モチベーション & ターゲット
既に出尽くされているであろうGoogle BigQueryのテーブル設計について改めて考えてみます。
特にこれからBQを使おうという方や、データサイズがそれほど大きくなく特に検討する必要がなかった
(ただし、これから大きなデータ扱うかも)という方向けという感じです。あと自分の備忘録としてメモ的に書いています
(私見なので間違いもあります、ご指摘いただければ幸いです)
取り扱うアーキテクチャ
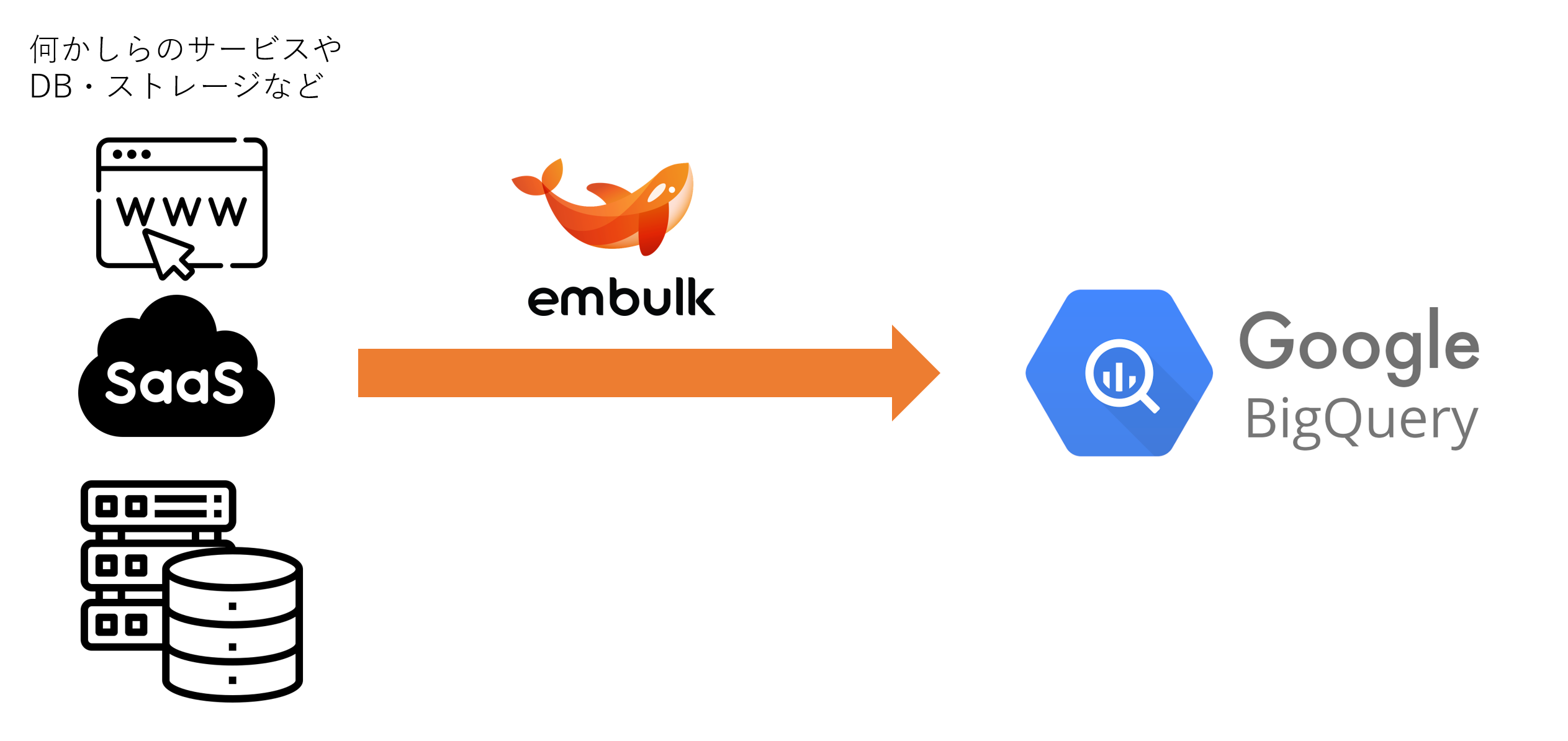
- データを転送したい「元」はサービスやDB・ストレージなどを想定します(要は何でもOK)
- 転送するためのサービスはembulkを使用するイメージ
- 転送先はDWHを想定し、今回はGoogle BigQueryをチョイス
- 特にそれぞれの何が良い/悪いみたいな話は割愛します
転送元で考えること
- BigQueryに入れるので、基本的には構造化なデータが取得できるサービスやシステムを想定
- ポイントとなるのは、転送元のデータ構造がどれほど変わるものなのかという点
- 例えばSaaSサービスなどの場合は取得できるカラムが増えることが合っても、取得できるカラムが減るということは少ないかも
- スプレッドシートみたいな表計算ツールになると、ガンガンデータ構造も変わるかも など
