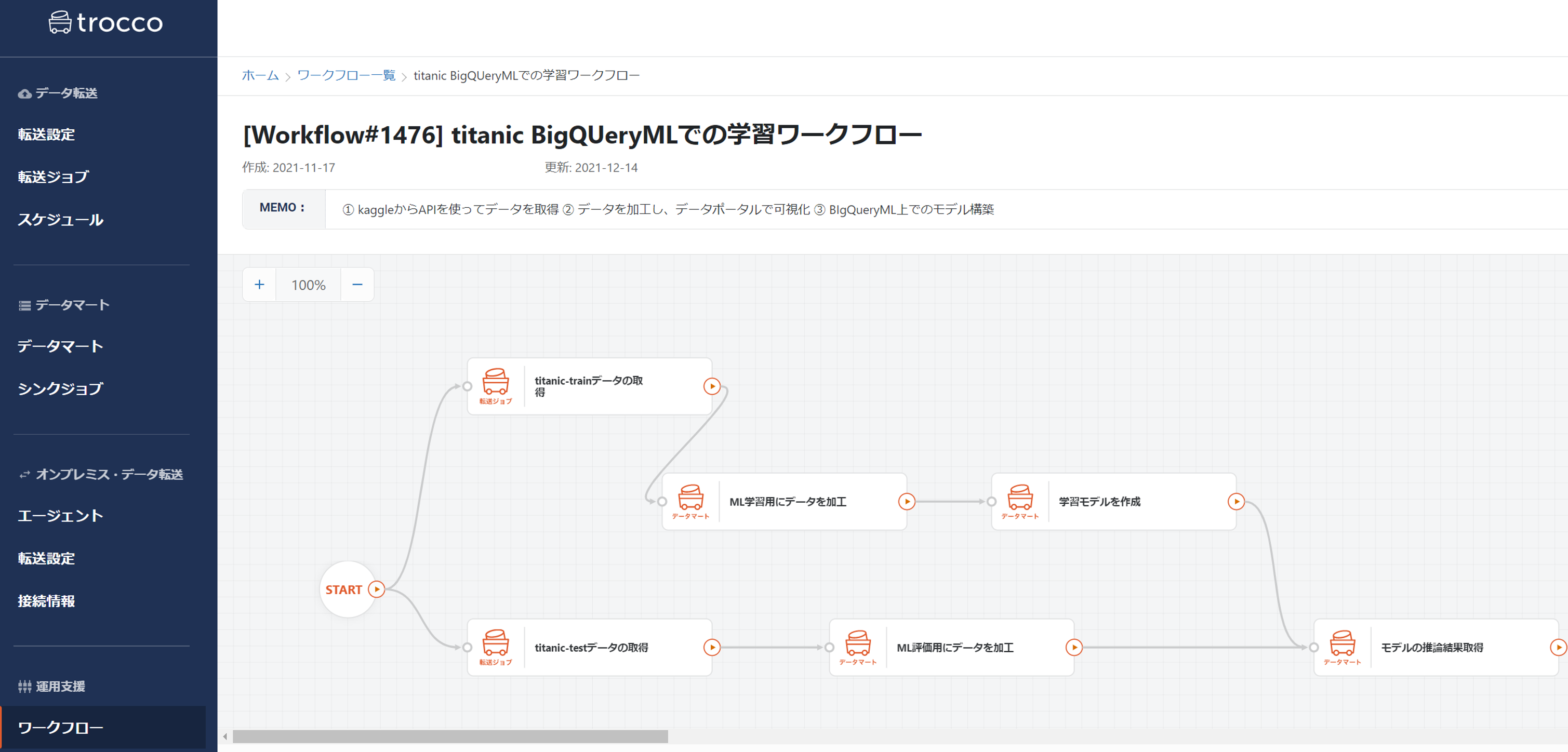
上記ワークフローの流れとしては
1:kaggle APIを使って、学習/テストデータをそれぞれ取得し、BQに蓄積(trocco転送ジョブを使用)
2:BQに蓄積されたデータを簡易的に前処理し、BQに蓄積**(troccoデータマートを使用)**
3:BQMLを使って2のデータを学習**(troccoデータマートを使用)**
4:3で作成した学習モデルを使用して、テストデータを一括推論、BQに蓄積**(troccoデータマートを使用)**
となります。一つずつ簡単に見てみましょう。
4-1. kaggle APIを使ったデータ転送