- あとは地味に転送元側でも地味にSQLを書ける環境があるかどうかなどもポイント
- 例えば、SalesForceであればSQLライクなSOQLが書けるなど、転送元がDBであればやはり楽かもしれない
embulkで考えること
- データを取得する側のinputプラグインについては今回割愛
(主にはBQ側のテーブル設計にフォーカスをあてたい) - BigQueryへのoutputプラグインはこちらを利用検討
- GCS(Google Cloud storage)に一時ファイルを吐き出して、それをロードする形式
- ポイントとなるのはデータの転送モード、一次テーブルを作って扱うかという挙動(下図参照)
- REPLACE : データ置き換え
- APPEND : データ積み上げ

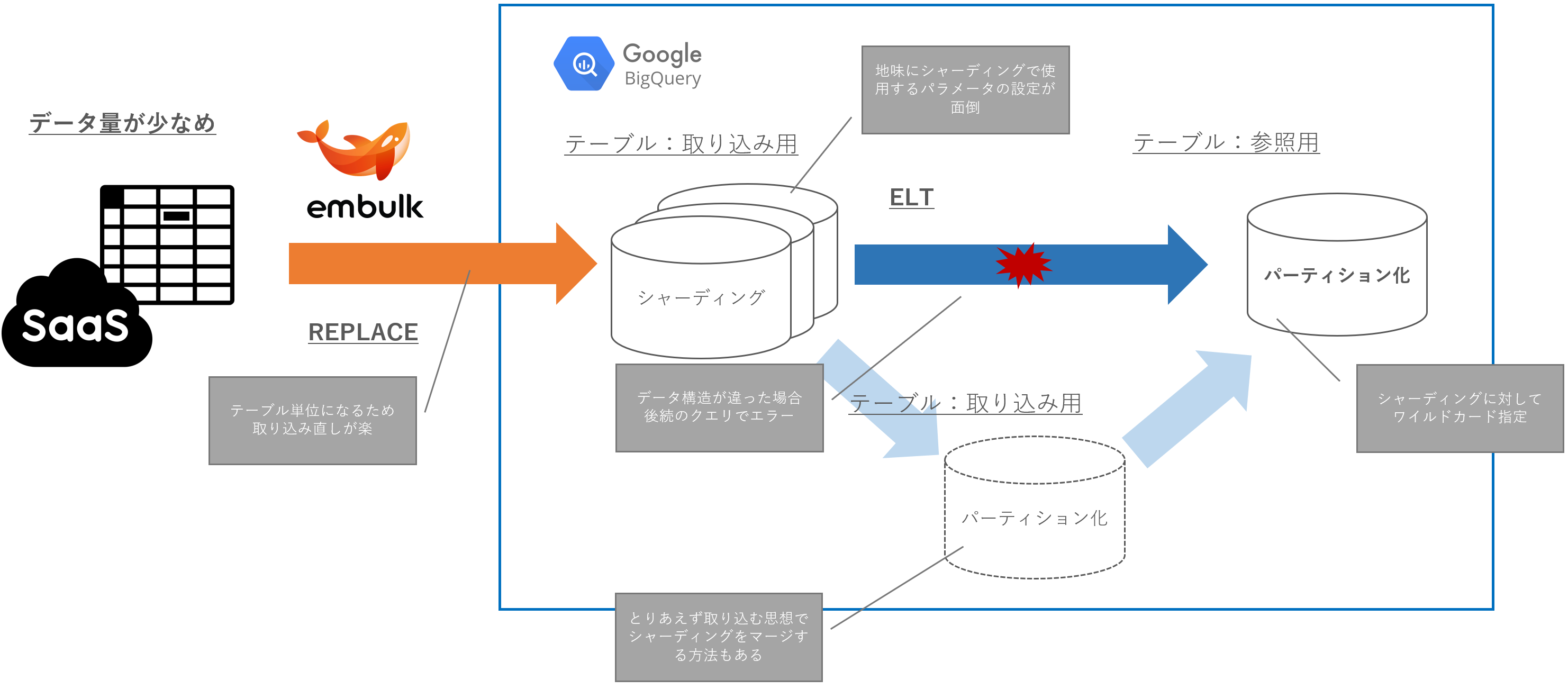
パーティションとシャーディング
- 少し雑ですが、まとめたものは下図
- 公式的にも迷ったらパーティションがおすすめという感じですが、公式Docが書くシャーディングおすすめの場合はこちら

ちなみにBQコンソール上でのシャーディングの見え方はこんな感じです。個人的には結構好みです。
上記から考えるユースケースと設計イメージ
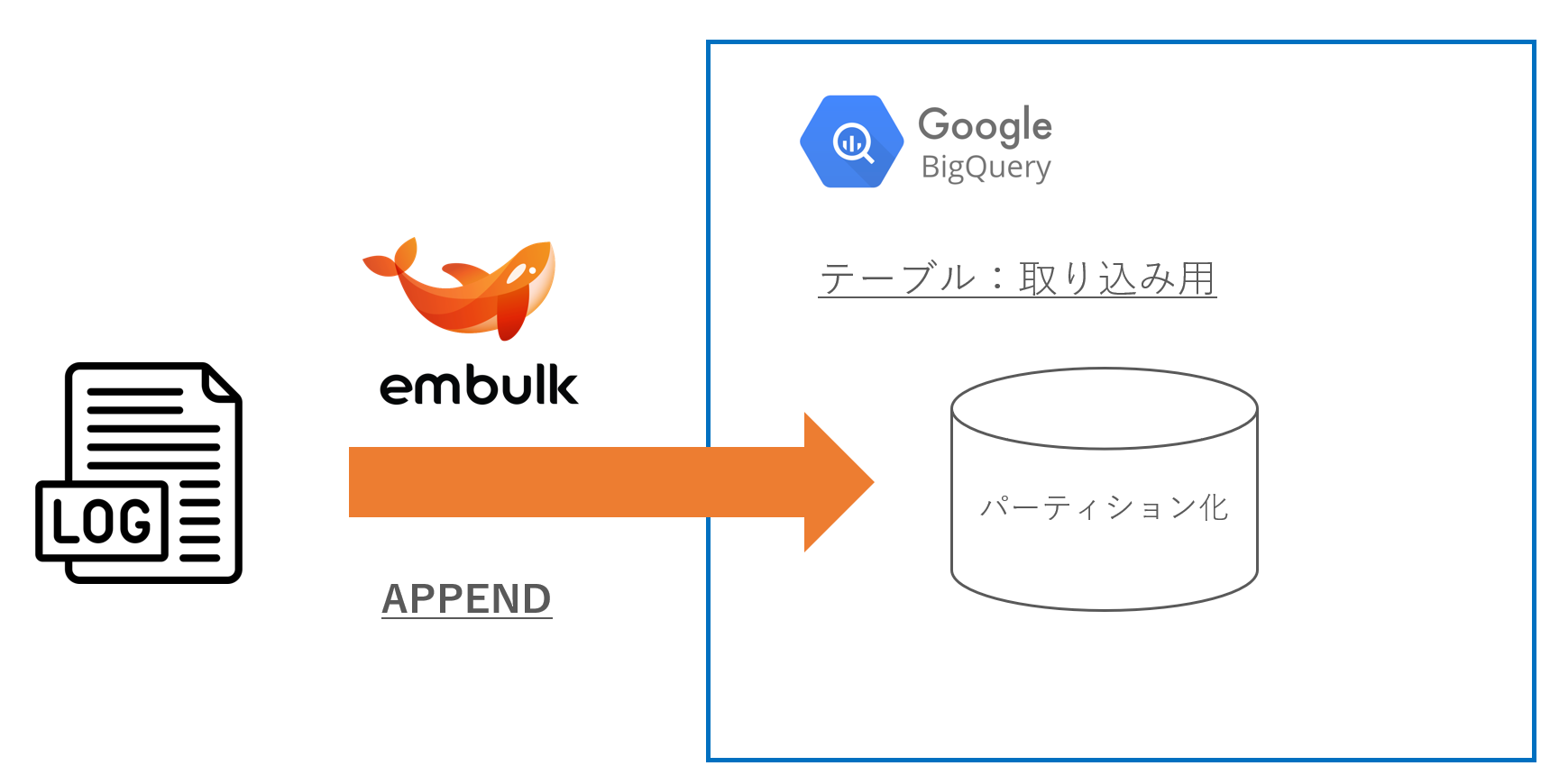
転送元のデータ構造があまり変わらない場合 かつ 転送はAPPEND
- ユースケースとして「アプリケーションのログ」などをイメージ
- 基本的にはログファイルとしてストレージに吐き、日付(ログ日付 or 取り込み日付)でパーティションを設定するのがよさそう
- ただしデータ量がそれなりに大きい場合は、取り込み日付(1ログファイル内で統一した値) でパーティション設定したほうが良い
- 再度データの入れ直しが発生したときにリカバリが楽になる(DELETEが楽で速い)
- シンプルに取り込み直しはクエリを用意する必要があるので、面倒(再取り込みにおける同じキーへのDELETE/INSERTの機構を用意する必要あり)
- ストレージ側にログファイルがあるので、リストアもしやすそう
転送元のデータ構造があまり変わらない場合 かつ 転送はREPLACE
- ユースケースとして、「DBにおけるマスタ情報」を転送する際に該当
- トランザクションが発生しないテーブルであり、データ量としても大きくないイメージ
- こちらも上記同様パーティションを設定するのが良いが、用途的にはパーティションを必要としないケースも多いイメージ
- 後続の処理に応じてパーティションの要否を検討するレベル

転送元のデータ構造が変わる場合
- このユースケースをさらに転送元のデータ量で分けるとしたら下記のようなイメージ
- データ量が多い:SaaSサービスやSFA、CRMなど
- データ量が少ない:スプシ(表計算ツール)やMAなど