学習データの取得ジョブの詳細となります。kaggle側でAPIのtokenを発行、エンコードし、ヘッダーに詰め込むだけです。
このあたりもtrocco側の設定項目として設けられているので、特に迷うこともありません。
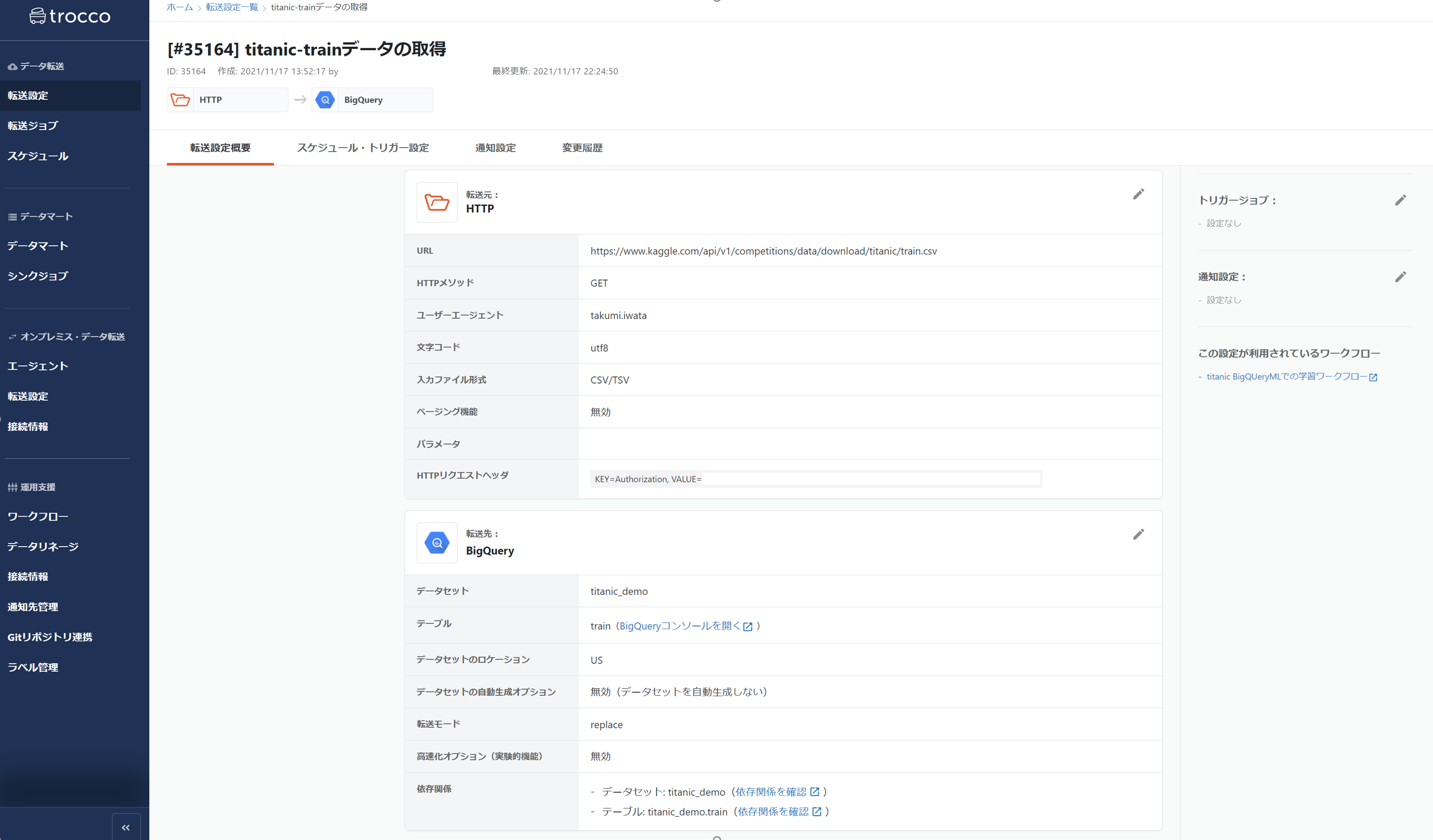
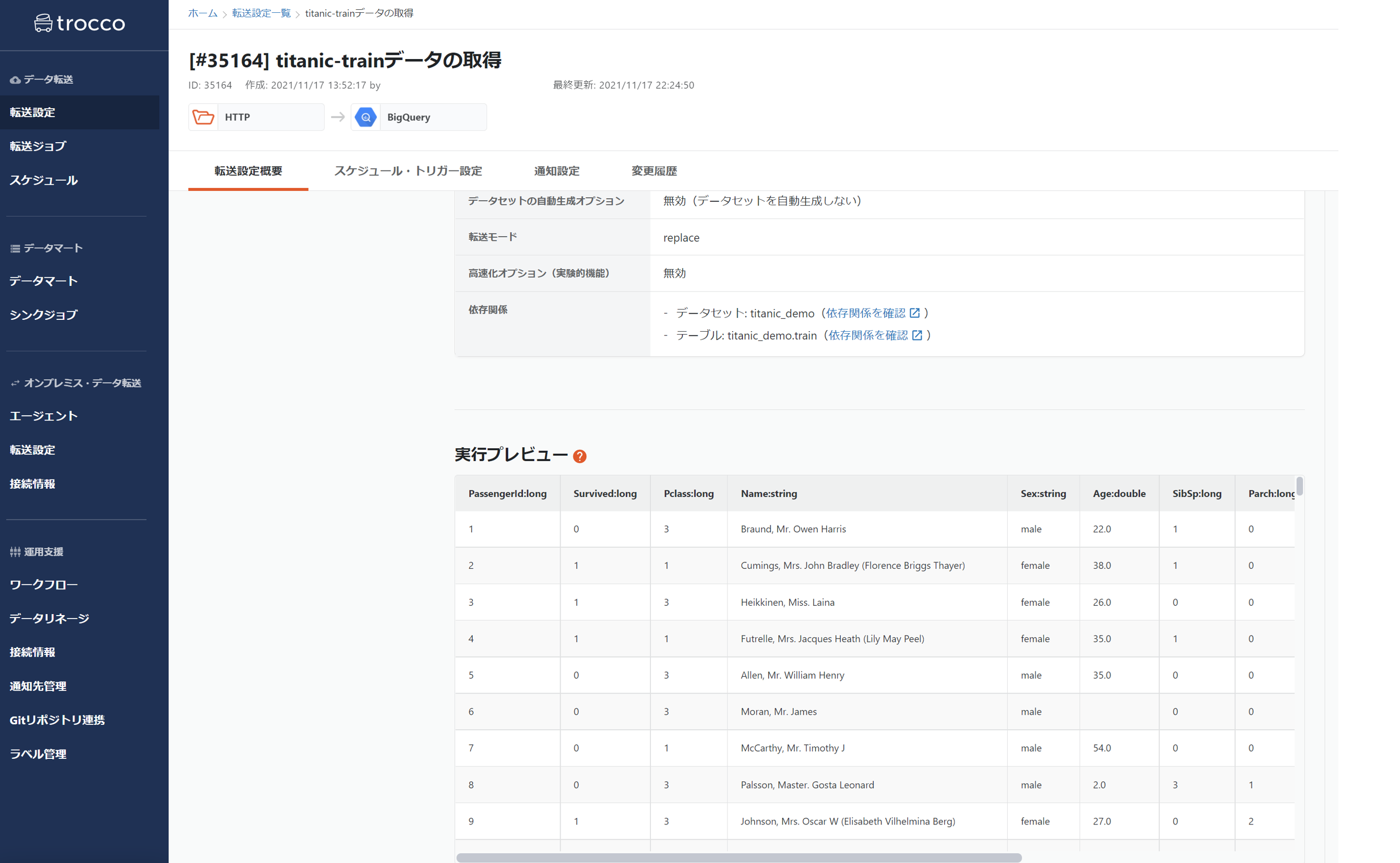
で、実行プレビューでも問題なくデータが取れました。
ちなみにこの転送時にも簡易なETLであれば、GUI上で実施できるので置き換えなどはやってしまっても良いかもしれません。
(プログラミング言語を使ったETLも先のセクションで記載した通り可)
4-2. データの簡易前処理(ELT)