- 選べるアーキテクチャの選択肢としては
- 転送モードは APPEND を選択して、パーティション を使う
- 転送モードは REPLACE を選択して、シャーディング を使う
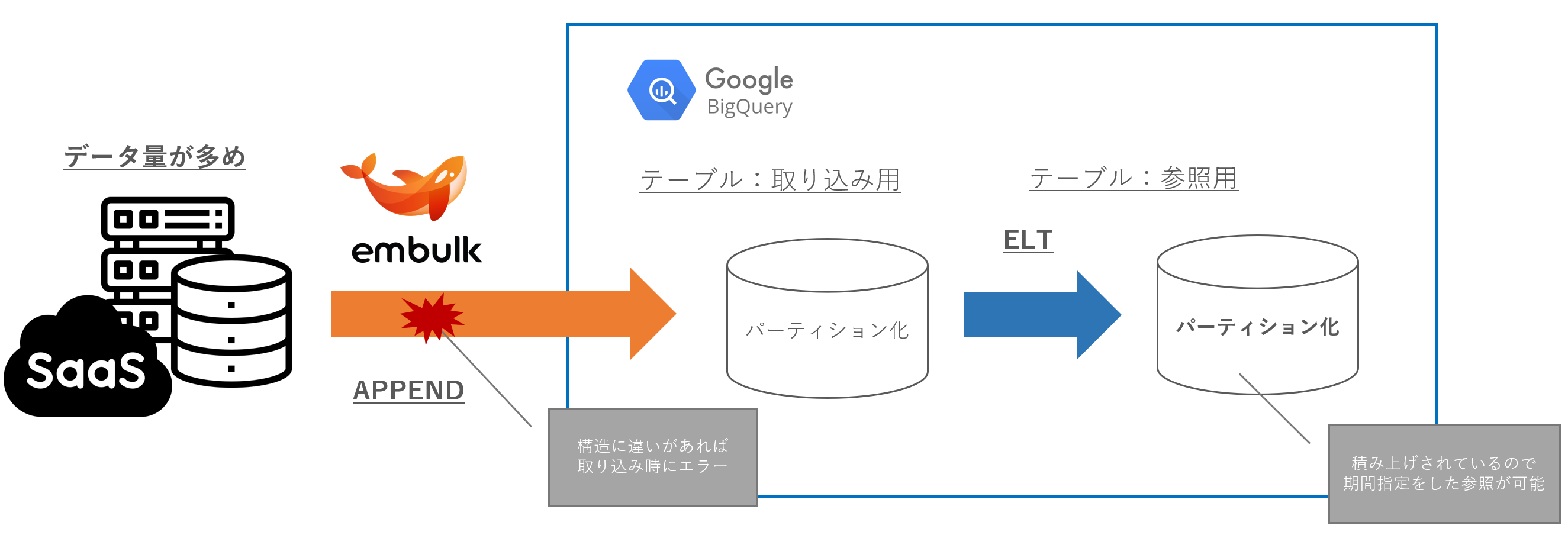
転送モード APPEND & パーティション
- どちらかというと転送量のデータ量が大きい場合の用途をイメージ
- 取り込み時にデータ構造の違いがある場合、エラーとなる(これが頻発すると調査が面倒)
- 後続の参照用テーブルもパーティションキーを踏襲しやすいので、設計が楽になる
- (シャーディングの場合と対比して)1テーブルに積み上げで情報を持っているので、速度や処理に不安が少ない
- この取り込みテーブルが大きくなればなるほど、クエリのパーティションキー指定を忘れられないのでリテラシーを求める必要がある
転送モード REPLACE & シャーディング
- どちらかというと転送量のデータ量が少ない場合の用途をイメージ
- 各テーブルに対して取り込みを行う形となるため、取り込み時にはエラーが起きない
- とりあえずデータは取り込んで、起こり得るエラーはBQ上で全て確認するという思想もあり
- エラーパターンとしては、後続の参照用テーブルで存在しないカラムを呼び出した場合などが該当
- 現状使用しないカラムが追加された場合などはエラーにならないので、その点は良い