BQに蓄積された学習/テストデータを使って、加工を行っていきます。
カラムに対しての四則演算や集計、セグメント設計などはSQLで十分(というかやりやすい部分も多い)ですが
やはり本格的な前処理は、少し物足りなさがあります。このあたりは最後にまとめてみます。
簡易な例として、年齢をセグメント分けてカラムとしました。一応ビニングとさせておくれ。
SELECT
CASE
WHEN Age <= 16 THEN 0
WHEN Age <= 32 THEN 1
WHEN Age <= 48 THEN 2
WHEN Age <= 64 THEN 3
ELSE
4
END as age_seg,
*
FROM
titanic_demo.train
4-3. BQMLでの学習
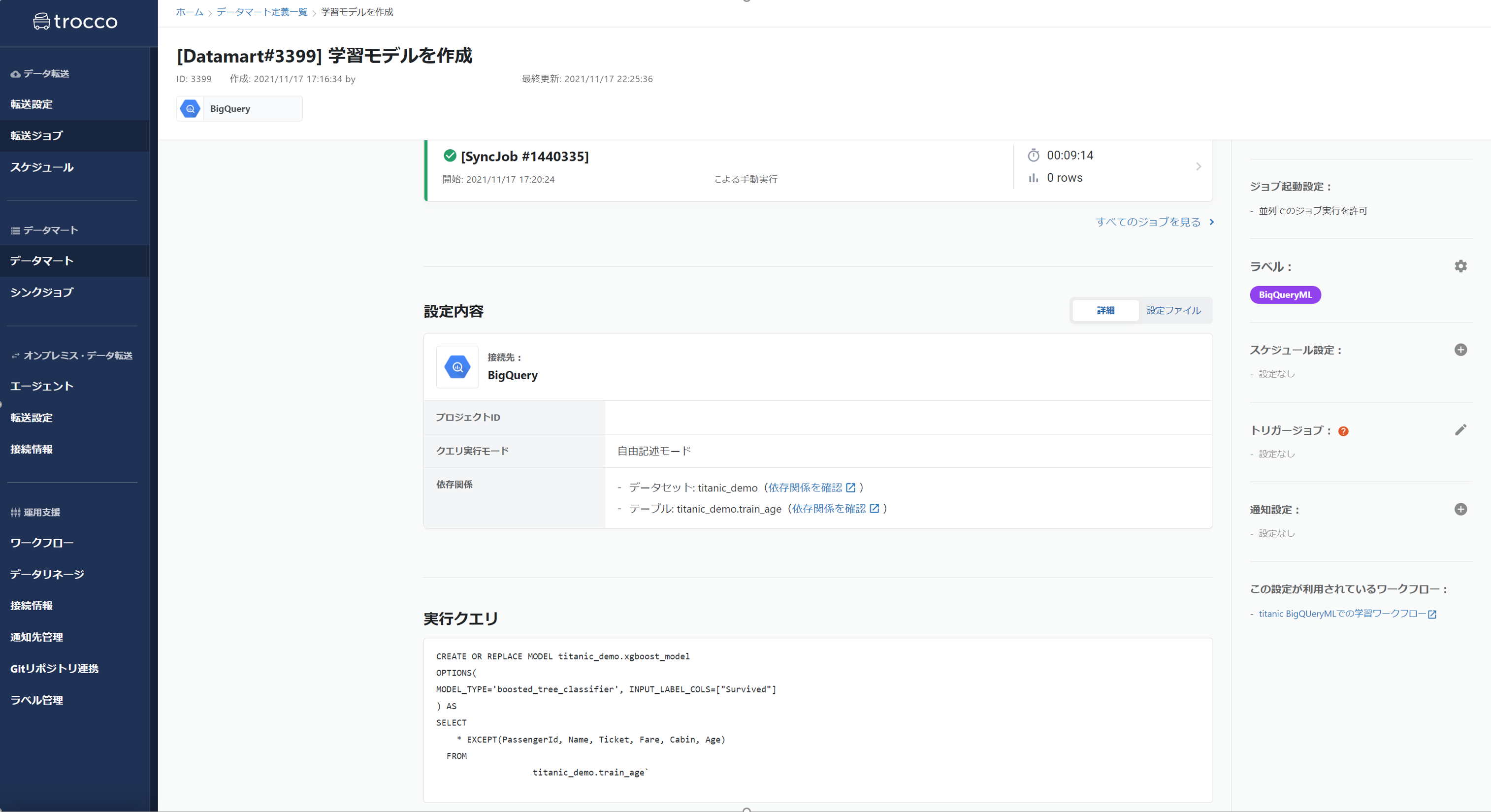
やはり下記のようなSQLだけでまさかの機械学習できるのがBQMLの利点ですね。
XGBoostを使ってシンプルに学習を行います。
CREATE OR REPLACE MODEL titanic_demo.xgboost_model
OPTIONS(
MODEL_TYPE='boosted_tree_classifier', INPUT_LABEL_COLS=["Survived"]
) AS
SELECT
* EXCEPT(PassengerId, Name, Ticket, Fare, Cabin, Age)
FROM
titanic_demo.train_age