- シャーディングに該当する複数テーブルをワイルドカードで呼び出すときの不安
- 速度もあるが、データ構造が統一化されていないこともあり、想定したデータが取れているか不安もある
- そのためシャーディングで取り込んだテーブルをパーテイション化したテーブルで積み上げる方法もあり得る
まとめ
- ユースケースからも見る通り、やはり基本的にはパーティションを使うのが良い
- ただし、シャーディングにも使うメリットが十分あるため、使い分けをお勧めする
- 特に以下の場合などシャーディングを検討してもいいじゃないかと思う
- 転送サイズが小さいがたくさんの転送元サービスから情報を持って来る場合
- 各取り込み処理が日付やキーで独立しており、後続で積み上げる必要がない場合
- 構造違いでエラー起こった際にBQ上で切り分けをしたい場合
- 基本転送元サービスのカラム削除はなく、カラム追加が多い場合、そして後続ELT処理の修正と同期がとりやすい場合(チーム的にも)
最期に宣伝
- embulkのマネージサービスとして、troccoを提供しています
- 上記アーキテクチャに対しても、もちろん対応しており、テーブル取り込み前後のDML処理やシャーディングの動的な日付パラメータ管理なども含めて可能です
- まだ一部とはなりますが、カラム変更におけるスキーマ追従などにもスポットをあてておりますので、気になった方は是非覗いてみていただければと思います!