上記のようなSQLをそのままデータマート処理として設定するだけです、楽チン。
ジョブ自体は成功し、結果 0件 となっていますが、しっかりとモデルファイルが作成されているか次の工程で確認しましょう。
4-3. BQMLでの推論
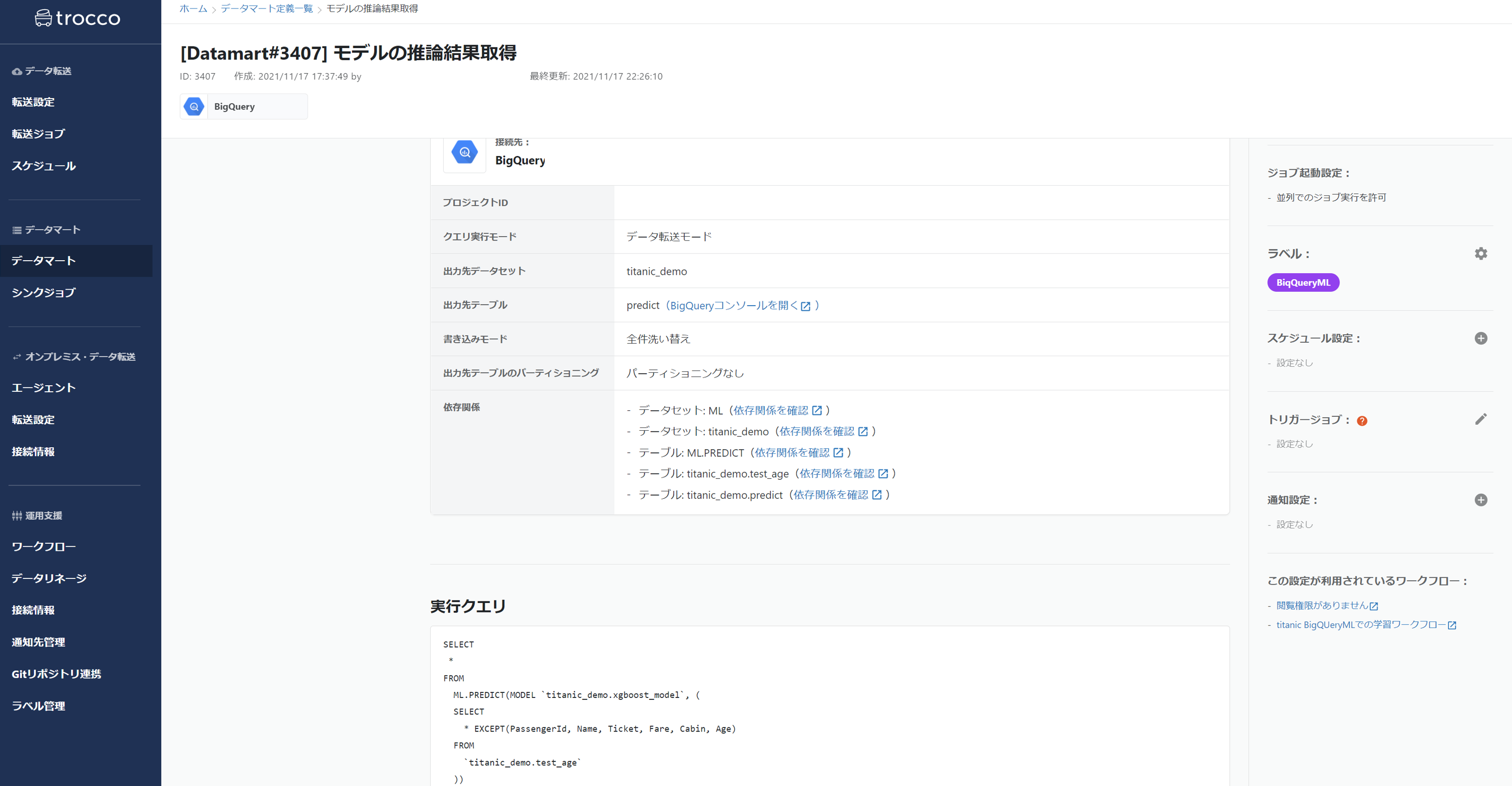
作成したモデルに対して、predictを行ってみます。
まず下記のようなSQLを使って、テストデータに対して推論を行います。
その推論結果はpredictというテーブルに格納されます。
SELECT
*
FROM
ML.PREDICT(MODEL `titanic_demo.xgboost_model`, (
SELECT
* EXCEPT(PassengerId, Name, Ticket, Fare, Cabin, Age)
FROM
`titanic_demo.test_age`
))
これも学習と同じようにtroccoでジョブ化を行います。
じゃあ通しでワークフロー実行!
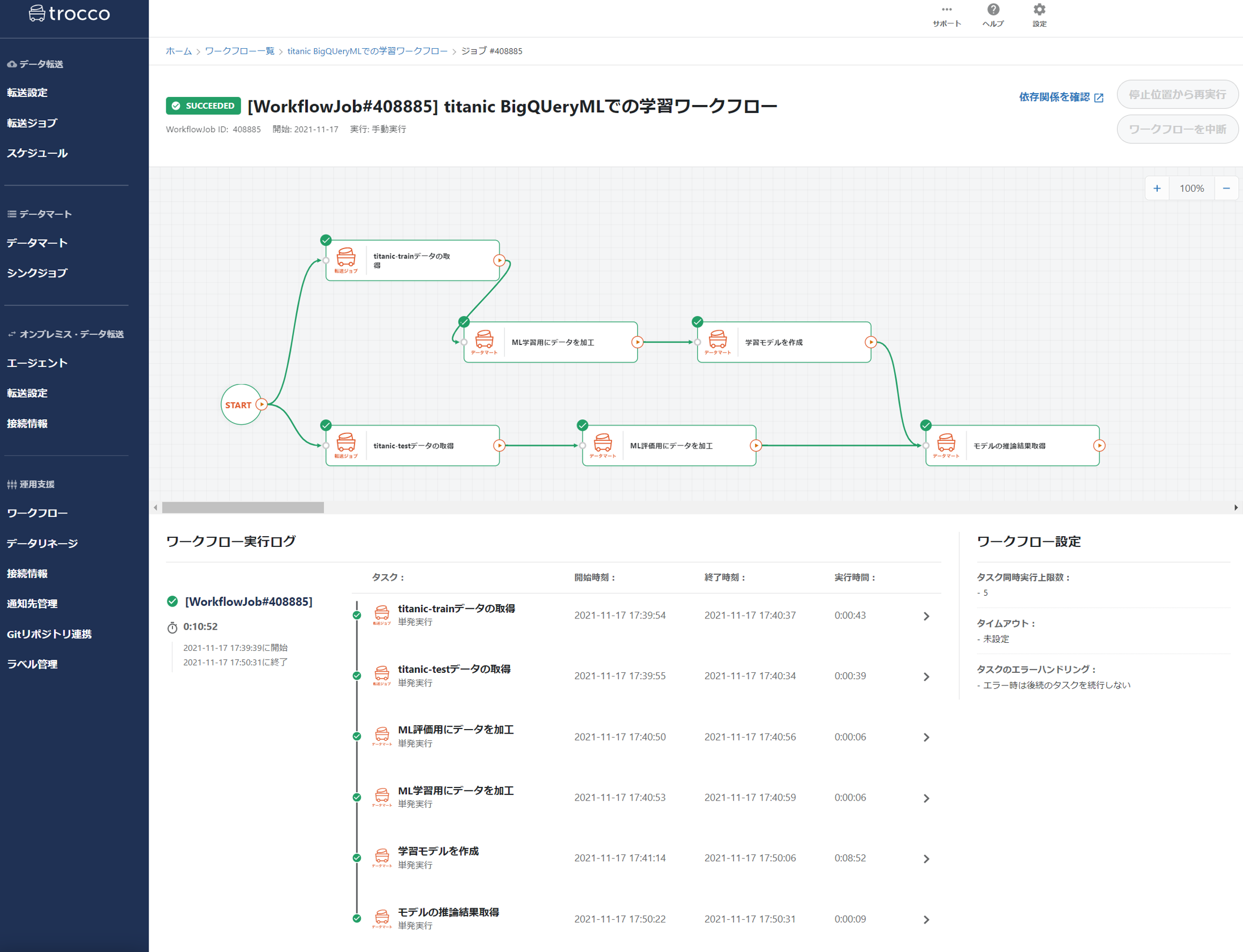
うまくいった🙆最後にBQ側でも確認しましょう。
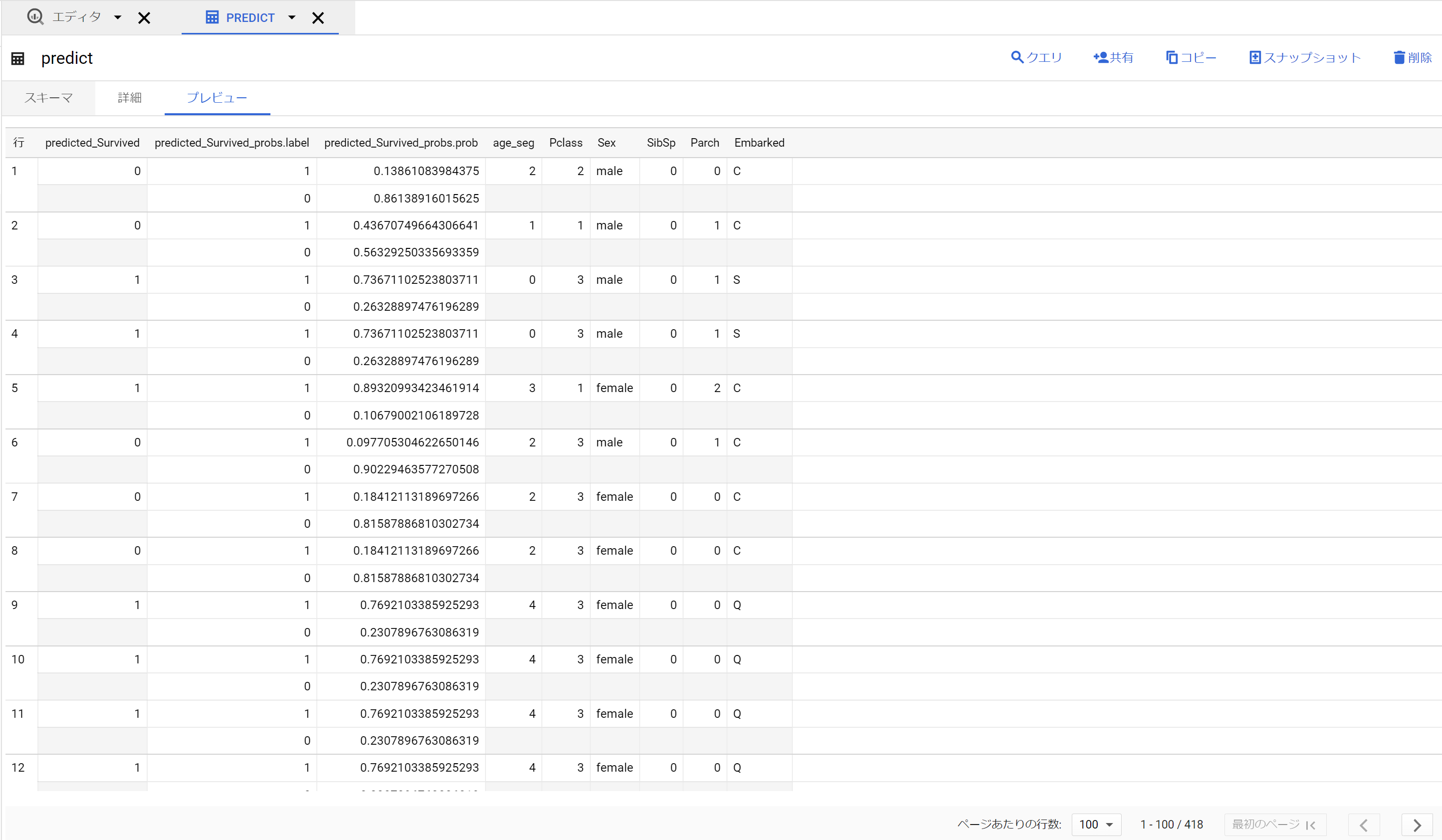
ちゃんとprobability含めて蓄積されています。さらに、このデータに対して、データマートを書いてもいいし
その結果を他のサービスに転送したり、リバースしたりもできるので応用は広がりますね。
(転送先:HTTPは無かったので、全自動でkaggle側に送信して順位まで見るというのはでは不可でした)
APPENDIX 可視化
最後に可視化もちょっとだけ。
今回はBQ上にデータを蓄積しており、ちょと簡易に可視化したいのであればGoogle DataPortalが使えます。
各断面のデータをベースにして、考察やグラフを整えるのもよいのではないでしょうか。とくに
この点はPythonなどのプログラミング言語を使って可視化するよりも、一段ハードルは下がるので取っ付きもやすいですね。
まとめ
troccoを使って、簡易なMLOPsをまわすことが達成できました。担当を少し整理します。
■ BQ・BQML
各データの管理
モデルファイル、学習における結果の管理
SQLにおける前処理(ELT)
学習・サービングなどのMLの機能
権限管理(主にデータへの直接権限)
■ trocco
全体ワークフローの管理(スケジュールなど)
PythonやRubyにおける前処理(ETL)
各種実行ジョブ管理(誰が、いつ実行したのかなど)
権限管理(ジョブ単位でのグループ管理機能)
なかなか良い棲み分けですが、さらに希望としては
- troccoと分析環境との連携、colabとかでも十分嬉しいですね。最近はproも使えるし
- trocco側でBQMLの学習結果なども見れるようになる → 直接GCPコンソールを開く必要も無くなりそう
な感じでしょうか。今後も追いかけていければと思います。
おわり🙇